
燃气负荷预测技术综述
2023-09-14 07:09同济大学机械与能源工程学院郝现英陈志光
上海煤气 2023年4期
同济大学机械与能源工程学院 郝现英 陈志光
长沙新奥燃气有限公司 王建林 雷 行
“双碳”目标的提出,为我国燃气行业带来了新的机遇与挑战,持续推动天然气发展是我国既定的能源战略。天然气具有清洁、高效、低碳等特点,在推动我国能源结构转型和能源供应安全方面发挥着桥梁与支撑作用。近年来,我国天然气产业发展迅速,2020 年天然气消费量约为3 340 亿m3,占一次能源消费总量的8.7%,2025 年我国天然气总需求量预计将达到4 080 亿m3。燃气负荷预测不仅关系到燃气公司的效益,而且对能源供应、燃气输配和燃气管网建设都有重大的影响。
1 燃气负荷预测法
长期以来,国内外学者对燃气负荷预测法进行了许多研究,并建立了多种预测模型。20 世纪50年代,Verhulst 等人在法国首次提出了人工煤气预测模型,为燃气负荷预测的研究奠定了基础。20 世纪80 年代,我国开始进行燃气负荷预测的研究,近些年也有了一定的进展。从国内外的研究情况来看,依据算法理论的不同,燃气负荷预测技术中的预测方法主要可分为数理统计预测法、人工智能预测法及组合预测法。
1.1 数理统计预测法
数理统计预测法是以概率论为基础,运用统计学的方法对燃气负荷历史数据进行分析并得出规律,从而建立数学模型来预测未来燃气负荷。城市燃气领域常用的数理统计预测法包括回归分析法、时间序列法及灰色预测法。
(1) 回归分析法。回归分析法是指通过分析历史数据的规律性,列出回归方程来进行负荷预测,包括一元线性回归、多元线性回归及非线性回归。高红燕等人[1]利用西安市某供暖期的燃气负荷及气象观测逐日资料,分析西安市供暖期、节假日、双休日燃气负荷的变化规律。在此基础上采用多元线性回归分析方法,构建供暖期日燃气负荷预测模型,并对模型进行检验评估。VAJK I 等人[2]基于分段逼近理论,采用非线性方程模型预测燃气负荷,拟合精度较准确。
(2) 时间序列法。按时间顺序对燃气负荷数据进行统计并分析,之后使用模型拟合预测燃气负荷的方法被称为时间序列法。时间序列法分为随机型和确定型两类。随机型时间序列法包括移动平均模型、自回归模型及自回归-移动平均模型等方法,确定型时间序列法则有指数平滑法等。哈尔滨工业大学焦文玲等人[3]通过分析城市燃气负荷的特点及影响因素,应用指数平滑法建立了城市燃气短期负荷预测模型,并指出平滑指数为0.3 的直线模型具有较高的预测精度。ERVURAL B C 等人[4]采用ARMA 的方法,并利用遗传算法优化对土耳其燃气负荷进行预测,有效提高了预测精度。
(3) 灰色预测法。灰色预测法以灰色系统理论为基础,将影响燃气负荷变化的因素视为一个含有不确定性因子的系统,通过累加、累减等方式对原始数据序列进行处理,之后在生成的序列中对被放大的规律进行分析,降低随机波动的影响。金芳[5]针对天津市的燃气年负荷预测提出了灰色残差预测模型,并验证了该模型在一定时间内精度相对较高。由相关实验得出,基于灰色模型来预测燃气负荷预测数据,适用于短期预测[6]。
