
基于注意力融合的海上目标检测算法
2023-09-16 09:14杨露菁阚钦高
舰船科学技术 2023年16期
张 鹏,黄 亮,杨露菁,阚钦高
(1.海军工程大学 电子工程学院,湖北 武汉 430033;2.中国人民解放军91431 部队,海南 海口 570100)
0 引 言
我国是海洋大国,提高我国的海上军事国防实力, 维护海上疆域和领土完整关乎到我国的长治久安。在海上国防军事技术中,海洋目标探测技术对于加强海上领土的监管有非常重要的意义[1]。
不同于雷达等主动探测设备,光电探测设备被动接受外界信息,不对外发射电磁信号,具有隐蔽性好、抗干扰能力强等优点。
近年来,基于深度学习的图像特征提取技术在目标检测领域得到广泛的应用。深度卷积神经网络能够通过学习获得表示图像高级特征的能力,从而实现对图像中目标的检测。现行的深度学习目标检测算法主要可分为基于回归思想的单阶段目标算法和基于候选区域思想的两阶段目标检测算法。其中单阶段检测算法相对速度更快,更能够满足海上目标检测时效性的要求。YOLO 系列检测算法是单阶段目标检测算法中应用最为广泛的[2]。赵文思[3]基于YOLOv3 模型,引入GIOU loss 并加入SPP 结构,提出了YOLOv3SPP 卷积神经网络模型,实现对船舶的检测;王文亮等[4]在YOLOv5 算法中加入SimAM 注意力模块和Transformer 结构增强高阶特征语义信息,提高海面小目标检测能力;张晓鹏等[5]在YOLOv5 算法的基础上,融合SE 注意力模块和改进的非极大值抑制模型,实现提高海上船舶识别整体效果;姬嗣愚等[6]在YOLOv5 算法中引入了坐标注意力机制,将位置信息嵌入通道注意力中,增强模型的特征提取能力,在满足实时性要求下更好地完成水柱信号的检测要求。
