
加入梯度均衡机制的端到端方面级情感分析
2023-09-13 03:14:54罗涵天杨雅婷
计算机工程与设计 2023年8期
罗涵天,杨雅婷+,马 博,董 瑞,李 晓
(1.中国科学院新疆理化技术研究所 多语种信息技术实验室,新疆 乌鲁木齐 830011;2.中国科学院大学 计算机科学与技术学院,北京 100049;3.中国科学院新疆理化技术研究所 新疆民族语音语言信息处理实验室,新疆 乌鲁木齐 830011)
0 引 言
方面级情感分析(aspect-based sentiment analysis,ABSA)的任务是对文本中一个或者多个对象进行情感极性的分类,为对象打上情感标签。给定一段文本sentence={W1,W2,W3,…,Wn}, 文本中包含s个方面词(aspect),目标是预测s个方面词的情感极性。例如:I like apples,but I don’t like pears。其中apples和pears为方面词,其情感极性分别为正向和负向,而端到端的ABSA就是将方面词和情感极性同时抽取出来。
端到端ABSA任务中,样本的标签类别存在不平衡的问题。方面词标签在总标签数中所占的比例较小,而非方面词占据了绝大多数,这样会导致模型在训练的过程中过多的学习非方面词标签,使得非方面词标签的梯度权重过大。从损失函数的角度来说,以往常用的方法是使用交叉熵损失,交叉熵损失函数不能有效降低易分类类别标签的权重,而Focal损失虽然可以通过增加难分样本的权重来缓解标签类别不平衡,但一些诸如错标、漏标等潜在的离群点的样本标签仍然会对实验结果造成影响。因此,为了缓解端到端ABSA类别标签不平衡的问题,从梯度的角度出发是一个比较好的策略。本文提出使用梯度均衡损失来缓解此类问题,从梯度的角度对比不同的损失函数所带来的影响,并探究使用一种通过指数式递减加权的移动平均的方法,用来估计变量局部的均值,进一步从梯度的角度对实验结果进行探究。
1 相关工作
早期的ABSA以情感词典或是统计机器学习的方法[1]为主,这些方法不能很好地提取句子的语义信息,因而使得句子的分类效果不佳。近几年常用的模型以深度学习方法为主,如基于RNN[2,3]的方法,基于Transformer[4]的方法以及基于Bert[5]的方法等。
ABSA任务中的标签主要有两种标注方式,一种是联合标记方式(Pipline/Joint)[6],一种是统一标记(Collapsed)[7,8]方式。联合标记方式是将方面词和情感极性联合建模,如先识别方面属性:“B”、“I”、“O”,再识别情感级性:“POS”、“NEG”、“NEG”等,非方面词则识别为“O”。统一标记方式是将方面词以及情感极性同时抽取出来,如“B-NEG”和“I-POS”。基于联合标记的方式需要先抽取方词再对方面词进行情感极性分类,早期常用Pipline的方式来进行研究,但是这种方式很容易产生误差传播,在近几年的学术界中研究较少,本文的研究的方法是基于Collapsed的方式,标签标记方式样例见表1。

表1 标签标记方式
其中“B”即为begin表示一个方面词的开头,“I”即为 inside表示方面词中的一部分,“O”即为outside表示非方面词,“POS”、“NEU”、“NEG”分别表示积极、中性、消极的情感极性,在现有的ABSA标注数据集中,常出现类别不平衡的情况,即标签“O”所占的比重远大于 “POS”、“NEU”、“NEG”等标签,本文对4个标准数据集Laptop、Rest14、Rest15、Rest16做了统计,标签分布统计如图1所示。

