
基于Transformer的实时语义分割网络及应用
2023-09-22 09:01:14郑天宇丁一铭
激光与红外 2023年8期
刘 青,李 宁,熊 俊,郑天宇,丁一铭
(北京卓越电力建设有限公司,北京 100027)
1 引 言
随着电力系统发展,电缆隧道、综合管廊数量迅速增长,应用机器人替代人工巡检并完成应急处置是必然趋势。电缆隧道巡检机器人的应用,对保障电网安全运行具有重要意义。研究人员通过开发一系列电网巡检机器人[1-3],不仅实现了对电网设备运行状态和环境的实时监测,提高了巡检过程的自动化程度、准确度及精度,也实现了机器对人工的替代,降低了运维人员的作业风险,提高了工作效率。
近年来,以深度学习为中心的机器学习技术饱受人们关注。在机器人应用逐渐广泛化的过程中,机器人场景理解成为当前研究的热点内容。目前,语义分割作为解决机器人场景理解的关键性技术[3-5],其主要任务是将图像中的每个像素链接到类标签。语义分割的结果图可以帮助机器人理解场景并辅助完成规划路径或紧急避障。
目前图像语义分割可分为基于全卷积编解码、基于扩张卷积、基于注意力机制以及基于语义细节双分支的方法等。全卷积神经网络(Fully Convolutional Network,FCN)在语义分割领域应用广泛[5],它能够获取任意大小的图像并生成相应空间维度的输出,采用像素级损失和网络内上采样来增强密集预测。针对全卷积神经网络在语义分割时感受野固定和分割物体细节容易丢失或被平滑的问题,Vijay等人提出SegNet网络[6],采用池化索引保存图像的轮廓信息并降低参数量。Olaf等人提出了U-Net网络[7],在U型对称结构中加入跳跃连接融合相同分辨率上采样及下采样特征图,对医学图像产生更精确的分割。Simon等人提出FC-DenseNets网络[8],通过将网络层与后续层建立密集连接完成特征的复用。基于全卷积对称语义分割模型得到分割结果较粗糙,忽略像素之间的空间一致性关系,因此,Chen等人提出Deeplab网络[9],采用扩张卷积增加感受野获得更多语义信息[10],并使用完全连接条件随机场提高模型捕获细节的能力。Deeplab-V2增加空洞空间金字塔池化模块,利用多个不同采样率的扩张卷积提取特征,再将特征融合以捕获不同尺度的语义信息[11]。Deeplab-V3在空洞空间金字塔池化模块中加入了全局平均池化,同时在多尺度扩张卷积后添加批量归一化,有效捕获全局语义信息[12]。由于卷积层结构限制,提供的上下文信息不足。因此,Wang等人受计算机视觉中经典的非局部均值启发,提出Non-local建立图像上相距较远像素之间的联系[13]。Fu等人引入通道及空间注意力机制,更好聚合不同类别之间的上下文信息[14]。Huang等人提出交叉循环注意力,更好捕获上下文信息的同时大量减少计算量[15]。近年来,受到自然语言处理领域中Transformer成功应用的启发[16],尝试将标准的Transformer结构直接应用于图像[17],将整幅图像拆分成小图像块,经过线性嵌入后作为输入送入网络中,使用监督学习的方式进行图像分类的训练。
