
基于敏感变量筛选的多光谱植被含水率反演模型研究
2023-09-23 03:48赵文举段威成王银凤
农业机械学报 2023年9期
赵文举 段威成 王银凤 周 春 马 宏
(兰州理工大学能源与动力工程学院,兰州 730050)
0 引言
植被生理生态指标作为农田生态系统敏感性表征,植被含水率直接反映土壤干燥程度[1]。研究植被含水率对干旱的响应有助于理解全球气候变化背景下,植被对气候波动的响应机制特征,这对提高植被变化预测、农业估产和水肥调控的准确性具有重要意义[2]。
传统方法获取植被含水率分布及变化规律费时费力,易受地形限制[3]。无人机搭载光谱仪器作为低空遥感的一种,可快速获取大范围光谱信息,进而实现土壤墒情和作物生长大范围、快速监测,可为植被含水率反演提供科学高效的技术手段[4-5]。引入红边波段(Red edge position,RedEdge)可提取新的光谱信息,将其替代R波段可衍生多种改进光谱指数[6]。赵文举等[7]将红边波段应用于不同植被覆盖土壤含盐量反演研究,结果表明该波段对植被响应敏感,改进光谱指数对模型精度提升显著。ZHANG等[8]通过对比有无红边波段的20个植被指数,发现引入RedEdge的变量组精度提高7个百分点,且此波段能与植被覆盖下的耕地土壤盐分建立非线性关系,可提升植被含水率反演精度。
光学遥感因其高密度数据组合及复杂的地物构成,严重影响模型反演精度和效率[9]。敏感光谱变量作为反演模型的重要输入因子,其筛选方法一直是该领域的研究热点[7]。研究表明,使用适合的变量筛选算法可提高模型精度及学习效率[10]。代秋芳等[11]将CARS筛选变量与全波段组分别进行CNN模型运算,反演结果中敏感变量组相较于全变量组决定系数R2和均方根误差(RMSE)分别提升0.03、0.007,改进效果显著。WANG等[12]利用变量投影重要性分析等4种筛选算法提取敏感光谱变量进而高效反演土壤含盐量。陈俊英等[13]利用灰色关联度分析筛选光谱指数,基于不同机器学习算法,反演不同生育期不同深度土壤含盐量,筛选变量组反演结果优于全变量组。ZHAO等[6]使用皮尔逊相关性分析法选取相关性高的光谱指数构建不同植被覆盖表层土壤含盐量反演模型,所构建模型较好地反映真实土壤盐分含量。