
数据结构与算法创新实验教学实践
——以跨模态检索为例
2023-09-13 13:20:36宗林林刘馨月徐秀娟张晓彤张宪超
实验室研究与探索 2023年6期
宗林林, 于 红, 刘馨月, 徐秀娟, 张晓彤, 张宪超
(大连理工大学软件学院,辽宁 大连 116620)
0 引言
数据结构与算法是信息学科相关专业学生掌握计算机程序与现实世界问题关联的入门课程。该课程的任务是使学生从应用角度出发,掌握基本数据结构的逻辑结构、物理结构及常用算法,能够运用课程所讨论的结构和算法更好地进行数据处理,为进一步提高程序设计的能力、进一步学习和掌握计算机专业基础知识奠定基础。本课程分成5 大部分:基本概念及线性表结构、树与二叉树、图、检索、排序。传统教学中均使用传统的案例进行讲解并分析算法应用,在大数据蓬勃发展的今天具有较大局限性。
大学生创新创业训练计划项目的实施,有助于改革人才培养的模式,增加本科生的创新实践经历[1-2]。学生可以自主选题或者参与教师科研项目中的课题,经过项目背景调研、问题提出、设计解决思路、数据处理与实验验证几个阶段,最终完成整个项目的研发。通过开展大学生创新创业训练项目,重点培养学生将课本中的理论知识应用于实际问题的能力,从而提高大学生的创新能力,进一步培养适应国家创新发展需求的高水平创新人才[3-5]。
本文以数据结构与算法课程中的检索任务为例,在创新训练项目中,分析大学生如何利用课本中的内容来提高分析问题和解决问题的创新能力。在大数据时代,数据常表现为文本、图片、视频、音频等多模态形式[6],多模态数据作为近年来被广泛分析的一类数据,其数据特性与传统单模态数据具有较大的差异。基于多模态数据方面的科研项目,结合数据结构与算法中检索一章的内容,在跨模态检索任务中,引导本科生提出自己的想法,在老师的指导下完成4 项大学生创新训练项目。
1 跨模态检索设计
随着移动互联网的迅速发展,网络平台的多媒体数据呈现出多模态、多样化的特征,网络多媒体数据的形式从单一文本数据逐渐转变为表达形式生动、内容丰富的图片、视频、音频等多模态数据,多模态数据融合过程贴近人类自主学习和认识世界的内在规律,因此如何实现多模态数据的有效整合,亟待深入研究和突破。
针对多模态数据处理相关项目背景和研究意义与前景[7],学生初期获取最为广泛使用的维基百科多模态数据集,为后续的具体计算与分析奠定基础。该数据集由2866 对图像和文本组成,每一对由图像和对应的完整文本文章组成,用以描述总共10 个语义类(即艺术,生物,历史等)中的一种。基于维基百科数据,首先对于两个模态中的数据,将第j个样本中第i个模态定义为,然后将其中的ni个数据一一标识为,其中,1}c是对应的语义标签向量,其中c代表着语义种类数。如果样的语义类别为第k类,则=1,否则=0。