由于上述方法非常耗时,因此不能直接部署在机器人上,轻量级分割算法越来越受到关注[18-22]。Yu等人提出了一种由细节和语义分支组成的新型双分支网络BiSeNet[23],网络架构如图1(a)所示,主要包括语义分支、空间分支以及融合模块。语义分支首先使用轻量级骨干网络Xception[24]通过快速下采样特征学习,获取足够的感受野,同时采用全局池化来降低计算量,稳定最大感受野。下采样的特征图再经过注意力优化模块,借助全局平均池化捕获上下文语义信息,计算注意力向量,优化语义分支中的输出特征。空间分支主要负责保留空间信息并且生成高分辨率特征,通过3个Conv-BN-ReLU(ConvBR)卷积层将输入图像降采样到原始图像的1/8。特征融合模块首先将两种特征进行通道连接,经过一个ConvBR卷积层后,使用残差结构对原始特征及注意力优化后的特征进行融合。最终直接采用双线性插值上采样到原图像分辨率,得到图像的分割结果。这种双分支网络实现比当时基于编解码器的方法[25]更高的分割精度。
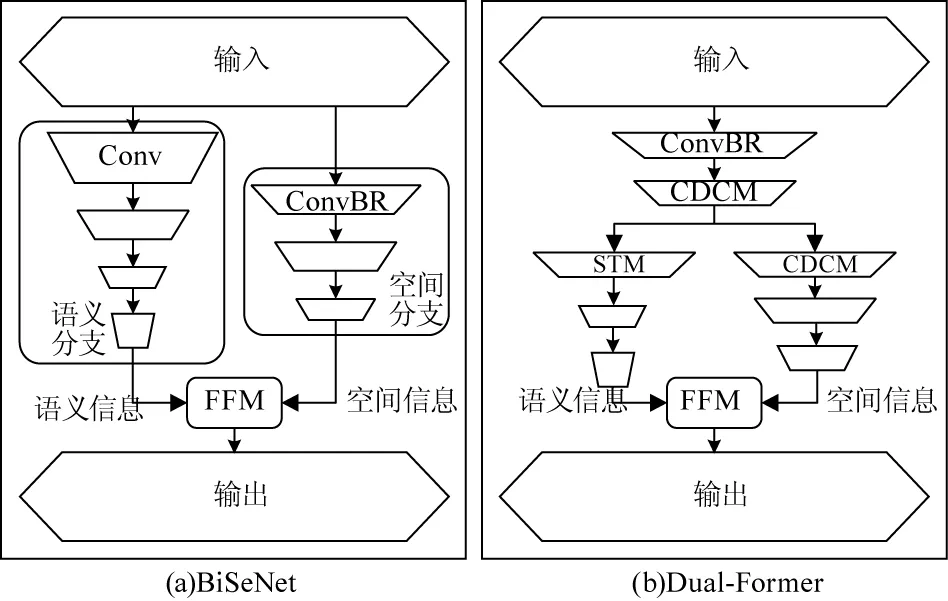
图1 网络架构
针对以上的分析,本文设计了一种新型网络架构Dual-Former,如图1(b)所示。网络中设计了分割Transformer模块(Segmentation Transformer module,STM)和通道递减卷积模块(Channel Decreasing Convolution Module,CDCM)分别提取语义和细节信息,最后通过特征融合模块(Feature Fusion Module,FFM)将底层的空间细节信息和深层的上下文语义信息融合得到不同尺度的图像特征,获得良好的分割结果。
2 基于Transformer的语义分割网络
在语义分割任务中,图像的全局上下文语义信息和局部细节信息对于分割结果至关重要,BiSeNet采用双分支框架,将低级细节和高级语义信息结合起来,然而,添加额外的分支来获取低层特征是耗时的,并且BiSeNet提取的语义和细节信息十分粗略,经过融合后物体边界分割模糊,不同类别存在混淆,无法得到精细的分割结果。为此,构建了基于Transformer的语义分割网络,并提出分割Transformer模块、通道递减卷积模块和特征融合模块以提升模型分割能力。
2.1 网络架构
基于Transformer的语义分割网络的架构如图2所示,该网络由特征提取主干、语义分支、空间分支及融合分割部分组成。特征提取主干首先使用卷积核大小为3×3,步长为2的ConvBR卷积层和步长为2的通道递减卷积模块将原始图像下采样至原始分辨率的1/4,特征提取主干将图像下采样的同时,能够较好保留图像的原始信息与特征,解决了BiSeNet使用双分支获取低层特征造成计算冗余的问题,便于特征语义和细节信息的提取。