本文采用最新的目标检测模型YOLOv7[7]作为基础模型,结合海面上目标成像特点,采用自注意力模块加强特征提取,利用通道与空间注意力模块,引导高层特征与低层特征融合,对特征融合网络进行轻量化改造,实现对海上目标的实时准确检测。
1 YOLOv7 算法原理
YOLO 系列发展至今已有诸多版本,在目标检测领域发挥重要作用。YOLOv7 是YOLOv4 官方团队在前代网络的基础上进一步改进而来,相同体量下,拥有比现在最流行的YOLOv5 更高的检测精度。与YOLOv5 一样,为了满足不同检测场景的需求,YOLOv7共发布的7 个基础模型。本文主要针对海上目标进行检测,为满足模型轻量化和检测实时性要求,以YOLOv7-tiny-SiLU 作为基准模型,并针对海上目标检测任务进行优化。
YOLOv7-tiny-SiLU 的总体结构如图1 所示。
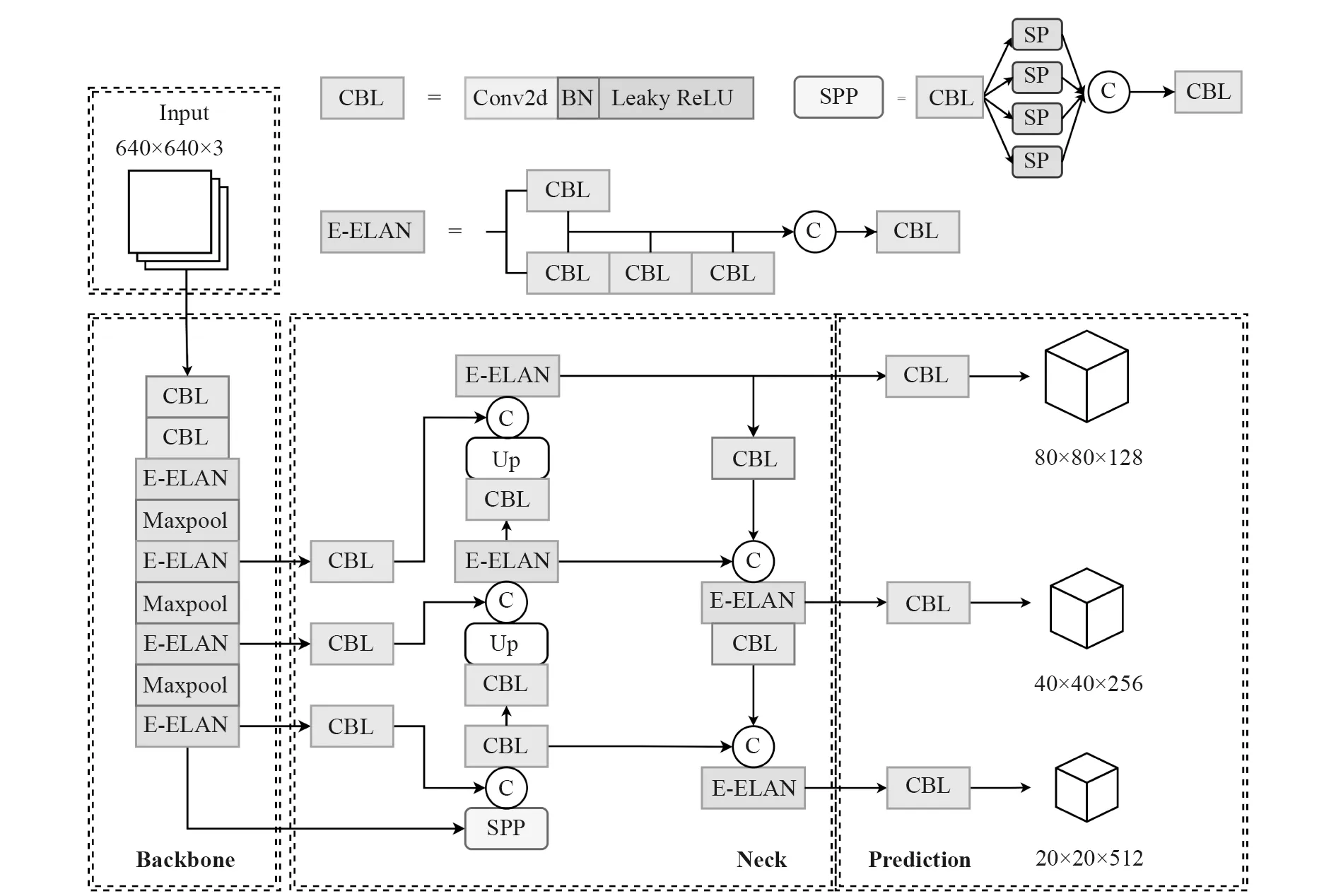
图1 YOLOv7-tiny-SiLU 模型结构Fig.1 YOLOv7-tiny-SiLU model structure
输入端(Input)继续采用Mosaic 数据增强、自适应锚框计算和自适应图片缩放方式对输入图像进行预处理,以提高输入模型的数据质量。
主干网络(Backbone)相对前代YOLO 模型进行较大改进。Focus 下采样结构恢复为步长为2 的卷积层,在下采样的同时保留部分语义信息;参考ELAN 结构设计扩展高效聚合网络E-ELAN,在不破坏原始梯度路径的情况下,提高网络的学习能力;在P3 至P4 与P4 至P5 两次下采样过程中,由E-ELAN 负责特征提取,降采样操作由最大池化完成,保证特征提取的同时,进一步减少计算参数与计算量。