与传统检索任务类似,跨模态检索[8]也需要首先给定待查询样本,然后在数据集合中通过依次比较数据进行检索。这里跨模态检索任务可以分解为通过图片检索文本和通过文本检索图片两个子任务。在图检文和文检图两个子任务中,如果检索样本和检索结果样本的语义类别相同,则认为检索成功,否则视为检索失败。与传统检索任务相比,跨模态检索的难点在于如何在文本和图像之间进行比较。图1 展示了跨模态检索任务的流程图。
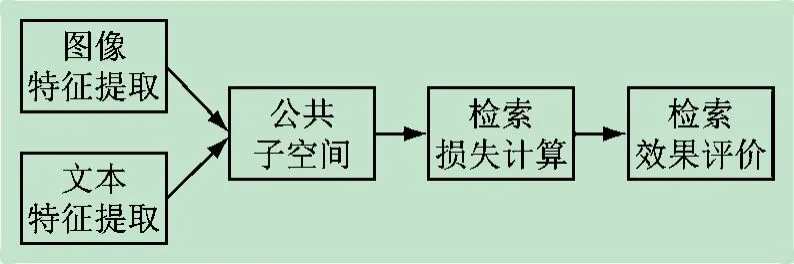
图1 跨模态检索流程图
(1)为了对数据进行更好地处理,学生需要接触并学习Python、文本和图像特征提取方法,用基于Python语言的文本和图像特征提取工具实现维基百科数据中文本和图像内容的特征提取;
(2)进行数据挖掘操作,考虑到图像和文本语义表达形式的不同,将不同模态结果映射到相同的子空间中,连接标签向量单元进行损失计算;
(3)学生采用平均精度(mAP)作为检索成功率的评价指标,绘制mAP 分数表格表示这一指标,并绘制查全率-查重率曲线辅助进行额外的比较。
2 大学生跨模态检索创新实验
学生通过老师提供的国内外相关资料,初步掌握文本和图像两个模态数据的特点,在一般数据挖掘知识的基础上,认识到多模态数据的特性。相关的大学生创新项目采取渐进式教学方法[9],主要进行了图像标注实验、可扩展跨模态检索实验;联邦跨模态检索实验。
2.1 图像标注实验
跨模态任务涉及图像处理、文本处理等知识,因此,首先通过一个图像标注的实验,令学生掌握基本的图像和文本处理方法,学习跨模态学习领域的基本知识,掌握Python 语言及其使用环境等运用方法,感受到共同合作、各取所长、团结协作的重要性。
图像标注的任务是根据图像给出对应描述的自然语言语句。学生主要练习图像特征提取和Transformer模型[10]的使用。学生在编码器中通过ImageNet 上预训练的InceptionV3 完成对图像的相关特征提取[11],得到一组64 ×2048 的特征向量,然后再经过一层全连接层对特征进行编码,同时在解码器中使用4 层Transformer。第1 层的输入是真实标注命名为x,以及编码器的输出标注命名为enc_output。首先对x使用多头注意力处理得到out,然后将out 作为下一个多头注意力机制的查询,enc_output 作为下一个多头注意力的关键码、值,然后输出得到下一层的输入y,往复执行之前的操作。
具体实施过程中,采用Python 环境下的TensorFlow 库对图像进行操作。通过tf. keras.applications.InceptionV3 使用在ImageNet 上预训练的InceptionV3 模型。由于InceptionV3 模型要求输入图片的大小为299 × 299,因此在此之前需要使用tf.image.resize函数将所有图片大小调整到299 ×299。预处理和标注处理时,选择所有标注中的前100000个单词来生成序列,计算所有标注的最大长度为52。实验结果如图2 所示,给定图2 中的图像,输出图2 的文字描述。

