
结合长短时记忆网络和宽度学习的股票预测新模型研究
2023-09-25 02:32孙凯强谈昊然
运筹与管理 2023年8期
韩 莹, 张 栋, 孙凯强, 谈昊然, 陆 超
(1.南京信息工程大学 自动化学院,江苏 南京 210044; 2.北京交通大学 经济管理学院,北京 100004)
0 引言
股票市场是资本市场的核心组成部分[1]。股票关注的重点之一就是股价的走势和未来趋势预测。股票市场的数据具有非线性、多尺度的特点,传统的金融计量方式存在大量的局限性,SEZER等[2]证明深度学习预测的结果优于传统的机器学习。
RNN(Recurrent Neural Network,循环神经网络)及其扩展模型,如LSTM(Long Short-Term Memory,长短期记忆网络),GRU(Gate Recurrent Unit,门控循环单元)等,近年被用于进行股票预测。丁文绢[3]利用ARIMA模型与LSTM模型分别对上证A股50的历史交易数据进行训练预测比较,得出LSTM模型在股票预测精度方面优于ARIMA模型的结论。NIKOU等[4]通过对比证明LSTM预测模型在股票预测中相比SVR(Support Vector Regression,支持向量回归)、随机森林和神经网络模型有更高的预测精度。罗鑫和张金林[5]引入CNN(Convolutional Neural Networks,卷积神经网络)并与LSTM相结合,提出多时间尺度CNN-LSTM模型,改善了对沪深300指数涨跌预测的效果。乔若羽[6]分别将RNN,LSTM,GRU与注意力机制(Attention Mechanism)机制相结合,并通过对比单一模型证明了注意力机制与深度学习相结合,提高了股票预测的准确性。
LSTM网络具有的优势使其被广泛用于金融预测,且复合模型相比单一的LSTM模型更有优势。但金融序列中的噪声对精确预测有很大挑战。ZHANG等[7]构建了深度学习复合预测模型,分别将EMD(Empirical Mode Decomposition,经验模态分解),EEMD(Ensemble Empirical Mode Decomposition,集合经验模态分解),CEEMD(Complementary Ensemble Empirical Mode Decomposition,互补集成经验模态分解),提取抽象、高级特征,并将其用于单步向前股票价格的预测。并得出CEEMD-LSTM模型能有效地提高股票指数的收益率预测精度的结论。REZAEI等[8]提出新的混合算法,构建了CEEMD-CNN-LSTM与EMD-CNN-LSTM模型,为股票预测提供了更有效的方法。WEI等[9]提出了一种混合模型,将CEEMD算法、模糊时间分析技术和LSTM模型复合。实验结果表示混合算法的每个部分都可以在很大程度上提高预测能力。
LSTM结构特点造成了其易陷入局部最优、具有时滞性的缺点,从而影响股票价格的预测精度。近年来,BLS (Broad Learning System,宽度学习系统)的提出为预测提供了新的解决方案[10],且实验证明了BLS采用的随机设置权重训练出的模型已经能达到与深度学习相当的分类准确率,且建模时间远小于深度学习。CHEN等[11]在理论角度证明了在时间序列的预测上,BLS具有良好的函数逼近能力,通过实验证明其在回归性能上优于现有的几种学习算法。
综上分析,本文首先尝试将深度学习与宽度学习相结合用于股票价格预测问题,提出了LSTM-BLS股票价格预测模型。模型将LSTM模块的输出特征交于BLS进行承接处理,以防止模型出现局部最优。进一步地,考虑到股票价格序列的非线性、非平稳特点,引入了时频分析中的CEEMD模块,提出了CEEMD-LSTM-BLS(C-L-B)股票复合预测模型。据笔者所知,本文新提出的两类深度、宽度融合的预测模型都是首次应用于股票价格预测中。
为了验证本文提出模型的有效性,选取了我国农林牧渔行业股票收盘价作为实例验证。分别选择三个性能指标平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2_score)评估算法性能。首先,证明了三个评价指标上,本文提出的LSTM-BLS模型不但在预测精度方面明显优于ARIMA,SVM等基线模型,而且也高于已有的LSTM,CNN-LSTM以及Attention-LSTM等股票价格预测模型。特别地,当股票数据出现较大波动时,现有的CNN-LSTM模型出现了拟合程度差的现象,Attention-BLS模型则出现了滞后现象,但新提出的LSTM-BLS模型即使在数据较大波动时,仍然很好的拟合了真实值,且避免了滞后现象。
通过对比EMD-LSTM,EEMD-LSTM与CEEMD-LSTM三个预测模型的预测精度,证明了CEEMD在股票收盘价分解上的优势。进一步融合了CEEMD模块后,C-L-B的预测精度与LSTM-BLS模型相比进一步提升。特别地,为了验证BLS在LSTM预测精度方面的提升,将C-L-B模型与不融入BLS的CEEMD-LSTM模型分别对经CEEMD分解后的分量的预测结果进行对比。结果表明,分解后的信号仅通过LSTM模型进行预测会存在一定的误差,且越是拐点处,预测误差越明显,越是高频分量,预测误差越大,而C-L-B模型中的BLS模块能够适当解决这类精度问题。在三个评价指标上,C-L-B相比现有的CEEMD-CNN-LSTM这类“分解-预测-整合”股票价格模型的预测精度也有相应的提高。同样地,在数据波动较大时,C-L-B的预测优势与现有模型相比,更为明显。
注意到,C-L-B模型的MAE与RMSE的值均未超过0.01,R2_score达到了0.9924。对于股票价格这种受多种因素影响,波动较大的预测问题,本文模型在只考虑单一收盘价历史数据的前提下,能达到这样的预测精度,证明了本文模型的有效性。本文提出的深度+宽度预测模型架构给出了时间序列预测模型架构的新思路,不但可以应用于股票预测,亦可应用于其他序列数据。
1 模型结构
本节主要首先回忆了本文模型所需要的一些基本模型原理及结构。接着给出了本文提出的两个新的股票预测模型结构。
1.1 基本原理及应用
LSTM由遗忘门ft、输入门it和输出门ot构成,其数学原理运算公式如式(1)~(5)所示。
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(2)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(3)
ot=σ(Wxoxt+Whoht-1+bo)
(4)
ht=ot*tanh(ct)
(5)
其中Wxi,Wxf,Wxc,Wxo分别表示对应单元的权重矩阵,bi,bf,bc,bo分别表示对应的偏置向量,*表示矩阵的Hadamard积。
CEEMD在原始信号中加入一组正负相反的白噪声信号来改变信号的极值点分布,之后进行EMD分解。CEEMD分解的步骤如下:
(1)在原始信号中加入符号相反的多组噪声信号,每次加入幅值相同的新噪声(式(6)、式(7))。
(6)
(7)
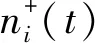
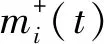
(3)最终的分解结果为两组IMF分量的集成平均值。
2018年陈俊龙提出了不需要深度架构的增量学习系统—宽度学习系统。BLS提供了很好的泛化能力,若网络需要扩展,BLS网络可以快速重构,无需重新训练过程。用BLS承接深度模型能有效降低模型的复杂度,一定程度上防止LSTM在训练过程中出现过拟合、滞后的现象。BLS具体运算流程如下:
(1)输入数据X先进行处理(特征提取),把输入数据映射为n个映射节点,记作Z1,Z2,…,Zn。其中,Zi如式(8)。
Zi=φ(XWei+βei),i=1,…,n
(8)
(2)把Z1,Z2,…,Zn乘上一组随机权重W再加上偏置(bias),激活函数处理后作为增强节点,记作H1,H2,…,Hm。其中,Hm如式(9)。
Hm=ξ(ZnWhm+βhm)
(9)
(3)最后把Z1,Z2,…,Zn与H1,H2,…,Hm合并,记作A=[Z|H],输出Y=AW。
1.2 深度和宽度融合的股票预测新模型
融合深度和宽度学习的优势,提出了LSTM-BLS股票价格预测模型。并进一步引入了CEEMD模块对股票序列进行降噪提升预测精度,提出CEEMD-LSTM-BLS股票预测模型(其映射原理图见图1),具体流程如下。

