
图像级标记弱监督目标检测综述
2023-09-26 04:21:36陈震元王振东宫辰
中国图象图形学报 2023年9期
陈震元,王振东,宫辰
1.南京理工大学计算机科学与工程学院,南京 210094;2.高维信息智能感知与系统教育部重点实验室,南京 210094;3.江苏省社会安全图像与视频理解重点实验室,南京 210094
0 引言
目标检测是计算机视觉领域的基本任务之一,其旨在使用矩形框定位图像中的每个目标物体并预测其类别。目标检测已在生活的各个领域发挥着重要作用,体现出巨大的应用价值(曹家乐 等,2022)。例如,在自动驾驶中,需要实时对周围环境进行分析,检测出可能存在的障碍物,从而辅助无人系统及时做出反应(徐歆恺 等,2021);在遥感图像识别中,需要在高分辨率图像上检测出目标(如道路、植被和水体等)分布,从而提供更准确的地理位置信息(赵文清 等,2021;Yao等,2021)。随着卷积神经网络的高速发展,目标检测在一些实际应用中已达到较高的精度。然而,目标检测的高精度依赖于检测器训练时精确的区域或实例级别的图像标记,但实际场景中背景的复杂性以及目标的多样性等因素使得图像精确标注极为费时费力。因此,研究人员开始将目光转移到对监督信息依赖程度较低的、基于图像级别粗标记的弱监督目标检测算法上。
弱监督目标检测旨在降低对标记的要求,从而有利于更便捷地获取大量已标记训练样本,使模型达到接近全监督目标检测的效果。具体地,传统的全监督目标检测算法需要人工用最小矩形框标记出图像中各物体的位置及其类别,因此训练样本的获取代价较高;而弱监督目标检测算法只需要整体图像的类别标记即可进行训练,所以通过一些图像检索网站上的类别标签,就可以轻松获取大量训练样本。因此,弱监督目标检测算法具有较高的研究意义和应用价值,对该领域的进展进行归纳和综述也有很大的必要性。
然而,现有弱监督目标检测相关综述仍存在一些不足之处。比如,杨辉等人(2021)按照不同的特征处理方法对典型算法进行分类,该分类依据的边界较为模糊,且不能直观体现弱监督目标检测算法的特点。周小龙等人(2019)和Liu 等人(2020)的综述发表的时间较早,因此没有囊括近几年的新进展。Shao 等人(2022)和Zhang 等人(2022a)都是将目标检测与目标定位相结合,统一描述两者的发展历程,没有细致地区分深度弱监督目标检测的方法类别。任冬伟等人(2022)综合介绍了弱监督视觉领域的研究进展,对弱监督目标检测的介绍还不够细致。针对上述问题,本文首次根据核心网络架构对弱监督目标检测领域的经典及最新算法进行了全面且清晰的分类归纳与对比分析,并提出多个有价值的未来研究方向。
具体地,本文介绍了弱监督目标检测的问题定义、基础框架和面临的主要难题;按核心网络架构将现有典型算法分为三大类并分别阐述各类算法的核心贡献;通过实验对比了各类主流算法的检测效果;简要探讨了弱监督目标检测领域未来的研究方向。
1 弱监督目标检测简介
本节从弱监督目标检测的问题定义出发,介绍基于多示例学习的通用基础框架(Bilen 和Vedaldi,2016),并阐述该领域所面临的三大主要难题。
1.1 问题定义
弱监督目标检测训练阶段和测试阶段的示意图见图1。其中,训练阶段的输入是训练图像及其类别标记,输出是训练好的目标检测器。测试阶段的输入是测试图像,输出是在该图像中的目标检测结果。训练阶段中,由于目标检测需要使用矩形框框出图像中每个目标物体的位置,因此一般需要先在输入图像上生成大量目标候选框,然后对目标候选框提取特征并预测其类别,最后将预测结果与输入的图像类别标记计算损失并以此更新模型参数。所以,整个弱监督目标检测问题可理解为学习一个从图像包含的若干候选框到图像类别标记的映射关系。
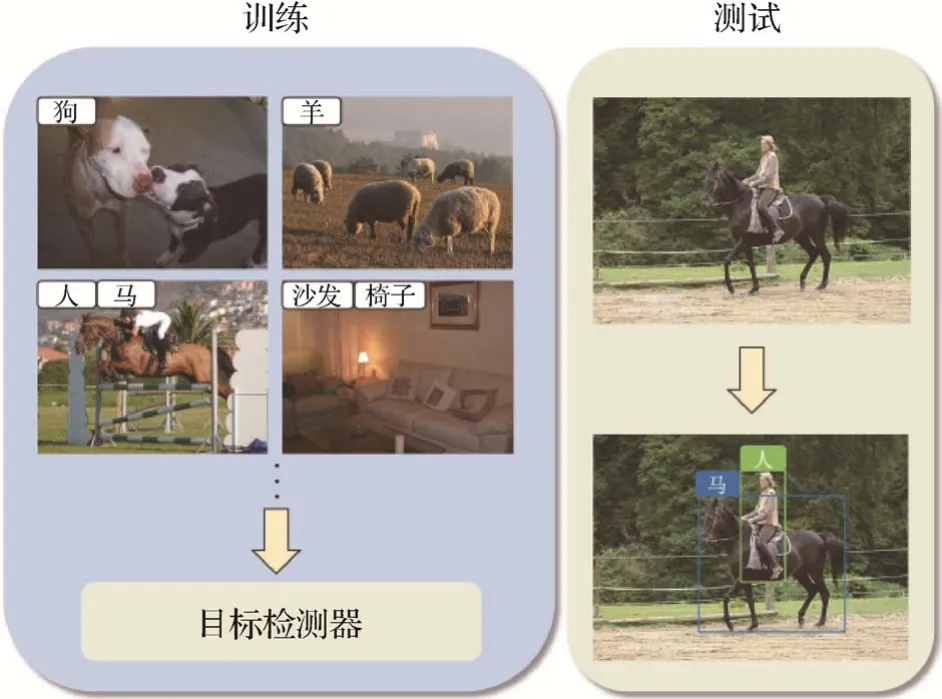
图1 弱监督目标检测训练和测试示意图Fig.1 Illustration of training and test phases in weakly-supervised object detection
1.2 基础框架
弱监督目标检测所需解决的问题与弱监督学习中的多示例学习(Dietterich 等,1997)研究目标相吻合,因此通常将弱监督目标检测视为多示例学习问题来处理。具体地,将每个候选框看做一个示例,将包含所有候选框的图像本身看做一个“包”。对于每个类别,图像中若含有至少一个该类的目标物体,则该图像为一个正包,否则为一个负包。因此,可基于图像中的候选框进行检测器参数学习。如果某幅图像被预测为某类的一个正包,则表明该图像中包含该类目标,从而可以使用矩形候选框标识出该目标。