变量筛选模型及机器学习算法凭借其处理非线性问题的优势,已经在农业水土遥感上得到应用,但多种变量筛选算法在植被指数优选中应用较少,且不同算法对植被指数敏感表征的相关研究较少,变量筛选算法结合不同机器学习模型,反演不同植被覆盖含水率的响应机理还有待深入研究。
综上所述,本研究基于无人机搭载多光谱成像系统获取苜蓿、玉米遥感影像,并对植被含水率进行同时段野外实测,通过引入红边波段构建25种传统及改进光谱指数,采用变量投影重要性(Variable importance in projection,VIP)、灰色关联度(Gray relational analysis,GRA)与皮尔逊(Person)相关性分析算法对光谱指数进行筛选,将筛选后的敏感变量作为模型输入层,构建基于反向神经网络(Back-propagation neural network,BPNN)、偏最小二乘法(Partial least squares regression,PLSR)、支持向量回归(Support vector regression,SVR)和随机森林(Random forest,RF)4种机器学习算法的植被含水率反演模型,通过对反演效果评价,以讨赖河流域边湾农场为例,确定不同植被覆盖的含水率反演模型,以期为快速、精准反演植被含水率提供理论依据。
1 材料与方法
1.1 研究区概况
本研究区域位于甘肃省讨赖河流域边湾农场,该地区气候干旱,降雨稀少,蒸发量大,水资源时空分布不均。农场主要作物有:玉米、小麦、向日葵和苜蓿等,是河西走廊重要的粮食生产基地。无人机多光谱遥感监测及实地采样位置如图1所示。
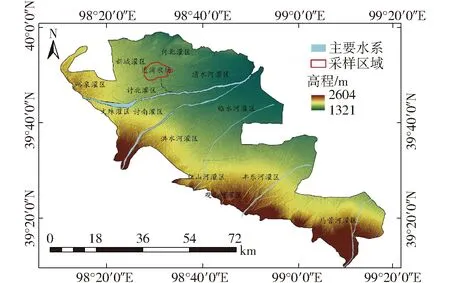
图1 研究区示意图
1.2 试验数据采集与预处理
1.2.1无人机多光谱遥感影像
采样日试验区光照条件充足、均匀,所用遥测平台为DJI公司Phantom 4 Multispectral无人机,共搭载6个1/2.9英寸CMOS影像传感器,包含1个彩色RGB传感器和5个单色光谱传感器,详细波段参数如表1所示。设置飞行高度40 m,航线重叠率70%,旁像重叠率65%,无人机平均速度4 m/s,并采集白板数据用于辐射校正。通过DJI Terra及ENVI 5.3软件完成影像预处理。