图2 图像标注结果展示(一辆双层巴士在街上行驶)
2.2 可扩展跨模态检索实验
本项目主要研究可扩展跨模态检索,以期望得到一个模态动态增加时的高效模型[12]。学生学习一个可拓展的深度跨模态检索模型(SDML)[13],分析模型的优缺点,保留模型优点,突破模型缺点,提出相应的解决方案,并进行实践验证。
SDML模型的基本思路是为每一个模态建立单独的网络,这些网络各自的目标是读取各自模态的数据,然后学习并转换到固定子空间中进行学习,将数据投影到预定义的公共子空间P中,这种操作将使得不同类别之间数据之间的相关性被进一步提高。该方法可以在4 个核心部分进行优化:优化编码器;优化解码器;优化P矩阵;优化损失计算函数。经过反复试验,发现对损失计算函数的修改导致效果提升不明显,测试还发现解码器对最后效果有提升作用但是并没有预期中的提升,另外,因公共子空间过于繁杂且最后采取的样本语义数量相同而忽略了对P 矩阵的修改。因此,主要在编码器角度进行模型优化。
学生深入分析原模型中的编码器,发现其仅仅由全连接层组成,这种结构非常依赖于输入数据,一旦输入数据特征不明显就会导致模型的表现较差,仅仅依靠全连接层简单地实现模型的通用性是不够的。因此,指导学生优化编码器结构。
对于图像模态,学生将全连接结构替换成了卷积神经网络(CNN)结构,具体而言,在全连接层前增加了4 层卷积层用于提取图像特征,每层卷积层后连接了一个归一化层以防止数据在进入下一层函数前因为数据过大而导致网络性能的不稳定,下一层的线性整流层作为激励函数给模型增加非线性语义,之后相连的一层最大池化层减少卷积层输出的特征防止出现过拟合。卷积层和其余各层数量一致为4 个。对于全连接层,因卷积层的特征提取已经足够,将其修改为单层全连接层做维度修改以映射到公共子空间中。
对于文本模态,学生采用对文本友好的文本卷积神经网络(textCNN)模型,其思路和CNN类似,该模型对无上下文语义的文本分类非常有效。文本与图像有着模态异构性,具体而言彩色图像通常是三维表示,而文本则是二维数据,因此将卷积层进行缩减,由原先的4 层缩减到3 层以更高效地提取特征,并且在实现细节有区别,比如textCNN 使用的一维卷积,而CNN 使用的二维卷积。修改后的模型具体如图3 所示。
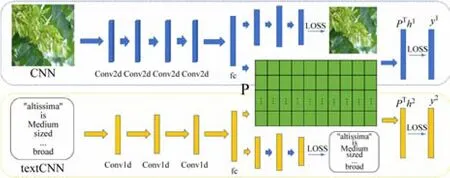
图3 修改后的模型展示
本项目的实验在维基百科数据上,学生对比SDML模型,SDML-1 模型(上文中描述的使用CNN和textCNN 的版本)和SDML-2 模型(使用VGGNet 和Doc2 Vec提取特征的版本),3 种版本分别对应着无针对性神经网络模型,简单的神经网路模型,复杂的神经网络模型。