Bilen 和Vedaldi(2016)首次提出基于多示例学习的弱监督目标检测框架。该框架的核心贡献是解决了将实例级别的候选框得分映射到图像级别的类别标记这一重要难题。具体地,该框架将经过空间金字塔池化(spatial pyramid pooling)(He等,2015)之后的候选框特征矩阵输入一个识别分支和一个检测分支。进而,在识别分支中将候选框特征矩阵使用softmax 操作映射到类别维度;在检测分支中将候选框特征矩阵使用softmax 操作映射到候选框维度。最后,将得到的两个矩阵按位相乘并计算所有候选框关于每个类别的得分之和,从而得到维度为类别数的向量,完成从候选框得分到类别标记的映射。完整框架包含以下3个主要部分:
1)候选框生成器。该部分一般采用Selective search(Uijlings 等,2013)或Edge boxes(Zitnick 和Dollár,2014)算法在输入图像上生成大量目标候选框。
2)特征提取。该部分一般采用VGGNet(Visual Geometry Group network)(Simonyan 和Zisserman,2015)对输入图像进行特征提取,再通过空间金字塔池化(He 等,2015)或感兴趣区域池化(region-ofinterest pooling)(Girshick,2015)生成固定尺寸的候选框特征矩阵。
3)检测器。如前文所述,将候选框特征映射到图像类别标记,计算多示例学习损失函数,完成对图像中目标物体的定位和分类。
尽管上述弱监督目标检测框架有效且易于实现,其检测精度较之于全监督目标检测算法仍有较大的提升空间,二者之间的差距主要归结于下面介绍的三大难题。
1.3 主要难题
在公开数据集VOC2007(visual object classes 2007)上,目前效果最好的弱监督目标检测算法的精度达到58.1%,然而全监督目标检测算法能达到89.3%。造成如此之大的差距主要归结于弱监督目标检测所面临的三大难题:
1)局部主导问题。模型更关注图像中辨识度较高的部分,而不关注整体。如图2 第3 行所示,以第2 幅图像为例,模型只能检测出人和马的头部,而无法检测出人和马的身体部分,原因在于头部往往更有辨识度。

图2 实例歧义问题和局部主导问题示意图Fig.2 Illustration of instance ambiguity problem and local dominance problem
2)实例歧义问题。对于图像中含有多个目标物体的情形,算法容易遗漏目标物体,且难以区分同类别的不同实例。遗漏物体实例的情况如图2 第1 行所示,以第1 幅图像为例,该图像中包含数量较多的天鹅,但是只有个别天鹅能够被检测出来。难以区分物体实例的情况如图2 第2 行所示,以第3 幅图像为例,该图像中存在多只羊相互遮挡。对于这种遮挡的情形,模型容易将相互挨着的多个物体实例检测为一个物体实例。
3)显存消耗问题。图像级别的标记信息决定了弱监督目标检测必须生成并处理大量的候选框,因此模型训练对于显存的消耗程度较大,导致训练和预测速度较慢。同时,由于显存消耗大,用于提取特征的主干网络往往只能采用规模较小的VGGNet(Simonyan 和Zisserman,2015),而难以采用ResNet(deep residual network)(He等,2016)等更深、更先进的复杂网络。
为了解决3 大难题并进一步提高检测精度,研究人员以1.2 节所介绍的弱监督目标检测框架为基础,从该框架的各个部分切入开展了大量的研究工作。
2 弱监督目标检测算法
本节按核心网络架构将现有弱监督目标检测典型算法分为基于优化候选框生成的算法、结合分割的算法和基于自训练的算法。其中,基于优化候选框生成的算法的核心在于改进1.2 节所介绍的基础框架中的候选框生成器。结合分割的算法和基于自训练的算法的核心皆在于改进基础框架中的检测器,区别在于前者旨在添加一个分割分支并通过分割指导检测,而后者旨在优化检测网络本身。特别地,基础框架的第2 部分,即特征提取部分,由于都是采用现有的主干网络(Simonyan 和Zisserman,2015;He 等,2016),因此不属于核心网络架构上的创新。3类算法的优缺点对比如表1所示。
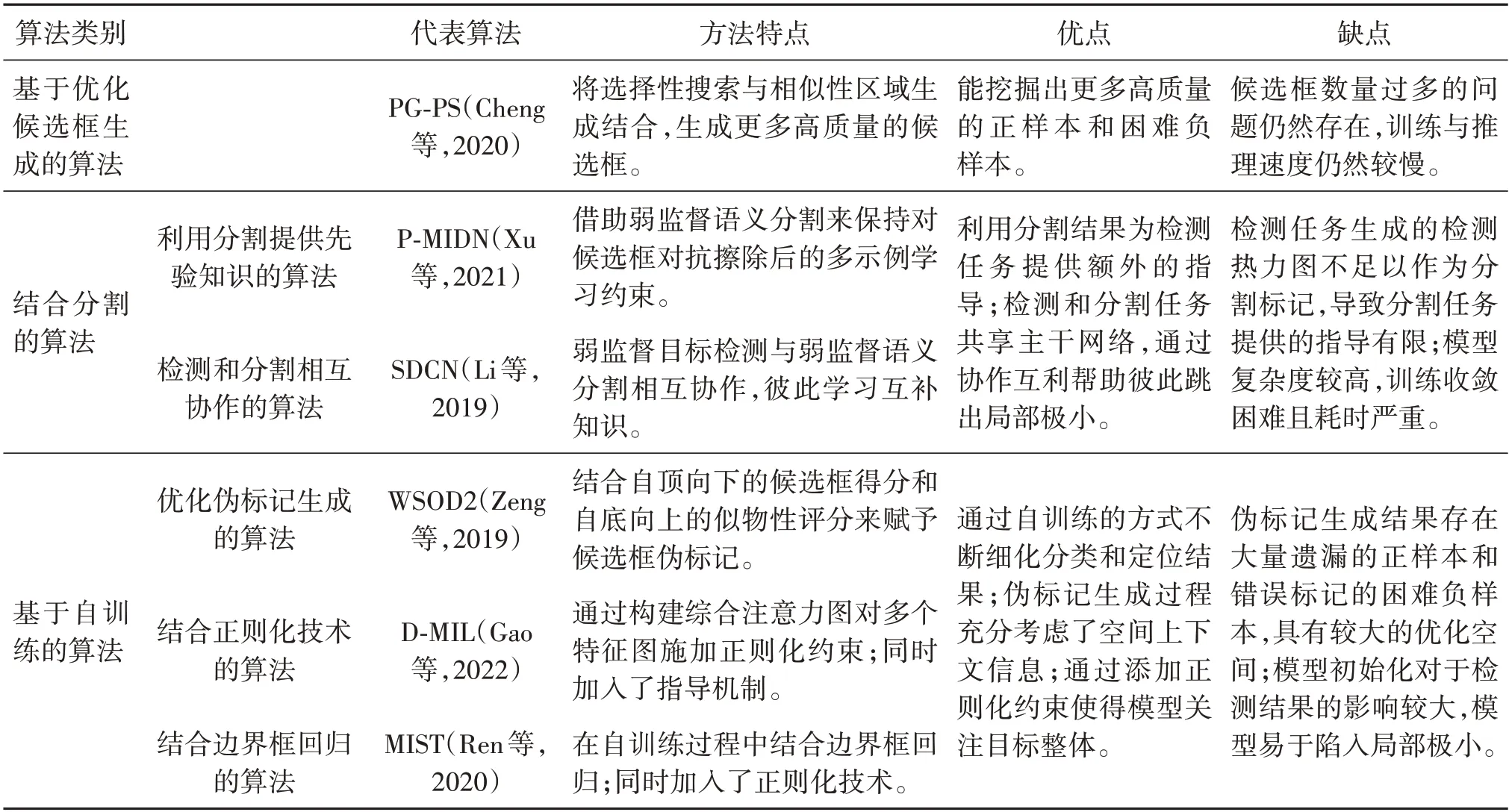
表1 弱监督目标检测算法优缺点对比Table 1 Comparison of weakly-supervised object detection algorithms
2.1 基于优化候选框生成的算法
