
玉米生长铜铅污染信息光谱辨别研究
2023-09-23 03:47杨可明何家乐李艳茹张建红
农业机械学报 2023年9期
杨可明 何家乐 李艳茹 吴 兵 张建红
(中国矿业大学(北京)地球科学与测绘工程学院,北京 100083)
0 引言
玉米是世界主要的谷类作物,近年来玉米的总产量仅次于水稻,位居我国第二位[1],玉米已经逐渐成为日常生活中基本的粮食、饲料和生产原料等。因此玉米种植中的健康生长尤为重要,玉米的合理化种植逐渐成为研究热点[2]。如果土壤中的重金属含量超标,就会逐渐被农作物吸收并累积,从而对人体有严重影响[3-4],其中铅(Pb)是重金属污染物中毒性较大的一种,能直接伤害人的脑细胞;而铜(Cu)中毒轻者会产生胃肠道黏膜刺激症状,重者甚至会出现肾功能衰竭及尿毒症、休克等[5-7]。
农作物的重金属污染监测非常关键,只有正确地识别重金属污染元素的类别,才可以对农作物接下来种植的土壤进行调整[8-10],因此对玉米生长中所受重金属污染的辨别研究显得尤为重要,采用高光谱技术辨别重金属污染逐渐成为了遥感应用热点[11],目前采用高光谱技术进行参量反演的方法比较常见[12-13],但是运用到农作物重金属污染辨别的还较少。
高伟等[14]建立了CLCDF污染判别特征,对作物中的重金属污染种类进行判别,为重金属胁迫的光谱辨别提供了新的思路;GUO等[15]通过基于高光谱的ML模型,确定污染垂直分布的关键因素和判断地下土壤中的金属(类);LI等[16]通过构建新的光谱指数,快速识别了土壤重金属污染中的元素,经过验证该模型的通用性和鲁棒性都较好。还有学者采用了特征光谱融合提取[17-19]以及深度强化学习[20-22]的方法对植被灾害以及污染进行辨别。
上述研究在重金属胁迫辨别方面均取得了较好的结果,但是光谱处理与辨别方法较为繁琐,辨别准确度仍需提高,算法较为复杂,计算量大,不易进行应用,因此寻找一种快速辨别农作物重金属污染的方法变得尤为重要。