
基于机器阅读理解的案件要素识别方法
2023-09-13 03:14:38窦文琦陈艳平秦永彬黄瑞章刘丽娟
计算机工程与设计 2023年8期
窦文琦,陈艳平,秦永彬+,黄瑞章,刘丽娟
(1.贵州大学 计算机科学与技术学院 公共大数据国家重点实验室,贵州 贵阳 550025;2.贵州师范学院 丽琼工作室,贵州 贵阳 550018)
0 引 言
在大数据和人工智能发展的背景下,智慧司法研究领域兴起并日趋火热,类案推荐、刑期预测、信息抽取等自动化研究成为了该领域的热点研究方向。随着我国司法机关不断推进案件信息公开,海量的裁判文书得以出现在互联网上,这些裁判文书蕴含了丰富的信息,对其进行挖掘将产生巨大的价值。案件要素识别作为司法信息抽取任务中一部分,为量刑、罪名预测等任务提供信息支撑。
以盗窃案为例,从“外衣口袋内”这一关键信息可以推断出被告存在扒窃的盗窃行为;“如实供述”表示被告认罪态度好;“曾因犯盗窃罪”说明被告属于累犯。这些包含重要信息的案件要素可以决定案件性质、左右被告人量刑。案件要素在裁判文书中有多种不同的表现形式,使用人工查找的方式耗时耗力。因此,使用深度学习模型辅助司法工作显得尤为重要。
针对案件要素识别的研究存在以下几个难点:传统的案件要素识别方法主要通过裁判文书中的文本特征预测案件要素的标签类别,忽略了案件要素标签的司法语义信息;在裁判文书中,某些案件要素在裁判文书中的出现次数相对较少,导致模型无法充分学习到小样本的特征,很难从中提取规律。针对以上问题,本文提出了一种基于机器阅读理解的案件要素识别方法,主要研究工作如下:
(1)本文方法将案件要素标签信息作为先验知识辅助模型进行案件要素的识别。针对每类案件要素进行案件要素标签信息与上下文的语义交互,使模型充分学习到小样本中的语义特征,提高了模型的整体性能。
(2)本文针对裁判文书中文字书写歧义问题,使用对抗训练策略。在模型的词嵌入部分应用对抗扰动,提升了模型应对噪声样本的鲁棒性。
1 相关工作
近年来,随着神经网络和深度学习的发展,越来越多的学者开始将其用于相关要素的识别任务中。如邓文超[1]使用深度学习方法对单人单罪的刑事案件识别时间、地点、影响、行为等基本案件要素,并应用于自动量刑、相关法律条文预测和相似案件推荐等司法任务中。刘等[2]提出多任务学习模型,对案情描述部分采用BiLSTM神经网络和注意力机制进行编码,识别法条和罪名要素。使用文本分类方法进行案件要素识别的模型有Att-BiLSTM、TextCNN、FastText、DPCNN[3]等。为了进一步提升要素识别的效果,Liu等[4]采用基于BERT[5]的预训练语言模型将案件要素识别问题转化为多标签分类任务,加入Layer-attentive策略微调,提升了案件要素识别的性能。Huang等[6]提出了SS-ABL框架,充分利用领域知识和未标记数据改进分类器。与以前仅用单一信息的方法相比,实现了显著的性能改进。
近年来,基于深度学习的机器阅读理解方法受到了广泛的关注。机器阅读理解是指根据给定的问题,从文本中找到答案。Wan等[7]提出了一种新的基于Transformer的方法,能够识别段落的相关性并通过具有级联推理的联合训练模型找到答案范围,可以有效地处理长文档。Li等[8]提出了一种多任务联合训练方案,通过增强预训练语言模型的表示来优化阅读理解模块,并通过胶囊网络优化答案类型分类模块,设计了一个多任务联合训练模型,同时获取答案文本和答案类型。越来越多的学者将信息抽取任务转化为机器阅读理解方法,例如实体关系抽取[9,10]、事件抽取[11]、命名实体识别[12,13]等。Li等[9]使用机器阅读理解方法处理命名实体识别任务,在嵌套和非嵌套的NER上都表现出了良好的性能。Gupta等[14]提出了一种新颖的名词短语生成方法构造输入问句,使用机器阅读理解模型从句子中识别实体,并证实了模型的有效性。刘等[15]借助机器阅读理解方法,引入先验知识,充分挖掘上下文的语义信息,提高了中文命名实体识别的精确性。
