
RTS游戏中基于强化学习的行动参数配置优化
2023-09-20 10:36:50臧兆祥郭鸿村
计算机仿真 2023年8期
田 佩,臧兆祥,张 震,郭鸿村
(1. 三峡大学水电工程智能视觉监测湖北省重点实验室,湖北 宜昌 443002;2. 三峡大学计算机与信息学院,湖北 宜昌 443002;3. 重庆对外经贸学院大数据与智能工程学院,重庆 401520)
1 引言
RTS游戏[1],[2]是一种即时的、非回合制的游戏,需要agent在游戏中承担侦察获取敌方信息、更新己方当前兵力资源信息、实施作战策略等任务。星际争霸作为一种典型的RTS游戏,DeepMind团队运用深度强化学习算法训练AlphaStar[3],训练完成后,AlphaStar在Battle.net上的排名超过了99.8%的活跃玩家。不仅是游戏领域,作战模拟领域中也广泛运用人工智能技术[4]。利用数据、知识和规则等,结合机器学习方法[5],建立和优化推演过程中各类行动实体的决策模型,为作战方案分析,战法试验分析等提供数据支撑,并使分析结果更具有说服力,学习结果更具高置信度。2017年美国提出“算法战”,启动了认知智能在军事领域中的探索和应用,并于2020 年2月发表研究报告[6],进一步明确智能化战争的核心技术路线,即人工智能技术和自主化系统。其中人工智能主要是用于开发决策辅助工具,用来协助指挥官管理快速而复杂的作战行动,提升决策优势,进而取得竞争优势。
寻求作战单位行动指令的最优参数配置,总体而言是一个抽象化的最优化问题[7],但是传统的优化算法例如梯度下降算法[8]等,有明确的目标函数要求,智能优化算法例如遗传算法[9]等,局部搜索能力较差,且收敛速度慢。强化学习[10]作为机器学习[11]的一个重要方向,主要用于描述和解决智能体在与环境的交互过程中,通过学习策略达成最大奖赏值或者实现特定目标的问题。强化学习算法[12]不仅可以学习优化参数配置,还能实现在线更新。因此,针对传统算法的不足之处,提出了使用强化学习中的Q-Learning算法[13],并借助游戏仿真平台,对游戏中作战单位的行动指令参数配置进行优化,寻求使其自身行动结果和效果最好的参数配置。
2 强化学习算法
2.1 基本原理和模型
强化学习[10],其思想是智能体处在一个无人指导的环境中,通过自身的不断试错和与环境所提供的反馈,来纠正自己执行的动作,以期最大化目标收益。基本模型图如图1所示。

图1 强化学习基本原理图

图2 游戏平台战场地图
Agent在与环境的交互过程中,每一时刻会发生以下事件:
1)Agent在t时刻从环境中获取一个状态st;
2)根据当前状态和即时奖励或惩罚rt,选择一个动作at;
3)当Agent选择的环境作用于环境时,会从状态st,转移至下一个状态st+1,并且获得一个即时的奖励或惩罚rt;
4)rt反馈给Agent,t←t+1;
5)返回第2)步,如果新的状态是结束状态,结束循环。
其中A是一组动作集,动作a∈A,rt由st和at决定。
2.2 Markov决策过程
强化学习中Agent与环境的交互过程,如果Agent下一时刻的状态只与当前状态有关,而与其之前状态均无关,称该过程具备马尔科夫特性,则可以将该过程建模成Markov决策问题[11]。
具体过程为:先考虑一个有限的随机过程,状态集合S,动作集合A,at表示Agent在t时刻采取的动作,psi sj(at)表示Agent在t时刻由于采取动作at而使环境从状态si转移到状态sj的概率,其中at∈A,si,sj∈S。则转移概率为
psisj(at)=p(st+1=sj|st=si,at)
(1)
Markov决策问题的目的是寻找一个最优策略,对于每一个时刻的状态,Agent都会根据最优策略选取最合适的动作。
2.3 Q-Learning算法
Q-Learning算法最早用于求解具有延迟奖励或惩罚的序贯优化决策过程问题,迭代计算公式[13]如式(2)所示
Q(st,at)=Q(st,at)+α[rt+

