
基于三维卷积神经网络的动作识别算法
2023-09-17 12:25赵建洗景海彬程磊
科技与创新 2023年17期
赵建洗,景海彬,程磊
(沈阳理工大学信息科学与工程学院,辽宁 沈阳 110170)
目前,由于人工智能和深度学习的飞速发展,对社会生活的各个方面都产生了重要的影响,其中计算机领域尤为显著。比如在机器视觉领域,如图像分类、目标检测、图像分割等;在自然语言处理方面,如机器翻译、语音识别、情感分析、文本分类等。本文重点研究的技术是动作识别技术,与之相比,动作识别技术的研究及其应用相对较少。其中一方面,由于动作识别视频数据源不稳定,动作类间差异较小或重叠;另一方面,连续动作识别及长视频识别动作的起始和结束没有明确的边界等[1-2]。基于以上原因造成动作识别技术难度较大,且准确率难以保证。
1 动作识别方法的发展历程
迄今为止,动作识别方法主要包括2 类,即基于传统特征的方法和基于深度学习的方法。
传统特征的动作识别方法分为标志点动作识别技术和视频分析处理动作识别技术。标志点动作识别技术的原理是使用标志点进行识别,在人的不同关节放置很多的标志点,通过多个摄像机在不同的地理位置和摄像机到人体的位置关系拍摄人物的运动,结合相关的数字模型来得到多个标志点的位置关系,通过这种方式连续进行识别,组成人物动作,以此来达到动作识别的相关目的;视频分析处理动作识别技术的原理是不依赖任何装置及外部设备,直接对拍摄的图片帧进行分析,提取出特征,进而得到人体的相关动作[3]。
深度学习的动作识别方法分为基于二维卷积神经网络技术和基于三维卷积神经网络技术。
基于二维卷积神经网络技术发展经历了2个阶段,即双流网络基础网络阶段和二维卷积神经网络阶段。双流网络基础网络由空间流和时间流网络组成,空间流网络以单帧图像作为输入,作用是建模外观特征;时间流网络以光流图像作为输入,作用是建模运动特征。训练时,空间流网络和时间流网络单独地训练。二维卷积神经网络是被FEICHTENHOFER 等[4]提出的,采用卷积网络融合双流特征的方法,通过CNN(Convolutional Neural Networks,卷积神经网络)学习空间线索和时间线索的对应关系,实现了分类器级融合到特征级融合的转变。CNN 网络在图像分类上的表现优异,将它应用于动作识别,一定程度上推动了动作识别技术的发展。
基于三维卷积神经网络技术对输入图像在时间和空间维度上同时进行卷积操作,这样在获取每一帧表观特征的同时,也能提取出相邻帧随时间推移而产生的关联与变化,实现图像序列中时空信息建模[5]。