传统的数理统计预测方法虽然在理论上易于理解、运算快速,但该方法仅从燃气负荷数据角度进行分析,很难得到精确的预测结果,因而目前单独应用数理统计预测方法进行燃气负荷预测的情况较少。
1.2 人工智能预测法
在信息技术飞速发展的今天,人类进入了大数据时代。在大数据背景下,人工智能技术也逐步与燃气负荷预测领域相融合,从而产生了许多智能化的预测模型,推动了燃气负荷预测技术的进一步发展。人工智能预测法中的预测模型主要包括基于人工神经网络的预测模型、基于支持向量机的预测模型及基于深度学习技术的预测模型。
(1) 人工神经网络。人工神经网络是对人脑神经进行高度模拟形成的网络系统。它对信息进行创新性的处理,利用机器学习得到映射出非线性关系的参数,对这些参数进行智能化分析,并对某些不够精确的数据进行自动适应。焦文玲等人[7]针对城市燃气短期负荷预测提出了BP 神经网络模型,并利用该模型得出与实际数据吻合性较强的预测结果。波兰学者Szoplik[8]通过构建人工神经网络中的多层感知器模型,对波兰Szczesin 市的燃气消耗量进行了预测,预测精度较高。
(2) 支持向量机。支持向量机具有扎实的理论基础和良好的泛化性能,其基于结构复杂性最小化原则,并结合考虑模型复杂性与模型学习能力。支持向量机对于处理复杂、小样本及多维度的数据具有优势。清华大学张超等人[9]利用支持向量机的方法,针对华北地区某城市建立了天然气日负荷预测模型,得到了较好的预测结果。
(3) 深度学习。深度学习是加拿大Hinton 教授等人于2006 年首次引入的概念,为机器学习与人工智能研究提供了新思路。深度学习源于人工神经网络,同时也是对神经网络的进一步发展。人工神经网络模型具有容易过拟合、训练时间较长、层数少时预测效果差等缺点。深度学习算法使用的训练机制与神经网络大为不同,它解决了神经网络训练中出现的问题[10]。有研究利用深度多任务学习算法对工业园区整体能源系统进行负荷预测,并验证了该算法的有效性与准确性,表明深度多任务学习在负荷预测方面具有广阔的应用前景。
与数理统计预测法相比,人工智能预测法的应用范围更广,预测精度也比数理统计预测法高。但是由于人工智能预测法的整个预测过程是一个黑箱,故也存在着无法对预测过程展开数学理论分析的缺陷。
1.3 组合预测法
复杂因子和随机干扰影响着燃气负荷序列数据,用单一的模型有时很难达到理想的预测效果。组合模型则结合了多种单一模型的优点,提高了模型的预测效果。按照组合预测模型的构建原则,可以将其划分为基于权重分配方式、基于预测模型参数优化方式、基于数据预处理方式及基于残差修正方式。
(1) 基于权重分配方式。基于权重分配方式是整合各种预测模型的信息,根据预测评价标准构建出基于预测结果的加权组合式预测模型。北京市燃气集团研究院王勋等人[11]分别利用Lasso 算法、线性回归、MLP 神经网络、XGBoost 算法预测北方某城市的燃气日负荷,再基于信息熵理论加权组合单一模型的预测结果,发现组合模型的预测结果比各单一模型的预测精度均高。
