
基于Deformable DETR的密集行人检测
2023-09-14 07:35张柏园王艺潼周慧
电子元器件与信息技术 2023年6期
张柏园,王艺潼,周慧
大连东软信息学院软件与大数据技术系,辽宁大连,116023
0 引言
行人检测在计算机视觉领域有着非常广泛的应用,例如智能视频监控、人机交互系统、交通分析等。作为先进的无人驾驶技术之一,行人检测系统近年来也作为研发的热点发展起来,它通常整合到碰撞预防系统当中,结合多种传感器检测行人,对周围的环境进行精准预测并及时刹车,减少事故造成的损失[1]。另外,行人检测在智能交通等领域也越来越受到关注。
随着计算机视觉的发展,行人检测算法越来越成熟,但计算机视觉领域下的行人检测算法还存在许多问题,主要分为两类。第一类是行人的多尺度问题。即行人尺度的大小不一致,特别是小尺度行人在图像中占比小,容易受到图像环境和噪声的影响,所以小尺度行人的漏检、误检等问题在检测过程中会经常发生。第二类是行人的遮挡问题。行人之间的遮挡率过高时会导致识别出的行人数量少于实际数量。传统的行人检测算法需要通过提取手工设计特征,再使用提取好的特征来训练分类器,得到一个良好的模型。如Dalal和Triggs[2]提出了HOG与SVM分类器相结合,利用HOG进行特征提取,再使用SVM训练获取分类器,从而实现行人检测。Felzenszwalb等人[3]基于改进后的HOG模型提出了DPM算法,DPM遵循“分而治之”的检测思想,对图像中可变形的物体部件进行了较好的检测,在目标检测方面取得了良好的成果。
随着深度学习[4]的兴起,神经网络可以从大量数据中自动提取特征,从而生成了许多强大的目标识别算法,因此基于深度学习的图像识别算法比传统算法在目标检测等领域中能够取得更好的效果[5]。在行人检测的项目中,将深度学习方法与行人检测相结合进行图像检索组成了行人重识别技术,目前行人检测和行人重识别是作为两个独立的阶段[6]。基于深度学习的目标检测算法主要有两种类型。一种是基于区域提议策略的两阶段目标检测算法,如Fast RCNN[7]、Faster RCNN[8],该类算法精度高,但速度慢、训练时间长。另一种是基于回归框架的一阶段检测与识别算法,主要代表是YOLO[9]系列和SSD[10]系列,该类算法速度快,但精度低、小物体的检测效果不好。上述模型都需要较多的先验知识得到先验框,还会采用非极大值抑制来剔除冗余的预测框,以筛选出高质量的检测结果。2020年Facebook团队提出基于Transformer的端到端目标检测DETR,DETR通过Transformer中的encoder获取全局特征,decoder对明显的个体特征进行解析,在目标检测过程中对重叠目标的检测准确率较高。但这种优势只对大目标检测效果较好,在检测小目标上表现出了较差的性能,主要是因为高分辨率特征会使DETR增加计算复杂度,所以DETR在检测小物体方面性能不是很好。而可变形卷积deformable是一种有效关注稀疏空间定位的方式,Deformable DETR将deformable卷积的最佳稀疏空间采样方法和Transformer的关系建模能力结合起来[11],不仅加速了DETR的收敛,而且降低了问题的复杂性。实验结果表明,基于Deformable DETR在密集人群数据集中检测精度提升,能实现高密集场景下的行人识别。
1 改进的DETR模型
1.1 DETR结构
DETR是基于Transformer的端到端目标检测算法,与之前的目标检测算法相比,它没有非极大值抑制NMS后处理步骤、没有anchor等先验知识和约束,实现了完全端到端的目标检测。DETR的网络结构非常简单,由用于获取图像特征的backbone、基于Transformer的encoder、decoder和prediction四部分组成,具体结构如图1所示。
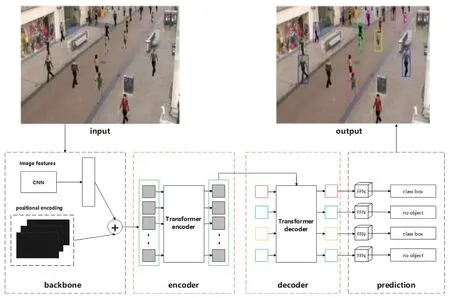
图1 DETR 结构图
在backbone部分采用传统的CNN网络提取特征,经过1×1卷积对通道降维,与图像的位置编码一起送入基于Transformer的encoder中,得到一些候选特征,decoder将这些候选特征和Object Query进行独立解码,最后通过全连接层得到对应的框坐标和类标签,从而得到最终预测。
1.2 基于Deformable Self-Attention的DETR模型结构
Deformable卷积引入了参考点和采样点,每个object query对应一个参考点,它只关注参考点周围的小部分关键采样点,避免了原生注意力机制中需要大量时间去计算每个query和所有图像特征之间的交互,也极大地节省了计算量,其中参考点和采样点的位置是可学习的,推理的结果是参考点坐标的offset,使推理结果与decoder attention直接相关,有利于模型加速收敛。
Deformable DETR采用了多尺度的特征来增强检测效果,对于位置编码采用scale-level embedding,用于区别各种特征层。scale-level embedding是随机初始化并且是随网络一起训练。对于输入一张图片,首先经过Multi-scale Deformable self-Attention选取特征点,再做特征映射并生成向量,然后输入decoder中。decoder过程首先初始化向量,经过self-Attention的处理,然后与encoder特征做注意力运算,最后进行预测。
原始的Transformer注意力的关键问题是它会关注所有可能的空间位置。而Deformable注意力模块只会关注参考点附近少量的关键采样点,不管特征图的空间大小是多少,用query计算出K个offset,然后和参考点相加,算出K个“关注点的坐标”,而不是整个feature mapH*W个点,如图2所示。