注意力机制在机器阅读理解模型中的运用比较广泛,许多模型都是针对这一部分进行改进的。Shen等[16]在注意力机制层将问题和上下文汇总为单个特征向量。Yu等[17]发现BiDAF注意力考虑了文本到问题以及问题到文本的双向注意力,它比简单地使用从文本到问题的单向注意力效果更好。受此启发,本文方法采用BiDAF注意力策略,以便更好地进行案件要素标签信息与上下文之间的语义交互。
2 模 型
本文方法中案件要素识别模型主要分为3个部分,如图1所示,从左到右依次为嵌入层、交互层和预测层。①在嵌入层,使用FGM算法在word embedding部分添加对抗扰动,将对抗样本和原始样本混合一起训练模型以提升模型应对噪声样本的鲁棒性。案件要素标签信息构建的问题与文本以拼接的形式进行输入。②在交互层,使用RoBERTa预训练语言模型以增强问题和文本的语义表征。通过双向注意力从两个方向出发为上下文和案件要素标签信息的交互提供补充信息。③在预测层,通过一层全连接网络和softmax函数最终识别案件要素。
2.1 数据预处理
此节通过数据预处理构建符合阅读理解的输入形式。给定一篇裁判文书
P={P1,P2,…,Pn}
(1)
其中,n表示文本P的长度。给P中所有的案件要素分配一个标签y∈Y,Y是所有标签种类(如案件要素标签again累犯,surrender自首等)的预定义列表。
首先将带标签的数据集转换为三元组(问题,答案,上下文)的形式。每个案件要素标签y∈Y都与一个问题相对应,问题表示为
Qy={Q1,Q2,…,Qm}
(2)
其中m表示问题Qy的长度。三元组(问题,答案,上下文)中每个“问题”与案件要素标签y∈Y相对应,“答案”即是案件要素存在与否,记为A,“上下文”代表一篇裁判文书P。最终表示为三元组 (Qy,A,P) 的形式,向模型输入Qy、P,期望输出A。
使用案件要素标签信息进行问题的构造,案件要素标签信息根据量刑规则制定。问题统一设为表1的形式。

表1 问题构建
2.2 嵌入层
模型的输入包括问题Qy、裁判文书P、特殊符号[CLS]和[SEP],它们组成输入序列
{[CLS],Q1,Q2,…,Qm,[SEP],P1,P2,…,Pn,[SEP]}
(3)
如图2所示,对于序列中的每一个token,其输入表示是词嵌入(token embeddings)、段嵌入(segment embeddings)和位置嵌入(position embeddings)三者的相加[5]。词嵌入层将各个token转换为768维的向量表示;段嵌入层用两种向量表示,辅助区分Qy和P两部分,第一个向量中各个token用0表示,第二个向量中各个token用1表示;位置嵌入层通过在每个位置上学习一个向量表示进行序列顺序信息的编码。

图2 模型输入表示
2.3 交互层
本层使用RoBERTa[18]模型作为编码器,结构与BERT[5]一致。RoBERTa[18]是一种经过预训练的深度双向Transformer模型,可在各种任务中实现先进的性能,结构如图3所示。

图3 RoBERTa结构
图3中的TN代表第N个字符经过RoBERTa网络输出的语义字符向量,Trm代表Transformer。每一层的输入都是基于上一层的输出,第i层的输出可以表示为
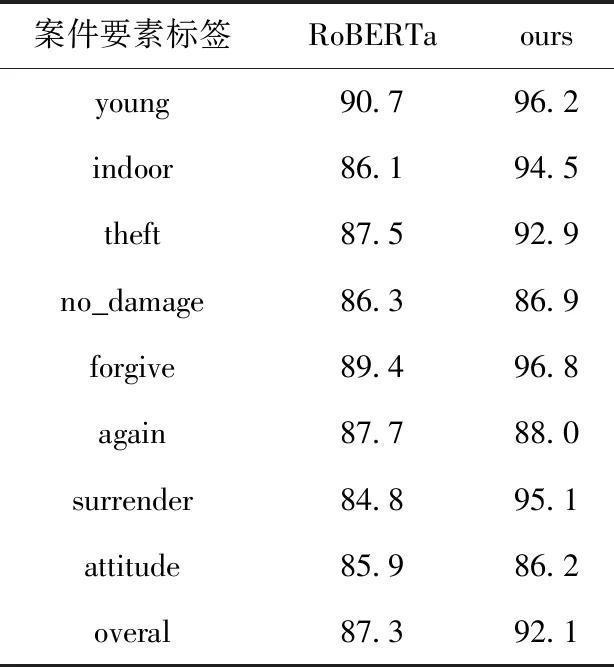
