
基于关系影响的加权知识图谱卷积网络推荐模型
2023-09-25 03:39肖秋实张帆
电脑知识与技术 2023年22期
肖秋实,张帆
(黄冈科技职业学院,湖北 黄冈 438000)
0 引言
随着科技进步,人们可以通过网站快速访问大量在线内容,如新闻、电影和在线购物。如何有效获取这些线上平台所存在的海量信息,一直是理论和实践所关注的热点和难点。推荐系统已经广泛应用在实际生活中的很多场景,特别是个性化推荐系统已经有越来越多的研究工作和落地实践,但是仍然面临一些问题,例如数据稀疏、冷启动等问题。为了解决上述问题并减轻海量信息超载对信息获取效果的不利影响,需要深入研究信息内容要素,并揭示要素之间的关联关系。
近年来,研究者们将知识图谱作为辅助信息整合到线上网站平台的推荐系统中,从而提高推荐系统的准确性,使得推荐结果更加精准和个性。知识图谱是一种常用于表示实体之间关系的有效工具,通过将物品和属性信息映射到知识图谱当中,帮助我们了解物品之间的相互关系;还可以将用户及其辅助信息整合到知识图谱当中,更加精准地捕捉user与item之间的关系以及用户的喜好。而目前的知识图谱嵌入方法主要着重于对语义关联的建模,更适用于知识图谱补全和链路预测等图应用[1]。这些方法对于推荐系统来说并不太适用。推荐系统需要考虑更多因素,如用户的历史行为、偏好和上下文信息等,而现有的知识图谱嵌入方法未能充分利用这些信息。因此,为了适应推荐系统的需求,需要开发新的方法将知识图谱与推荐系统进行有效结合。
在图嵌入的方法中,图的建模和特征表示与下游任务是独立的,首先在传统的KGCN(Knowledge Graph Convolutional Network) 模型中,特征表示中采用是n阶实体邻域聚合表示,但是其不同阶之间的权重系数皆为1,这显然不合适;其次,目前的KGCN模型中,用户关系评分没有考虑用户和关系的单独影响;最后,不同的激活函数会保留当前参数的不同特性,目前的KGCN模型中没有很好地考虑这一点。为了解决上述问题,本文提出了一种基于不同阶带权实体邻域聚合特征,重构用户关系评分函数和合理的激活函数选择的WKGCN(Weighted knowledge graph convolutional network) 模型。
WKGCN 中,实体表示学习的过程根据不同阶聚合的邻居节点数,计算不同阶实体邻域聚合的权重,并根据需要选择适当的激活函数来考虑用户和关系对评分的影响。这种方法的主要优点是:1) 使当前实体获得更准确的表示,能够更好地捕捉实体之间的关系和特征,从而提高推荐的准确性。2) 根据参数的不同特性,选择不同的激活函数,从而使当前特征获得更准确的表示,进而提高推荐准确性;3) 考虑用户和关系单独对评分的影响,可以更加充分地利用知识图谱中的用户和关系。
1 相关工作
目前,国内外现有的基于知识图谱的推荐系统的主流技术如下:1) 基于协同过滤的推荐系统(Collaborative Filtering, CF)[2]。协同过滤算法是一种基于相似度度量的推荐方法,它通过考虑user之间或item之间的相似度来进行相关推荐。2) 基于内容的推荐系统(Content-based Filtering, CB)[3]。基于内容的推荐方法则是从item的内容信息中学习user和item的表示,主要关注item的特征和属性,例如文字描述、标签、图片等,通过分析这些内容信息来理解user和item之间的关系,并进行个性化推荐。