在维基百科数据集上,图4 分别显示了图像-文本和文本-图像的查重率(Precision)、查全率(Recall)曲线。表1 中展示了修改模型mAP 的对比结果。通过它们之间的比较可以看出,为每个模态添加在各自分类中表现较好的特征提取模块将提升跨模态检索模型的效果,进而验证学生修改方向的正确性。
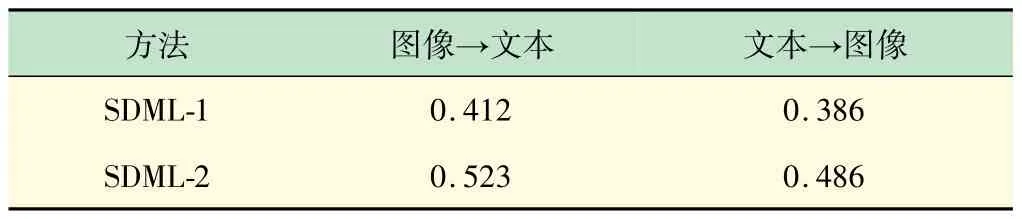
表1 维基百科数据集上修改模型的mAP数值
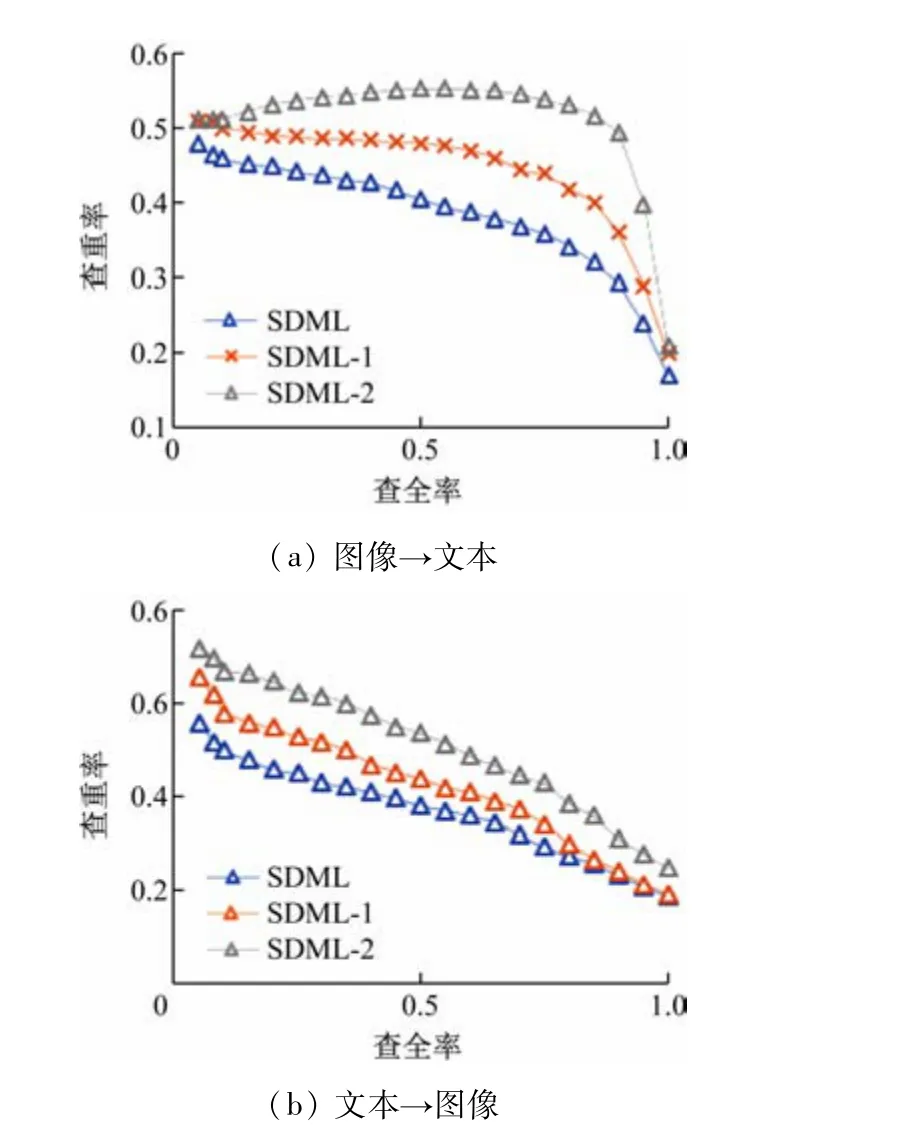
图4 维基百科数据集上的查全率-查重率曲线
2.3 联邦跨模态检索实验
近年来由于互联网的高速发展,互联网用户有关搜索引擎的旺盛需求不断增加,而跨模态检索在搜索引擎和多媒体数据中的地位也越来越重要。深度的跨模态检索算法虽然性能很好但需要大量的训练数据。然而,聚合大量的数据将会产生巨大的隐私风险和高昂的维护成本。该问题与学生日常生活非常接近,学生对此类问题兴趣浓厚。经过调研后,发现要缓解用户隐私问题,可以结合联邦学习[14]的思想。本项目期待能够使用分散的多模态数据学习模型。在跨模态检索的基础上,学生可以进一步接触联邦学习领域的知识,扩大学生知识面。
学生提出联邦跨模态检索方法FedCMR,在传统的联邦学习算法中,多个客户端在可信中央服务器的协调下进行多轮通信,协作训练模型。在每一轮通信过程中,各客户端利用本地数据训练模型,并将训练成果模型上传至中央服务器进行安全聚合。但是在客户端本地模型架构复杂、参数量多的情况下,这样的做法通常会导致训练过程的通信开销巨大。考虑到子空间学习法作为跨模态搜索的主流方法,其重点是找到不同模态数据共享的公共子空间,以度量不同模态数据之间的相似性。所以,如图5 所示,提出用公共子空间代表客户端模型,上传至中央服务器,联合寻找一个全局一致的潜在公共子空间。
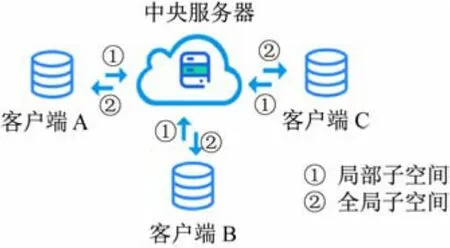
图5 联邦训练过程
具体实施过程分为本地训练、聚合和本地更新3个过程。在本地训练阶段,每个客户端都使用本地数据训练跨数据检索模型;在聚合阶段,服务器会聚合客户端的公共空间;在本地更新阶段,每个客户端根据最后一步计算的聚合模型更新本地模型的公共子空间。
学生在维基百科数据集上进行实验,为了模拟联邦跨模态检索过程,在实验中平均向3 个客户端分配数据。为了使所有客户获得适合本地目标函数的高质量模型,将训练过程分为联合训练和独立增强训练两个阶段。在联合训练阶段,每个客户端将随机选择80%的本地数据集来完成模型聚合过程。在独立的增强训练阶段,每个客户端完成本地更新过程,并继续使用剩余20%的数据迭代本地模型,从而缩小全局一致的公共子空间,使其更适合本地模型测量来自不同模式的样本之间的相似性。