Hi=TransformerBlock(Hi-1),1 (4) 其中,Hi∈Rt×d,t为序列长度,d为隐层维度,L表示Transformer层数。 在注意力交互部分,使用Q∈Rm×d和P∈Rn×d来分别表示编码的问题和上下文。首先计算每对Q和P的相似性,相似矩阵表示为S∈Rn×m。其中Snm表示第n个上下文词和第m个问题词的相似性,此处使用的相似度函数为[17] α(p,q)=W0[p;q;p⊙q] (5) (6) 其次计算从上下文到问题(P2Q)以及问题到上下文(Q2P)两个方向的注意力。 P2Q注意力表示哪些问题词与每个上下文词最相关。P2Q注意力如图4所示,构造如下: 图4 P2Q注意力 通过应用softmax函数对相似矩阵S的每一行进行归一化,第n个上下文词对问题词的注意力权重an计算为 (7) 对于所有n,Σanm=1。 每个上下文关注的问题向量为 =∑manmQ (8) Q2P注意力表示哪些上下文词与每个问题词最相关。Q2P注意力构造如下: 通过函数maxcol找出相似矩阵S每一列的最大值并进行归一化。问题词对上下文词的注意力权重b计算为 b=softmax(maxcol(S))∈Rn (9) 问题关注的上下文向量为 =∑nbnP∈Rd (10) (11) β(p,,)=[p;;p⊙;p⊙]∈Rn×3d (12) 上一层通过双向注意力交互生成的表示矩阵E经过解析层得到最终的语义表征E’,输入到预测层进行预测。 在预测层,通过预测答案类型来判断案件要素是否存在。将特殊符号[CLS]表示hCLS作为序列的整体表示,被传递到一个全连接层以计算概率分布,进而表示答案类型 Ptype=softmax(FFN(hCLS)) (13) 其中,hCLS为特征向量,FFN表示全连接层,softmax表示层归一化。 使用Focal Loss作为损失函数,答案类型损失定义如下 L=FocalLoss(ptype,Y) (14) 其中,Y为答案类型标签。 GAN之父Goodfellow首先提出对抗训练概念,其基本原理为在原始输入样本上添加扰动radv,得到一些对抗样本,然后将对抗样本放在模型中进行训练。这样不仅可以提高对抗样本的鲁棒性,还可以提高原始样本的泛化性能。起初的对抗训练是针对CV任务的,为了将对抗训练迁移到NLP任务中,Goodfellow提出了FGM算法,FGM算法可以在连续的embedding上做扰动。本文方法使用FGM算法进行对抗训练,将对抗扰动应用于词嵌入(word embedding)。设词嵌入向量为S,模型参数为θ,给定模型的条件概率为p(y|S;θ)。 则S上的对抗性扰动radv定义为 radv=-∈g/g2 (15) (16) 本文的数据集来自裁判文书网,包含某省的脱敏裁判文书数据。在所有案件中盗窃案占了相当大的比例,因此选用917篇盗窃案裁判文书作为实验数据集,表2详细描述了相关案件要素的统计信息。 表2 数据集相关信息 评价指标准确率(Precision)、召回率(Recall)、F1值(F1-score)的计算方式如下 precision=TPTP+FP (17) recall=TPTP+FN (18) F1=2*recall*precisionrecall+precision (19) 其中,TP表示正确预测为正例,FP表示错误预测为正例,FN表示错误预测为负例。 本文模型采用Python平台,PyTorch 框架实现,在NVIDIA Tesla P40 GPU平台上进行实验。批处理大小batch_size=16,训练轮数epoch=10,学习率learning_rate=2e-5,权重衰减指数weight_decay=0.01,最大总输入序列长度max_seq_length设为512,问题最大长度max_question_length设为64,答案最大长度max_answer_length设为55,优化器使用AdamW优化器。 