图2 可变形注意力
给定输入特征图x∈R(C×H×W),用q作为一个query元素的索引,Zq表示特征图上的原始特征,二维参考点为pq,Deformable注意力特征的计算如下:
m代表多头注意力机制,是注意力head的索引,k代表采样点,K是整个采样点的总个数(K< 本文实验在对小目标行人的检测上,能够准确标定出行人所在的位置,并给出置信度。在对小目标行人进行部分遮挡的情况下,Deformable DETR仍然能够精确标记出行人的位置。在昏暗条件下的行人图像被采集时出现了动态模糊的效果,但是也能够清晰地标记行人所在的位置。数据集选用widerperson,按照8∶2比例划分成训练集及测试集。实验均在型号为NVIDIA Tesla V100的显卡上运行,本文设置训练周期epochs数目为50,初始学习率为0.0002。 本实验采用的实验指标为精确率、召回率、平均精确率和平均召回率。 精确率用来计算被标注为正类的数据中检测结果正确的行人目标数据占整体数据的比例。其中TP表示检测结果正确的正类样本数据,TP+FP则表示整体被标注为正类数据。其计算公式为: 召回率用来计算检测标注为正类行人目标数据占整体被标注为正类数据的比例。其中TP表示检测结果正确的正类样本数据,TP+FN则表示整体满足被标注的样本数据。其计算公式为: 平均精确率综合了精确率和召回率两者的性能,进行更加精准的计算。其计算公式为: 平均召回率是用于比较检测模型性能的数值指标。其计算公式为: 实验关注的重点在于密集场景下能否将遮挡人群正确检测出来,分别选择遮挡情况下计算出DETR模型和Deformable DETR模型的平均准确率AP和平均召回率AR的值。如表1所示,原始的DETR模型在遮挡情况下检测的平均准确率为38.2%,平均召回率为47.7%。而改进后的模型有着明显的提高,相比之下,Deformable DETR模型在该情况下检测的平均准确率和平均召回率分别提升了3.6%和3.8%。该结果证明了Deformable DETR模型在遮挡情况下的行人检测性能优于原始的DETR模型。Deformable Detection模型损失函数收敛情况如图3所示。Deformable DETR识别结果如图4所示。 表1 原始模型与改进模型指标对比 图3 Deformable Detection 模型损失函数收敛情况 图4 Deformable DETR 识别结果 目前精确率较高的目标检测模型如Faster_RCNN、Yolov5、多尺度检测模型FPN等,在正常场景下的人群检测任务中也能取得较好的检测效果。如表2所示,在密集场景的检测中Faster_RCNN模型、Yolov5模型和FPN模型的平均准确度整体的测量值分别为39.9%、23.9%和40.5%,平均召回率分别为47.9%、41.0%和50.8%。Deformable DETR模型的平均精准度达到41.8%,平均召回率达到51.5%。通过表2的对比检测的结果可以得出Deformable DETR模型在存在遮挡情况下的人物目标检测中有着更为突出的表现,相比之下检测性能较强。图5为不同模型的检测效果。 表2 不同目标检测模型指标对比 图5 不同算法识别效果对比示意图 本文针对遮挡场景下的密集人群目标检测容易发生错检和漏检的问题,提出了一种采用可变自注意机制的Deformable DETR目标检测模型,利用可变自注意力机制取代原有的DETR中Transformer的encoder部分,该方法可以显著提高遮挡场景下小目标的检测性能。通过在公开的行人检测数据集实验对比分析,验证了该模型在遮挡场景中的小目标检测具有可行性和有效性。2 实验结果与分析
2.1 实验过程
2.2 实验指标
2.3 实验分析



2.4 与其他模型对比


3 结论
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林(2021年5期)2021-04-18
金属加工(冷加工)(2020年11期)2020-11-24
扬子江(2019年1期)2019-03-08
测控技术(2018年5期)2018-12-09
精密制造与自动化(2018年1期)2018-04-12
传媒评论(2017年3期)2017-06-13
小天使·一年级语数英综合(2017年6期)2017-06-07
第二课堂(课外活动版)(2016年2期)2016-10-21
设备管理与维修(2016年5期)2016-03-16