由于技术的不断推进与发展,人体姿态估计技术横空而出。人体姿态估计是指通过一张图片能够检测出人体关节的关节点,并按照人体的结构将此相连接,从而得到一张人体关节姿态图[6]。人体姿态估计可被广泛地应用在动作识别[7-8]、人机交互[9]、智能跟踪[10]等很多领域,已成为计算机视觉领域的研究热点之一。 在此基础上进行动作识别技术的研究,既不需要外部设备,也不需要设置标志点进行复杂的操作。一方面,大大节省了时间成本;另一方面也使动作识别技术变得相对简单,为动作识别技术的发展作出了重大贡献。
近年来,由于深度学习的广泛应用,基于深度学习的人体姿态估计方法陆续被提出,准确率也越来越高。其中比较著名的有基于Google 的Mediapipe 框架下的人体姿态估计方法[11]、由卡内基梅隆大学提出的基于卷积神经网络和监督学习的OpenPose 人体姿态估计方法[12]、由上海交通大学提出的AlphaPose 人体姿态估计方法[13]、基于YOLO 框架的YOLO-Pose 人体姿态估计方法[14]。
经过查阅资料,发现仅仅有较少的论文将人体姿态估计和动作识别结合到一起,应用于动作识别。本文结合人体姿态估计得到了人体关节关键区域的姿态图,使用连续25 张图片动作序列作为一个动作输入,使用改进的图片分类网络模型进行训练,将二维卷积神经网络改为三维卷积神经网络,以适应训练连续25张图片动作序列的目的[15]。
虽然通过人体姿态估计能够得到人体关节姿态图,但并不能很好地实现动作识别的要求。仅仅通过一张图片的关节姿态图,可简单地识别人物的动作,如站、坐、躺、蹲等。但是对于一些复杂的动作,单单通过一张图片难以推测人物的真实动作。本文的主旨是通过人体姿态估计连续提取25 张图片的人体姿态图作为一个动作序列,之后结合三维卷积神经网络,将大量的连续动作序列作为网络的输入,最后训练出一个较好的三维卷积神经网络模型,通过训练三维卷积神经网络模型进行视频动作的识别。结果表明,三维卷积神经网络模型具有较好的动作识别的辨别能力。
2 卷积神经网络
卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一[16-17]。
卷积神经网络的研究始于20 世纪80—90 年代,Lenet-5 是最早出现的卷积神经网络[18];不过刚开始时,由于电脑运算能力的低下及各种环境条件的限制,卷积神经网络并未得到过多的发展和重视。直到21 世纪后,随着电脑性能的大幅度提升及卷积神经网络在图像处理领域的卓越能力,再加上深度学习的不断完善,为卷积神经网络的发展和进步提供了得天独厚的条件。卷积神经网络不断发展进步,并被应用到图像分类、图像识别、图像分割等各个领域。