图1 标签分布统计
从图中可以看出,标签“O”在所有标签中占的比重远大于标签“POS”、“NEU”、“NEG”,这样容易导致模型在训练的时候,对易学习的标签“O”分配较高的权重,进而对全局的梯度造成影响,在过去的研究中缓解梯度分配不均常用的方法为Focal损失[9],它最早是用于解决目标检测任务中类别标签不平衡的问题,实验结果表明在不影响模型速度的情况下,能将one-stage detector的准确率,达到two-stage detector的效果。Focal损失是在交叉熵的基础上进行修改的,可以减少易分样本的权重,使得模型更加聚焦于难分类样本。
后来B Li等[10]对目标检测任务中类别标签不平衡问题做了更深一步的研究,提出了梯度均衡损失(gradient harmonizing mechanism loss,GHM-Loss)并且实验结果要优于使用Focal损失的结果。Focal损失只考虑了易分类样本的权重,未考虑离群点等样本的权重,而GHM-Loss考虑了离群点样本,并且可以对离群点样本进行抑制从而提升模型的泛化能力以及鲁棒性。离群点样本指的是在样本标签标记中可能出现的错标、漏标或者是潜在噪声样本,这样的样本会对实验结果造成影响。在基于联合标记方式(Joint)的ABSA方法中,H Luo等[11]将方面属性抽取(aspect terms extraction,ATE)和方面情感分类(aspect sentiment classification,ASC)任务联合建模,提出了梯度协调和级联标记模型,引入了梯度均衡损失来缓解类别标签不平衡,并达到了显著效果。
对于统一标记的ABSA模型中此类问题的研究较少,本文从中受到启发,基于BERT端到端的ABSA模型,引入了梯度均衡机制,并做了多组对比实验,使用交叉熵损失、Focal损失、以及梯度均衡损失在多个数据集中进行对比实验。本文还在此基础上探究了指数滑动平均(exponential moving average,EMA)对实验结果的影响,EMA可用来缓解因离群点样本集中在同一个小批量数据而产生噪声的影响,并且可以控制前面的数据对滑动窗口内值的影响,从而使得模型训练更稳定,鲁棒性更强。
2 模型和方法
2.1 Focal 损失
对于分类问题损失函数的定义,以往常用的方法是使用交叉熵损失,公式如下
CELoss=-∑Ni=1yi*log(pi)=-log(pn)
(1)
其中,pn为第n类输出对应的概率值,y为样本标签的one-hot向量表示,Tsung-Yi Lin等为缓解目标检测任务中类别标签不平衡的问题,以提升one-stage detector的准确率使其达到two-stage detector的效果,提出了Foca损失。在目标检测样本中,负样本数量占总样本的数量很大,因此梯度总和的占比很大,并且大多样本是易分样本。改进后的交叉熵损失即为Focal损失,简单来说它通过降低易分类别样本的权重,增加难分样本的权重来缓解标签类别不平衡。其公式如下
FCLoss=-αn(1-pn)λlog(pn)
(2)
其中,αn表示第n个类别样本的权重,pn表示输出第n类的概率值,(1-pn)λ是用来调整难易分类样本所占的比例,此方法降低了易学习样本类别标签的权重,较好地缓解了类别标签不平衡。
2.2 梯度均衡机制(gradient harmonizing mechanism)