(2)
其中Q(st,at)是t时刻状态-动作对的值函数,α是学习率,γ是折扣因子且0<γ<1,rt是在状态st下采取动作at到达st+1状态后获得的奖励或惩罚。
Q-Learning算法具体描述如下
给定离散的状态空间和动作空间,学习率和折扣因子,以表格的形式存储值函数Q(st,at),并选择动作。
1)初始化值函数、学习率和折扣因子,令时刻t=0;并观测下一时刻的状态st+1;
2)循环,直至满足终止条件:
a)对当前状态st,选取动作at,并观测下一时刻的状态st+1;
b)根据迭代式(2)更新当前状态-动作对的值函数Q(st,at);
2.4 单步Q-Learning算法
与Q-Learning算法相比,单步Q-Learning算法[14]只考虑一步操作,其目标是最大化单步奖励值,因此在更新值函数过程中,不存在折扣因子γ,迭代计算式(3)所示
Q(st,at)=Q(st,at)+α[rt-Q(st,at)]
(3)
其中Q(st,at)是t时刻状态-动作对的值函数,α是学习率,rt是在状态st下采取动作at获得的即时奖励或惩罚。
3 实验设计
3.1 实验平台介绍
本实验借助一个作战模拟的游戏仿真平台[15]。游戏设置背景和规则:红方作为攻击方,综合运用海空突击和支援保障力量,突破蓝方防空体系,摧毁蓝方两个指挥所;蓝方作为防守方,依托地面、海面和空中立体防空火力,守卫己方岛屿两个指挥所。若在一场游戏时间(150min)内,两个指挥所均被摧毁,判红方胜利;两个指挥所均未被摧毁,判蓝方胜;达到一场游戏时间时,若只摧毁一个指挥所,则统计红蓝双方的战损比和非军事目标误伤比,判优者胜。红蓝双方的兵力设置如表1、2所示,游戏平台战场地图如图1所示。

