
基于模板匹配的搜索引擎粗糙集特征检索
2023-09-21 01:36:46王学军
物联网技术 2023年9期
王学军
(广州华立学院,广东 广州 511325)
0 引 言
随着网络信息技术的发展,采用搜索引擎实现网络数据信息管理和检索成为常态。搜索引擎检索数据,是在信息化体系构架下,进行搜索引擎粗糙集查询;结合知识结构图模型设计,建立搜索引擎粗糙集查询数据的检索和特征匹配模型,构建搜索引擎粗糙集查询数据信息和文献资源的数据分析模型,能够提高数据检索的精准度。相关的搜索引擎粗糙集特征检索方法研究受到了人们的极大关注[1]。
对搜索引擎粗糙集查询数据信息检索是建立在对大数据信息结构特征分析技术上的,采用统计特征分析方法,建立基于大数据分析和云计算技术的搜索引擎粗糙集特征检索模型[2-3]。文献[4]中提出基于大数据分析的搜索引擎粗糙集查询数据融合方法,结合耦合参数匹配和信息重组方法实现搜索引擎粗糙集特征检测,但采用该方法进行数据检索的实时性不好。文献[5]采用联合关联规则性挖掘的方法,实现搜索引擎粗糙集查询数据信息检索的特征分析,建立搜索引擎粗糙集查询数据信息检索的联合特征匹配模型实现引擎检索,但该方法的计算负载较高。针对上述问题,本文提出基于模板匹配的搜索引擎粗糙集特征检索方法。首先采用稀疏性字典匹配集存储机制构建搜索引擎粗糙集查询数据信息的分块网格化词义结构模型;然后建立搜索引擎粗糙集查询的模板匹配参数,采用模板匹配和自适应参数估计的方法,通过关联规则调度,建立搜索引擎粗糙集查询数据信息匹配和检索的寻优学习模型;通过粗糙集语义参数估计,结合特征聚类方法实现搜索引擎数据检索。最后进行仿真测试,结果表明,采用本文方法进行搜索引擎粗糙集检索的查准率较高,检索匹配能力较好。
1 搜索引擎粗糙集查询数据结构特征分析
1.1 搜索引擎粗糙集查询数据结构模型
为了实现搜索引擎粗糙集查询数据信息检索,结合高层语义之间的语义特征分析和密度聚类分析,构建搜索引擎粗糙集查询数据信息检索的特征匹配模型,采用关联规则融合和相似度特征检测,进行搜索引擎粗糙集查询数据信息的特征检测和粗糙集参数查询[6]。根据空间分布状态特征得到搜索引擎粗糙集查询数据结构分布如图1 所示。
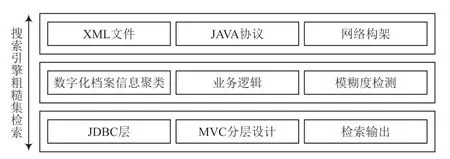
图1 搜索引擎粗糙集查询数据结构分布
根据图1 所示的搜索引擎粗糙集查询数据特征分布,采用模糊引擎查询调度的方法,得到搜索引擎粗糙集的HOG特征,构建搜索引擎粗糙集查询数据的样本平均分布集,得到差异度匹配集Ei,j=
式中:PT-elec为搜索引擎粗糙集查询数据的语义属性;R为语义本体特征;LDATA为用户的交互项目与被推荐项目的自由度;LACK为描述复杂特征信息的知识图谱参数。根据搜索引擎粗糙集查询数据的样本构造特点,得到模糊度检测参数t,给定一个数据集S={x1, ...,xm},用元路径或元图向量x=[x1x2...xk]表示搜索引擎粗糙集查询数据信息检索的统计特征量。根据M1,M2, ...,MN的聚类性,得到搜索引擎粗糙集查询数据的特征匹配结构式为:
式中:
式中:DIFS 为搜索引擎粗糙集查询数据的描述统计特征量;tDATA为知识图谱卷积网络图谱参数采样时间间隔;tslot为用户与项目之间的细粒度;tT-start为检索开始时间;SIFS 为差异化概率密度。根据上述分析,采用稀疏性字典匹配集存储机制构建搜索引擎粗糙集查询数据信息的分块网格化词义结构模型,实现粗糙集特征分配检索[7]。
1.2 搜索引擎粗糙集查询数据检索特征匹配
在计算学习者嵌入表示的过程中,根据搜索引擎粗糙集查询的分组检测结果,将邻居节点信息聚合到当前节点,得到检索关键词匹配参数为,搜索引擎粗糙集查询数据的梯度聚类函数为:
式中:l为搜索引擎粗糙集的边缘分布特征;Ecomm为局部的近似结构及特征;pdrop为联合自相关统计特征量,给定交互矩阵与知识图谱,得到搜索引擎粗糙集查询数据信息的模糊集分布为:
式中:v表示聚合邻居实体;c(v)为学习资源l的拓扑结构信息。学习资源的嵌入聚合实体的权重分量,分单元格表示为:
式中:Pk+1|k为聚合实体的权重分配概率密度;Gk+1为知识图谱中实体的邻域分配系数,为其转置特征量。通过模糊字节特征匹配方法,建立搜索引擎粗糙集查询的模板匹配参数分配模型[8]。
2 搜索引擎粗糙集查询数据信息检索优化
2.1 搜索引擎粗糙集查询数据信息融合处理
设nz为搜索引擎粗糙集查询数据信息检索节点数,引入搜索引擎粗糙集查询数据语义的属性分类策略,采用分组检验,得到搜索引擎粗糙集查询数据信息检索的粗糙集为:
式中:N为交互数据的语义序列长度;x为搜索引擎的知识图谱分布;τ为时间延迟。由此,建立搜索引擎粗糙集查询数据的语义自动分配目录,根据粗糙集特征分配,进行模板匹配和语义检索[9]。
2.2 搜索引擎粗糙集查询数据特征检索
建立搜索引擎粗糙集查询的模板匹配参数分配模型,采用模板匹配和自适应参数估计的方法,通过关联规则调度,得到层次聚类中心为Mi和Mj;采用粗糙集特征匹配的方法,得到搜索引擎粗糙集查询数据信息检索的层次密度聚类输出为Clustdist(Mi,Mj)。当(i≠j, 1 ≤i≤q, 1 ≤j≤q)时,搜索引擎粗糙集查询数据语义属性的聚类输出的时间概率密度函数表示为:
式中:Xp为搜索引擎粗糙集查询数据信息语义分布的源信息;u为搜索引擎粗糙集查询数据的粗糙度;v为搜索引擎粗糙集匹配度特征量。建立模糊度匹配模型,得到模糊边缘匹配系数为的边缘向量值,用四元组(Ei,Ej,d,t)来表示大数据背景下引擎粗糙集的融合度,得到信息融合输出:
式中:σs为学习状况和学习满意度的联合匹配泛函;X1为学习者行为参数;H为信息熵。设搜索引擎粗糙集查询数据的采样周期为Ts,则每个周期包含的搜索引擎粗糙集查询数据信息数据点数m=T/Ts。采用类型化的模板参数匹配,实现对搜索引擎粗糙集查询数据知识结构图模型的匹配[10-12]。
3 仿真实验与结果分析
通过MATLAB 仿真实验验证本文方法在搜索引擎粗糙集特征检索中的应用性能,实验中以图片检索为例,图片采样大小Q设置为4,相似度为0.28,学习率为0.001,待检索图像如图2 所示。
图2 搜索引擎待检索图
以图2 为研究对象,采用本文方法进行模板匹配和粗糙集特征提取,实现图像检索,结果如图3 所示。

图3 搜索引擎信息检索结果
分析图3 可知,采用本文方法进行搜索引擎粗糙集特征检索的模板匹配性能较好,匹配精度较高。测试检索的查准率,对比结果如图4 所示。分析图4 可知,本文方法的查准率更高,性能优于传统方法。
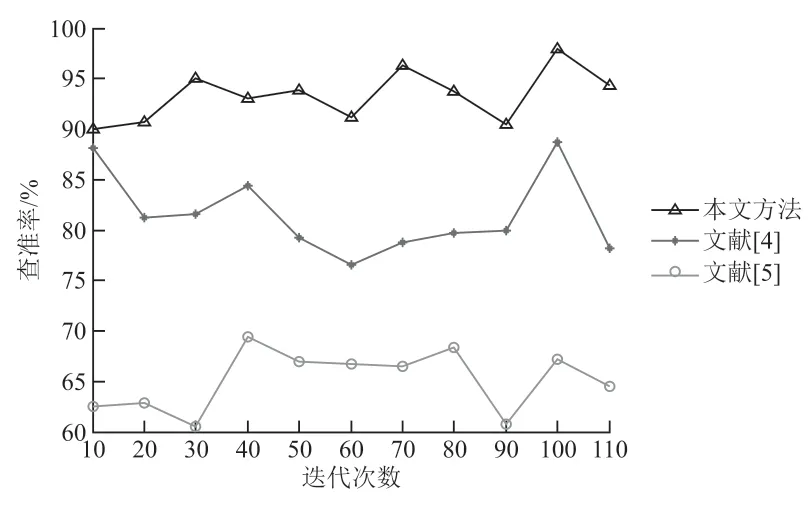
图4 查准率对比
4 结 语
结合知识结构图模型设计,建立搜索引擎粗糙集查询数据的检索和特征匹配模型,能够提高数据检索的精准度。本文提出基于模板匹配的搜索引擎粗糙集特征检索方法。采用稀疏性字典匹配集存储机制构建搜索引擎粗糙集查询数据信息的分块网格化词义结构模型,实现粗糙集特征分配检索;采用类型化的模板参数匹配,实现对搜索引擎粗糙集查询数据知识结构图模型的匹配。分析得知,本文方法对搜索引擎粗糙集特征检索的匹配性和查准率较高。
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
新闻传播(2016年18期)2016-07-19 10:12:06
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
现代计算机(2016年11期)2016-02-28 18:35:15
中国卫生(2015年12期)2015-11-10 05:13:38
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:21
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
河南科技(2014年11期)2014-02-27 14:10:19