图1 C-L-B模型的映射原理
首先,在信号分解前采取将数据限定在一定范围内,即归一化处理。归一化的股票收盘价数据投入分解模块,通过CEEMD算法将数据分解成多个IMF分量。
其次,将分解得到的序列分别输入LSTM-BLS预测模块进行训练。分解后的序列分别输入LSTM模块提取出投入分量的简单特征、抽象特征,形成映射节点。再通过BLS层进行训练,再次提取特征,同时自动生成增强节点,更新权重以及偏置,输出各个分解模块预测结果。
最后,不同序列的预测结果求和,得到最终的预测结果。
2 实验验证
2.1 数据准备与预处理
本文选取的农林牧渔指数(399231)收盘价数据来自于国泰安数据库(CSMAR)。时间选自2005年6月7日至2020年11月26日,将空缺数据排除,只留交易日数据,共3761组数据。设置时间分割点将处理好的数据划分成训练集和测试集,本文选取前90%作为训练集,剩下的10%作为测试集。为将寻优过程变得平缓,先将数据通过转换函数做归一化处理。其中转换函数如式(10)。
(10)
其中,xmax,xmin分别为分量内最大最小值。
2.2 实验设置
对于本文模型所涉及到的参数,首先,不对CEEMD模块的参数进行修改,自行分解为最佳分量。其次,LSTM模块考虑到3761条数据量并不是很大,故选择较小的Layers(层数),Number of neurons(神经元数目),Batch_size(批量大小)以及Epoch(迭代次数),相应的,对Activation(激活函数),Loss(损失函数)以及Optimizer(优化器)做出选择。然后Dense层链接LSTM与BLS,其Number of neurons应与BLS中N1(每个映射特征节点个数)保持一致。最后对于BLS模块,N1与N2(映射特征个数)的乘积应略大于N3(增强节点总个数),另选取较小值作为C(正则化参数)。经反复调参实验,得到如表1所示的模型的所有参数。
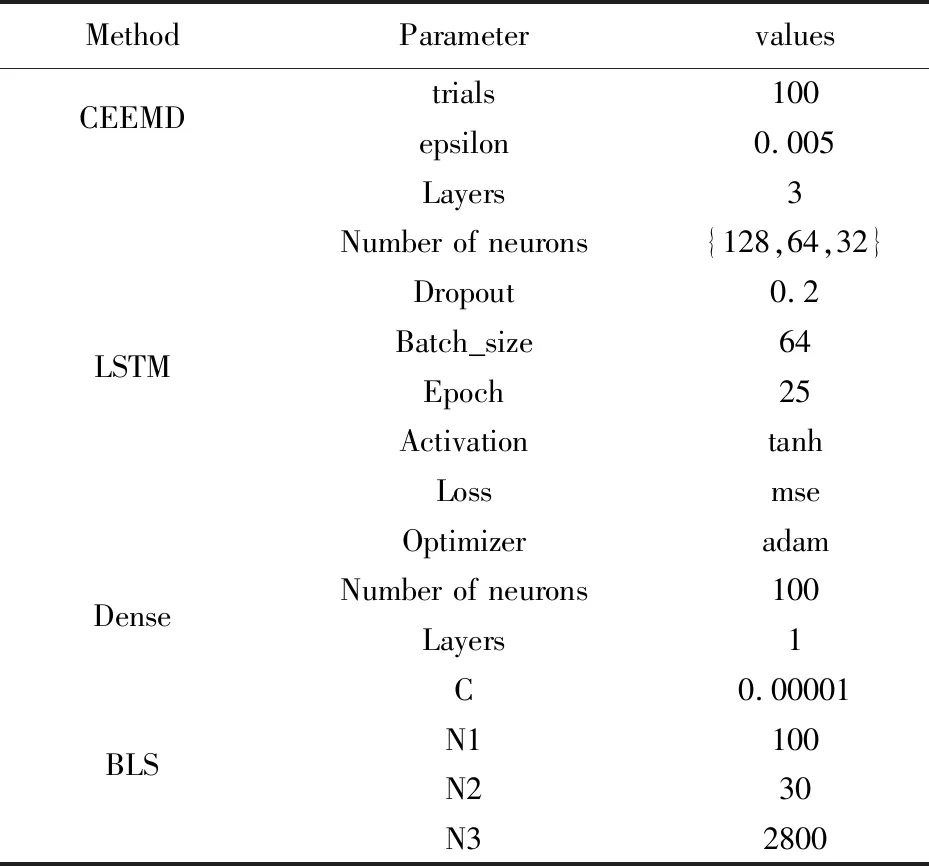
表1 算法的参数
本文选择三个性能指标:MAE(式(11)),RMSE(式(12))和R2_score(式(13))评估算法性能。
(11)
(12)
(13)