本文以受不同程度铜铅(Cu、Pb)胁迫的玉米叶片为研究对象,采用ASD光谱仪获取玉米叶片的光谱,经过0.1~1.0阶的分数阶微分(Fractional derivatives,FD)处理后,通过竞争性自适应重加权算法(Competitive adapative reweighted sampling,CARS)提取光谱的特征光谱,最后通过比较多种辨别模型的性能,最终选择性能最佳的多层感知机(Multi-layer perceptron,MLP),构建FD-CARS-MLP模型并进行试验,以达到辨别玉米叶片中Cu、Pb污染信息的目的。
1 试验
1.1 试验材料
以不同梯度重金属元素(Cu、Pb)胁迫的不同时期玉米生长叶片为研究对象,选用玉米品种为中糯1号。共分为两组:重金属元素(Cu、Pb)胁迫试验分别选CuSO4·5H2O和Pb(NO3)2溶液作为试剂,胁迫梯度为0、50、100、150、200、300、400、600、800、1 000、1 200 μg/g,胁迫梯度平行试验共3组。试验期间,保持土壤湿润,空气畅通,保证各盆栽生长环境一致,避免其他因素对试验结果产生影响。
1.2 光谱采集
选取ASD FieldSpec 4型便携式地物光谱仪,进行重金属元素(Cu、Pb)胁迫试验苗期、拔节期、抽穗期玉米叶片高光谱数据采集。每次光谱反射率测定前使用标准白板对光谱反射系数进行校准,光纤探头视场角为25°,探头垂直于叶片表面,垂距小于5 cm,每盆玉米叶片光谱测量5次。得到不同重金属(Cu、Pb)胁迫试验的光谱曲线如图1所示。
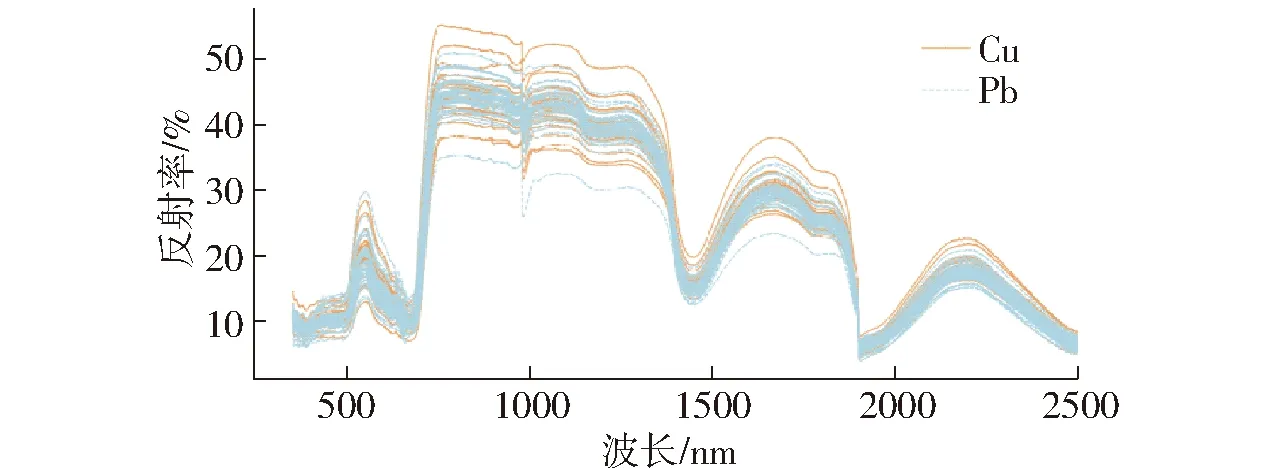
图1 重金属(Cu、Pb)胁迫的光谱曲线
2 基本原理
2.1 分数阶微分
分数阶微分的定义形式有很多种,其中主要有Riemann-Liouville、Grünwald-Letnikov、Caputo、Remann-liouville、广义函数等[23-24],本研究选择Grünwald-Letnikov进行光谱数据处理。若设f(λ)为一维的光谱曲线,则分数阶微分定义可表示为
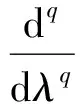
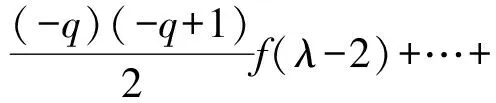
(1)
式中q——任意阶数n——波段数