大部分弱监督目标检测算法都是使用Selective search(Uijlings 等,2013)或Edge boxes(Zitnick 和Dollár,2014)算法来生成目标候选框,通过在一幅图像上生成数以千计的候选框来确保召回率,然而其中绝大多数候选框都属于负例,十分影响检测效果。同时,大量候选框的处理严重消耗显存,不仅难以采用ResNet(He 等,2016)等更先进的复杂网络提取特征,还会导致训练和预测速度低下。全监督目标检测中一般使用区域建议网络(region proposal network,RPN)代替传统方法(Ren 等,2015),该网络通过最小化一个前背景二分类损失和一个边界框回归损失对初始生成的候选框进行筛选和优化,从而将原本数以千计的候选框减少到数十个,大幅度提高了算法效率。然而,该方法需要借助实例级别的标记,因此无法应用于弱监督目标检测任务。针对此问题,一些学者提出了适用于弱监督目标检测的候选框生成的优化算法。Bilen 等人(2015)将该问题转化为一个凸聚类问题,利用了深度卷积神经网络(convolutional neural network,CNN)和凸优化技术结合,来学习更加精确的目标定位模型。Zhu 等人(2017)提出了一个软建议网络(soft proposal network,SPN),首次将候选框生成集成在一个端到端的卷积神经网络里。作者定义了一个软建议(soft proposal)模块,可以插入到卷积神经网络的任意一层,并且额外时间消耗几乎可以忽略不计。借助该模块,模型可以在迭代中不断优化候选区域,然后再将其映射回特征图上,最后实现网络参数的整体优化。与此同时,Wang等人(2018)、Zhang 等 人(2018d)等均通过迭代优化的方式精炼候选框。Tang 等人(2018)提出了一个基于弱监督的区域建议网络(weakly supervised region proposal network,WSRPN),该网络由3 个阶段组成,第1 个阶段利用卷积神经网络的底层语义信息来评估滑动窗口的似物性分数(objectness score);第2 个阶段通过一个基于区域的卷积神经网络分类器来优化第1 个阶段的候选框;第3 个阶段完成目标检测。Cheng 等人(2020)提出了一种高质量候选框的生成算法(proposal generation and proposal selection,PG-PS),作者将选择性搜索(selective search)(Bilen 和Vedaldi,2016)与基于梯度的类激活图(gradient-based class activation map)(Selvaraju 等,2017)相结合,从而生成比基于贪婪搜索的方法更多高交并比的候选框。针对候选框筛选,该方法对于每一个目标类别,在选取尽可能多的正样本的同时,只选取类别明确的困难负样本,并通过上调它们的权重,使模型在训练中关注更具辨识度的负例候选框,从而提高检测精度。周明非和汪西莉(2018)提出一种候选框融合算法,合并重叠候选框的同时调整候选框的位置,以此优化候选框。Jia 等人(2021)提出了一种新颖的两阶段框架,其包含一个候选框评分模块(boxes grading module)和一个信息增强模块(informative boosting module)。具体地,候选框评分模块通过训练一个弱监督目标检测模型来生成候选框并对其进行筛选和评分;信息增强模块利用候选框评分模块生成的定位监督信息训练增强的候选框生成器和检测器,从而进一步提升检测效果。Cao 等人(2021)发现许多类别存在共享特征(例如形状、纹理等)之间的相似性,这些特征可以从已有的精确标注数据中学习,并应用到其他类别上。因此在多示例学习的框架基础上提出了一种特征迁移模型,保留并微调不同类别之间的特征。区别于前人基于多示例学习的算法框架,Song 等人(2021)提出了一种基于分组标签的上下文实例特征梯度和掩码预测的方法(weakly supervised group mask network,WSGMN),利用这些掩码动态地选择最有价值的实例特征信息来识别特定的对象。图3 为弱监督目标检测基础范式,通过似物性分数、选择性搜索、基于梯度的类激活图选择和掩码预测选择等方法,达到优化候选框生成的目的。

图3 弱监督目标检测基础范式Fig.3 Illustration of the basic framework of weakly supervised object detection
2.2 结合分割的算法
如图4 所示,结合分割的弱监督目标检测算法的特点是在主干网络的基础上添加一个分割分支,希望借助分割结果来指导检测任务。结合分割做弱监督目标检测包含单向和双向两种策略,单向策略指仅利用分割给弱监督目标检测提供先验知识;双向策略是让检测和分割相互协作、共同进步。这里的分割指弱监督语义分割,分割所需的伪标记在两种策略中由不同方式生成。
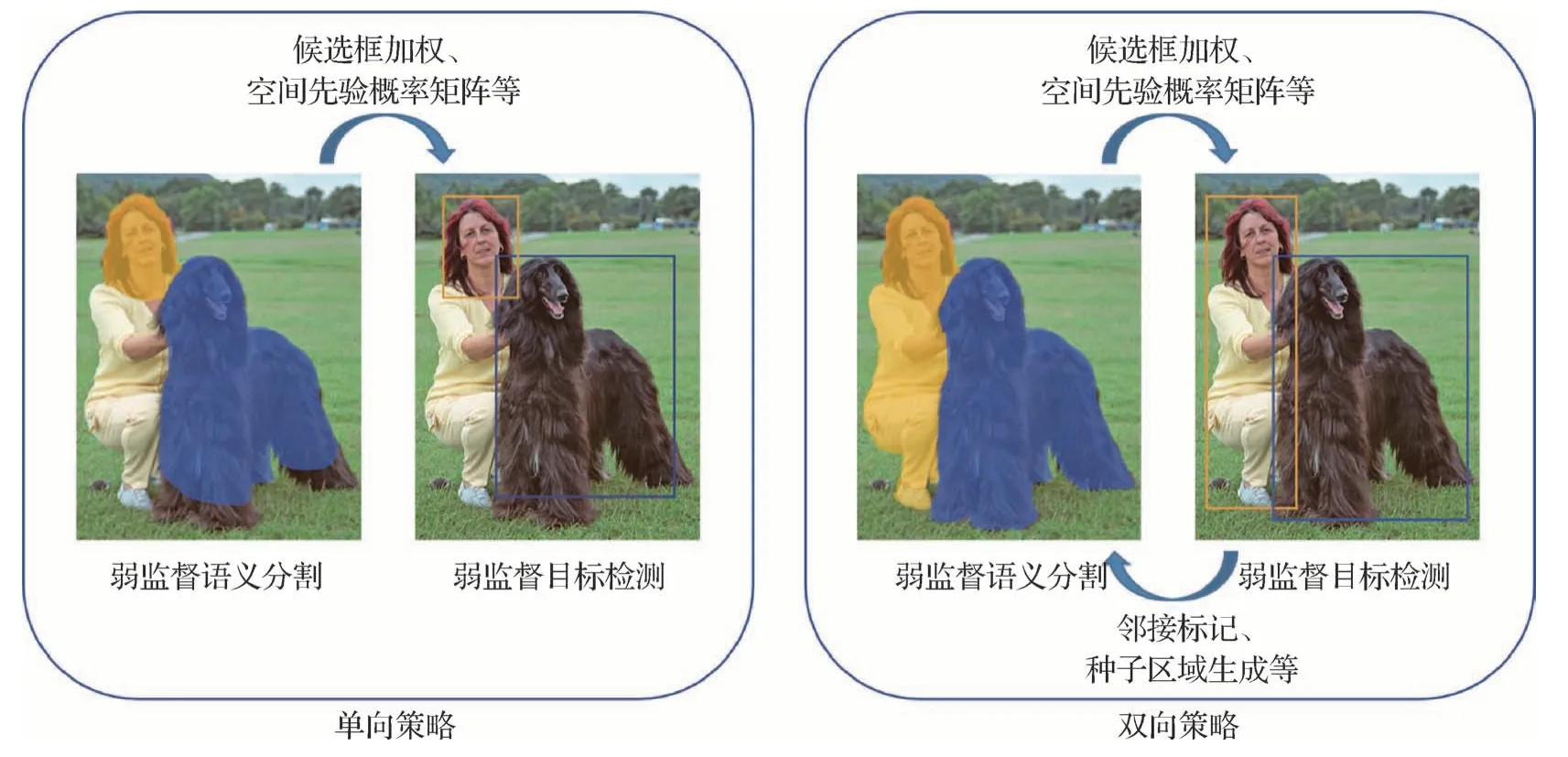
图4 结合分割算法的弱监督目标检测范式Fig.4 Illustration of weakly supervised object detection paradigm combined with segmentation algorithm