2.1 Lenet-5 网络
Lenet-5 网络模型最早诞生于1994 年,是最早的卷积神经网络之一[18]。它的网络结构非常简单,只包含了卷积层、池化层、全连接层,但包含了卷积神经网络的核心,是各种卷积神经网络模型结构发展的基石。事实证明,该神经网络在数字识别和字符识别领域获得了卓越的成就。
Lenet-5 网络模型结构一共由7 层组成,即C1 卷积层、S2 池化层、C3 卷积层、S4 池化层、C5 全连接层、F6 全连接层和输出层。该网络结构全部采用5×5的卷积核和2×2 的池化核,3 层全连接数量依次为120、84、10。网络中padding 选择valid 的方式,卷积计算后会缩小输入图片的形状,池化会成倍缩小图片的尺寸。事实证明,该网络虽然简单,但对手写数字识别及字符识别这样的数据无论是训练集、验证集还是测试集都有不错的拟合效果。Lenet-5 网络模型结构如图1 所示。

图1 Lenet-5 网络模型结构图
2.2 Alexnet 网络
Alexnet 网络模型结构在2012 年的ImageNet 竞赛中脱颖而出后,卷积神经网络又引起了人们的广泛关注[19]。它是以Lenet-5 模型结构为基础改进的,一方面增加了网络的深度,另一方面采用了不同的卷积核大小。实际说明,一定的网络深度和不同的卷积核尺寸能够在一定程度上提高神经网络的准确率。
Alexnet 网络模型结构由5 个卷积层、3 个池化层和3 个全连接层组成。5 个卷积层分别使用11×11、5×5、3×3、3×3、3×3 的卷积核大小,卷积核的深度依次为48、128、192、192、128,padding 选择same的方式,卷积计算后,保持原尺寸大小,不足的部分使用0 填充;3 个池化层使用的是2×2 池化核大小的最大池化,使输入图片变为原来的1/2;3 个全连接层数量依次为2 048、2 048、1 000。事实证明,该网络结构有效地提高了图片分类的准确率。Alexnet 网络模型结构如图2 所示。

图2 Alexnet 网络模型结构图
2.3 Vggnet 网络
Vggnet 网络模型结构于2014 年在ILSVRC 竞赛中荣获亚军,各种卷积神经网络层出不穷,卷积神经网络迎来了发展高峰。Vggnet 网络模型也是在Alexnet模型结构基础上进行的改进,网络的准确度进一步提高。虽然网络深度增加,由于网络结构近似统一,不但看起来整洁易懂,而且准确率也能达到不错的效果。