λ——波段的中心波长
将波长范围按步长h进行等分,[a,t]为波长范围区间,λ∈[a,t],因为玉米叶片在光谱采集时,光谱仪光谱重采样间隔为1 nm,因此令h=1,n=t-a。
2.2 竞争性自适应重加权采样法
竞争性自适应重加权采样法(CARS)结合了蒙特·卡罗方法(Monte Carlo,MC)和最小偏二乘回归方法(Partial least squares regression,PLS)对特征变量进行选择[25-26],该算法和达尔文的“适者生存”理念非常相似。CARS采用自适应加权采样(Adaptive reweighted sampling,ARS)的方法,选择PLS中回归系数绝对值占比权重相对较大的波长,形成新的组合形式[27],去掉权重占比较小的特征波长,以新建的组合为基础重复上述方法,得到PLS交互验证均方根误差(Root mean square error of cross validation,RMSECV)最小的最优组合,该组合中的剩余波长将被作为原始光谱的特征波段,进行接下来的数据辨别,具体过程如下:
(1)通过蒙特·卡罗方法,从原数据中随机抽取一部分数据用于模型建立[28],剩余数据将作为PLS模型的预测数据(一般建模数据与预测数据的比例为8∶2),采样时PLS中的回归系数权重的绝对值计算式为
(2)
式中bi——第i个变量回归系数
wi——第i个变量回归系数权重
m——采样剩余变量的数量
(2)通过指数衰减函数(Exponentially decreasing function,EDF)剔除回归系数权重占比绝对值相对较小的波段,第i次MC采样构建PLS模型时,通过EDF获取保留波段点的占比Ri为
Ri=ue-ki
(3)
式中u、ki——常数
(3)每轮采样均从前一轮采样时的数据中,通过自适应加权采样(ARS)提取Ri的n个波段,进行建模,并经过计算得到RMSECV。
(4)经过所有的采样后,CARS生成了多组待选择的特征波段集合,并且每个集合都有相对应的RMSECV,最后保留RMSECV最小的一组作为所需要的特征波段。
2.3 交叉验证