2.2.1 利用分割提供先验知识的算法
该类算法由于单方面通过语义分割来指导目标检测,因此分割所需的伪标记是由在弱监督语义分割中普遍用于生成分割标记的类激活图(class activation map)(Zhou 等,2016)提供的。Wei等人(2018a)提出了一个利用周围语境分割上下文的紧贴框挖掘算法(tight box mining with surrounding segmentation context,TS2C),该算法分为3 部分:1)训练一个分类网络生成类激活图;2)将类激活图作为语义分割伪标记来训练分割网络,生成分割置信图;3)利用分割置信图来挖掘更紧贴目标物体的候选框,从而提升检测网络的效果。Gao 等人(2022)提出了一个利用一对多示例检测网(coupled multiple instance detection network,C-MIDN)来对候选框进行对抗擦除的方法,其同时借助弱监督分割结果来保持对候选框对抗擦除后的多示例学习约束,最后通过组合两个多示例检测网络的结果,有效解决了1.3 节所介绍的局部主导问题。Xu 等人(2021)在MIDN 的基础上,受特征金字塔(Lin 等,2017)启发,提出了一种多尺度空间金字塔融合的方法(pyramidal multiple instance detection network,P-MIDN),对不同尺度的候选框检测结果进行融合,生成更高质量、更全面的伪标签。Zhang 等人(2022b)通过利用丰富的上下文关系,弥补在弱监督下监督信息的缺乏,提高学习过程的鲁棒性。
2.2.2 检测和分割相互协作的算法
该类算法旨在将弱监督目标检测和弱监督语义分割结合到一个多任务学习框架。具体而言,检测分支和分割分支相互提供指导,最终在两个任务上同时达到更好的效果。由于检测和分割之间的影响是双向的,因此分割所需的伪标记是由检测分支生成的检测热力图(detection heat map)提供的。Shen等人(2019)提出了一种结合弱监督目标检测和弱监督语义分割的多任务学习框架(weakly supervised join detection and segmentation,WS-JDS),研究表明检测任务能发现更多的目标物体,而分割任务能挖掘出更完整的目标物体。为了充分利用这两种任务学习到的互补知识,提出了一个循环引导学习(cyclic guidance learning)框架,其中检测分支为分割分支提供较好的像素种子,分割分支学习到的分割图帮助检测分支跳出局部极小值。Li 等人(2019)提出了一种分割检测协作网络(segmentation detection collaboration network,SDCN)。在该网络中,检测分支生成检测热力图为分割分支提供实例级别的监督信息,分割分支生成分割图反过来为检测分支提供空间先验概率矩阵,以指导候选框筛选。最终,检测分支和分割分支彼此紧密地相互作用并形成动态协作循环,从而相辅相成获得更好的效果。
2.3 基于自训练的算法
基于自训练的弱监督目标检测算法旨在优化检测网络本身。在1.2 节所介绍的弱监督目标检测基础框架中,检测器负责将实例级别的候选框特征矩阵映射到图像级别的类别标记,所以实际上只是一个图像级别的分类器。然而图像级别的分类器难以学习到准确的实例级别的候选框得分,为此研究人员考虑利用半监督学习中的自训练(self-training)思想来解决该问题。具体地,如图5 所示,将基础框架中的图像级分类器作为初始分类器,利用其输出的候选框得分为每个候选框生成伪标记并训练实例级分类器,最后重复该过程训练多个实例级分类器,通过这种知识蒸馏(knowledge distillation)的方式不断提炼出更准确的候选框得分。
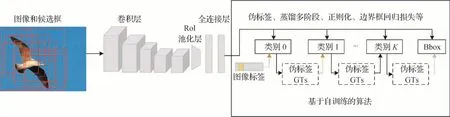
图5 结合自训练的弱监督目标检测范式Fig.5 Illustration of weakly supervised object detection paradigm combined with self-training
基于自训练的算法是弱监督目标检测领域的研究热点,按其优化检测效果的技术特点又可进一步分为优化伪标记生成的算法、结合正则化技术的算法和结合边界框回归的算法。
2.3.1 优化伪标记生成的算法