语义分支使用Transformer提取图像全局上下文语义信息,每层逐渐降低特征图分辨率并加深通道数,经过注意力优化后获取更深层的语义信息,最后对特征图进行上采样到原始分辨率的1/8。细节分支首先使用步长为2的通道递减卷积模块对特征图进行下采样到原始分辨率的1/8,经过通道递减卷积模块的特征图能够更好保留图像的多尺度细节信息。然后使用两个步长为1的通道递减卷积模块,提取高分辨率特征图的局部细节信息。由于保持特征图分辨率维持在原始分辨率的1/8,能够更好提取原始图像中的细节信息。融合分割部分首先经过特征融合模块,由于两分支的输出不属于同一种特征,因此不能使用简单相加的方式对特征进行融合。特征融合模块将语义和细节分支的特征图采用通道维度叠加,即将语义分支特征图通道与细节分支特征图通道进行级联,经过通道注意力选取特征。之后经过分割模块,采用一个3×3的ConvBR卷积层和一个3×3的卷积层将特征图的通道映射到实际分割任务的类别数目,出于速度的考虑,最后使用简单的双线性插值将编码阶段变小的特征图还原到输入图像分辨率,从而达到与标签一一对应的分割效果,实现端到端的训练。

图2 Dual-Former网络整体架构
2.2 语义分割
语义分割的目标是识别每一个像素,要分割的对象或内容经常受尺度、光照和遮挡的影响,由于卷积运算本身属于局部操作,使用卷积神经网络获取高级语义信息需要通过不断地堆积卷积层来完成对图像从局部信息到全局信息的提取,不断堆积的卷积层慢慢扩大了感受野直至覆盖整个图像。具有相同标签的像素的特征可能具有一些差异,这些差异因感受野受限被放大,引入了类内不一致性并影响了卷积神经网络的识别准确性。由于Transformer将一幅图像分割成小图像块作为输入,不需要叠加就可以获得与输入大小相同的感受野,能够较好解决感受野受限问题,并提取图像全局信息。
分割Transformer模块如图3所示,首先将小图像块进行位置编码与向量化,特征图维度从(C,H,W)转化成(C,N(H×W)),其中C代表通道数,H和W代表高和宽。然后向量作为Transformer编码器的输入,经过多头注意力对输入分别乘以三个随机初始化的矩阵WQ,WK,WV,便得到了三个矩阵Q,K,V。多头注意力计算过程如公式(1)所示,式中dhead代表注意力头的数量(本文取3),经过注意力的优化后作为多层感知机(MLP)提取深层语义信息,扩大模型感受野,能够更好捕获特征图的高级特征。
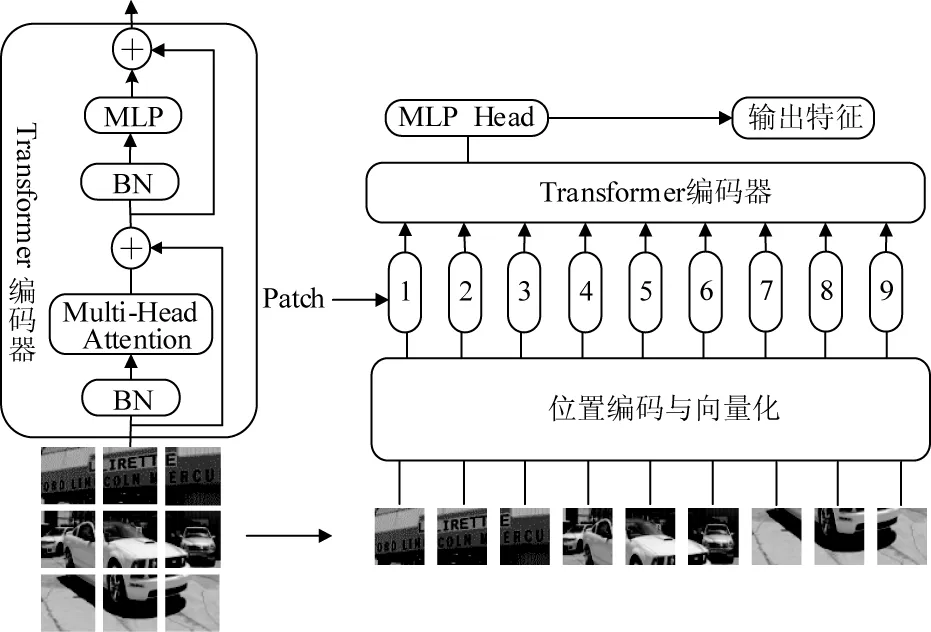
图3 分割Transformer模块
(1)
视觉Transformer使用显式位置编码引入位置信息[16],然而,显式位置编码的分辨率是固定的,因此当测试分辨率不同于训练分辨率时,需要对位置编码进行插值,这通常会导致精度下降。为了缓解这个问题,使用padding为0的3×3卷积对小图像块进行隐式位置编码,实验结果证明3×3卷积足以为Transformer提供位置信息。