3.4.1 对比实验 将本文模型与案件要素识别常用的多标签分类模型作对比,模型分为无预训练和有预训练两类,实验结果选取3次实验的平均值。 (1)无预训练模型选择Att-BiLSTM、TextCNN、FastText、DPCNN[3]。其中,Att-BiLSTM是基于attention机制的双向LSTM神经网络模型;TextCNN是用来做文本分类的卷积神经网络;FastText能取得与深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级;DPCNN用来解决TextCNN在捕获长距离特征时不理想的问题; (2)有预训练模型选择BERT[5]、ERNIE[19]、RoBERTa[18]、SS-ABL[6]。其中,BERT是Google提出的基于Transformer的预训练模型,下游多标签分类任务采用微调方法;ERNIE在BERT的基础上采用短语和实体级别的mask;RoBERTa在BERT的基础上使用更大的数据再次训练,改进优化函数,采用动态mask方式训练模型;RoBERT+Seq2Seq_Attention是指用RoBERTa提取文本特征,用Seq2Seq_Attention框架进行标签的识别;SS-ABL使用反绎学习方法实现基于BERT模型的案件要素识别。 本文的模型和其它模型在同一数据集下识别效果见表3,从实验结果可以看出,使用预训练模型比不使用预训练模型的效果要好,其中RoBERTa预训练模型表现最为出色,因为预训练方法可以让模型基于一个更好的初始状态进行学习,从而达到更好的性能。相比无预训练的多标签分类方法,本文方法提升了12.2%,相比有预训练的多标签分类方法,本文方法提升了3.2%。与对比方法相比较,本文方法在预训练模型RoBERTa的基础上使用了机器阅读理解方法,通过案件要素标签信息构造的问题为模型的识别提供了辅助作用;通过双向注意力机制进行问题与上下文语义的进一步交互,使模型更加关注于问题指示的上下文信息;通过对抗训练进一步提高了模型的鲁棒性,使模型在案件要素识别任务上有更好的效果。 表3 模型性能对比/% 3.4.2 消融实验 为了验证本文方法各模块的有效性,我们对模型进行了消融实验,实验结果见表4。MRC表示使用机器阅读理解方法,Attention表示加入双向注意力机制,AT表示对模型使用对抗训练,FLoss表示使用Focal Loss损失函数。 表4 模型消融实验/% RoBERTa预训练模型为消融实验的基准模型。 RoBERTa+MRC在基准模型RoBERTa的基础上使用了机器阅读理解方法,F1值提升了3.3%。因为本文使用的机器阅读理解模型在输入文本前加入了案件要素标签信息即案件要素类型的描述信息,这些案件要素类型的描述作为先验知识提升了模型的识别效果。 RoBERTa+MRC+Attention在RoBERTa+MRC的基础上增加了双向注意力机制,F1值提升了0.2%。经过RoBERTa模型之后使用双向注意力机制进一步融合上下文和问题之间的交互信息,使模型更加关注于与问题有关的上下文语义表征,进而提升识别效果。 RoBERTa+MRC+Attention+AT在RoBERTa+MRC+Attention的基础上对模型加入了对抗训练,F1值提升了1.1%。使用对抗训练中的FGM算法在word embedding部分应用对抗扰动,可以提高模型在应对噪声样本的鲁棒性。 RoBERTa+MRC+Attention+AT+Focal Loss在RoBERTa+MRC+Attention+AT的基础上使用Focal Loss损失函数,F1值提升了0.2%。