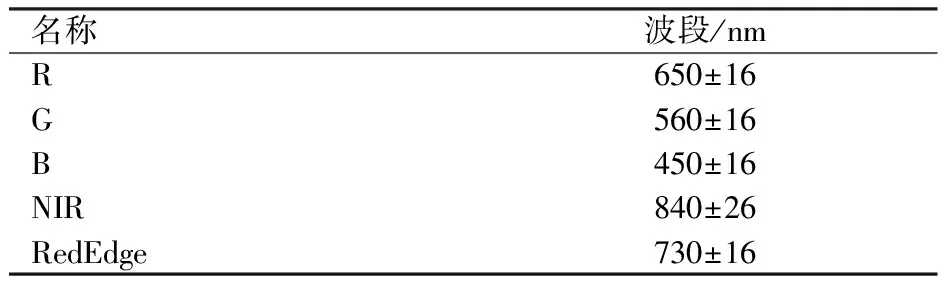
表1 机载光谱仪波段参数
1.2.2野外实测采样
2022年6月8—10日在边湾农场进行实地采样,采样点分布见图2。分别在苜蓿、玉米覆盖地均匀布设60个采样点。在获取无人机多光谱遥感影像后,对植被进行整株采样,并使用手持RTK进行打点定标。将采集样本用去离子水洗净称量鲜质量后,放入干燥箱105℃杀青30 min,然后75℃干燥至恒定质量,测其干质量[14]。

图2 采样点分布图
1.3 光谱指数构建与筛选
1.3.1光谱指数构建
利用遥感影像中提取的光谱反射率,进行不同的波段组合。通过研究发现该红边波段可有效提升植被覆盖下反演模型精度[15]。本文将红边波段替换传统光谱指数中的R波段,进而衍生出改进光谱指数,共构成25个光谱指数如表2所示[16-19]。

表2 光谱指数
1.3.2筛选算法构建
光谱数据普遍存在数据密度大、波段及组合繁杂等特点。在模型构建中,冗余及干扰变量均会影响植被含水率反演精度和准确性,进而需要进行变量筛选[9]。本文选取VIP、GRA与Person相关性分析对25个光谱指数进行筛选、对比。VIP分析和GRA分析通过Matlab R2016a实现,Person相关性分析则是使用IBM SPSS 26进行筛选运算。
1.4 植被含水率反演模型构建与精度评价
1.4.1模型构建
将玉米、苜蓿覆盖地获取的60个样本数据,随机挑选40个划分为建模集,用于回归建模与训练,20个划分为验证集,用于检验模型精度。
通过Person相关性分析、VIP分析及GRA分析,将优选出的敏感光谱变量作为模型的输入层,实测的植被含水率作为模型的输出层,分别采用BPNN、SVR、RF和PLSR构建植被含水率反演模型,机器学习模型均通过Matlab R2016a实现。
1.4.2模型精度评价