表1 红方兵力设置
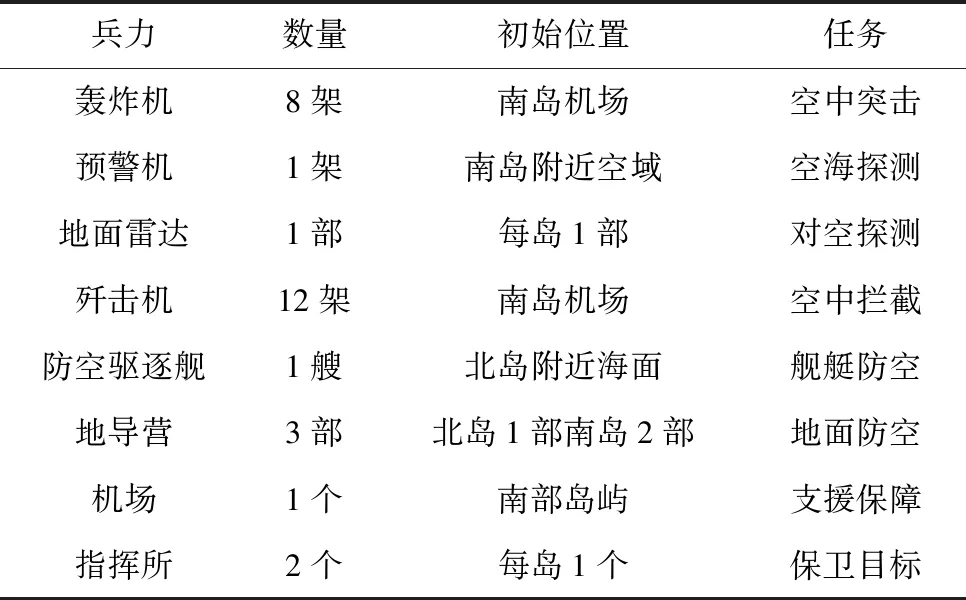
表2 蓝方兵力设置
实验中涉及的作战单位为红方轰炸机、预警机和蓝方防空驱逐舰。实验场景是:红方轰炸机执行起飞目标突击指令突击蓝方舰船,通过实验获取轰炸机突击效率最高的指令参数配置。轰炸机执行起飞目标突击的相关参数:起飞机场编号,起飞数量,敌方平台编号,突击方向([0,360]),武器发射距离与最大射程的百分比([1,100]),突击速度(单位:千米/小时,[600,800])。
3.2 预处理
初始部分设置轰炸机的起飞数量为2,每架飞机配置2枚弹药,护卫舰配置36枚弹药,飞机被击中一次即视为被击毁,护卫舰船被击中3次则视为被击毁。护卫舰船的火力范围100公里,自动攻击距离为最大攻击距离的60%。轰炸机的攻击范围是80公里。因此,实验中对指令的相关参数进行了预处理。
突击方向(direction),将360度离散化成18个点;武器发射距离与最大射程的百分比(range):根据舰船的自动攻击范围和轰炸机的攻击范围限定,武器发射距离与最大射程的百分比从60开始取值,离散化成6个点;突击速度(speed),将单位换算成米/秒,速度范围为166~216,同样离散化成6个点。
3.3 实验设计
根据预处理的结果,初始化一个初始均为0的Q表。Q-Learning算法直接训练的收敛速度比较慢,本文预计使用ε-greedy策略、轮盘赌策略以及Boltzmann Exploration策略来优化动作选择策略,以加快Q-Learning算法的收敛速度。
3.3.1 ε-greedy策略
ε-greedy策略[16]以概率ε随机选择一组参数配置,否则选择具有最大Q值的参数配置,这种方法可以有效地提升Q-Learning算法的收敛速度。
具体描述为:在进入正式迭代之后,在[0,1]之间生成一个随机数,并将生成的随机数与初始设置的探索率epsilon进行比较,根据比较结果的大小关系决定是进入探索阶段,还是进入利用阶段。如果随机数小于初始设置的探索率epsilon,则进入探索阶段,随机选择一组参数配置进行仿真推演,更新该组参数配置对应的Q值;如果随机数大于初始设置的探索率epsilon,则进入利用阶段,即选择Q值最大的一组参数配置进行仿真推演,并更新Q表。

(4)
3.3.2 轮盘赌策略
轮盘赌策略[17]也被称为比例选择方法,基本思想是每一组参数配置被选择的概率与其Q值的大小成正比。计算每一组参数配置被选中的概率:利用每组参数配置所对应的Q值大小Qi(i=1,2,…,M,M是参数配置组数),计算其在所有参数配置Q值之和中的概率p:

(5)
3.3.3 Boltzmann Exploration策略
Boltzmann Exploration策略[18]的思想与轮盘赌策略的思想类似,都是通过概率大小选择动作。不同的是,Boltzmann Exploration策略选择动作的概率是与Q值的指数成正比,即Q值较大的动作更有可能被选择到,而Q值较小的动作被选择到的概率也比较小,但仍然有可能被选择到。

(6)
3.3.4 奖励函数
依据初始设定的轰炸机起飞数量,可知飞机所载弹药数为4。可设置奖励函数:一轮推演中,若飞机没有命中舰船,设置奖励值为0,否则按照每命中一次,奖励值依次加5。
4 实验结果及分析
根据上述实验设计,使用强化学习算法进行训练,对实验结果进行分析讨论,以及验证Q-Learning算法的收敛性。下面将对实验结果结合可视化图表进行研究分析。
首先检验Q-Learning算法在本实验中的收敛性,然后观测实验结果的准确性。折线图展示了Q-Learning算法的训练过程,根据纵坐标Q值的变化情况,验证了Q-Learning算法的收敛性。
图3是完全随机探索策略的Q-Learning算法Q值变化曲线图。