交叉验证又名循环估计,是一种统计学中将数据作为总集合分成多个子集合的过程[29]。K-fold交叉验证即在样本空间中,选择大量数据作为训练样本,剩余数据作为模型的测试样本,并且求出剩余样本的误差、准确度以及其平均值。将样本的误差平方相加,即可得到模型的预测误差。常见的交叉验证方法有简单交叉验证、K-fold交叉验证和留一验证,本研究选择最常用的K-fold交叉验证,在数据辨别之前划分出训练、预测数据。
2.4 分类算法
分类是一种通过机器学习(Machine learning)的自然语言处理任务,机器学习中的分类算法,是通过训练集来预测其他数据将会属于某个种类的概率。本研究选择的分类算法为多层感知机(Multi-layer perceptron,MLP)、K-最近邻(K-nearest neighbors,KNN)、支持向量机(Support vector machine,SVM),经过试验最终选择性能最优的MLP分类模型作为主辨别方法。
以MLP分类模型为例,该模型分为输入层、隐藏层和输出层,其中输入层为数据的不同特征,在本研究中就是光谱不同波段的反射率,即输入层的神经元个数就是光谱的波段数目;隐藏层为1层,有25个神经元;最后输出层共有2个神经元,分别表示铜污染和铅污染信息。
3 结果与分析
3.1 分数阶微分
分数阶微分处理后的光谱数据和原数据差别较大,它可以放大数据的特征,获取到光谱数据中的更多细节信息,相较于原数据更有利于污染信息的辨别。综合考虑光谱数据量和数据质量,本研究选择以拔节期玉米叶片光谱数据为主,苗期和抽穗期为辅进行辨别,对受重金属(Cu、Pb)胁迫生长的玉米叶片高光谱数据进行从原光谱到1.0阶的分数阶微分处理(即0~1.0,以0.1为间隔依次增加),随着微分阶数的不断增加,光谱逐渐产生变化,以200 μg/g浓度梯度铜胁迫下的拔节期玉米叶片光谱为例,经过0.1~1.0阶分数阶微分的光谱曲线如图2所示。
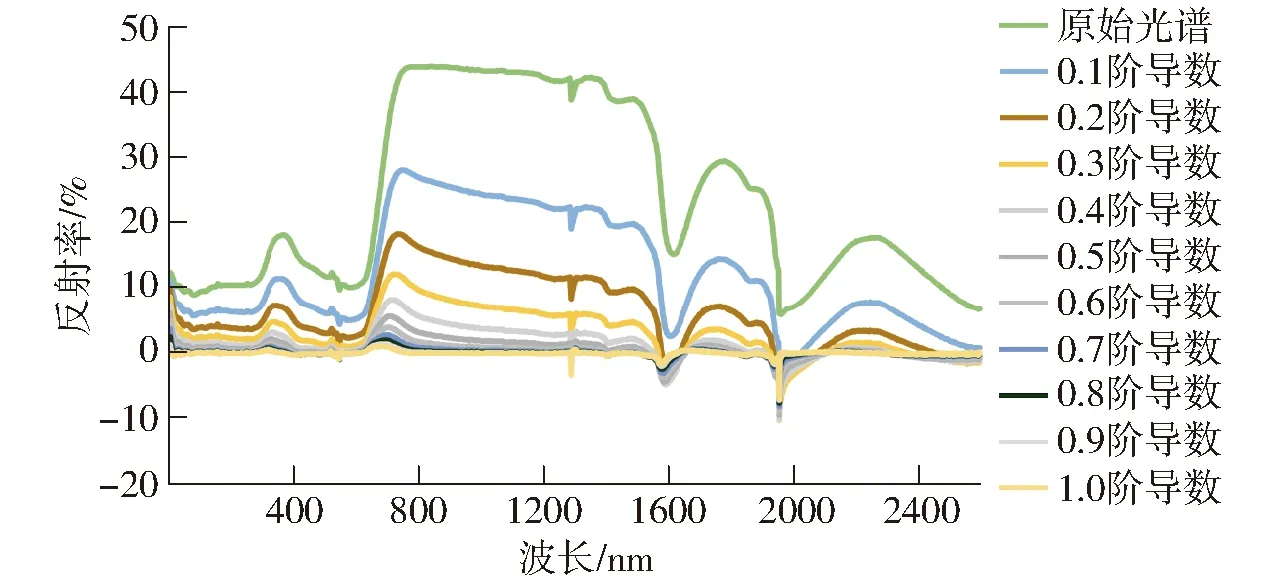
图2 0.1~1.0阶分数阶微分的光谱曲线
3.2 CARS获取特征波段