颈部(Neck)继续沿用FPN+PAN 结构的路径聚合网络结构,但将其中的CSP 模块替换E-ELAN 层。
输出端(Prediction)针对检测目标的大小不同,设定输入图像的1/8、1/16、1/32 三种大小网格。每个网格包含3 个预测框,每个预测框包含目标分类、位置、置信度信息,最后通过非极大值抑制 NMS(Non-Maximum Suppression)对重复冗余的预测框进行剔除,保留置信度最高的预测框信息[8],从而完成目标检测过程。
除此之外,YOLOv7-tiny-SiLU 在模型的训练上也进行优化。一是参照RepConv 进行模型重参化设计[9],用没有identity 连接的RepConv 来设计重参数化卷积的体系结构,实现用复杂的模型训练、用简单的模型推理,在保证模型精度的前提下进一步压缩模型的大小。二是利用深度监督的思想,在网络的中间层增加额外的辅助头,利用辅助检测头学习住检测头已学习的信息,使得主检测头能够进一步学习更多信息[10],并通过一种新的软标签生成方法来训练模型,以增强网络的检测能力。
现有的YOLOv7-tiny-SiLU 算法是针对全场景下目标检测任务设计的,为使网络更加符合海上目标检测需求,对网络进行海上目标检测的针对性改进。
2 模型改进
与其他场景相比,海上场景背景相对简单。海面目标沿海天线向画面边缘由远及近分布且与背景有密切关系,如同样的白色像素区域在天空背景下通常为云朵,在海面背景下通常为海浪,故在进行海上目标检测时,需充分考虑图像中的上下文信息。本文利用注意力机制增强骨干网络的特征提取能力,对颈部的特征融合网络进行设计,增加特征融合的针对性。
2.1 自注意力机制