3) 混合推荐系统(Hybrid Method)[4]。混合推荐系统将基于内容的推荐系统中的用户和物品信息与协同过滤方法相结合。混合推荐系统将用户和物品的内容信息(用户辅助信息和物品辅助信息)整合到协同过滤框架中,从而可以提供更好的推荐性能。通过在协同过滤方法中引入内容信息,混合推荐系统能够更好地理解用户和物品之间的关系,并且能够在冷启动和数据稀疏的情况下提供更准确和个性化的推荐结果。这种方法能够有效地弥补协同过滤的不足,提高推荐系统的性能和用户满意度。
相关研究虽然已经提出了许多新的模型来利用KG 作为推荐的辅助信息,但仍存在一些机会。在此概述和讨论一些未来的研究方向。
动态推荐[5]:现有的大多数方法都是采用用户的静态偏好推荐。然而,在某些情况下,如在线购物、新闻推荐、Twitter 和论坛,用户的兴趣可能会很快受到社会事件或朋友的影响[6]。在这种情况下,使用静态偏好建模的推荐可能不足以理解实时兴趣爱好。为了捕获动态偏好,利用动态图网络可以作为一种解决方案。
跨领域推荐[7]:由于不同领域的数据信息不一致,交互数据也不等同。例如,在亚马逊平台上,图书评论比其他领域更多,然而不同领域的交互数据可以互为补充,因此通过迁移学习等技术,可以共享源领域数据相对丰富的交互数据,以便更好地推荐目标领域。
知识增强的语言表示:增强知识的文本表示策略应用于推荐任务中,可以更好地学习user/item 表示,获得更准确的推荐结果。
知识图谱Embedding 方法(一种将高维数据转换为低维表示的技术):虽然现在已经将KGE 方法应用到上述基于知识图谱的推荐系统中,然而,没有一些研究工作表明在数据源、推荐场景和模型架构等不同情况下,应该采用何种特定的 KGE方法。因此,另一个研究方向是比较不同KGE 方法在不同条件下的优势。
综上,知识图谱卷积网络(KGCN) 是一种自动捕捉KG 中高阶的结构信息和语义信息的推荐方法[8]。其关键思想是在计算KG 中给定实体的表示时,将具有偏差的邻域信息进行汇总和合并。目前,传统的KGCN模型尚需要进一步完善,针对相关不足,本文尝试做了相关的改进:1) 传统的KGCN模型只考虑了用户与关系之间的相互依存的关系,并未考虑用户与关系单独对评分的影响,本文拟考虑用户与关系的依存关系和它们单独对评分的影响;2) 传统的KGCN模型选用的激活函数relu是线性激活函数,它极大可能地保留了当前参数的线性特征,而传统的KGCN模型中有部分特征需要更大可能地保留非线性部分,本文拟对传统的KGCN模型中激活函数进行改进;3) 传统的KGCN 模型尚未充分考虑实体领域阶数及其重要程度,本文拟基于不同阶的实体领域需要聚合的邻居个数来设置不同权重,用这个权重来体现实体领域阶数的重要程度。基于上述传统KGCN 的不足及相关途径,本文提出了WKGCN模型,以进一步提高推荐的精确性。
2 模型构建
传统的KGCN 推荐系统的核心是基于输入的知识图谱,以用户某项目为中心,求该项目的邻域。WKGCN可以在知识图中捕获实体之间的高阶结构重要性,考虑了用户和关系对用户评分的单独影响。
2.1 问题公式化
在WKGCN模型中,可将知识图谱视作有权图,也即将关系转化为权重。该权重可被理解为相应关系对用户选择行为的影响程度。例如用户是更喜欢通过相似演员还是更喜欢通过相似题材寻找喜欢的电影,所以该权重也是节点间消息传递的权重。
2.2 WKGCN图层
在WKGCN模型中,U用户是,用户向量表示为u,物品为V,物品向量表示为v,最基本的公式还是:
f(·)是任意函数,是预测的值,例如预测用户U对物品的点击率。
图1中间节点指的就是要推荐的目标电影V,每条边用一个权重w来表示:
u是用户向量,ri是连接第i个邻居之间的关系向量。g(·)是任意函数,Ri表示关系,wv Ri即表示目标用户u对关系Ri的偏好程度,也就是经过Ri边时消息传递的权重。每次消息传递都加入了用户向量,所以结果比自然提取关系向量ri更能体现用户U的注意力。公式(2) 反映了用户和关系之间相互依赖的关系,但是忽略了用户和关系单独对用户评分之间关系,所以对公式进行改进。
g1是积函数,g2是和函数,积函数的激活函数是celu,最外层的激活函数选用的是selu,接下来对wvRi进行Softmax操作归一化:
其中,N(V)代表节点V的一阶邻居集,然后进行一次加权求和的操作得到新的特征向量͂:
ei代表第i个邻居的特征向量。根据图采样的思想,消息传递由内而外进行。例如,在进行图中的节点e5,e6,e7,e8传递到e1时,那么就代入公式(4) 中,得到e1消息聚合后的特征向量,最终传递给中心位置V,得到特征向量͂。此时的还不是最终物品V的特征向量v,͂与v还必须进行另一次消息聚合,经过一次或多次全连接层的操作,该过程被描写为:
elu是激活函数,W是线性变换矩阵,b是偏置项。而agg(͂,e)表示对物品V 在做一次消息聚合,不带下标e就是物品V的初始特征向量。
本文KGCN中考虑了以下三种类型的聚合器:
和聚合器采用两个表示向量的求和,即将͂+e对应元素位相加:
共线性聚合器首先连接这两个表示向量,即将向量͂与e向量拼接起来,W是线性变换矩阵,b是偏置项的维度,也发生相应的变化。
邻域聚合器直接采用实体͂的邻域表示作为输出表示:
将聚合好的向量代入公式(6) ,得到这一轮物品V的向量v,然后代入公式(1) 得到推荐值,与真实值建立损失函数yuv:
在WKGCN的训练过程中,为了提高计算效率,采用了负采样技术。在负采样中,使用交叉熵损失函数作为目标函数,其中,负样本的个数(Tu) 与用户(u) 正样本的个数相同。负样本的分布(P) 被设为均匀分布。此外,还添加了L2正则项作为正则化项,以防止过拟合。激活函数被设置为crelu 函数。通过这些技术和设置,可以更有效地进行训练。
在模型的一层中,实体的表示只依赖于自身及其邻域,这被称为一阶实体表示。其中vagg表示项目v的一阶表示,又记为v1。通过将每个实体的初始表示(0阶表示)与其邻域实体的零阶表示进行聚合,可以得到一阶实体表示。为了扩展模型到多个阶层,首先获取项目的一阶邻居,然后通过一阶邻居找到项目的二阶邻居,并将二阶邻居的实体信息聚合到二阶邻居实体中。再将一阶邻居的实体进行聚合,得到项目v 的二阶表示v2。一般来说,一个实体的P 阶表示是指它自身与其P层范围内的实体的聚合,将该项目的阶表示视为最终的项目表示vp。
2.3 实体领域阶数与其重要程度
实体领域阶数与其重要程度考虑到不同阶的实体领域实体对该实体的影响程度是不同的,所以用同一权重系数来获取不同阶的实体领域就不合适,对此本文根据不同阶的实体领域给予不同的权重进行聚合。
wu为项目v的u阶实体领域对项目v的权重系数,将得到的eus(e)代入聚合器函数e中进行聚合。
3 结果分析
通过收集在真实的电影和音乐网站中的推荐场景中的相关数据集,我们将对比本文提出的加权知识图谱卷积网络模型与传统相关模型,以评估本文提出模型的有效性。通过比较这些模型在推荐任务上的性能,我们可以得出结论。这将帮助我们确定加权知识图谱卷积网络模型是否在电影和音乐推荐领域具有优势以及它是否能够提供更好的推荐效果。