原数据的波段为350~2 500 nm,如果直接运用,不仅后续处理数据量庞大,数据处理时间过长,而且特征点过多也会使分类的精度降低。CARS可以通过计算,直接筛选出回归系数权重占比最大的波段,直接得出原数据的最佳特征波段,该方法相较于传统的主成分分析法(Principal components analysis,PCA)等方法更加方便,不用手动调整参数即可直接给出多种特征波段组合以及其每一种波段组合的RMSECV,该均方根误差越小表示该波段组合的性能越好,通过比较每一种波段组合的RMSECV即可直接给出最佳特征波段,采用该种方法进行特征提取更加简便智能,而且不会遗漏特征波段组合。
本研究的特征波段提取过程由Python编程实现,对经过分数阶微分后的光谱数据通过CARS进行特征数据提取,从2 250个波段中进行自动的特征波段选取。进行胁迫辨别时要求相同波段对应,本研究对以重金属(Cu、Pb)胁迫的光谱数据进行CARS计算。接下来以拔节期Cu、Pb胁迫光谱数据为例,结合图3进行分析。
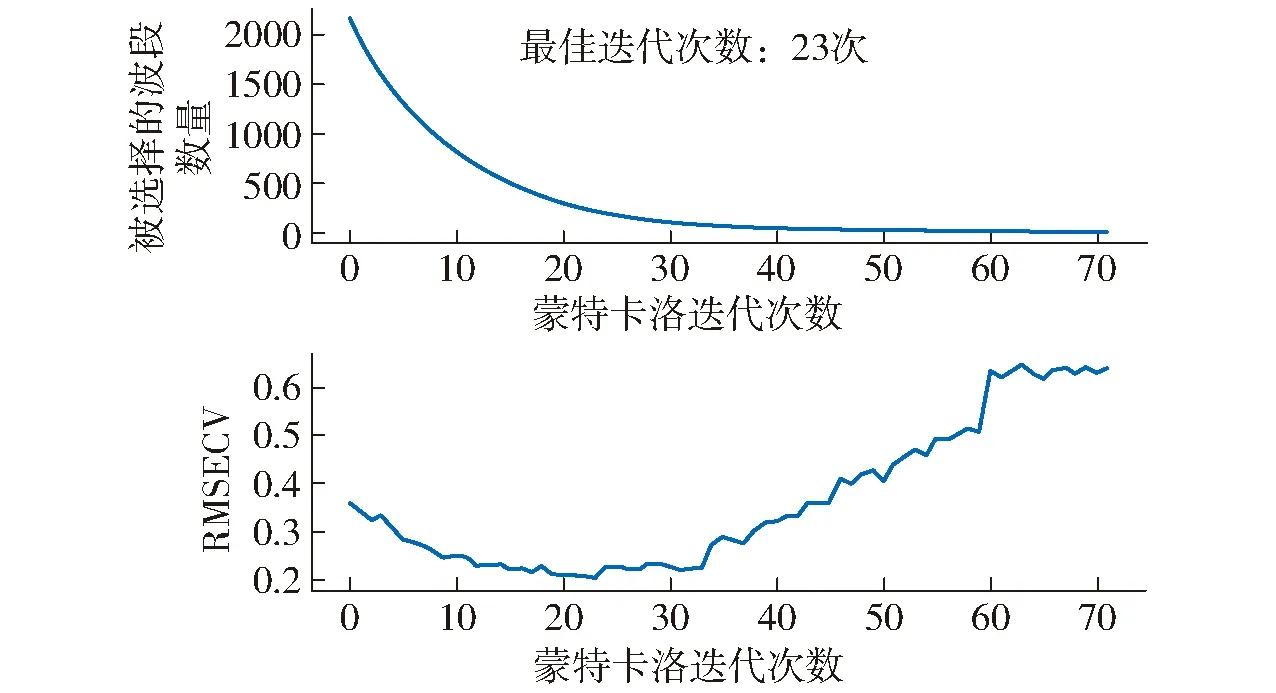
图3 经过CARS计算的拔节期Cu、Pb胁迫原数据
对于拔节期的重金属(Cu、Pb)胁迫光谱数据进行CARS计算,其最佳筛选次数与特征波段数如表1所示。
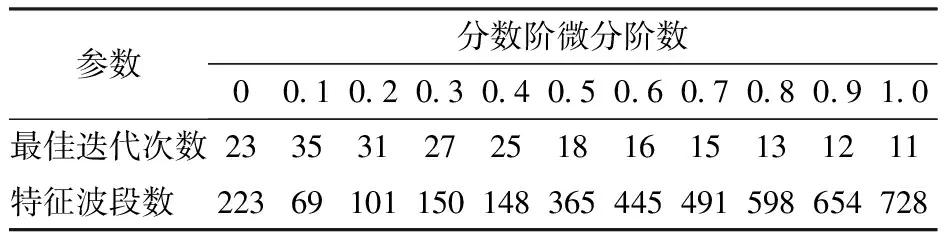
表1 最佳筛选次数与特征波段数
由图3和表1可得,随着迭代次数的增加,得到的特征光谱数量不断减少,RMSECV呈现先降低后增加的趋势,对于重金属(Cu、Pb)胁迫光谱数据来说,随着分数阶微分阶数的不断增加,最佳特征波段所对应的的迭代次数不断减少,波段数量不断增加。
3.3 依据最佳特征波段的污染辨别
经过分数阶微分和CASR处理后,得到了代表每一组光谱的最佳特征波段,然后选择不同的分类模型进行胁迫污染辨别,选取最适合玉米叶片光谱数据的模型,以达到最好的污染辨别效果。本研究选择的分类算法为MLP、KNN、SVC。在数据辨别之前先通过5折交叉验证(K=5)划分出训练数据和预测数据,以方便后续对所建的模型进行性能评估。