B Li等提出了梯度均衡机制(gradient harmonizing mechanism,GHM),其目的是为进一步解决类别标签不平衡的问题,它在目标检测任务中实验结果中优于Focal损失,其与Focal损失最主要的区别是Focal损失只考虑了降低易学习样本的权重,没考虑到潜在离群点样本的标签权重。而梯度均衡机制则考虑到了离群点标签,从梯度分布的角度将梯度进行均衡,并且有效缓解了样本中可能出现因离群点而引起的噪声的问题。定义x为模型的输出,则有
p=softmax(x)
(3)
那么x的梯度将定义为
g=∂CELoss∂x=|p-pt|
(4)
其中,pt表示真实标签的类别,将g称为梯度范数,其值可以表示一个样本分类难易程度的属性,在本文研究的数据集中,标签的分布极不平衡,标签“O”相较于其它标签占了总类别标签中的大多数,通常在这种情况下,标签“O”所占的比重过大会对全局梯度产生较大的影响,另外对于某些潜在的离群点标签来说,如果模型过多的学习这些离群点标签,也会对实验结果造成影响。
2.3 梯度密度(gradient density)
梯度密度是为了缓解模型训练过程中梯度分布不协调的问题,将梯度密度函数定义为
d(g)=1lε(g)∑Nk=1δε(gk,g)
(5)
其中,gk表示第k个样本的梯度范数,且当g-ε2≤gk θ=d(gi)Tl (6) 梯度调和参数定义为 βi=1θ (7) 其中,Tl为样本的总数和,当样本梯度为均匀分布的时候βi=1, 当样本梯度较大的时候,将会对权重进行向下加权处理。 梯度均衡损失可被定义为 GHLoss=1N∑Ni=1βiCELoss=∑Ni=1CELossd(gi) (8) 其中,N为样本的数量,其中g=|p-pt|, 表示样本的梯度范数,pt表示真实的样本类别标签,p为经过softmax(x) 操作后模型预测的概率值。定义单位区域长度ε,M=1ε为分成区域的区间数。定义γi为单元区域,γi=[(i-1)ε,iε], 其中i为第i个单元区域的索引。定义Ri为位于第i个单元区域的样本数量,定义 ind(g)=ks.t.(k-1)ε≤g (9) ind(g) 为g所在单元区域的索引。此梯度密度的近似为 d^(g)=Rind(g)ε=MRind(g) (10) 其中,d^(g) 表示统一单元区域内的样本具有相同的梯度密度。 在定义的单位区域内的,可能会有多个离群点样本数据,这样容易产生噪声并对实验结果造成影响,因此本文使用指数滑动平均的方法(exponential moving average,EMA)来缓解这个问题,这是一种通过指数式递减加权的移动平均的方法,可以用来估计变量局部的均值。定义移动平均数 Vti=(1-α)Rti+αVt-1i (11) 其中,α为动量系数(momentum parameter),Rti表示第i个单元区域下的样本第t次迭代时刻的样本数。这样可以使用Vi代替Ri来平滑梯度密度,降低极端值的对实验结果的影响,可再次定义梯度密度为 d^(g)=Vind(g)ε=MVind(g) (12) 针对模型结构,本文采用了基于BERT的端到端ABSA模型作为本文的baseline模型进行研究,模型结构如图2所示,输入为训练文本,经BERT层,将输出的隐藏层向量输入ABSA分类层中,最后输出情感分类结果。其中在ABSA分类层中本文使用了多个模型(GRU、Transformer、SAN)进行对比实验,实验部分将在下一个模块进行讨论。 图2 端到端的ABSA模型结构 本文采用4个标准ABSA数据集,laptop、rest14、rest15、rest16来源于SemEval challenges,在数据集中,统计了不同数据集中训练集、验证集和测试集,以及总样本的语料句子数,见表2。 