卷积神经网络(CNN)利用天然的归纳偏置优势来学习视觉表征,在空间信息域上建立局部依赖关系,但也由此缺乏学习全局表征的能力。基于自注意力机制的视觉Transformer(ViT)具备捕捉输入特征图全局感受野的能力,能在空间维度上建立全局依赖关系从而学习到全局视觉表征信息。但由于缺乏空间归纳偏差,ViT 架构通常计算量较大且难以训练。在此基础上,Mehta S 等[11]结合CNN 与Transformer 的优点,构建出轻量级网络架构MobileViT,如图2 所示。
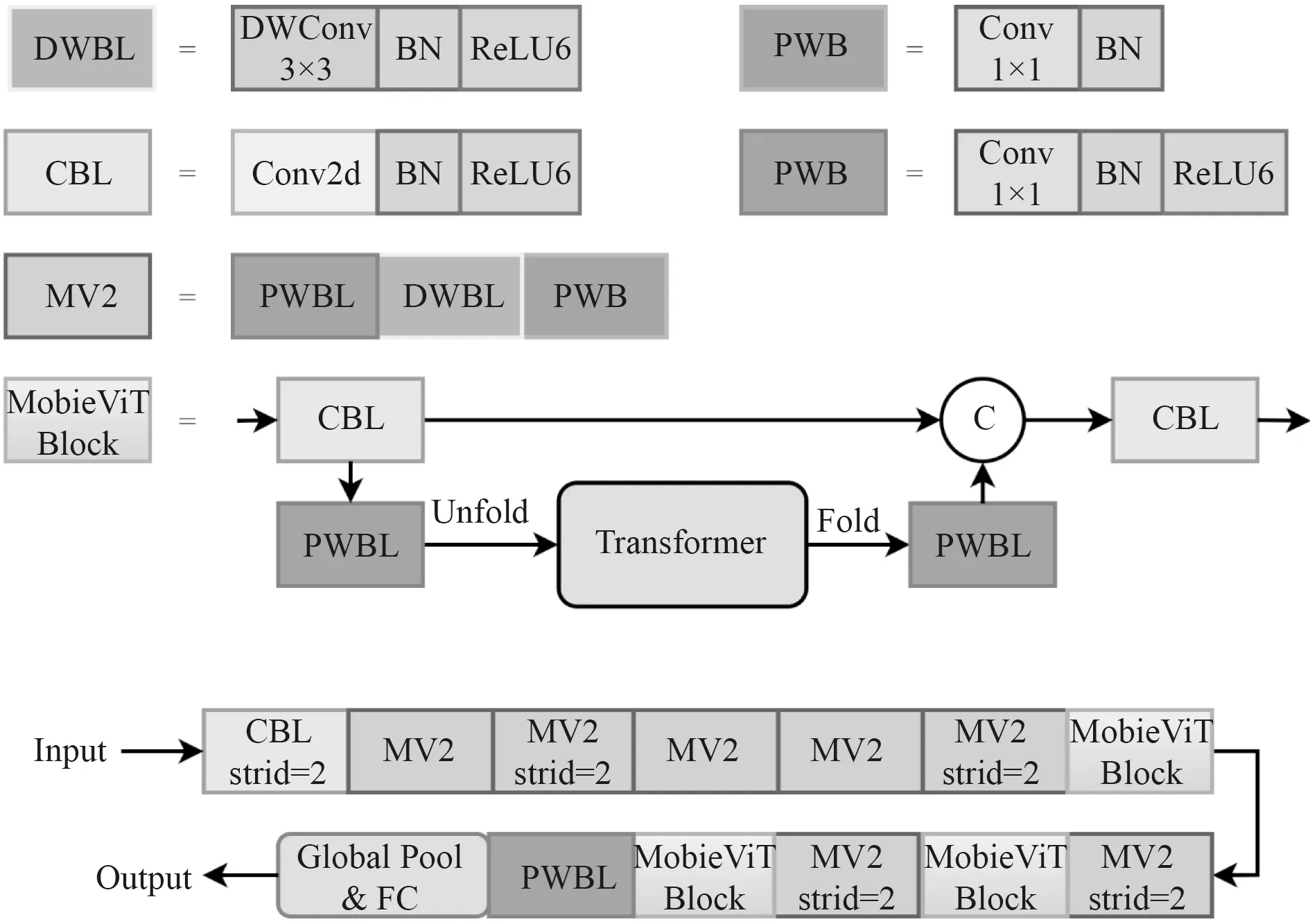
图2 Mobile ViT 架构Fig.2 Mobile ViT architecture
在MobileViT 架构中,MobileViT Block 是融入Transformer 的核心部分。具体流程为:
X∈RH×W×C
步骤1 利用一次普通卷积学习输入的张量局部空间信息;
步骤2 通过点卷积将步骤1 的输出特征投影到高维空间,将得到的张量XL∈RH×W×d展开后通过Transformer 建模得到张量XG∈RH×W×d;
步骤3 重新折叠张量XG∈RH×W×d,并通过点卷积进行降维得到张量XF ∈RH×W×C;
步骤4 将步骤1 的结果与张量XF∈RH×W×C拼接后,利用卷积融合其中的局部特征与全局特征。
MobileViT Block 能够同时感知特征图的全局信息与局部信息,在骨干网络中插入该模块能够提高网络的特征提取能力。
2.2 通道注意力机制与空间注意力机制
骨干网络提取的特征层包含丰富的语义信息,但不同层级的特征图所包含的语义信息有所差别,对不同目标检测的贡献度也不同。YOLOv7-tiny-SiLU 的颈部结构对各层级进行融合,能够提高目标检测能力,但并非所有层的信息对目标检测的贡献度都相同,冗余的信息甚至会误导网络对有效信息的利用。