利用模型的决定系数(Coefficient of determination,R2)、均方根误差(Root mean squared error,RMSE)和平均绝对误差(Mean absolute error,MAE)来评价建模精度。R2越接近1,RMSE和MAE越小,表明预测值和实测值之间的偏差越小,模型反演效果越好。
2 结果与分析
2.1 植被含水率统计特征
为了对预测模型进行训练和验证,将划分的建模集与验证集互补性进行对比检验。全集、建模集和验证集描述性统计结果如表3所示。
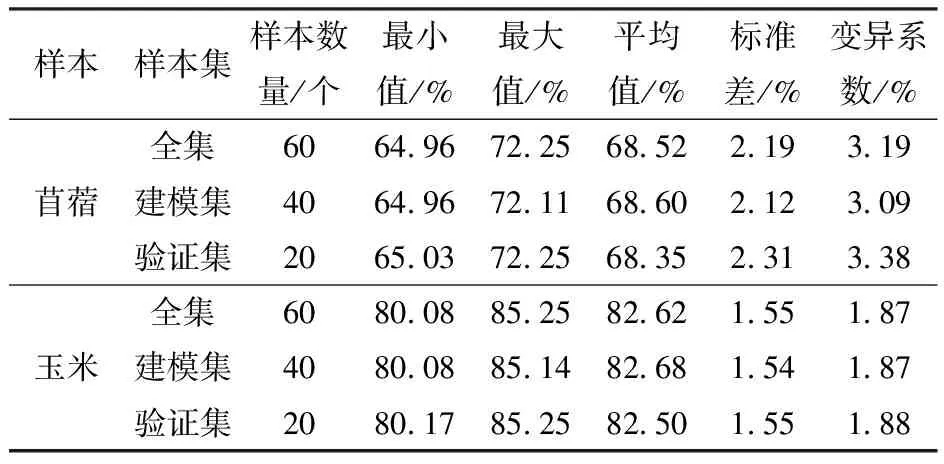
表3 植被含水率统计特征
由表3可知,不同植被覆盖的建模集和验证集均保持和全集植被含水率相近的统计结果。最大限度地减小了建模集和验证集之间的偏差。这表明所选建模集和验证集的植被含水率可以代表整个数据集,采样数据可以较为真实地反映研究区的植被含水率。
2.2 敏感光谱变量筛选
2.2.1皮尔逊相关性筛选
在遥感定量估算植被含水率的研究过程中,通常需要建立植被含水率与光谱指数之间的相关关系,并进行分析研究[6],选择出敏感光谱变量,各变量之间的相关关系由皮尔逊相关系数(Pearson correlation coefficient,PCCs)表示。
将计算获取的光谱指数分别与苜蓿、玉米的植被含水率进行相关性分析,反射率、光谱指数与含水率的PCCs分布矩阵如图3所示。

图3 Person相关系数矩阵
从图3可知,苜蓿地除EVI、EVI-reg、CVI、COSRI及NDVI-reg以外的20个光谱指数都通过了显著性检验;玉米地则去除G波段、EVI、EVI-reg、CVI、NDGI、COSRI和TVI,保留18个敏感变量作为模型输入层。
2.2.2变量投影重要性筛选
变量投影重要性分析法是一种基于偏最小二乘算法的变量筛选方法,主要用于评估数据集中每个变量对于解释目标变量的重要性[12]。该方法通过计算每个变量在主成分分析或因子分析中的投影贡献,来评估变量的重要性。
在Matlab R2016a中对5个光谱反射率及25个光谱指数进行变量投影重要性分析,将筛选阈值设置为1.0,筛选结果如图4所示。
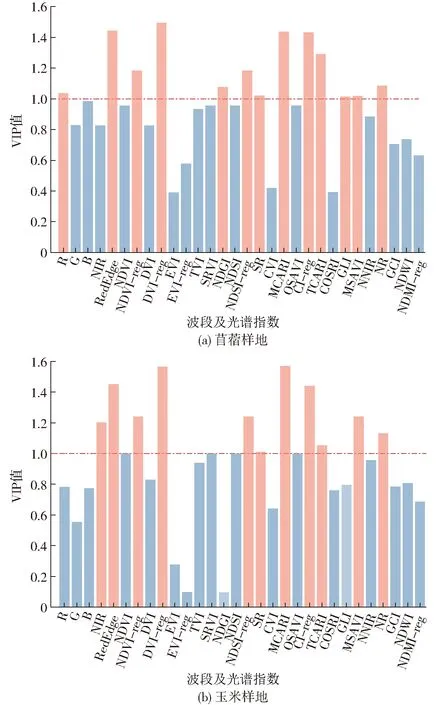