基于接收者操作特征曲线(Receiver operating characteristic curve,ROC),本研究选择ROC曲线下面积(Area under curve,AUC)、准确率(Accuracy,Acc)、精确度(Precision,Pre)、错误接受率(False acceptance rate,FAR)以及错误拒绝率(False rejection rate,FRR)5个评价指标,5个评价指标均位于0~100%之间,其中AUC、Acc、Pre 3个指标数值越接近于100%,FAR、FRR 2个指标越接近于0表示所建立的模型辨别性能越好。3种分类模型指标如图4所示。
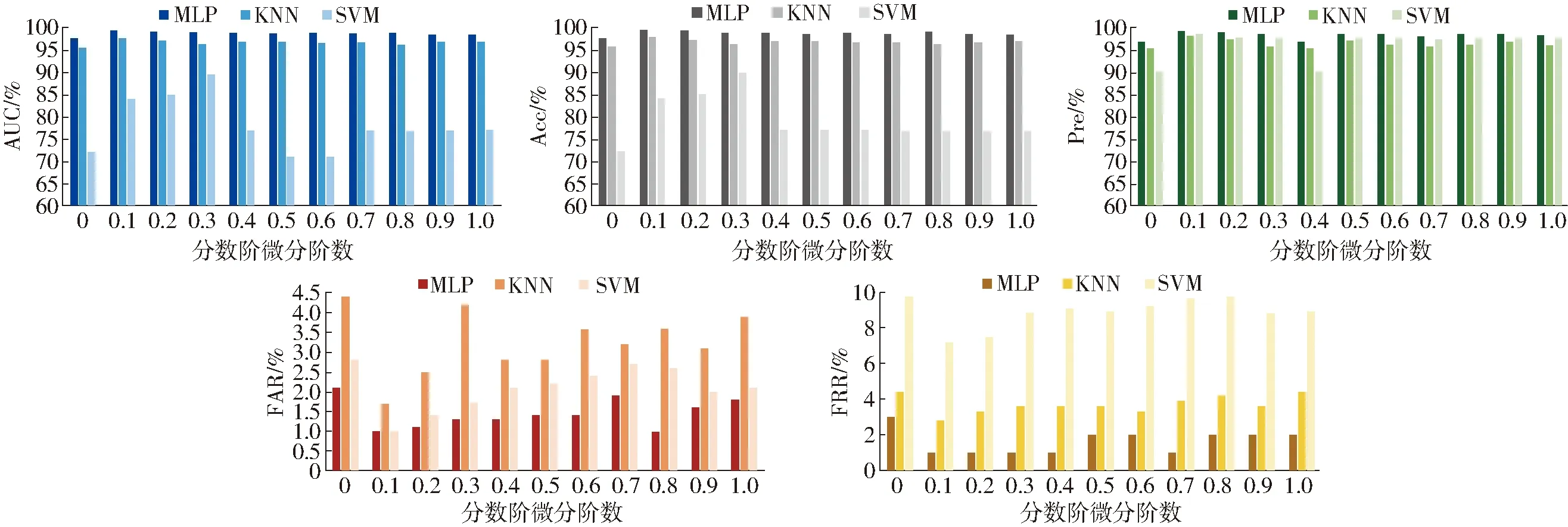
图4 基于MLP、KNN、SVM分类模型的拔节期Cu、Pb 污染辨别评价指标对比
由图4可得,3个分类模型中,KNN模型的AUC、Acc、Pre 3个指标数值均在95%以上,除原数据以外,均为96%以上;FAR、FRR均在4%以下;MLP模型的AUC、Acc、Pre均在97%以上,除原数据以外,均为98%以上;FAR、FRR均在2%以下,MLP模型相比于KNN模型在5个指标数值上均提高2个百分点,性能较好,对于重金属(Cu、Pb)胁迫玉米叶片的辨别能力较好;而SVM明显不适用于本次研究数据的辨别。
本研究的数据量较大,因此SVM并不适用;KNN分类模型的计算量较大,特别是当特征变量增多时,而本试验的特征变量较大,并且如果样本量不平衡时,其精度也会有所降低;MLP分类模型辨别率高且分类速度快,因此MLP综合来看最适合本研究的分类任务。
选取MLP作为数据辨别的方法,对重金属(Cu、Pb)胁迫的光谱数据进行辨别。分析可得,经过分数阶微分的污染信息辨别评价指标高于原数据,并且最佳的阶数为0.1和0.2,随着阶数的增加,辨别准确度有所下降,但是仍高于原始光谱数据。由此可以构建一个新的玉米叶片重金属(Cu、Pb)污染信息高光谱遥感辨别模型——FD-CARS-MLP模型。
3.4 辨别模型验证
为了验证FD-CARS-MLP模型的可行性,选择拔节期、抽穗期重金属(Cu、Pb)胁迫的玉米叶片进行验证,分数阶微分选择效果最好的0.1、0.2阶进行验证,结果如表2所示。