注意力机制能够动态调整所融合信息的权重,提升神经网络对有用信息的注意,并抑制对无效信息的关注。为了让检测器能够在检测不同目标时能合理分配注意力,进而提高对有用信息的感知。
CBAM[12]注意力机制能够同时感知通道注意力(Channel Attention,CA)与空间注意力(Spatial Attention,SA)。其中,CA 模块与SENet 类似,在SENet的基础上增加了maxpool 的特征提取方式,利用特征间的通道关系来生成通道注意力图;SA 模块利用的是特征间空间关系,沿着通道轴并行平均池化和最大池化操作,连接后经过一个卷积层得到注意力图,如图3所示。通道注意力图与空间注意力图的计算过程为:
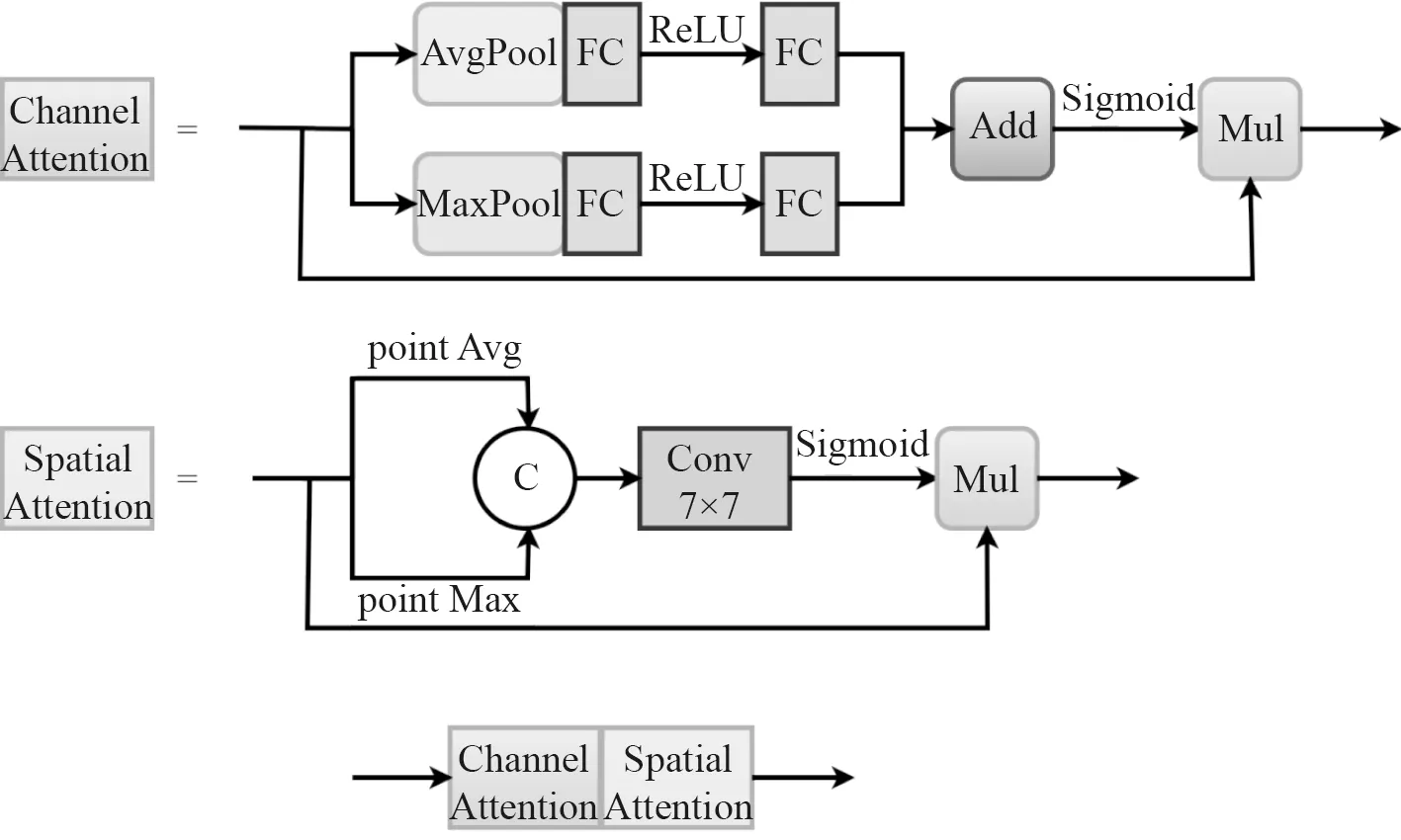
图3 CBAM 结构Fig.3 CBAM structure
将CBAM 注意力机制应用于多尺度特征融合结合使用,对融合的特征图进行自适应的加权调整。
2.3 改进的特征融合网络
将CA 模块与SA 模块根据需分别嵌入颈部的特征融合网络中,并对颈部进行轻量化改造,使其更加专注于特征融合。在大量减少计算开销的情况下,保留颈部特征融合能力,将获得的特征提取网络命名为CS-FPN,如图4 所示。CS-FPN 网络中特征融合的过程为:
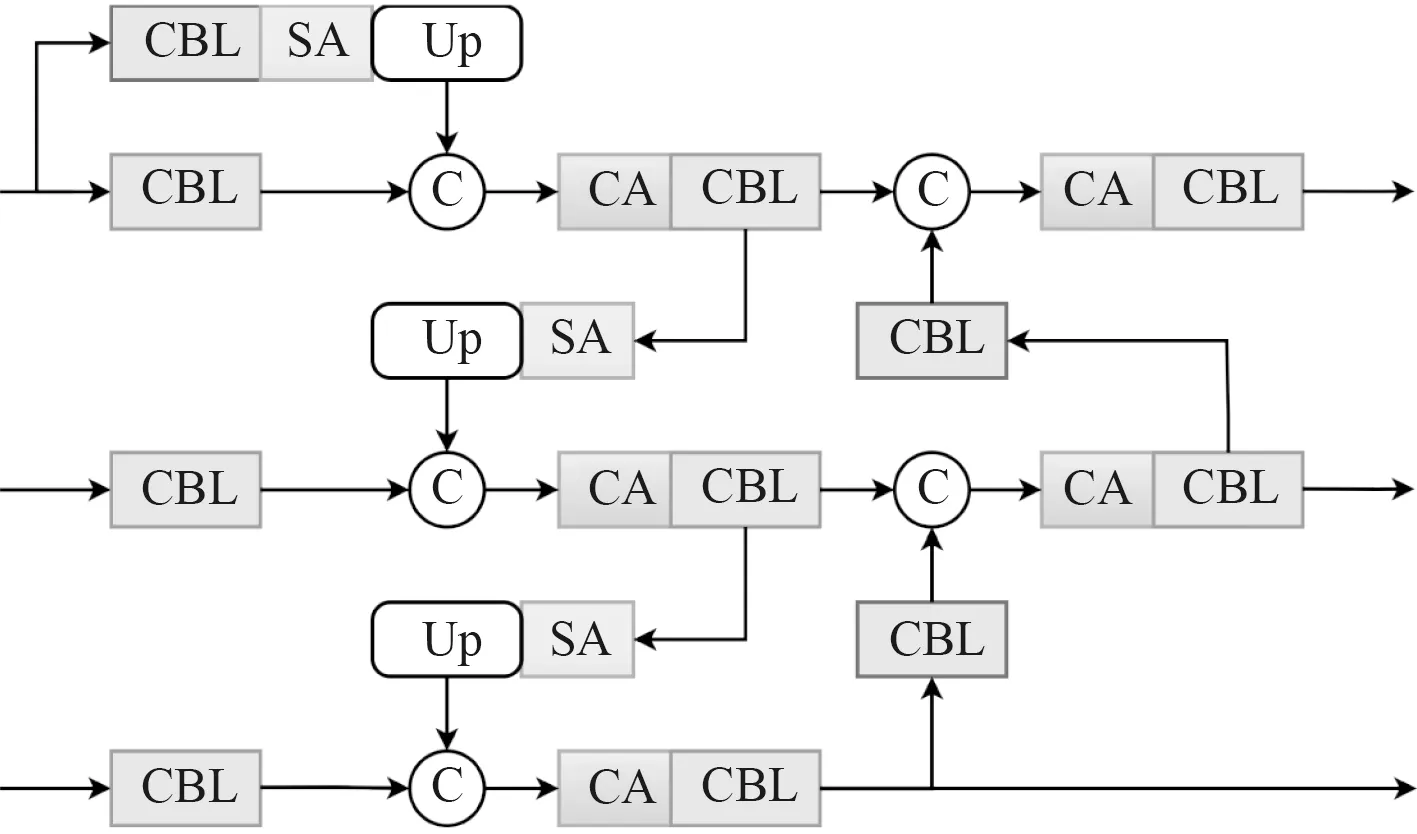
图4 CS-FPN 结构图Fig.4 CS-FPN structure
步骤1 由骨干网络提取到的P5 特征层经过一次卷积下采样,获得拥有更高一级的语义信息特征层P6。