(2) 基于预测模型参数优化方式。基于预测模型参数优化方式是利用蜂群算法、布谷鸟搜索算法、果蝇算法等,在理论上改进和优化模型中的激活函数或参数,从而提升预测效果。基于遗传算法优化的BP 神经网络模型,能获得更加理想的预测结果[12]。
(3) 基于数据预处理方式。基于数据预处理方式是全面考虑数据的质量,对输入的数据进行一系列处理,比如特征提取、特征降维、数据去噪等,以确保数据可以完整、准确地输入到预测模型中。用改进的主成分分析法提取燃气负荷的影响因素,随后输入到长短期记忆网络模型中进行预测,实验结果显示预测精度提高很多[13]。
(4) 基于残差修正方式。基于残差修正方式通常是指用一种模型输出的残差序列去修正另一种模型的输出值。西南石油大学王兵等人[14]基于燃气负荷数据特点,采用鲁棒局部加权回归对负荷序列进行分解,针对分解后的趋势项、周期项、余项建立了ARIMA 和Light GBM 组合预测模型,之后设计了三支残差修正法对Light GBM 的预测结果进行修正,该模型的表现良好。
2 燃气负荷预测软件
欧美各国对城市燃气负荷进行了大量研究,在此过程中,燃气负荷预测技术逐渐完善。除了对燃气负荷预测法的研究,许多能源公司都开发出了燃气负荷预测系统和软件。我国在燃气负荷预测软件的开发方面进展比较缓慢,目前国内仅有北京、上海等一线城市具备完善的城市燃气负荷预测系统,而经济较落后地区的燃气负荷预测系统与国外先进水平相比仍有很大差距。我国多数研究都只是针对特定地区,还未建立可对全国通用的预测模型和预测软件系统。常见的国内外部分燃气负荷预测软件各有特点,详见表1。
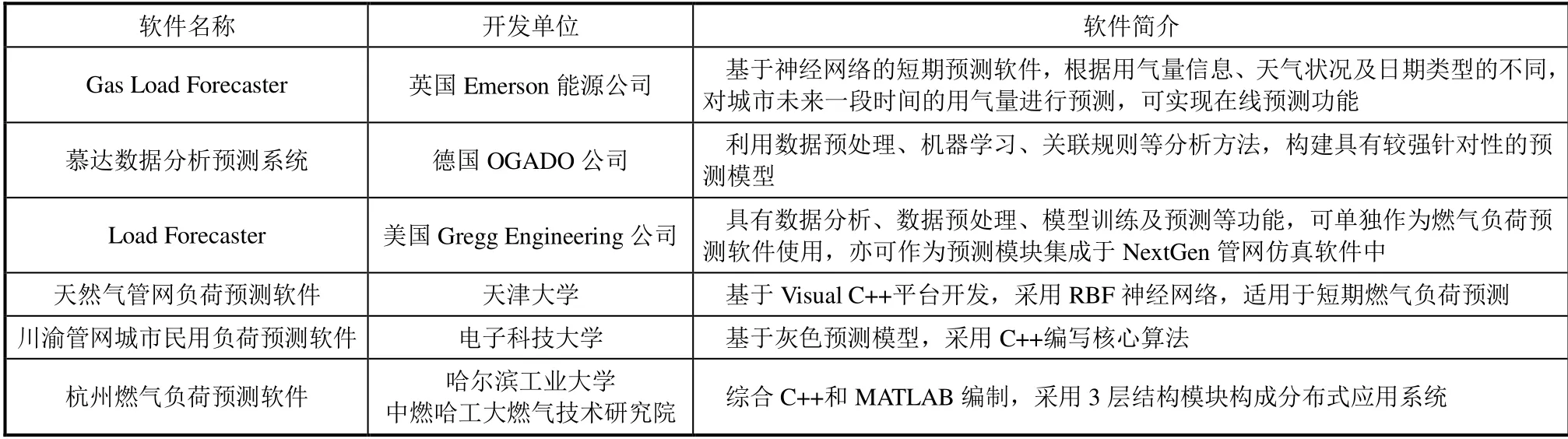
表1 常见国内外燃气负荷预测软件
3 结语
燃气负荷预测技术对于燃气的发展意义重大。燃气负荷预测方法中,数理统计预测法为燃气负荷预测奠定了基础,但该方法只能进行少量的数据预测,且考虑燃气负荷的影响因素较少,预测精度低。人工智能预测法是以机器学习为基础,可进行大量的数据预测。深度学习作为一种新兴的机器学习方法,极大地推动了人工智能的发展,利用该方法构建的燃气负荷预测模型,在泛化性、精确度等方面均有较大提高,其有望成为燃气负荷预测的新发展趋势。组合预测法的初衷是扬长避短,对单一预测模型进行优化,可提高运算速度和预测精度。西方很多发达国家均已开发出多种负荷预测软件,但这些软件并不适合我国的用气状况,因此研究一款与我国用气特征相符的燃气负荷预测软件,是我国燃气行业亟需解决的问题。
猜你喜欢
江苏安全生产(2023年9期)2023-10-24
煤气与热力(2022年4期)2022-05-23
大众投资指南(2021年23期)2021-12-06
广东蚕业(2019年3期)2019-05-14
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
核科学与工程(2015年2期)2015-09-26
中央民族大学学报(自然科学版)(2014年1期)2014-06-11
电测与仪表(2014年14期)2014-04-04
河南科技(2014年7期)2014-02-27