图4 VIP变量筛选结果
苜蓿覆盖地筛选出R、RedEdge、NDVI-reg、DVI-reg、NDGI、NDSI-reg、SR、MCARI、CI-reg、TCARI、GLI、MSAVI、NR共13个光谱波段及光谱指数。玉米地筛选出NIR、RedEdge、NDVI-reg、DVI-reg、NDSI-reg、SR、MCARI、CI-reg、TCARI、MSAVI、NR共11个光谱波段及指数,并分别作为模型输入层。
2.2.3灰色关联度分析
在构建神经网络模型过程中,过多的输入层数据会影响模型的学习过程,降低模型的收敛速度和预测精度,本文采用灰色关联度分析对数据进行筛选,达到去除冗余数据的目的。引入灰色关联度分析法对该区域的植被含水率进行了定量分析[20],计算灰色关联度系数(Gray correlation degree,GCD),分辨系数取0.5。
在Matlab R2016a中对光谱波段及指数进行灰色关联分析,将筛选敏感变量的GCD阈值设置为0.7,苜蓿覆盖地筛选得G、B、NIR、RedEdge、NDVI-reg、EVI-reg、NDSI-reg、SR、COSRI、MSAVI、NNIR、NDWI、NDMI-reg共13个敏感变量作为模型输入层,玉米覆盖地则仅排除DVI、EVI、TVI和TCARI。筛选结果如图5所示。
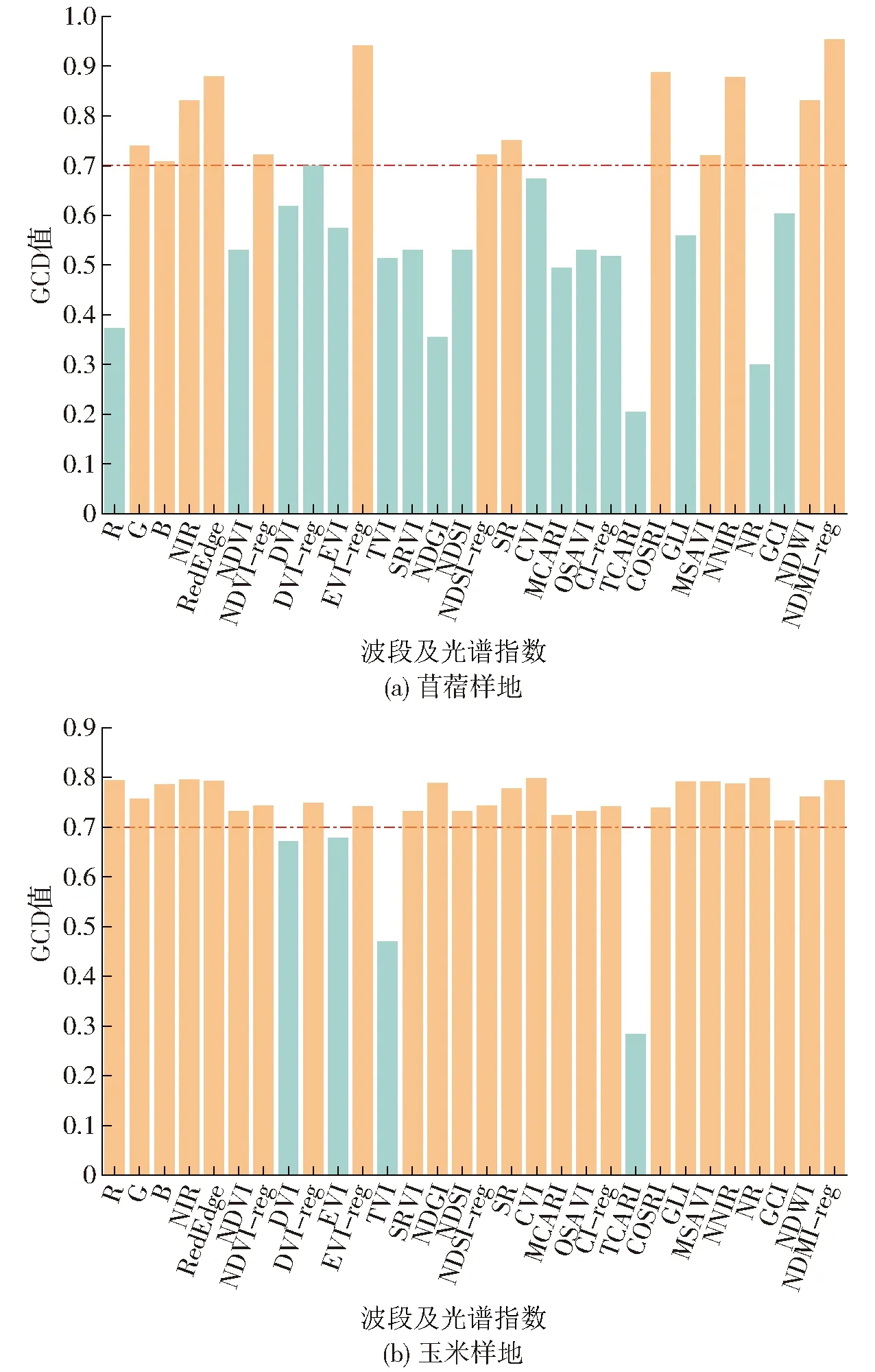
图5 GRA变量筛选结果
2.3 基于敏感变量的植被含水率反演模型
基于VIP、GRA和Person相关性分析3种筛选模型算法,建立波段及指数联合样本集,并对所选样本集构建BPNN、PLSR、SVR和RF共4种机器学习模型并进行精度验证,建模集和验证集的结果如表4所示。
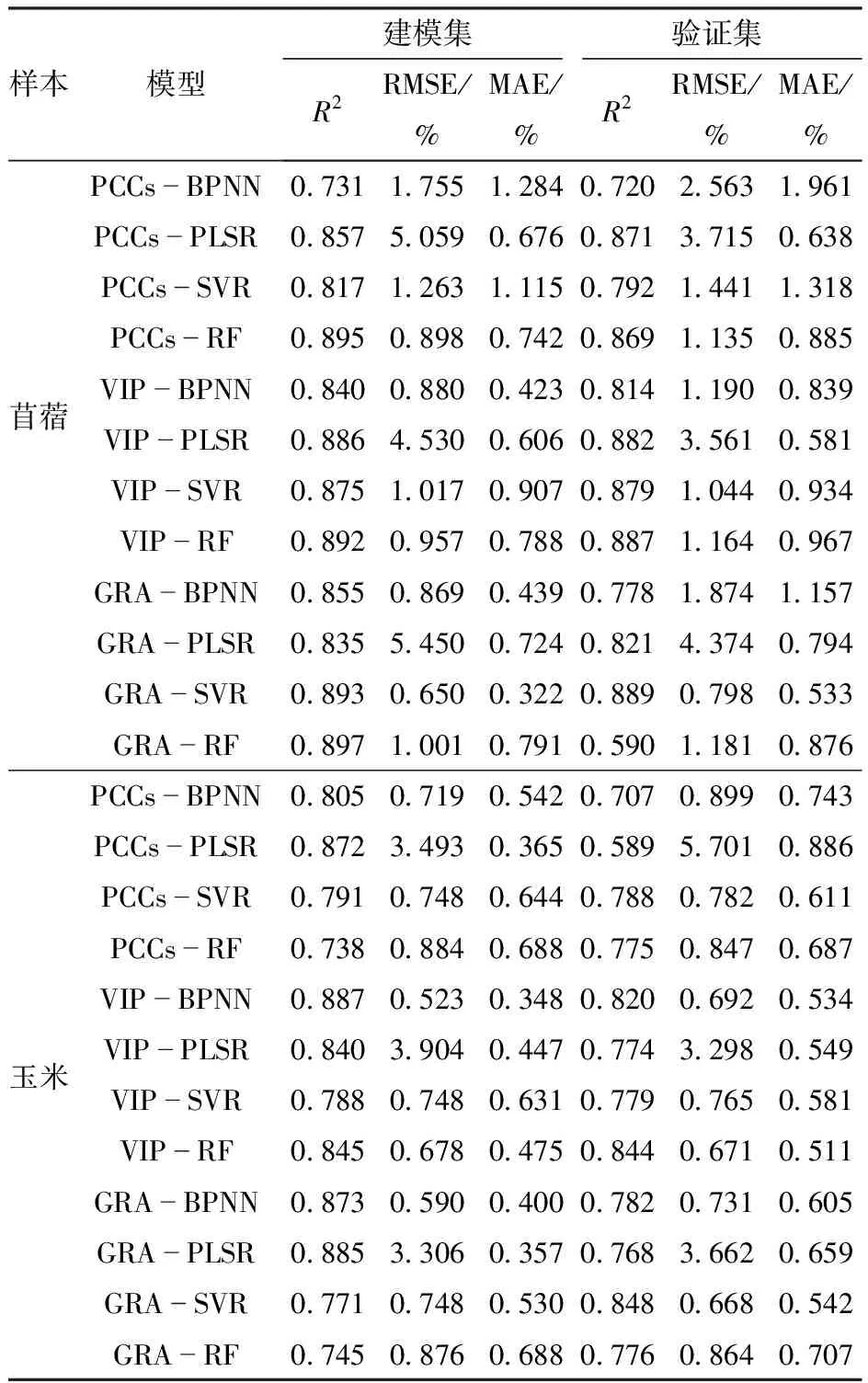
表4 植被含水率反演模型精度