表2 样本数统计 本文采用精确率(Precision)、召回率(Recall)和F1分数(F1-score)作为评价指标来评估方法的优劣,各项指标的计算公式为 Precision=TPTP+FP (13) Recall=TPTP+FN (14) F1=(2×Precision×Recall)Precision+Recall (15) Precision表示预测为正例样本中实际为正例的样本所占的比例,Recall表示实际为正例的样本中预测为正例的样本在所占的比例,其中F1值为Precision和Recall的调和均值。 首先本文使用BERT预训练语言模型为“bert-base-uncased”模型,transformer层为12层,且隐藏层维度为768维。在参数设置中,优化器本文使用AdamW,初始学习率设为2e-5,batchsize设置为32,实验的环境参数见表3。 表3 实验环境配置 本文基于BERT的端到端ABSA模型,将其作为baseline模型,探究了引入Focal损失以及梯度均衡机制对实验结果带来的影响,并且在ABSA分类层中使用了线性模型、基于RNN的模型(GRU)、基于自注意力的模型(SAN)以及基于transformer(TFM)的模型方法。除此之外还对比了近几年的ABSA论文中的结果,模型介绍如下: DREGCN[12]提出了一种使用基于多任务学习的新型依存句法知识增强交互体系结构,使模型能够充分利用句法知识来进行分类,并且设计了一个依赖关系嵌入图网络(DREGCN)。 IMN[13]提出了一种交互式多任务学习网络,引入了一种消息传递机制,信息可通过一组共享的潜在变量迭代地传递给不同任务。 DOER[14]提出了一种交叉共享RNN框架,通过使用双循环神经网络来学习各任务语义表征,并使用交叉共享单元来考虑任务之间的关系。 DHGNN[15]提出了一种动态异构图的方法,为两个子任务进行联合建模。 GRU Gate Recurrent Unit是循环神经网络(RNN)的一种,将其作为本文研究中ABSA分类层模型之一,它通过使用门控机制可以有效缓解长期记忆问题以及梯度消失问题。 SAN由自注意力(self-attention)以及残差连接组成,是自注意力网络的一种变体结构,将其作为本文研究中的ABSA分类层模型之一。 TFM使用Transformer Encoder结构作为本文研究中的ABSA分类层模型之一。 在实验中本文将交叉熵损失、Focal损失、梯度均衡损失分别用-CEL、-FL以及-GHML表示,在实验数据中DHGNN、DORE、IMN、DREGC的实验结果以及Laptop数据集中的部分实验结果均来自原始论文的实验数据,其中P、R、F1分别表示精确率、召回率和F1分数,各模型实验对比见表4。 表4 各模型实验对比/% 从实验结果中,可以看出Focal损失和梯度均衡损失都对模型的性能有所提升,并且都可缓解类别标签不平衡的问题,通过多项评价指标可以得出本文所提出的方法在实验结果中优于许多强baseline模型,并且在基于BERT的端到端ABSA模型中,F1分数指标提升较为显著。对于最优结果,Laptop数据集中Bert+Linear-GHL的F1分数相较于baseline增长了3.14%,在Rest14数据集中Bert+TFM-GHL的F1分数相较于baseline增长了1.43%,Rest15数据集中Bert+GRU-GHL的F1分数相较于baseline增长了1.22%,Rest16数据集中Bert+TFM-GHL的F1分数相较于baseline增长了1.96%,这说明本文所提出的方法对于优化提升端到端的ABSA模型的性能有着重要的意义。 