为每个候选框生成更加准确的类别伪标记可以减轻负样本过多的影响,有效解决1.3 节所介绍的局部主导和实例歧义问题,因此该步骤是自训练过程中尤为重要的一步。Tang 等人(2017)提出了一个在线实例分类器优化算法(online instance classifier refinement,OICR)。该算法首次在基础框架之上添加了k个串行的实例分类器调整模块,每个实例分类器所需的伪标记由它的前一个模块提供,其中候选框伪标记按以下规则生成:为每个类别得分最高的候选框及与其交并比高于某一阈值的候选框赋予相应的类别标记,其余候选框标记为背景。Tang 等人(2018)在OICR 的基础上提出了一种候选框聚类学习算法(proposal cluster learning,PCL),该算法将空间上毗邻且与同一物体有关联的候选框划分到同一个簇,根据聚类结果给整个簇打上类别伪标记。这种将每一个簇作为一个小的多示例学习中的“包”的方式比直接给候选框打伪标记所产生的歧义更少。Arun 等人(2019)提出了一种“差异系数”的度量,其通过衡量一个实例与整个数据集之间的相似性来优化伪标签的生成。Wan等人(2019)将多示例学习过程分为多个连续的阶段,在训练过程中连续地寻找被错误标记为背景的正样本,在每个阶段继承之前阶段的信息,从而实现正样本的挖掘。Kosugi 等人(2019)提出了一种新的候选框标记算法,该算法利用上下文分类损失来找到包含更完整物体的候选框并赋予其正标记,同时对负标记施加额外的空间约束。Kosugi等人(2019)提出了一种目标物体挖掘算法(object instance mining),该算法通过对候选框建立空间图和外观图来挖掘图像中所有可能的目标物体,并设计了一个目标物体权重重调损失函数来平衡置信度最高的候选框和区分度较低的候选框的权重。Zeng 等人(2019)提出了一种结合自底向上和自顶向下的似物性蒸馏算法(objectness distillation for weakly supervised object detection,WSOD2)。该算法首先通过图像级分类器计算每个候选框的得分,再利用每个候选框区域的低级特征来计算其似物性得分,最后将两个得分矩阵点乘得到最终的候选框得分矩阵,并据此赋予候选框伪标记。Nguyen 等人(2020)使用不确定性估计的方式对伪标签生成结果进行精炼,通过最小化信息熵,减少多种增广下的不确定性,进而达到优化伪标签生成的目的。Lin 等人(2020)通过置信度排序和选取得分最高的预设框进行实例挖掘,优化候选框的生成。Ren 等人(2020)提出了一种新颖的多示例自训练算法(multiple instance self training,MIST),该算法中的候选框伪标记生成过程同时考虑了候选框的得分、上下文以及前人没有考虑到的空间多样性约束。Zhang 等人(2020b)提出的弱监督学习框架包含了对视觉表象的认知过程(proposal and semantic level relationships,PSLR)和对提议层与语义层关系的推理过程,从而形成了新的深度多实例推理框架。具体而言,该框架基于传统的CNN 网络架构,增加了两个基于图卷积网络的推理模型,在一个端到端网络训练过程中实现目标位置推理和多标签推理。Yin 等人(2021)引入了一种类特征库(class feature banks,CFB)的方法,采用底层和高层特征,以及弱标签信息进行训练。打破现有方法仅依赖全局图像标签的局限性,使得模型可以更有效地挖掘和定位对象实例。Wang 等人(2022)提出了一种基于负确定性信息(negative deterministic information,NDIWSOD)的WSOD 改进方法,该方法包含NOI 收集和开发两个阶段,在收集阶段,设计了几个流程来在线识别和提取负面实例中的NDI;在开发阶段,利用抽取的NDI构建了一种新的消极对比学习机制和消极引导实例选择策略,分别处理部分支配和缺失实例的问题。上述算法都在一定程度上解决了局部主导问题以及更加困难的实例歧义问题。
2.3.2 结合正则化技术的算法
由于缺乏实例级别的监督信息,弱监督目标检测模型在训练时容易陷入局部极小,导致模型只关注物体辨识度较高的部分。为此,可利用正则化技术为模型引入一些额外的约束,使得模型更加平等地对待每个区域,从而缓解局部主导问题。Ren 等人(2020)在其提出的多示例自训练算法MIST 的基础上,进一步提出了一种参数化且可微分的特征空间随机失活模块(concrete drop block),该模块通过端到端的学习来鼓励模型考虑上下文而不是局限于辨识度较高的部分,从而实现目标的完整检测。Huang 等人(2020)提出了一种综合注意力自提炼算法(comprehensive attention self-distillation),该算法在OICR 的基础上(Tang 等,2020),从网络的多个层和图像的多个变换特征图上分别获得注意力图(attention map),并将这些注意力图整合为综合注意力图,然后利用这个综合注意力图对多个层和多个变换的特征图施加正则化约束,最终综合注意力图中的信息被提炼到各个特征图上,从而实现完整物体和小物体的检测。Gao 等人(2022)将差异协同模块引入多示例学习(discrepant multiple instance learning,D-MIL)中,采用多个MIL 学习器来寻找不同但互补的目标部分,并将其与协作模块融合,实现目标的精确定位。与此同时,D-MIL 实施了一种新的教师—学生模式(teacher-student),MIL 学习者扮演教师,物体探测器扮演学生。多名教师提供丰富而互补的信息,这些信息被学生吸收并传递回来,以强化教师的绩效。