大学生对工作岗位陌生,对工作环境和人际关系不适应,学校的理论知识与实际工作存在差异等。面对这些问题,校企双方要共同协商解决。企业导师制有效解决了此方面的难题[4]164-166。企业专业导师不仅能够帮助学生快速熟悉业务,获得专业技能,还能以其独特的人格魅力感染学生,掌握实际工作中应具备的职业道德和敬业精神,深化岗位认知,快速适应新环境,胜任新工作。
2.3 细节分支
语义分割任务需要区分空间中的每类样本,用于分割的特征需要保留更多细节特征。低层特征有助于网络生成精细的分割边界,降采样操作虽然能够降低模型计算量,但同时也伴随着细节信息的丢失,使得网络在细小目标和目标边缘上性能下降。
细节分支将特征图的分辨率只下采样到原始分辨率的1/8,保持高分辨率的特征图来更好获取图像中的细节信息。通道递减卷积模块如图4所示,图4(a)代表步长为1的通道递减卷积模块,其中M和N分别代表输入和输出通道数,首先使用3×3的ConvBR卷积层将特征通道从M映射到N/2,再使用两个3×3的ConvBR卷积层依次对特征通道进行递减,考虑到最后一层特征图通道数量较少,因此,使用1×1的ConvBR卷积层提取最后的细节特征。在图像分类网络中,在更高层使用更多通道是一种常见的作法,但是在语义分割任务中,我们关注的是可扩展的感受野和多尺度信息。通道递减卷积模块各层感受野如表1所示,低层需要足够的通道来编码较小感受野的细粒度信息,较大的感受野更注重于高层的语义信息,由于所提算法将高层特征提取的重心放在语义分支上,因此,如果与低层设置相同的通道可能会造成信息冗余。图4(b)代表步长为2的通道递减卷积模块,其中下采样操作只在Block2中进行。为了丰富特征信息,通过跳跃连接将x1到xn的特征图连接。CDCM的输出如公式(2)所示。
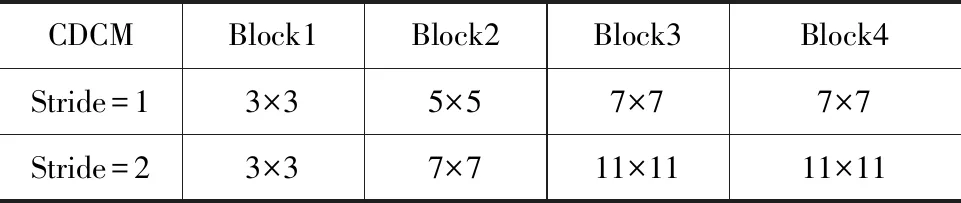
表1 CDCM中不同Block的感受野

图4 CDCM结构
xoutput=F(x1,x2,…,xn)
(2)
式中,xoutput表示CDCM模块的输出;x1,x2,…,xn是所有块的特征图;F代表特征的融合方式,考虑到效率,采用通道融合的方式对特征图进行连接。在细节分支中,由于保持特征图分辨率维持在原始图像的1/8,采用一个步长为2和两个步长为1的通道递减卷积模块。该模块的输出连接所有特征图,并采用通道数递减的方式保留了可缩放的细节和多尺度信息。
2.4 融合模块
在特征表示的层面上,上述双分支的特征并不相同。因此不能简单对双分支的输出特征进行加权。由空间分支捕获的空间信息编码了绝大多数的丰富细节信息,而语义分支的输出特征主要编码语义信息。换言之,空间分支的输出特征是低层级的,语义分支的输出是高层级的。因此,设计了一个独特的特征融合模块,如上文图2所示,它首先将双分支输出特征在通道维度上级联,采用全局平均池化产生通道相关的统计信息,然后使用1维卷积生成通道特征表达,最后通过Sigmoid激活函数计算权重向量,该权重向量可以对特征重新加权,相当于特征选择和组合,能够将双分支的输出特征进行较好融合。