2.3 结果分析
2.3.1 LSTM-BLS模型的预测结果对比与分析
表2给出本文提出的LSTM-BLS模型与基线模型—ARIMA,SVM模型的预测结果对比。通过表2可以看出,基线模型相比LSTM-BLS模型在具体数据的表现上存在明显差距。SVM模型训练速度值得肯定,但是精确度远不及本文模型,且SVM本身在训练股票这类大规模数据时存在一定缺陷。ARIMA模型对于处理稳定数据具有一定优势,但股票属于非平稳数据,会受到政策、新闻等因素的影响而波动,所以ARIMA模型对收盘价的预测精度比不上本文所提出的LSTM-BLS模型。
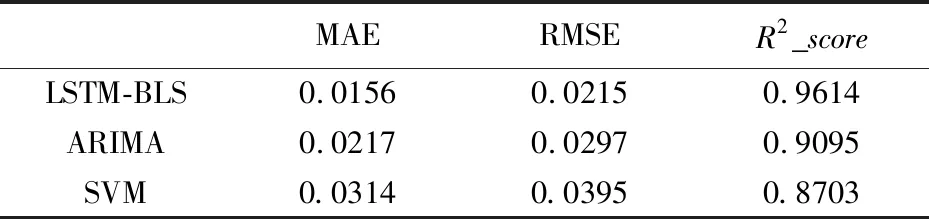
表2 与基线模型预测的性能指标对比
图2给出了LSTM-BLS模型与现有广泛应用的LSTM模型、CNN-LSTM模型以及Attention-LSTM模型的预测结果对比图。
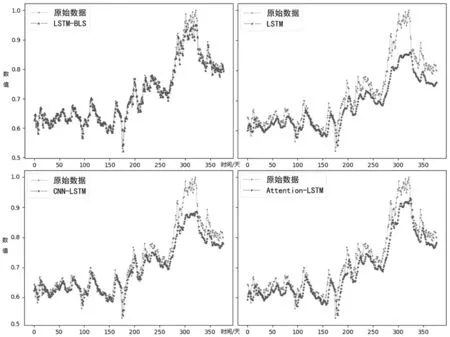
图2 LSTM-BLS等模型预测值与实际值对比
从图中可以明显看出本文提出的LSTM-BLS模型在数据的拟合程度上好于现有模型,且明显好于单一的LSTM模型。特别地,当股票数据出现较大波动时(250天到350天这一时间段),现有的CNN-LSTM模型出现了拟合程度差的现象。而Attention-BLS模型则出现了滞后现象,但新提出的LSTM-BLS模型在数据较大波动时,仍然很好的拟合了真实值,且避免了滞后现象。
2.3.2 分解模块对比分析
为证明本文选取的CEEMD分解模块在处理股票收盘价数据时优于EMD以及EEMD分解模块,针对不同分解方式进行实验对比,实验对比结果如表3给出的性能指标所示,可以得出CEEMD分解模块在处理股票收盘价数据时性能优于EEMD模块,更优于EMD模块。