2.3.3 结合边界框回归的算法
边界框回归是全监督目标检测中用于细化定位结果的一种常用手段。虽然弱监督目标检测没有实例级别的检测框标记,但是仍可以通过生成实例级伪标记来进行边界框回归。Yang 等人(2019a)提出了一种注意力引导的结合边界框回归的目标检测算法(towards precise end-to-end weakly supervised object detection,TPWSD),该算法包含一个OICR(Tang 等,2020)分支和一个边界框回归分支。两个分支共享特征提取网络,其中OICR 分支为边界框回归分支提供监督信息,同时特征提取网络通过添加一个注意力模块来为两个分支提供增强的特征图。Chen 等人(2020)提出了一种空间似然投票算法(spatial likelihood voting,SLV),该算法在OICR 的基础上添加了一个串行的空间似然投票模块,该模块以OICR 的输出为输入,进行实例挑选、空间概率积累和高似然区域投票,并将投票结果用于后续的重分类和重定位(即边界框回归)。Ren 等人(2020)在其提出的多示例自训练算法MIST 中也结合了边界框回归。该算法中的实例级分类器不仅包含一个分类分支,还包含一个边界框回归分支,每个实例级分类器所需的伪标记由前一个模块提供。该方法还进一步通过实验验证了在自训练过程中结合边界框回归有助于提高检测的鲁棒性和泛化性。Dong 等人(2021)通过利用大量未注释数据来训练一个边界框调整模型。该模型可以学习如何从粗糙(或不准确)的边界框调整到更精确的边界框。
3 实验分析
3.1 常用数据集
弱监督目标检测任务的常用数据集如下:
1)PASCAL VOC(pattern analysis,statistical modeling and computational learning visual object classes)数据集(Everingham 等,2010,2015)共分为4 个大类(交通工具、房屋设施、动物、人),并可进一步分为20 个小类。该数据集包含多个版本,其中VOC2007 和VOC2012 是弱监督目标检测领域最常用的数据集。VOC2007 训练集包含2 501 个样本,验证集包含2 510个样本,测试集包含4 952个样本,共9 963 个样本。VOC2012 训练集包含5 717 个样本,验证集包含5 823 个样本,测试集包含11 540 个样本,共23 080个样本。
2)MS COCO(Microsoft common objects in context)数据集(Lin 等,2014)共包含80 个类别。COCO数据集拥有33 万个样本,有标记样本超过20 万个。这个数据集因样本数量和类别数量较多,所以难度比VOC数据集要大。
3)ILSVRC(ImageNet Large Scale Visual Recognition Challenge)数据集(Russakovsky 等,2015)包含用于目标检测任务的200 个类别,涉及大部分生活中会见到的物体。该数据集包含多个版本,其中最常用于目标检测的是ILSVRC2013,训练集包含12 125个样本,验证集包含20 121个样本,测试集包含40 152 个样本。该数据集的难度比VOC 数据集和COCO数据集都要大。
3.2 评价指标
弱监督目标检测领域的常用评价指标如下:
1)平均精度均值(mean average precision,mAP)由准确率(precision,PR)和召回率(recall,RE)构成,常用于图像分类和目标检测任务。准确率和召回率计算为
式中,TP(true positive)表示正例样本中预测正确的样本数量,FP(false positive)表示正例样本中预测错误的样本数量,FN(false negative)表示负例样本中预测错误的样本数量。
样本预测正确是指预测框与真实框的交并比(intersection over union,IoU)≥ 0.5。交并比计算为
式中,b表示预测框,bg表示预测框所对应的真实框,AR表示区域大小。