在实验中,采用一个19 层的VGNET 来学习图像样本的表示,并获得VGNET的fc7 层为每幅图像输出的4096 维表示向量。为了表示文本样本,使用句子BERT来学习每个文本的1024 维表示向量。利用广泛使用的联邦学习框架PySyft来模拟联邦跨模态检索过程。
为了证明所提出的联邦学习方法的有效性,将FedCMR与以下方法进行了比较:①DSCMR[15],它在每个客户端上进行DSCMR,但不聚合客户端;②FedAvg[16],它在每个客户机上执行DSCMR,然后使用FedAvg聚合客户端。
表2、3 介绍了FedCMR的mAP评分和比较方法。从表中来看,有以下观察结果:①FedCMR 显著优于基准的联邦学习方法FedAvg。②FedCMR 的总体表现优于DSCMR。结果表明,研究多模态联邦学习是合理的,特别是在数据少量的情况下,多模态联合学习对聚合跨模态检索模型更有效。
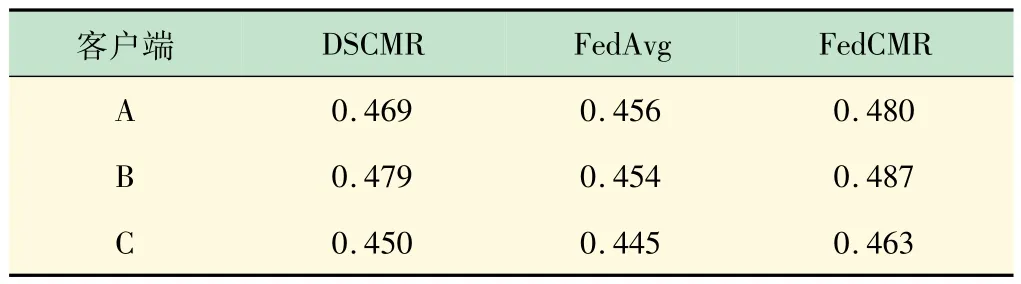
表2 维基百科数据集上图像→文本的mAP数值
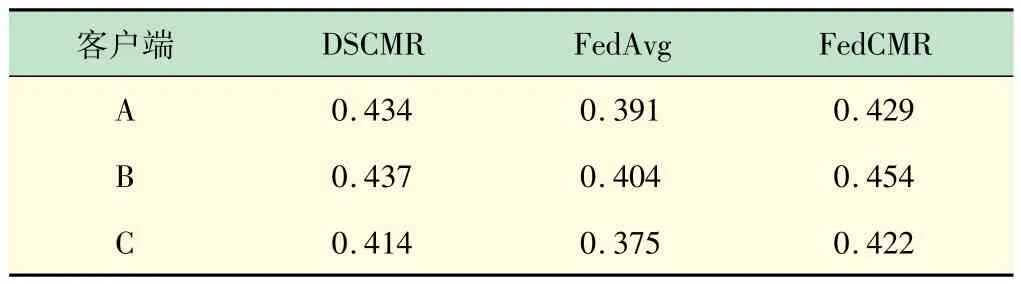
表3 维基百科数据集上文本→图像的mAP数值
3 实验效果
目前,这些案例已在我校实施3 轮,共有3 届学生受益。数据结构与算法课程于2020 年获评辽宁省线上线下混合式一流课程。获国家级大学生创新训练项目1 项(多模态3D物体识别),省级大学生创新项目2项(基于深度神经网络的跨模态检索算法研究,基于跨模态学习的视频检索系统)和校级大学生创新项目1项(基于深度学习的跨模态检索系统)。其中,省级大学生创新项目在第44 届信息检索研究与开发国际会议SIGIR 发表1 篇学术论文《FedCMR:Federated Cross-Modal Retrieval》[17],并且其中一位成员推免至复旦大学攻读研究生,一名成员推免至本校攻读研究生。
4 结语
跨模态检索创新实验将教师的科研项目很好地融合到课程教学中,解决了数据结构与算法课程教学过程中理论与实际脱节的问题。通过参与跨模态检索相关的创新实验,学生的阅读文献、发现问题、创新意识、动手能力和团队协作能力都得到了有效地提升,也加深了学生对理论学习的认识,深化了学生将理论知识应用到实际的能力。这些项目对于科研反哺教学、培养解决实际应用需求的高水平人才进行了一次有效的探索。
猜你喜欢
英语世界(2023年10期)2023-11-17 09:18:46
英语文摘(2021年8期)2021-11-02 07:17:46
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
专利代理(2016年1期)2016-05-17 06:14:36
读者·原创版(2015年11期)2015-03-01 06:15:34
意林(2014年2期)2014-02-11 11:09:17
测绘科学与工程(2013年1期)2013-03-11 15:07:25