Vggnet16 由5 个卷积层、5 个池化层、3 个全连接层组成。卷积核大小全部为3×3,卷积核深度依次为64、128、256、512、512,卷积核数量依次为2、2、3、3、3,padding 选择same 的方式,卷积计算后,保持原尺寸大小;5 个池化层的池化核采用2×2 大小的最大池化;3 个全连接层数量依次为4 096、4 096、1 000。Vggnet 网络模型结构如图3 所示。
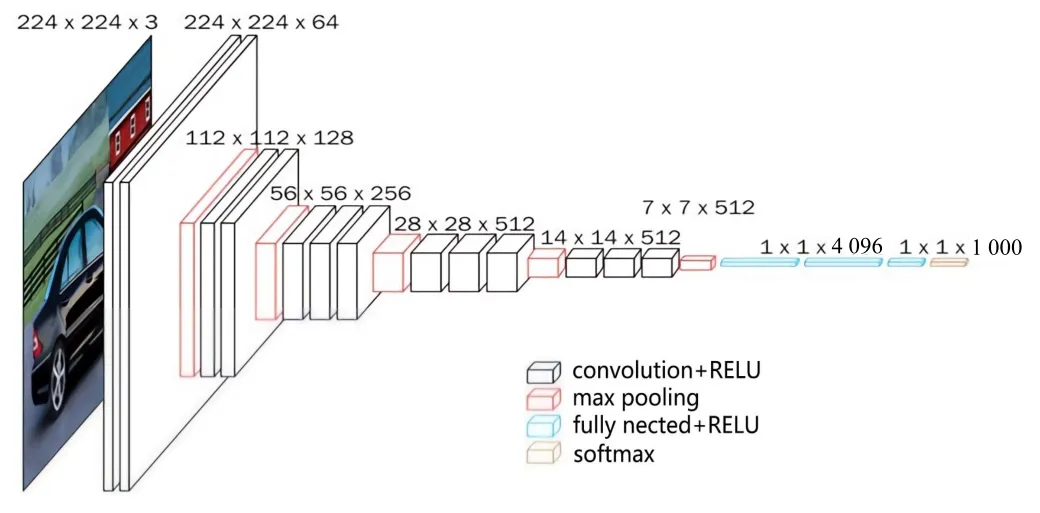
图3 Vggnet 网络模型结构图
3 改进的三维卷积神经网络
3.1 改进的Lenet-5 网络
Lenet-5 三维卷积神经网络最大的改进就是使用三维卷积替代二维卷积,目的就是能够使用图片序列作为网络模型的输入,而不仅仅是一张图片。相同的是该网络模型由卷积层、池化层、卷积层、池化层和3个全连接层组成。
改进的三维卷积神经网络模型输入层的维度是25×128×72×1 的连续动作序列;输出层为训练模型的动作类别,本文中为12 种不同动作类别。2 个卷积层均使用3×3×3 的卷积核大小替代原网络的5×5 的卷积核,步长为2。2 个池化层均采用1×2×2 的池化核大小,步长也为1×2×2。Lenet-5 三维网络模型结构如图4 所示。

图4 Lenet-5 三维网络模型结构图
3.2 改进的Alexnet 网络
Alexnet 三维卷积神经网络与上文相同,最大的改进也是将二维卷积改为三维卷积,以达到使模型能够训练动作序列的要求。和上文相同的是输入层和输出层,不同的是卷积层和池化层。
改进的Alexnet 三维卷积神经网络有5 个卷积层和2 个池化层。5 个卷积层卷积核大小依次为7×7×7、5×5×5、3×3×3、3×3×3、3×3×3,步长全部为2×2×2,卷积核深度和原始网络保持一致,依次为48、128、192、192、128。池化层采用最大池化,池化核大小均使用2×2×2,步长也均为2×2×2。Alexnet三维网络模型结构如图5 所示。

图5 Alexnet 三维网络模型结构图
3.3 改进的Vggnet 网络