图3 完全随机探索策略下的Q值变化曲线图
图4是使用ε-greedy动作选择策略的Q-Learning算法Q值变化曲线图。

图4 ε-greedy策略下Q值变化曲线图
图5是使用轮盘赌动作选择策略的Q-Learning算法Q值变化曲线图。

图5 轮盘赌策略下Q值变化曲线图
图6是使用Boltzmann Exploration策略时的Q-Learning算法Q值变化曲线图。

图6 Boltzmann Exploration策略下Q值变化曲线图
不同的动作选择策略对算法收敛速度的影响也不一样。对比四幅实验结果图,完全随机探索策略的收敛速度最为缓慢,ε-greedy策略只对一组参数的收敛速度进行了优化,但是可以十分迅速地学习到一组最优的行动指令参数配置;轮盘赌策略和Boltzmann Exploration策略的收敛速度比较相近,区别在于,Boltzmann Exploration策略计算概率时对Q值进行了指数放大,也即所有参数配置被选择的概率相比较轮盘赌策略的概率也被放大了,因此Boltzmann Exploration策略对Q值较小的参数配置的选择概率较轮盘赌策略的更为均匀,而轮盘赌策略在选择过程中几乎不会选择Q值较小的参数配置。
三种不同动作选择策略的使用,可以看出训练后期各参数配置的命中次数有明显的区分,经过统计,命中3次的曲线有14条,命中2次的曲线有87条,命中1次的曲线103条,命中0次的曲线有444条,因此最优的参数配置并非一组,观察Q值较大的参数配置的特征,突击方向的范围在[220,300]之间,武器发射距离与最大射程百分比的范围在[81,88]之间,而突击速度的范围总体还在[166,216]之间,由此可知突击方向、武器发射距离与最大射程百分比更能影响作战单位的行动指令效果,而突击速度则对作战单位行动指令效果的影响比较小。
5 结束语
本文利用Q-Learning算法,在RTS游戏中实现了作战单位行动指令参数配置的在线优化。考虑到行动指令中不同参数配置组合成的状态空间过大,对数据进行了预处理,剔除了一些明显不适用的数据,降低了状态空间的维度,同时减少了算法运行的时间。考虑到Q-Learning算法自身收敛速度缓慢的特点,引入了几种不同的动作选择策略,使得算法可以更快的收敛,学习效果更加地明显。实验对比发现,ε-greedy策略可以在训练轮数较少的情况下,就能学习到其中一组行动指令效果最优的参数配置。在实际问题中,往往希望Agent在训练的过程中就能比较快速地学习到最优策略;在本文中,Agent不仅在训练阶段中就能学习到最优的行动指令参数配置,而且在实用测试过程中,如果环境发生变化,也能实时地在线更新优化参数配置。本文虽然剔除了部分数据来降低Q表维度,但对剩下数据的离散化处理仍然不够细化,而Q-Learning算法在处理庞大状态空间问题上,存在Q表维度过大导致的收敛速度缓慢甚至难以收敛的不足,因此如何在平台中使用强化算法并快速学习到更为精确的数据结果,将会是下一步的主要研究内容。
猜你喜欢
当代陕西(2022年1期)2022-03-09 06:12:38
矿山安全信息(2021年21期)2021-07-04 06:33:32
政工学刊(2021年5期)2021-05-18 12:12:30
矿山安全信息(2020年37期)2020-12-26 07:25:58
装备制造技术(2020年1期)2020-12-25 05:18:24
矿山安全信息(2020年2期)2020-03-05 05:13:56
矿山安全信息(2020年3期)2020-03-04 10:18:08
小学科学(学生版)(2019年11期)2019-12-09 09:06:30
小哥白尼(军事科学)(2019年8期)2019-11-16 09:07:34
华北理工大学学报(自然科学版)(2016年1期)2016-12-19 09:17:52