3 实验与结果分析
所提方法在两个公开数据集Cityscapes、CamVid上同当前其他算法进行了对比,并对所提出STM及CDCM在Cityscapes数据集上进行消融实验,进一步扩展到电缆隧道的应用场景中。
3.1 实验平台及数据集
实验平台操作系统为Windows 10,显卡是Nvidia GeForce GTX 3060,12 G显存,CUDA版本为11.1,内存32 GB,CPU为英特尔酷睿i7-11700 2.5 GHz,网络结构基于Pytorch平台实现。
Cityscapes是关注城市街道场景解析的知名数据集之一[26]。它包含2975个用于训练的精细注释图像、500个用于验证的图像和1525个用于测试的图像。在训练过程中,所提算法不使用额外的20000个粗糙标记的图像。其中共有19个类可用于语义分割任务。由于图像的分辨率为1024×2048,因此对语义分割任务具有一定的挑战性。
CamVid是一个由剑桥大学采集并标注的道路场景数据集[27],它是从驾驶汽车的角度拍摄的。该数据集包含从视频序列提取的701幅带注释的图像,其中367幅用于训练,101幅用于验证,233个用于测试。图像分辨率为960×720,有32个语义类别,其中11个类别的子类用于进行语义分割。
3.2 网络参数
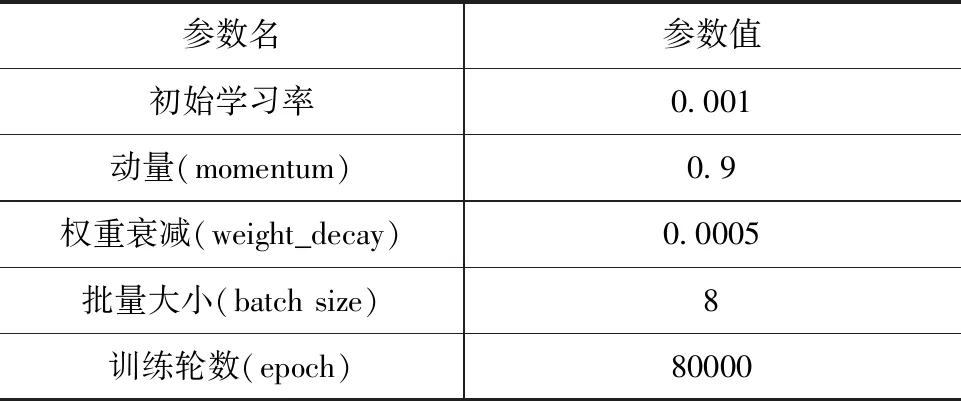
表2 网络参数
3.3 评估指标
本文使用语义分割任务中常用评估指标mIoU(mean intersection over union),即所有类别交集和并集之比的平均值,其计算过程如公式:
(3)
式中,k表示像素的类别数;pii表示实际类别为i类,且实际预测类别为i的像素数目,同理,pjj表示实际类别为j类,且实际预测类别为j的像素数目;而pji表示实际类别为i类,而实际预测类别为j的像素数目。ti表示i类像素的总数。
3.4 实验对比分析
将所提算法与其他方法进行对比,在Cityscapes数据集分割效果对比如表3所示。与BiSeNet相比,所提算法在Cityscapes数据集上的mIoU值提高了8.8 %,证明所提算法采用特征提取主干替代BiSeNet双分支网络架构对分割精度的影响较小,并且模型提取图像语义及细节信息的能力更强。相比于FCN[5]和Dilation10[10]等非实时分割算法,分割精度分别提升11.9 %、10.1 %,FPS帧数分别提升20.2倍、160.6倍。
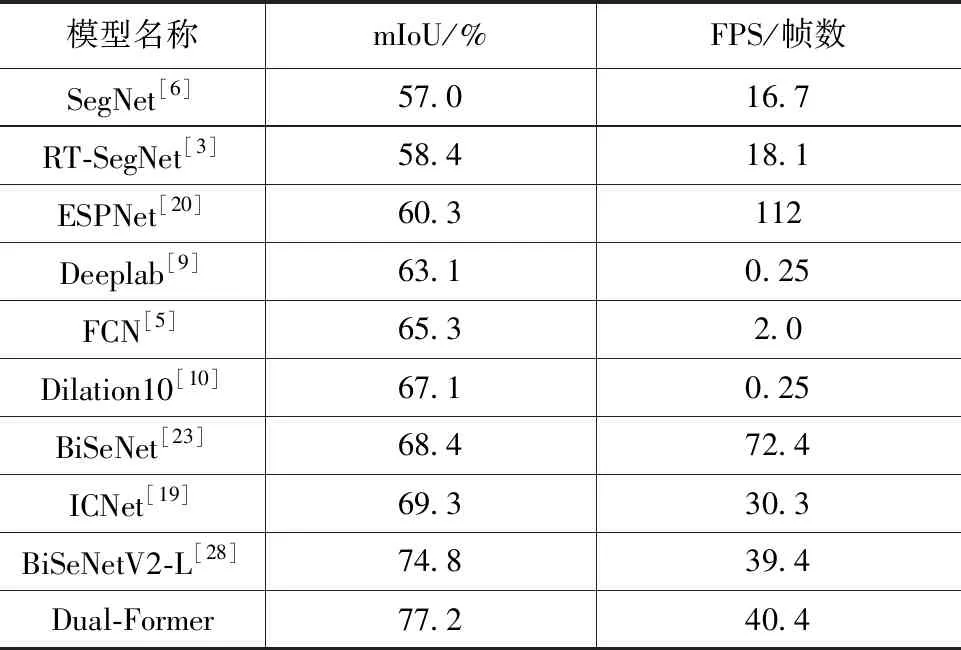
表3 Cityscapes分割效果对比