步骤2 由具有更高语义信息特征层借助注意力机制引导下一级特征层的信息融合。具体做法为:将P6、P5、P4 特征层经过1 次SA 模块获得空间注意力权重,经上采样后分别与P5、P4、P3 层进行拼接,将拼接后的特征层经过1 次CA 模块感知通道注意力权重,再利用卷积对特征通道进行融合,得到初步融合的特征图P'5、P'4、P'3。
步骤3 将底层特征图向高层融合。具体为:底层特征图P'3 、P'4 经过一次下采样分别与更高层的P'4、P'5 进行拼接,而后经过1 次CA 模块获得通道注意力权重,再通过卷积对特征通道进行融合,得到进一步融合的特征层P"5、P"4、P"3。
步骤4 根据检测任务需要,重复步骤2 和步骤3得到最终融合的特征层C5、C4、C3。
2.4 CS-YOLOv7s 网络模型
针对海上目标检测,在YOLOv7-tiny-SiLU 算法的基础上,将MobileViT Block 加入骨干网络中,再结合2.3 所提的特征融合网络,得到改进后的CS-YOLOv7s网络。其整体结构如图5 所示。
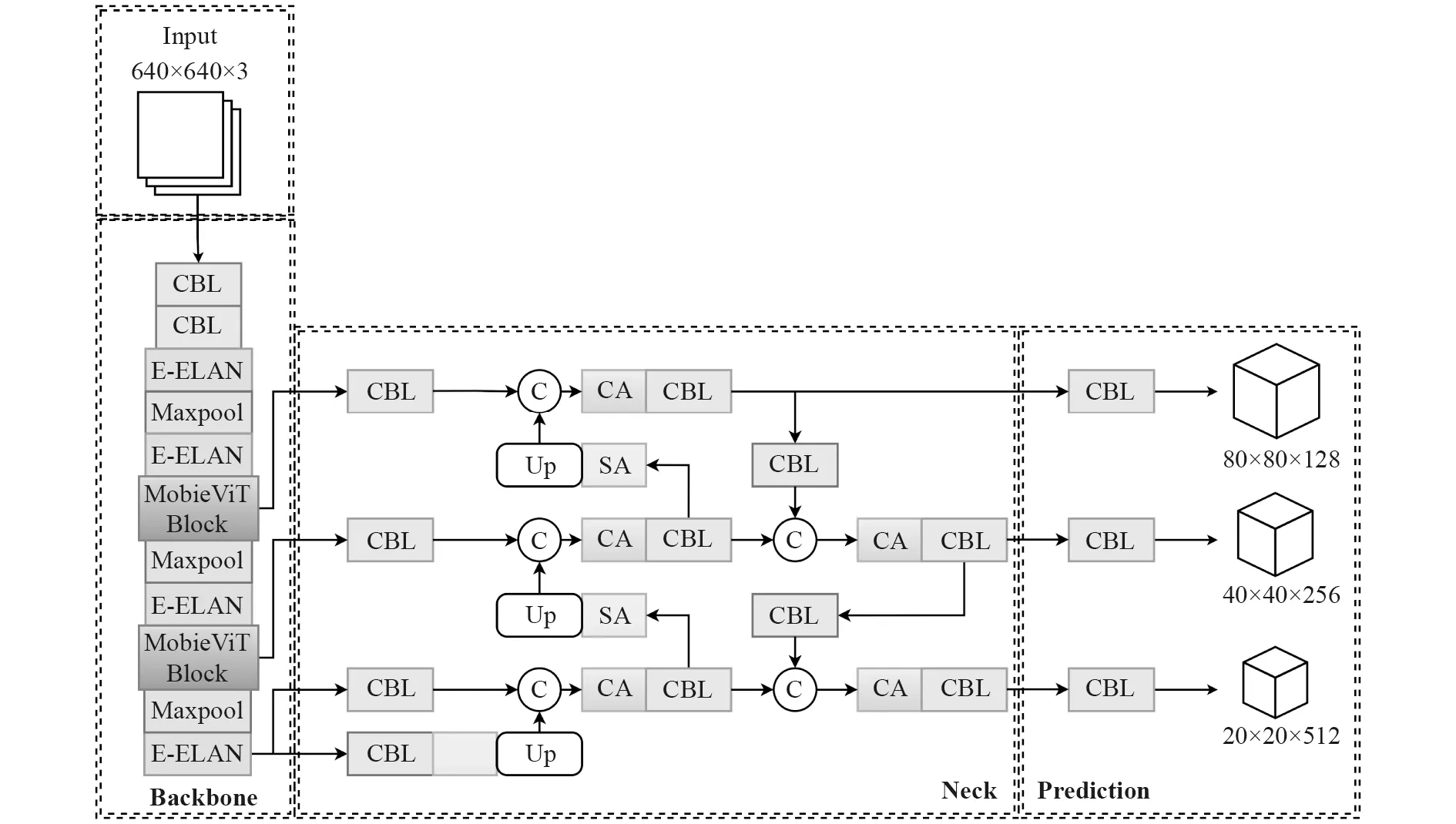
图5 CS-YOLOv7s 整体结构Fig.5 CS-YOLOv7s overall structure
3 实验结果与对比分析
3.1 实验环境与实验数据
本文实验环境为Ubuntu20.04 操作系统,CPU 为Intel i9-10920X,内存32 G,显卡为 NVIDIA GeForce RTX3070,Python3.8 编程语言,Pytorch1.8.0 深度学习框架。
数据集为互联网上公开的新加坡海事数据集,包括在2015 年7 月~2016 年5 月之间的各种环境条件下采集的视频数据,经分帧标注而得3605 张分辨率为1920×1080 的图片及相应标注文件。按照9∶1 的比例将所有数据划分训练数据与验证数据,再将验证数据按照9∶1 比例划分为训练集与测试集,即训练集2920张图片,测试集324 张图片,验证集361 张图片。