经Person相关性分析的敏感变量样本集,由4种机器学习反演可得,建模集及验证集决定系数R2均大于0.7,均方根误差(RMSE)存在小幅波动,多处于0.7%~1.2%之间,玉米覆盖地MAE在0.9%以内,苜蓿覆盖地在2.0%以内。由VIP筛选的样本集,执行反演运算。结果表明,建模集、验证集R2均高于0.75。除PLSR反演结果异常,其余模型的RMSE均小于1.2%,MAE保持在1.0%以内。对反演结果进行权重分析,此敏感变量组最佳反演模型为RF。GRA输入因子较多,由反演结果可得,建模集及验证集R2除RF外均大于0.75;模型RMSE多低于1.2%;玉米覆盖地MAE在0.7%以内。对评价指标进行权重分析,GRA苜蓿地及玉米地最佳反演模型为SVR。
基于4种变量筛选算法,分别绘制苜蓿、玉米覆盖地的机器学习反演结果散点图、拟合曲线,如图6(图中阴影部分为反演结果置信区间)所示。苜蓿覆盖地的散点分布比较均匀且集中,与玉米反演结果相比,其距离置信区间偏差较小,拟合曲线斜率也较为一致。苜蓿含水率反演结果主要集中于置信区间的中央,范围为66%~70%。而玉米含水率分布则比较分散,PCCs-PLSR反演结果的离散性较为明显,反演精度最差。在两种植被覆盖下,最佳反演模型均为GRA-SVR,散点图分布均匀,置信区间合理,残值较少,所有模型的决定系数R2都在0.8以上,反演效果较好。
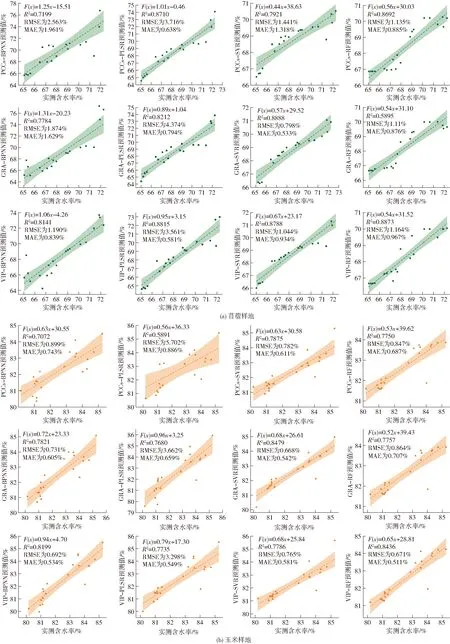
图6 植被含水率实测值与预测值对比
2.4 模型综合评价
将不同植被覆盖条件下含水率反演结果与实测值进行对比。由图7(图中误差棒长度表示RMSE)可得,PLSR在各类筛选模型中的RMSE最大,均大于3.5%,精度最差。基于GRA和VIP筛选后建立的植被含水率反演模型多取得了较好的反演效果,Person相关性分析筛选后的反演结果稍差,但苜蓿样地GRA-RF反演结果相较于其他两种筛选算法还有待改进。
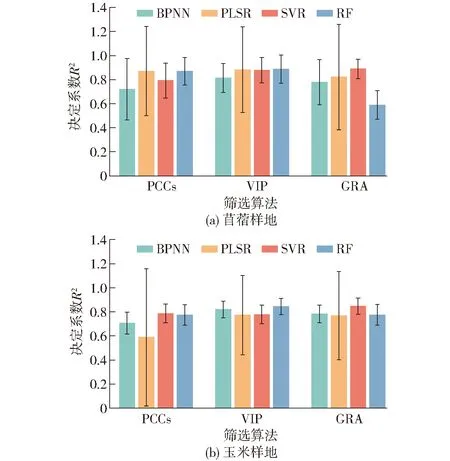
图7 模型反演精度对比
综上所述,苜蓿、玉米覆盖地植被含水率最佳反演模型为基于灰色关联度分析的支持向量回归模型,苜蓿地建模集R2为0.893,RMSE为0.650%,MAE为0.322,验证集R2为0.889,RMSE为0.798%,MAE为0.533%;玉米覆盖地建模集R2为0.771,RMSE为0.748%,MAE为0.530%,验证集R2为0.848,RMSE为0.668%,MAE为0.542%,模型反演精度较高,可较真实反映不同植被覆盖的含水率变化情况。