在Cityscapes数据集的分割结果如图5所示,其中第一、四行代表原始图像与分割标签,第二、三行分别代表BiSeNet和Dual-Former分割结果,由图5(a)可以看出,相比于BiSeNet对一些边缘细节分割的不连贯性,所提算法对于物体边界细节分割更为精确,证明Dual-Former提取细节信息能力更强;从图5(b)中得出,相比于BiSeNet会产生误分类的现象,比如:树林中混入卡车,引擎盖中混入道路等,所提算法通过STM提取多尺度的上下文信息,增强了像素之间的依赖,较好解决误分类的问题,证明Dual-Former提取上下文信息能力更强;从图5(c)中发现,相比于BiSeNet对远距离及小尺度物体分割误分类及边界粗糙的问题,所提算法展现对其优良的边界细节分割以及精准分类能力,这在电缆隧道机器人环境感知任务中至关重要。在分辨率为512×1024图像测试时FPS帧数达到40.4,同时分割精度提高8.8 %,完全满足机器人实时分割的需求,证明Dual-Former更适应于电缆隧道机器人环境感知任务。

图5 Dual-Former与BiSeNet分割结果
CamVid[27]数据集分辨率较小,但训练图像数量相比于Cityscapes数据集锐减,因此考验模型在有限数据情况下精准分割的能力。所提方法在CamVid数据集上同其他方法的分割精度如表4所示。
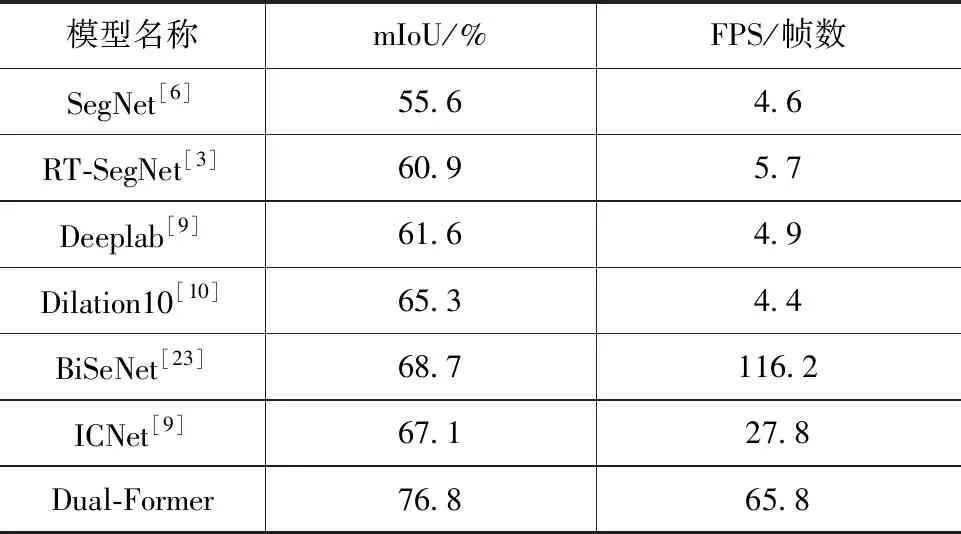
表4 CamVid分割效果对比
所提算法在CamVid数据集上达到了76.8 %的mIoU值,相比BiSeNet提高了8.1 %,证明Dual-Former面对较小数据集仍能保持较好的分割精度,模型鲁棒性较强。相比于SegNet[7]和Deeplab[10]等非实时分割算法,分割精度分别提升21.2 %、15.2 %,FPS帧数分别提升13.3倍、12.5倍。
3.5 消融实验
为了验证用于提取细节语义信息的CDCM和STM的有效性,将所提方法在Cityscapes数据集上进行消融实验,实验结果如表5所示。

表5 消融实验结果
由于本文所提算法是在BiSeNet网络基础上,针对其提取语义和细节信息能力进行改进。因此针对细节和语义分支中的CDCM和STM以及FFM分别设计消融实验,从表5实验结果可以得出,所提出的CDCM在增加少量计算量情况下,减少特征图的下采样操作,保留特征图的空间细节信息,并将卷积后的特征图通道数进行逐步衰减,并使用它们的聚合作为图像的特征表示,减少特征图的冗余信息。增强细节信息的提取,能够对物体边界产生精准的分割,提升模型mIoU值2.3 %。而STM得益于Transformer强大的提取图像全局信息的能力,其相比于卷积神经网络具有更大的感受野,能够更好学习像素之间的相关性。利用注意力的方式来捕获全局的上下文信息从而对远距离的像素建立相关性,从而为网络获取更丰富的上下文语义信息,能够较好解决分割类别混淆的问题,提升模型mIoU值4.2 %。FFM利用可忽略的参数量和较少的计算量融合双分支的输出特征,通过通道注意力机制对特征进行选择和组合,以较小的开销进一步提升模型分割效果,模型mIoU值提升2.3 %。根据消融实验可以得出,本文提出的CDCM和STM具有较好改善网络提取细节和语义信息的能力。