3.2 评估指标
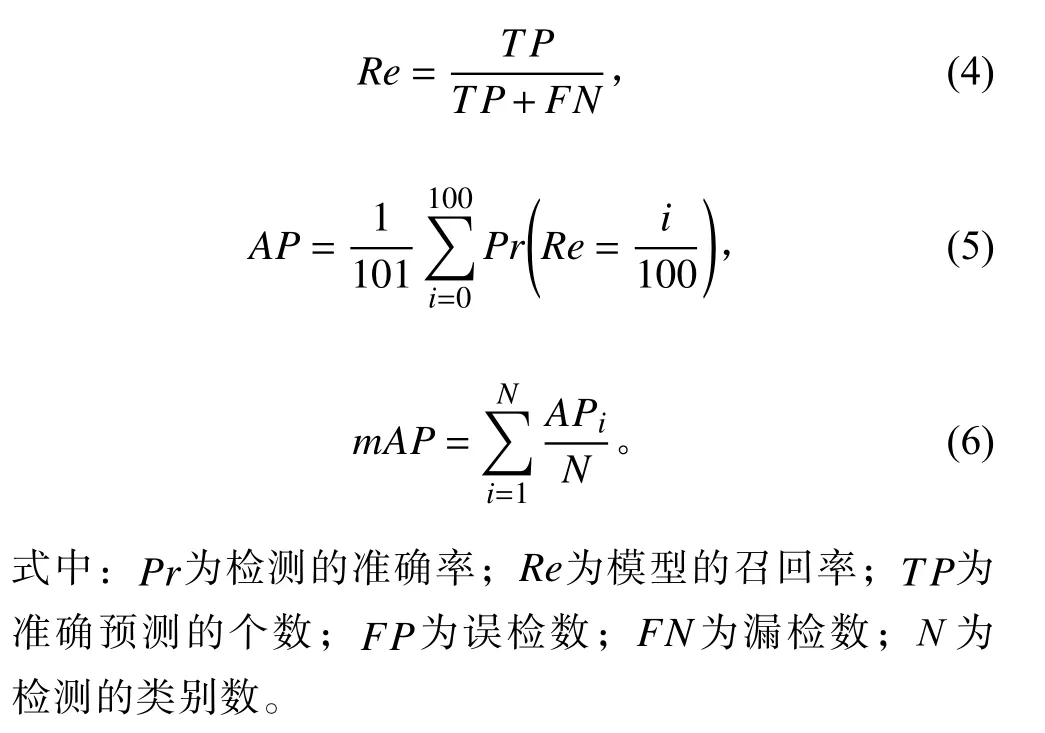
目标检测中通常用平均精准度(Average precision,AP)和平均精准度的均值mAP 来评价模型的检测效果和性能,AP 为召回率(Recall)和精确率(Precision)曲线下的面积。计算公式为:
3.3 实验对比
训练阶段的超参数设置:初始学习率为0.0032;衰减系数为0.12;动量为0.843;批大小(batch size)为16;训练次数(Epoch)为 500 次。
YOLOv7-tiny-SiLU 与CS-YOLOv7s 的损失函数曲线如图6 所示。可看出2 种模型在训练初期损失函数下降速度更快,整体波动较小,且训练到第100 轮左右时均损失值达到了0.04,收敛情况均良好,模型轻量化改进后最终损失比原始模型稍高。
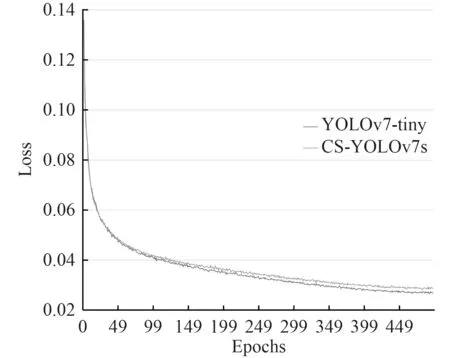
图6 训练损失情况Fig.6 Training loss
从训练结果上看,CS-YOLOv7s 的准确率最高为0.9668;召回率最高为0.8554;在置信度为0.5 时mAP 最高为0.8733。当置信度为0.5 时,模型改进前后其平均精准度的均值mAP 曲线如图7 所示。从图中可看出,CS-YOLOv7s 的平均精准度与YOLOv7-tiny-SiLU 基本持平,稍有下降。
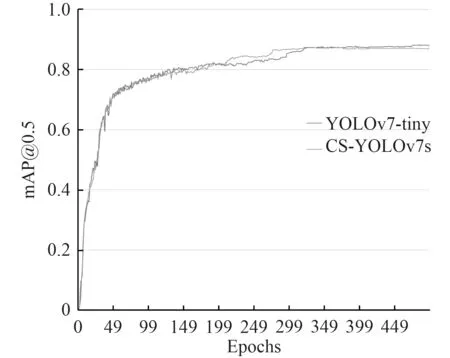
图7 mAP@0.5 曲线对比Fig.7 mAP@0.5 curve comparison