3 讨论
近地遥感具有获取信息快、覆盖面积广及运行成本低等优势,在估算植被含水率方面有较大的发展潜力,是未来精准农业的发展方向[21]。但采用大量的光谱变量使模型的构建变得较为复杂,且大量的光谱变量往往含有冗余信息。因此,选择适宜的筛选算法及反演模型是提高植被含水率监测精度的有效途径。
敏感变量筛选可有效去除光谱变量中的冗余信息,降低植被含水率反演模型的复杂程度,达到提高反演模型精度的目的。综合对比分析基于3种变量筛选方法的反演模型精度,基于VIP建立的4种反演模型精度R2较为统一,且均优于PCCs反演结果。但就整体而言,两块样地最佳反演模型均为GRA-SVR,这与贾萍萍等[22]、LI等[23]的研究结果一致。但GRA提取苜蓿、玉米敏感变量有较大差异,苜蓿样地筛选后敏感变量剩余13个,玉米样地筛选后仅排除4个冗余变量。主要原因是作物光谱特征因作物类型不同、植被覆盖差异,会表现出明显区别[13],采样时苜蓿种植密度高,且正处于盛花期;玉米覆盖度低,大面积的土壤处于裸露状态。张智韬等[24]在研究植被覆盖程度对土壤含盐量反演的影响时,证实了这一点,随着植被覆盖度增加,盐分指数敏感性逐渐降低,植被指数敏感性逐渐增加。不同筛选模型对光谱变量的响应差异较大[25],红边波段及相关改进光谱指数复现率较高,而DVI、NDSI对模型贡献率较差,引入红边波段改进后,光谱指数的Person相关性及变量筛选评分明显提升。此次采样的玉米正处于拔节期,含水率为75%~85%,盛花期苜蓿为60%~75%,与IMPOLLONIA等[26]利用无人机遥感技术对14个芒果杂交品种进行基于光谱指数的含水率测定结果一致。当植被含水率超30%时,模型精度较为稳定且精度较高。AHMAD等[27]以TRMM和AVHRR星载遥感数据为基础,分别建立支持向量回归、人工神经网络和多元线性回归模型反演土壤含水率,研究表明,SVR反演结果最优,这与本研究最佳反演模型结果一致,支持向量回归具有较高的估测性能,在处理多类问题时准确性较高,可有效反演植被含水率。