3.6 电缆隧道机器人环境感知
由于语义分割数据集标注困难,工作耗时,因此首先使用Cityscapes数据集对网络进行预训练,再将少量隧道内采集并完成标注的图像在模型上进行迁移学习。其中,隧道分割数据集将训练集与测试集划分为8∶2,以获得更好的分割效果。
由图6可知,所提出的分割网络可以有效地迁移至电缆隧道场景中,相对于标准数据集,电缆隧道数据集目标类别种类较少,但背景却更多、更复杂,因此在物体边界分割精度有一定下降,但能够保障机器人实际应用的效率。

图6 电缆隧道分割结果
为方便变电站巡检机器人实际应用,采用固定位姿的摄像头获取变电站道路图像。对于机器人前方目标的判断,则通过对固定摄像头位姿下图像进行语义分割,根据分割结果获取图像中固定区域各类别像素个数,并选择像素最多的类作为前方目标。对于巡检机器人偏离道路情况采用对比分割图像中左右固定面积区域的道路像素个数来判断。
从图6(a)中可以看出,所提算法对电缆隧道内可行走道路进行良好分割,并精准分割两旁电缆及工作人员的边界;从图6(b)中可以看出,所提算法对隧道内工作人员的分割较为精细;从图6(c)中可以看出,所提算法对隧道内电缆的分割较为精细;从而提升机器人整体环境感知能力及避障能力。
4 结 论
电缆隧道巡检机器人能够有效提高工作人员的安全系数并减少人员的劳动强度,缓解电力部门目前存在的结构性人员缺失状况,为提升电缆隧道场景机器人环境感知能力,提出新型语义分割网络架构Dual-Former,图像首先经过统一主干网络进行下采样并减少特征的损失。最终通过FFM融合STM和CDCM的语义和细节信息,突出低级特征细节信息和高级全局信息,提高分割效果,并在Cityscapes数据集上达到77.2 %的mIoU以及40.4的FPS,进一步应用在电缆隧道机器人中,保证实时分割的前提下,拥有较好的分割精度。提高智能化电网的运营能力,为电力部门做出贡献。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
开放教育研究(2020年2期)2020-03-31 01:54:14
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
学生天地(2019年28期)2019-08-25 08:50:54
数学物理学报(2018年1期)2018-03-26 08:16:36
现代语文(2016年21期)2016-05-25 13:13:44
CHIP新电脑(2016年3期)2016-03-10 14:22:03
大连民族大学学报(2015年2期)2015-02-27 08:28:11
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