使用Y O L O v 5 s、Y O L O v 7-t i n y-S i L U、C SYOLOv7s 对验证数据进行检测,完成消融实验,检测结果如图8 所示。从检测结果来看,CS-YOLOv7s对海上目标检测的准确性明显优于YOLOv5s,略差于YOLOv7-tiny-SiLU。

图8 检测结果示例。Fig.8 Example of test results
网络参数对比如表1 所示。
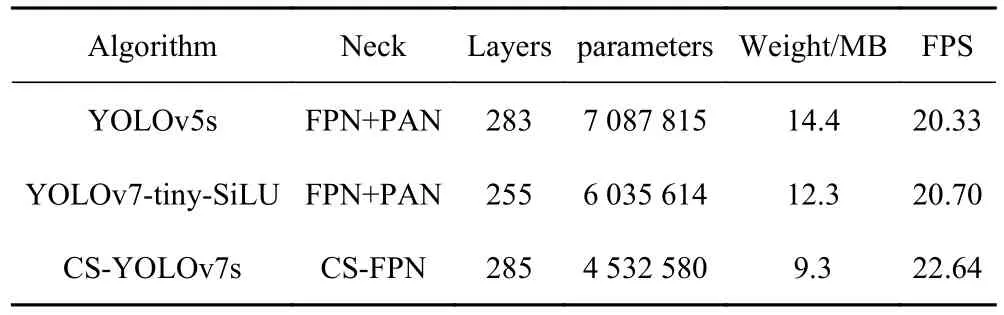
表1 算法模型性能对比Tab.1 Algorithmic model performance comparison
可以看出,相比于YOLOv5s 与YOLOv7-tiny-SiLU,CS-YOLOv7s 算法网络模型层数虽然有所增加但模型权重大大下降,参数量相对较少,检测速度有所提高,且经过模型重参化后权重仅为9.3 M。对于算法移植于其他平台更加友好,即使在高清图像中也能基本满足实时检测的需要。改进后的CS-YOLOv7s 算法能够满足海上目标检测场景中的实时检测任务。
4 结 语
针对海上目标检测任务,本文提出一种改进的YOLOv7 算法,运用 MobileViT 模块提高骨干网络的特征提取能力,参照CBAM 特征注意力机制,利用通道注意力模块与空间注意力模块设计更为轻量化的特征融合网络。结合注意力机制改进后的模型在准确率少量下降的情况下,速度达到22.64 帧/秒,权重为9.3 M。结果表明,CS-YOLOv7s 模型能够满足检测准确性与实时性要求,可以更好地完成海上目标检测任务。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