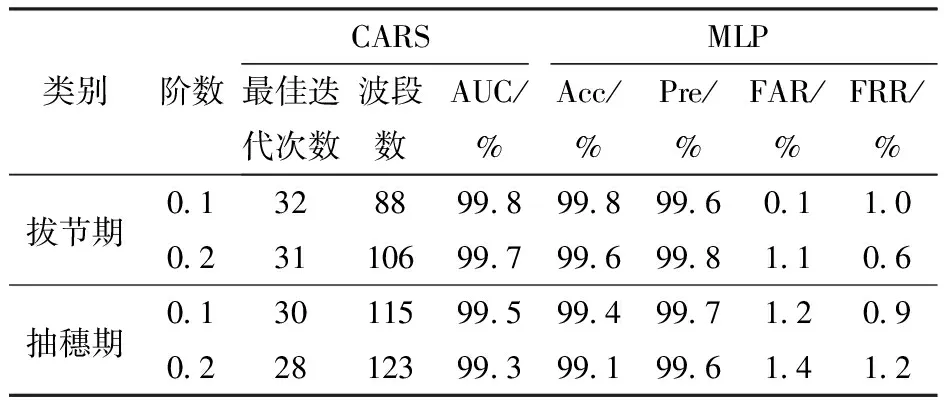
表2 FD-CARS-MLP模型验证
由表2可知,运用高光谱数据的分数阶微分处理结果,FD-CARS-MLP模型对于受胁迫的玉米叶片Cu、Pb污染信息辨别的精度较高且更稳定,为监测谷类作物不同胁迫的重金属污染监测提供了技术与方法。
4 结论
(1)光谱数据经分数阶微分处理后,许多光谱特征被加强,能够获取到更多细节信息,相较于原始光谱数据更有利于污染信息的辨别,试验可得,所有经过分数阶微分处理光谱数据的辨别精度均大于原数据,其中0.1、0.2阶的分数阶微分效果最好,数据辨别评估指标AUC、Acc、Pre的精度可以达到99%以上,FAR、FRR的精度可以达到1%以下。
(2)CARS相较于传统的特征光谱波段提取方法,可以涵盖每一组特征波段组合,更加全面化,且不用手动调整参数,更加方便快捷,CARS可以通过算法直接给出最佳的特征波段组合,使特征波段的选择更加智能化。
(3)经试验证明,FD-CARS-MLP模型可以有效地对受胁迫的叶片光谱数据进行Cu、Pb污染信息辨别,该模型的辨别评估指标AUC、Acc、Pre可以高达98%以上,FAR、FRR可以达到2%以下。FD-CARS-MLP模型辨别玉米在生长过程中受重金属胁迫的叶片污染信息效果良好,并且具有较好的可靠性和稳定性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
数学物理学报(2021年2期)2021-06-09
数学物理学报(2019年5期)2019-11-29
广东技术师范大学学报(2016年5期)2016-08-22
高师理科学刊(2016年8期)2016-06-15
中国光学(2015年5期)2015-12-09
西藏科技(2015年4期)2015-09-26
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19
河北北方学院学报(自然科学版)(2014年2期)2014-05-30
食品工业科技(2014年23期)2014-03-11