平均精度AP的具体计算过程如下:设定一组阈值,如[0,0.1,0.2,…,1],对于召回率大于每一个阈值分别得到一个对应的最大精确率,AP就是这组精确率的平均值。最终,平均精度均值mAP就是关于所有类别的AP的均值。
2)正确定位率(correct localization,CorLoc)表示每个类别中至少有一个预测框与真实框的IoU≥50%的样本占所有样本的百分比。CorLoc是在数据集上进行评估的重要指标。
3)top 错误率(top error)包含top-1 分类错误率、top-5 分类错误率、top-1 定位错误率和top-5 定位错误率。top-1 分类错误率是指预测得分最高的候选框被错误分类的样本占所有样本的百分比,top-5 分类错误率是指预测得分前5 的候选框被错误分类(预测得分前5 的候选框里至少有一个分类正确就算做正确)的样本占所有样本的百分比。定位错误率与分类错误率类似,不同点在于前者通过IoU 来判断定位是否正确。
3.3 实验结果对比
本文选取了当前主流的弱监督目标检测算法,在PASCAL VOC2007 和VOC2012 数据集上进行了对比。为了确保对比的公平性,所有算法均采用在ILSVRC 数据集上进行过预训练的VGG16网络作为用于提取特征的主干网络,且全部只考虑模型自身的效果,不考虑集成Fast R-CNN 等全监督模型的效果(Girshick,2015)。其中,WSRPN(Tang 等,2018)、PG-PS(Cheng 等,2020)、WSGMN(Song 等,2021)属于基于优化候选框生成的算法;TS2C(Wei 等,2018a)、C-MIDN(Gao 等,2022)、P-MIDN(Xu 等,2021)属于结合分割的算法中的利用分割提供先验知识的算法,WS-JDS(Shen 等,2019)、SDCN(Li 等,2019)属于结合分割的算法中的检测和分割相互协作的算法;OICR(Tang 等,2017)、PCL(Tang 等,2018)、WSOD2(Zeng 等,2019)、PSLR(Zhang 等,2020b)、NDI-WSOD(Wang等,2022)属于基于自训练的算法中的优化伪标记生成的算法,TPWSD(Yang 等,2019a)、SLV(Chen等,2020)、D-MIL(Gao 等,2022)属于基于自训练的算法中的结合边界框回归的算法,MIST(Ren等,2020)涵盖了基于自训练的算法中的全部3 种技术。
图6展示了WSDDN、OICR 和PG-RS 算法在VOC2007 测试数据集的可视化结果,黄色矩形表示地面真实边界框。成功检测(IoU ≥ 0.5)用绿色边框标示,失败检测(IoU < 0.5)用红色边框标示。根据图6 可以看出,PG-RS 算法可以生成更紧密的边界框,实现更精确的定位,而其他两种方法不能生成过大的框或只包含对象的一部分。特别是当同一类别的多个物体出现在一幅图像中时,PG-RS 算法可以用较大的IoU 准确地检测到它们,但其他两种方法通常会有一些漏检。

图6 WSDDN、OICR和PG-RS算法在VOC2007 测试数据集的可视化结果对比图Fig.6 Comparison of visualization results of WSDDN,OICR and PG-RS algorithms on the VOC 2007 test dataset((a)WSDDN;(b)OICR;(c)PG-RS)
表2 展示了主流算法在VOC2007 数据集上的mAP 对比,其中效果最好的算法是MIST(Ren 等,2020),单模型mAP 达到了54.9%。目前先进的弱监督目标检测算法mAP 都在50%~60%,难以超过60%,与常用做基线的OICR(Tang等,2017)算法相比提高了不到15%,可见该领域尚有较大的提升空间。观察各个类别的最高AP,不难发现在船、瓶子、椅子、人和植物这几类物体上,效果最好方法的AP依然难以超过40%,原因在于这几类物体存在更复杂的形变、遮挡等问题。同时,大部分类别的最高AP出现在基于自训练的算法中,说明自训练过程是弱监督目标检测缩小与全监督目标检测之间差距的重要环节。综合整个表1可知,3类算法各有所长,并无明显的优劣,因此本文归纳的3类算法都能有效解决弱监督目标检测所面临的难题,提高检测精度。

表2 主流算法在VOC2007数据集上的mAP对比Table 2 mAP comparison of popular algorithms on VOC2007 dataset/%
表3 展示了主流算法在VOC2007 数据集上的CorLoc 指标对比,其中效果最好的算法是SLV(Chen等,2020),其CorLoc达到了71.0%,与常用做基线的OICR(Tang 等,2017)算法相比提升了10.4%。各个算法之间的CorLoc 差距并不明显,尤其是较为先进的算法,大多都在68%~71%。观察各个类别的最高CorLoc,不难发现上限较低的仍然是瓶子、椅子和人等类别,原因同样在于这几类物体存在更复杂的形变、遮挡等问题。