3.1 数据集
本文实验选择了两个基准数据集,分别来自电影领域和音乐领域,并且这两个数据集的规模存在较大的差异。通过使用这两个数据集进行对比分析,可以对加权知识图谱卷积网络模型在不同领域的表现进行评估。MovieLens的数据来自MovieLens 网站,评分范围为 1 到 5;Last.FM数据来自在线音乐系统。数据集的具体统计结果见表1。
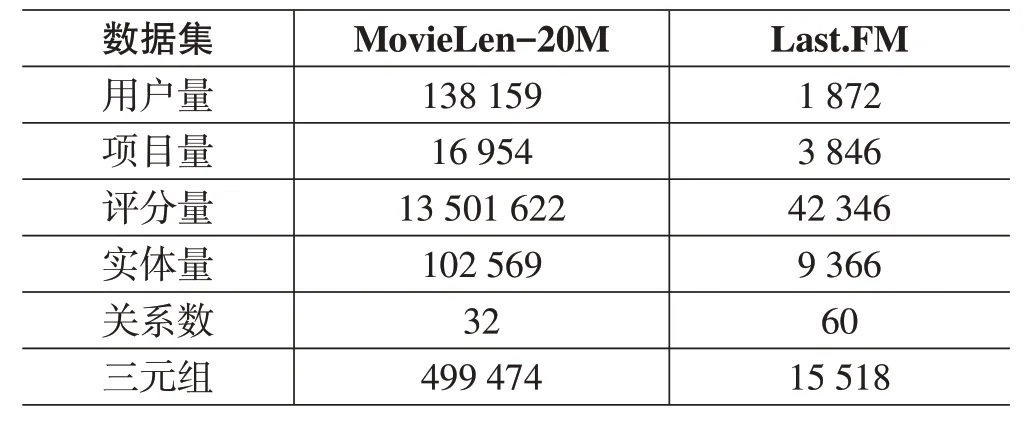
表1 数据集统计
3.2 基线
将本文中提出的模型与多个基线模型进行对比,并且在两个数据集上进行结果比较。通过与这些基线模型进行对比,可以评估本文模型在两个数据集上的相对性能。这将帮助我们了解本文模型是否在电影和音乐领域中具有优势,并且在不同数据集上的效果如何。
1) 本文第一个基线模型是 Personalized Entity Recommendation (PER)模型。PER 模型通过将用户的兴趣路径映射到知识图谱中的实体来进行个性化的推荐。通过这种方式,PER模型能够根据用户的兴趣和全局的知识图谱信息进行推荐。
2) 第二个基线模型是Collaborative Knowledgebased Embedding (CKE)。该模型利用TransE 模型来表示知识图谱,并将其与文本和图像信息相结合,共同学习用户和项目的表示。CKE 模型通过将知识图谱中的实体和关系映射到低维空间向量表示,并将这些向量与文本和图像特征结合,从而能够更全面地理解用户和项目的特征。通过这种融合多模态信息的方法,能够提供更准确的个性化推荐。
3) 第三个基线模型是LibFM。该模型采用了基于特征的因子分解机(Factorization Machines) 的方法,并将其应用于点击率预测任务。LibFM 模型通过将特征表示为向量,然后使用因子分解机模型对特征进行建模。这个模型可以捕捉到特征之间的交互作用,并预测用户点击某个项目的可能性。通过利用因子分解机的优势,LibFM 模型能够提供准确的点击率预测结果,从而在推荐系统中发挥重要的作用。
4) Wide&Deep是一种通用的深度推荐模型,它将传统的线性模型和深度模型相结合。这种模型结合了两种不同的方法,既能充分利用线性模型对特征之间的关联进行建模,又能通过深度模型学习更高层次的特征表示。通过结合这两种方法,Wide&Deep模型能够提供更准确和多样化的推荐结果。
5) RippleNet是一种推荐模型,它采用了一种类似于内存网络的方法。模型利用知识图谱中的信息来传播用户的喜好,并基于这些传播结果进行推荐。通过这种方式,RippleNet能够充分利用知识图谱中的上下文信息和关联关系,从而提供个性化的、更有针对性的推荐结果。这种方法使得RippleNet 在推荐系统中可以更好地理解用户的偏好和需求,提供更准确的推荐服务。
6) KGCN 是一种推荐系统模型,它利用图卷积网络来挖掘项目在知识图谱上的信息。该模型通过对知识图谱进行建模和分析,可以揭示项目之间的关联和特征。基于这些关联和特征,KGCN 能够提供更准确和个性化的推荐结果,使用户可以发现与其兴趣和喜好相关的项目。通过应用图卷积网络的技术,KGCN 在推荐系统中具有很高的灵活性和可扩展性,提升了推荐算法的效果和用户体验。
3.3 实验设置