表3 不同分解方式模型性能指标对比
2.3.3 IMF模块分析
通过前两节的实验分析,LSTM-BLS模型虽然预测精度已经较高,但通过图2可以看出在300天附近的预测值存在一定误差。为进一步提升模型精度,引入CEEMD分解模块。图3给出了收盘价的CEEMD分解结果。其中包含高、中、低三部分频率分量(低频IMF8为趋势项)。

图3 CEEMD分解图
各个分量显示了股民不同频率的波动特征,高频分量波动较大,表征短线炒股现象,中频分量表征受政府政策法规影响下的股市波动,低频分量波动较小,表征股市长期波动趋势,也代表股民投资的整体趋势。
2.3.4 C-L-B模型预测结果对比与分析
为验证本文模型更加适应股票收盘价预测,接下来对比C-L-B模型与CEEMD-CNN-LSTM(C-C-L)模型对这支股票收盘价的预测结果。
图4、图5分别给出C-L-B以及C-C-L模型的预测值与实际值对比曲线图。通过两图的对比可以看出C-L-B模型在数据的拟合程度上明显好于C-C-L模型。尤其是当数据有一个大幅度波动时,只有C-L-B模型能够达到一个优异的拟合程度。

图4 C-L-B模型预测值与实际值对比

图5 C-C-L模型预测与实际值对比
表4给出了相应评价指标的对比结果。结合表4与前几节中不同模型的数据对比,可以明显地看出,C-L-B模型的三个评价指标在LSTM-BLS模型的基础上有很大提升,相比CEEMD-LSTM以及C-C-L等复合模型也有较为显著的提高。

表4 C-L-B模型与现有模型性能指标对比
3 结束语
股票价格走势和未来趋势预测一直是亿万投资者关心的重点之一,但现有的单一的深度学习预测模型在预测精度上存在一定的误差,且存在一定的过拟合风险。本文将宽度学习与深度学习中的循环神经网络相结合,提出了两类深度、宽度融合的股票预测模型。通过大量的对比实验验证,证明了在LSTM模块后加入BLS模块构造的LSTM-BLS预测模型,能够解决单一LSTM模型的滞后、拟合差等问题,提高预测的准确性。为进一步提升预测精度,采用CEEMD分解模块相比EMD,EEMD能更好的处理股票数据中的噪声问题,进而提升在极值点附近的预测精度。通过对比一些现有模型,本文构造的CEEMD-LSTM-BLS股票收盘价预测模型能较为精准的预测股市的涨跌情况,对股民的投资有一定的参考价值。
本文模型只单一考虑了股票收盘价,而未加入其他股票价格因素,亦未考虑政策、舆论等对股票几个的影响。在后续工作中,我们将研究多变量、多因素影响下的深度、宽度融合的股票预测模型。
猜你喜欢
四川工商学院学术新视野(2021年3期)2021-11-05
股市动态分析(2018年21期)2018-06-07
股市动态分析(2017年40期)2017-11-01
股市动态分析(2017年22期)2017-06-19
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年32期)2016-10-25
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
管理现代化(2016年5期)2016-01-23