Vggnet 三维卷积神经网络的处理方式也是将二维卷积改为三维卷积,以达到使模型能够训练动作序列的要求,并且使得模型能够预测动作序列。和上文保持了相同的输入维度和输出维度,与输入层的图片维度保持一致;不同的是中间层的处理,即卷积层和池化层。输入层大小依旧是25×128×72×1,输出层依旧为设定的动作类别的数量。卷积核大小全部为3×3×3 的卷积核,池化核出最后一层外全部为2×2×2的最大池化。和原始网络对比,5 个卷积层除了由二维卷积改为三维卷积外,卷积核数量、卷积核深度、卷积步长均有调整。5 个卷积层均包含2 次卷积,未改变5 个卷积层的第一次卷积,只调整了第二次卷积的参数,将每个卷积层第二次卷积步长设定为2×2×2,第一次卷积步长不变;将第三、第四、第五这3 个卷积层的卷积次数由3 次改为2 次。由于电脑配置不足,将5 个卷积核的深度由64、128、256、512、512 调整为8、16、32、64、128。池化层除最后一个池化层使用1×1×1 的池化核外,其他均采用2×2×2 的池化核大小,步长也为2×2×2。为了更方便地观察Vggent三维网络模型结构,绘制了Vggent 三维网络模型结构图,如图6 所示。
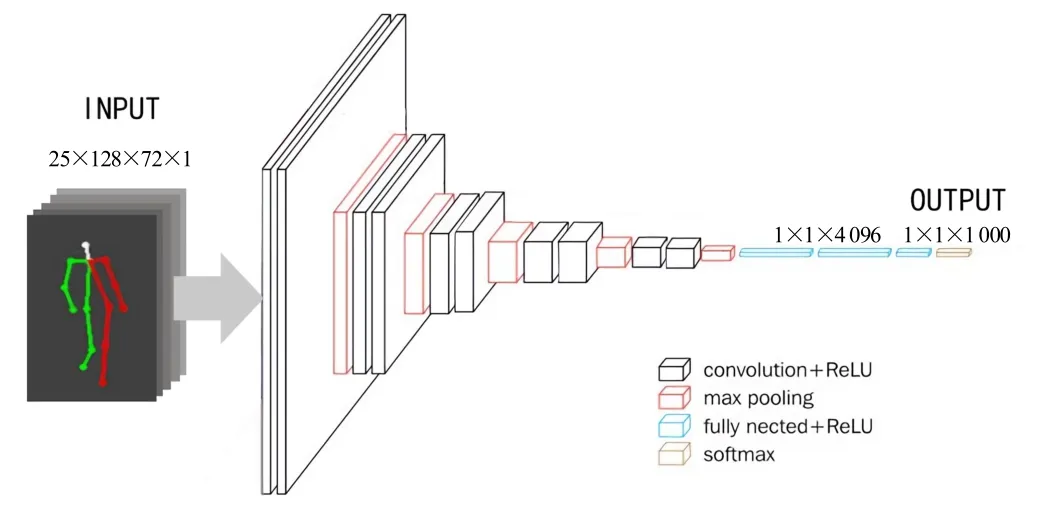
图6 Vggnet 三维网络模型结构图
4 结论
4.1 数据集的准备
首先,图片输入是一组人物动作的人体姿态估计的图片序列。何为人体姿态估计呢?本文的人体姿态估计方法是利用已有深度学习方法在给定的一张包含人体的图片之中,得到人体骨架的大致形状轮廓。本文采用的是谷歌开源的Mediapipe 中的人体姿态估计方法,相比OpenPose 和AlphaPose,人体姿态估计的最大优点是速度较快,能够达到每秒提取30 张左右。将大量的动作视频拆分成连续的动作序列,并将同种类别的视频放到相同类别名称的目录之下,为训练三维卷积神经网络模型做准备。
25 张人体姿态估计的连续序列图片如图7 所示,图中展示了一个人跑步的25 张人体姿态估计的连续序列。
4.2 模型数据及训练参数设置
本节进行模型训练前的准备工作,包括三维卷积神经网络模型的数据集、数据处理、参数设置等。首先,为了满足实验的要求本文没有使用官方数据集,收集了符合实验要求的大量数据。本文将大量的视频数据通过人体姿态估计的方法,制成一个个连续的动作序列作为训练的基础数据。将数据集划分为训练集数据和测试集数据,训练集数据包含37 000 多个动作序列文件,测试集数据包含8 000 多个文件。将训练数据的85%作为训练集,15%作为验证集;测试数据全部作为测试集。初始学习率设置为0.000 01,训练次数为50 次。为了提高准确率将训练的数据集和验证集重复32 次,这样可以在训练次数较少的情况下提高准确率;同样也有缺点,就是训练速度过慢。通过实验证明,不重复数据集时,训练次数调整为30 倍,训练的模型不能达到很好的效果,会造成局部过拟合。