Focal Loss损失函数降低了大量简单负样本在训练中所占的权重,可以更好地挖掘困难样本。 3.4.3 细粒度实验 为了验证本文方法在应对小样本案件要素情况下的表现,用本文方法与对比实验中的RoBERTa基线模型进行细粒度对比,进一步输出每种案件要素的细粒度结果。实验结果见表5,本文方法在属于案件要素类别young、surrender的小样本数据上分别提升了5.5%和10.3%。例如,属于surrender类别的案件要素在裁判文书中表现形式多样,在数据样本量较少的情况下仅通过学习裁判文书的文本特征很难进行有效识别。本文使用的机器阅读理解方法通过在输入文本前拼接案件要素标签信息,获得了一定的先验知识,使得模型充分学习到所要识别的案件要素特征。因此,本文使用的机器阅读理解方法对小样本案件要素的识别效果有所提高,可以有效改善样本不均衡问题。 表5 细粒度实验F1/% 3.4.4 对抗训练对模型鲁棒性的影响 为了验证对抗训练对模型鲁棒性的影响,本小节将扰动参数∈设1.0,对比了模型在加入对抗训练和不加对抗训练的效果,实验结果见表6。 表6 对抗训练对模型的影响/% 实验结果表明,对抗训练在对大部分的案件要素类别的识别上都有一定的提升。与不加对抗训练时的模型相比,加入对抗训练后的F1值整体提升了1.1%。这说明在原有模型训练过程中注入对抗样本,可以提升模型对微小扰动的鲁棒性,进而提升模型的整体性能。 3.4.5 Focal Loss对模型的影响 为了验证Focal Loss对模型性能的影响,在本文方法的基础上分别选用CE Loss和Focal Loss两种损失函数进行比较。实验结果见表7,可以看出使用Focal Loss的效果更好。 表7 Focal Loss对模型的影响/% 虽然CE Loss可以平衡正负样本的重要性,但是不能区分难易样本,Focal Loss可以降低易区分样本的权重,并关注难区分样本的训练。Focal Loss在CE Loss的基础上添加了调制因子,其中的参数γ∈[1,5] 取值对模型的影响见表8。从实验结果可以看出,γ取值为2时效果最好,我们选择γ取值为2时的Focal Loss作为本文模型的损失函数,使模型达到最佳表现。 表8 选取Focal Loss中不同γ值的影响/% 本文提出了一种基于机器阅读理解的案件要素识别方法,利用案件要素标签信息构造问题辅助模型识别。使用RoBERTa预训练语言模型增强问题和上下文的语义表征,通过双向注意力机制更好地融合问题到上下文以及上下文到问题的语义信息。实验结果表明,本文方法可以有效改善小样本案件要素的识别性能。同时,本文采用的对抗训练FGM算法进一步提升了模型的鲁棒性。 在未来工作中,我们将进一步识别更多类别的案件要素,并将其应用到法律判决预测的真实场景中。

2.4 预测层
2.5 对抗训练
3 实验及结果分析
3.1 数据集


3.2 评价指标
3.3 实验设置
3.4 实验结果及分析





4 结束语
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
当代水产(2020年4期)2020-06-16 03:23:30
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
现代园艺(2017年22期)2018-01-19 05:07:22
河北书画研究(2017年1期)2017-08-22 12:11:50
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
公民与法治(2016年10期)2016-05-17 04:12:58
山东青年(2016年2期)2016-02-28 14:25:36