表3 主流算法在VOC2007数据集上的CorLoc对比Table 3 CorLoc comparison of popular algorithms on VOC2007 dataset /%
表4 展示了主流算法在VOC2012 数据集上的mAP 和CorLoc 对比,其中mAP 最高的算法是NDI-WSOD(Wang等,2022),达到了53.9%,较之于OICR(Tang 等,2017)提高了16%。CorLoc 最高的算法是P-MIDN(Xu 等,2021),达到了73.3%,较之于OICR(Tang 等,2017)提高了11.2%。由于VOC2012 数据集较VOC2007 数据集样本更多更复杂,因此在这个数据集上各方法的mAP 普遍降低,但是在VOC2007数据集上检测精度较高的算法在VOC2012 数据集上依然具有优势。
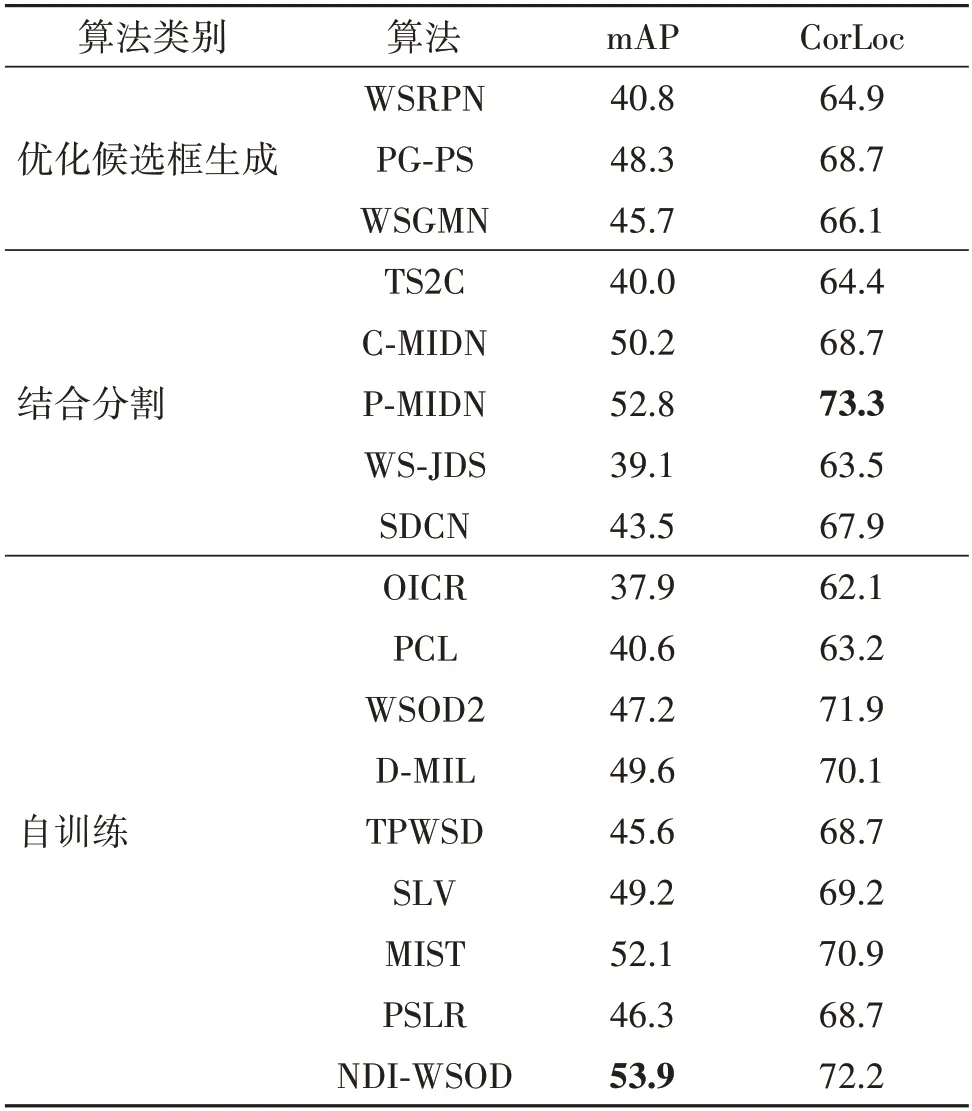
表4 主流算法在VOC2012数据集上mAP、CorLoc对比Table 4 mAP comparison and CorLoc comparison of popular algorithms on VOC2012 dataset /%
此外,本文选取了部分算法在MS COCO 数据集上进行对比,结果如表5 所示。由于COCO 数据集样本数量大、种类多,因此现有算法很难获得较高的检测精度。如表5 所示,ValAP50最高的算法是PMIDN(Xu 等,2021),达到了27.4%。其中ValAP 表示验证集上的平均精度,ValAP50表示在IoU 阈值为50%时验证集上的平均精度。

表5 主流算法在COCO数据集上ValAP、ValAP50对比Table 5 ValAP comparison and ValAP50 comparison of popular algorithms on COCO dataset /%
4 未来研究方向
得益于深度学习的蓬勃发展,基于图像级别标记的弱监督目标检测算法研究取得了较大突破。然而弱监督目标检测仍然面临诸多难题,其与全监督目标检测相比还有一定的差距。本领域一些有价值的未来研究方向包括:1)现有算法大多采用Selective search(Uijlings 等,2013)或Edge boxes(Zitnick和Dollár,2014)来生成初始候选框,然而这两种方法极为耗时且生成的绝大多数候选框属于负例。因此,如何生成数量更少、质量更高的候选框,是一个亟待解决的问题。2)由于检测热力图过于粗糙,不足以作为分割标记,所以现有的检测和分割相互协作的弱监督目标检测算法并不能很好地利用检测指导分割。因此,可以考虑设计更合理、更高效的检测分割协作机制。3)自训练过程中的伪标记生成是基于人工设计的策略实现的。尽管现有算法已借助多种手段来优化伪标记生成,但该步骤仍会遗漏大量正样本和错误标记大量负样本。因此,怎样设计更合理的策略或通过网络本身来挖掘出更多、更好的正样本,是一个值得深究的问题。4)现有的弱监督目标检测算法的网络模型复杂度较高。由于只有图像级别的监督信息,导致网络模型不得不通过增加复杂度来换取更高的精度,从而大大增加对硬件的需求。因此,设计轻量级的、能够应用于移动端的网络模型同样具有重要的研究价值。
5 结语
基于图像级别标记的弱监督目标检测算法对于标记信息的要求较低,能够显著降低训练样本的获取代价,因此具有重要的研究意义。本文首先介绍了弱监督目标检测的问题定义、基础框架和面临的主要难题。然后按核心网络架构将现有典型算法归纳为基于优化候选框生成的算法、结合分割的算法和基于自训练的算法,并分析了各种算法的特点及其优缺点。进一步,在多个公共数据集和多种指标上对主流算法进行了效果验证和比较,得出结论:本文归纳的三大类算法均可在一定程度上解决该领域所面临的主要难题并提高检测效果,其中目前效果最为显著的是基于自训练的算法。最后,根据现有算法的不足,并以进一步解决主要难题为目标,提出了该领域的一些有价值的未来研究方向,供相关研究人员参考借鉴。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
计算机工程与科学(2021年4期)2021-05-11 01:59:36
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
火力与指挥控制(2018年3期)2018-04-19 11:43:39
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