本研究基于无人机多光谱影像,建立不同植被覆盖的植被含水率反演模型并取得了较好的反演结果,相较于BPNN、PLSR和RF,通过GRA-SVR筛选、反演的植被含水率更真实地反映不同作物内水分变化情况。但就试验设计而言,仍然存在一定的改进空间,可考虑引入机载LiDAR进行植物表征监测,多源遥感数据的融合能进一步有效提高反演精度,同时探究不同植被、不同生长周期的含水率变化情况等[28-29]。进而以多源近地遥感为主要技术手段,构建多作物、少冗余、高精度的植被含水率反演模型,以期实现不同植被种类含水率的快速、精准获取。
4 结论
(1)对比Person分析结果构建的模型,通过VIP、GRA筛选获取的输入数据所构建的植被含水率反演模型反演效果更好,均方根误差更小,训练速度也明显提高,表明VIP、GRA筛选算法应用于植被含水率反演及相关研究是可行的。
(2)在4种机器学习算法中,SVR算法在非线性问题中相较于BPNN、PLSR、RF算法具有较强的解析能力和较高的模型鲁棒性,验证集R2在0.779~0.889之间,反演结果波动较小。故SVR对于不同作物覆盖下的植被含水率反演结果最能真实体现植被水分变化情况。
(3)对比分析24个土壤含水率反演模型,在不同植被覆盖下,GRA-SVR反演结果最佳,验证集苜蓿覆盖地R2为0.889,RMSE为0.798%,MAE为0.533%,玉米覆盖地R2为0.848,RMSE为0.668%,MAE为0.542%,且苜蓿覆盖下植被含水率反演精度略优于玉米覆盖地。
猜你喜欢
中等数学(2022年5期)2022-08-29
现代畜牧科技(2021年9期)2021-10-13
现代畜牧科技(2021年4期)2021-07-21
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
中国三峡(2017年4期)2017-06-06
高师理科学刊(2016年8期)2016-06-15
为了孩子(3~7岁)(2016年6期)2016-05-14
西藏科技(2015年4期)2015-09-26
河北北方学院学报(自然科学版)(2014年2期)2014-05-30