在WKGCN 中,超参数通过优化验证集上的AUC来确定。对于每个数据集,训练、测试、验证集采用6:2:2 的比例随机生成,并报告平均性能。在以下实验环境下评估本文的方法:Python 3.7,TensorFlow 1.15.0,和 NumPy 1.14.3。
WKGLN的实验准备如下:在WKGLN中,将 MovieLens-20M 的跳数H 设置为 2,而Last.FM 的跳数设置为1,其他超参数的设置如表2所示。
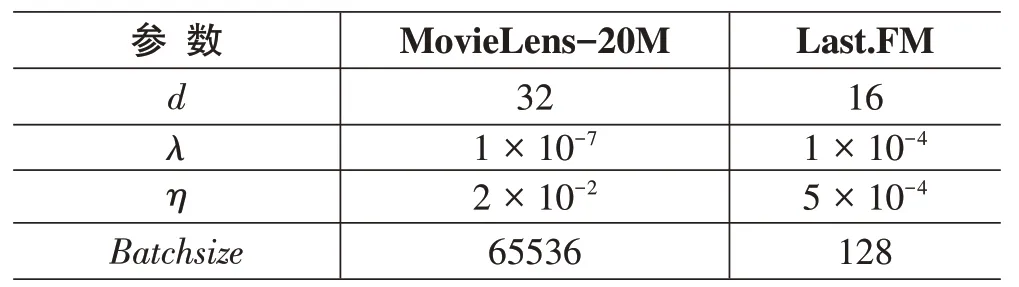
表2 WKGCN的超参数设置
d表示嵌入向量的维度,λ表示正则化参数,η表示训练速率。
3.4 分析结果
WKGCN 模型与其他基线模型比较结果如表3所示。

表3 WKGCN模型与基线的精确率
在实验结果中观察到,本文提出的WKGCN 模型在性能上普遍优于基准实验,它在两个数据集上都展现出了提升。然而,PER的性能较差的原因是它过于依赖专家知识,需要基于元路径挖掘知识图谱中的信息。CKE的推荐性能并不理想,这可能是因为在推荐系统实验中没有充分利用图像和文本信息。CKE 模型主要利用了预训练的实体表示方法(如TransE) 来捕捉知识图谱中的信息,但这种表示方法可能无法很好地利用知识图谱的详细信息和上下文关系。
而LibFM 和Wide&Deep 方法在推荐系统中表现出色,相对于其他结合知识图谱的方法,它们更有效地利用了知识信息。RippleNet 模拟了用户兴趣在知识图谱上的传播过程,但未考虑到待推荐项目的图谱信息,导致部分特征缺失。而KGCN通过图卷积网络获得了项目的向量表示,但未有效考虑不同阶的聚合邻域信息对项目的重要性、用户-关系对用户评分的影响以及不同激活函数对特征保留的差异。
相比以上模型,WKGCN 选择性地与实体聚合不同阶的邻域信息,考虑了不同的激活函数对特征保留的影响以及用户-关系对评分的影响。实验结果证明,相较于KGCN,WKGCN 有效地利用了用户-关系对评分的影响、激活了函数的特性和实体邻域的信息。
4 结论及展望
本文提出了推荐系统的加权知识图卷积网络(WKGCN) 模型。该模型在知识图谱关系下,首先考虑用户关系对用户关系评分的双重影响和单一影响,再通过加权聚合形成一阶特征向量表示,通过迭代拓展到高阶特征向量表示,不同阶特征表示对总特征影响不同,进而引入加权思想,完成高阶特征向量嵌入,并选择合适的激活函数,以提高推荐的精确性。基于两个实际数据集,该模型与六个基线模型进行比较,实验结果显示该模型可有效提高推荐的精确性。
未来需要进一步改进的方面:1) 本文提出的模型是均匀地从一个实体的邻居中采样来构造该实体的接受域,将尝试利用非均匀采样器(例如,重要性采样),以进一步提高模型的效率;2) 本文将知识图谱视为带权图,将尝试利用图深度学习模型,揭示节点间的结构性关联关系,以进一步提高推荐的精确性。
猜你喜欢
少先队活动(2020年12期)2021-01-14
吉林大学学报(理学版)(2020年3期)2020-05-29
中国外汇(2019年18期)2019-11-25
自动化学报(2018年7期)2018-08-20
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
周口师范学院学报(2016年5期)2016-10-17
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