4.3 模型实验效果分析
经过实验分析,3 种不同的三维卷积神经网络模型都能够达到对应的动作识别的预测效果。Lenet-5 三维卷积神经网络由于网络简单、计算量较小,因而训练速度较快,经过验证该模型预测效果还可以;Alexnet三维卷积神经网络的结构相对复杂,训练速度慢3~4倍,经过多次尝试准确率却并没有提升,且网络训练效果不稳定;Vggnet 三维卷积神经网络的结构最为复杂,计算量更大,所用时间更长,模型预测效果经验证是最好的。实验时的笔记本电脑显卡配置较低,能够较短时间内训练出较好的Lenet-5 三维卷积神经网络;另外2 种卷积神经网络因电脑配置较低,训练模型需要几天。电脑配置不足的情况下,建议使用Lenet-5三维卷积神经网络;电脑配置较高时,可以考虑使用更复杂的三维卷积神经网络模型。
经过多次实验,Lenet-5 三维卷积神经网络训练准确率为96%左右,验证准确率为80%,测试准确率为40%~50%;Alexnet 三维卷积神经网络模型效果不稳定,不能够进行有效使用;Vggnet 三维卷积神经网络准确率相比Lenet-5 三维卷积神经网络稍有提升,但提升不大。本实验的数据量不多,动作相似性较低,每个动作只采用了5~10 个视频,测试集数据是一个全新的动作序列,和训练集数据关联性不强。
为了更直观地显示改进的三维卷积神经网络的动作识别模型的效果,经过多次实验通过相关代码绘制出了以下准确率曲线变化图、损失函数变化曲线图及混淆矩阵图、ROC 曲线图,如图8 和图9 所示,通过这些图像使本文的实验结果更加直观。

图8 训练集及验证集准确率和损失函数变化曲线图
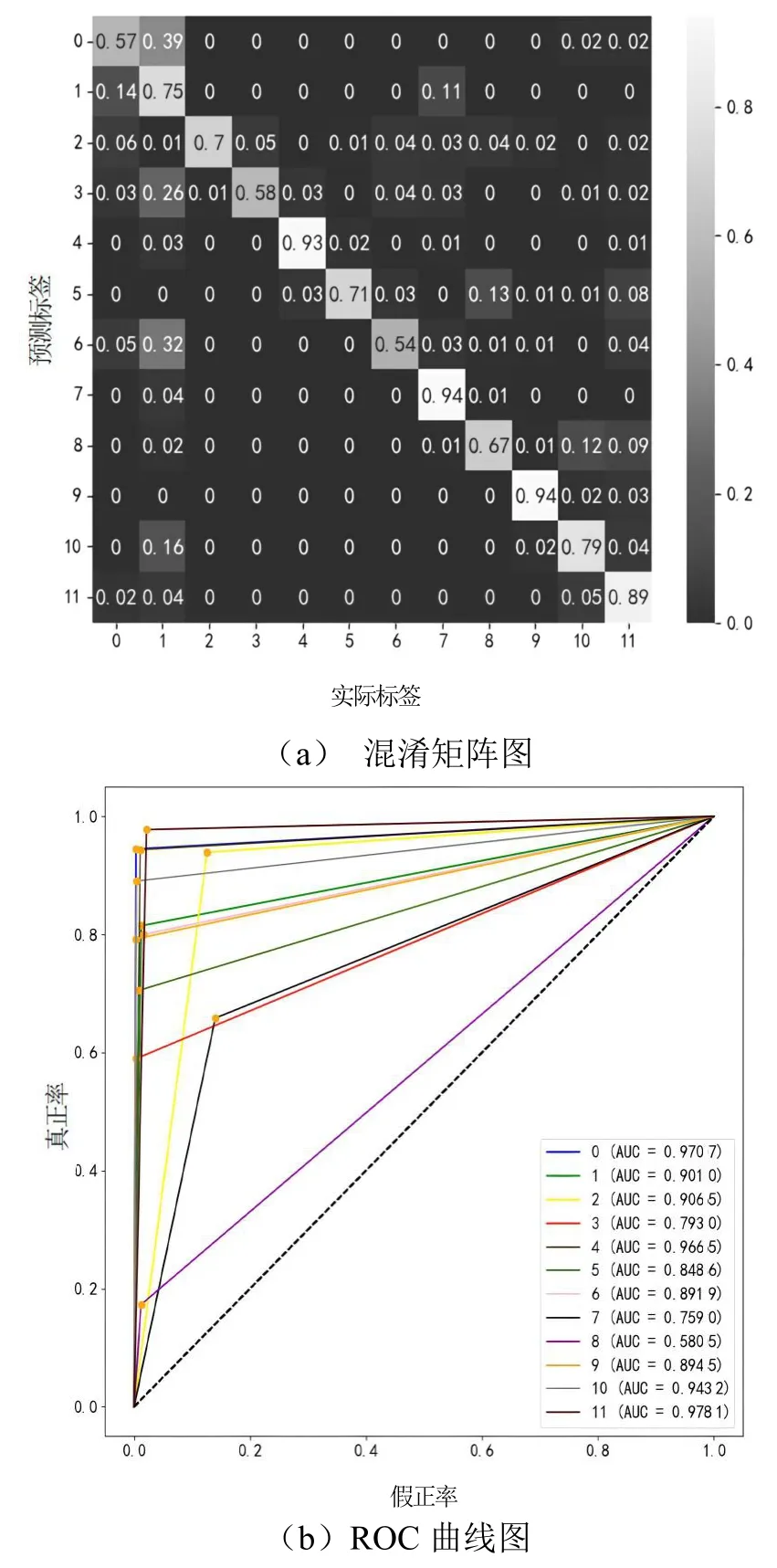
图9 混淆矩阵和ROC 曲线图
混淆矩阵和ROC 曲线都是图像分类的一个重要评价指标。从以上结果可知,模型实验结果对大部分的动作类别分类效果是比较不错的,但是也有一小部分的分类结果不能达到预期效果。通过扩大数据集或进一步改进网络有望达到更好的结果,若要达到更高的准确率还需要进一步进行实验与深入研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
学生天地(2020年3期)2020-08-25
电子制作(2019年11期)2019-07-04
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