为直观分析本文的实验较于基线模型的影响,进行了案例分析,对比了基线模型加和入梯度均衡机制的模型前后对于分类结果的影响,典型案例研究见表5。 表5 典型案例研究 本文研究了多个例子进行案例分析研究,表5为展示的几个典型的例子,其中(1)、(2)所示的案例为最为典型,模型无法正确识别方面词信息,将“B-POS”识别成了“O”,加入梯度均衡机制以后可以有所改善;(3)为样本标签标记有歧义的文本语句,虽基线识别正确,将这段话中lunch和buffet识别为负面(“NEG”)的情感,但是句子的本意应偏向于积极的情感极性,加入梯度均衡机制以后,识别结果正确;(4)中为情感识别错误的情况,梯度均衡机制也可以较好地改善此类问题。 每个训练样本最适合的分割区间数M都不相同,为探究划分区间数量对实验结果带来的影响,本文设置不同的区间数M,并进行了实验,以Bert+Linear模型为例,本文分别将ε设置为5,10,15,20,25,30并使用F1分数(F1-score)评价指标来对实验结果进行探究,F1分数随区域数M变化如图3所示。 图3 F1分数随区域数M的变化 不同M值下的实验结果见表6。 表6 不同M值下实验的F1分数 从实验结果中我那可以看出区间数M的设置对实验结果有略微影响,并且每个数据集中M的最优值都不相同,M的值代表了划分梯度范数函数值的区间数,单位区间范围就是ε,在M的设置中,随着M的增加,分割的区间数增加,可能会导致梯度密度统计不准确。因此需要设置一个合适的值来选定合适的M,在4个数据集Laptop,Rest14,Rest15,Rest16的实验中,实验分别在M为15,10,15,25的时候达到最优,其F1分数分别达到0.6357、0.7343、0.6229、0.6889。 除此之外本文还探究了加入EMA前后对比实验结果,在相同参数下F1分数的实验结果对比如图4所示。 图4 加入EMA前后对比F1分数 实验结果表明加入EMA确实可以提升模型的性能,在4个数据集中进行了实验,F1分数分别提升了0.69%、1.7%、0.26%、0.71%,EMA把每次梯度下降更新后的权重的值和前一次更新的值关联了起来,使得更新后的值受限于前面更新的值,因此加入EMA确实可以有效降低潜在极端值对实验结果的影响,并且可以使得模型的性能得到提升。 本文提出使用梯度均衡机制来缓解端到端方面级情感分类中类别标签不平衡的问题。并在多个数据集中进行了多组实验,探究了指数滑动平均对梯度造成的影响,在4个标准数据集中进行实验,实验结果表明本文提出的方法相比baseline方法有了较为明显的提升。但是本实验对于梯度区间数的选取策略还不够完善。下一步工作,将继续探究缓解类别标签不平衡的其它方法以及细化区间数的选取策略,进一步提高模型的分类性能。2.4 梯度均衡损失(gradient harmonizing mechanism loss)
2.5 指数滑动平均(exponential moving average,EMA)
2.6 模型基线
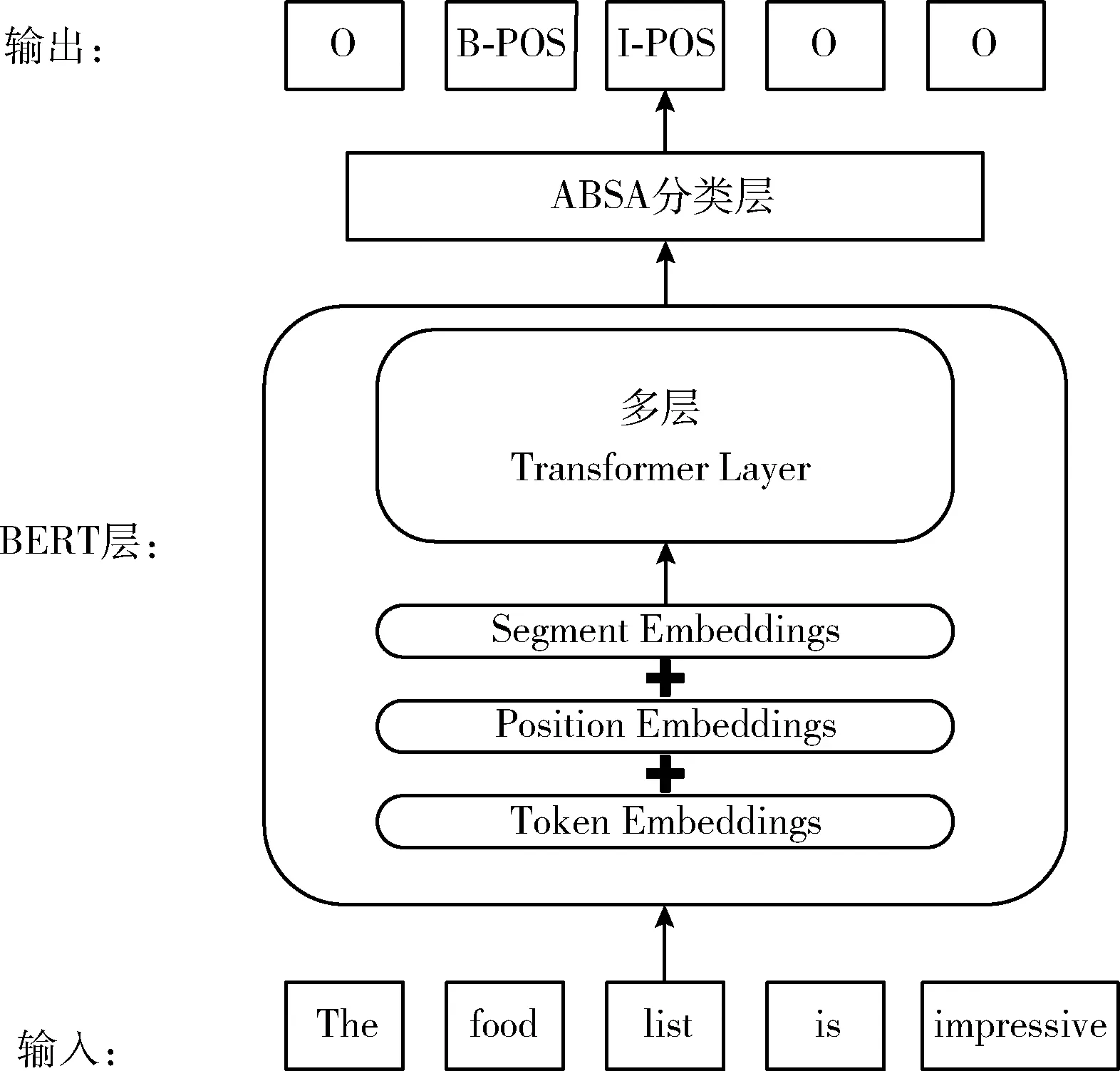
3 实 验
3.1 实验数据集及评价指标

3.2 参数设置

3.3 对比模型及方法
3.4 实验结果及分析


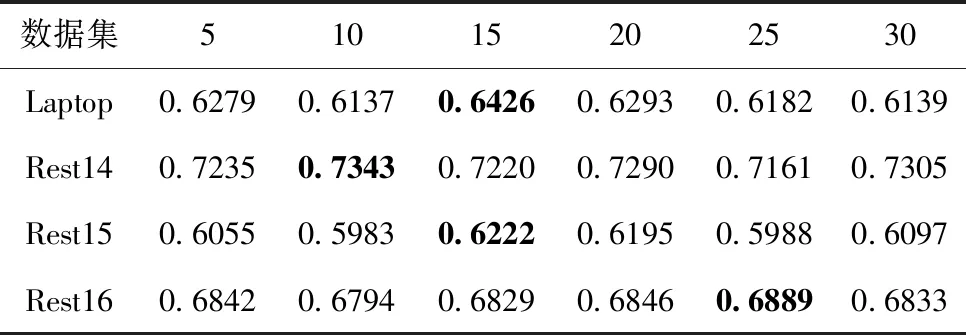
3.5 参数设置对实验结果的影响

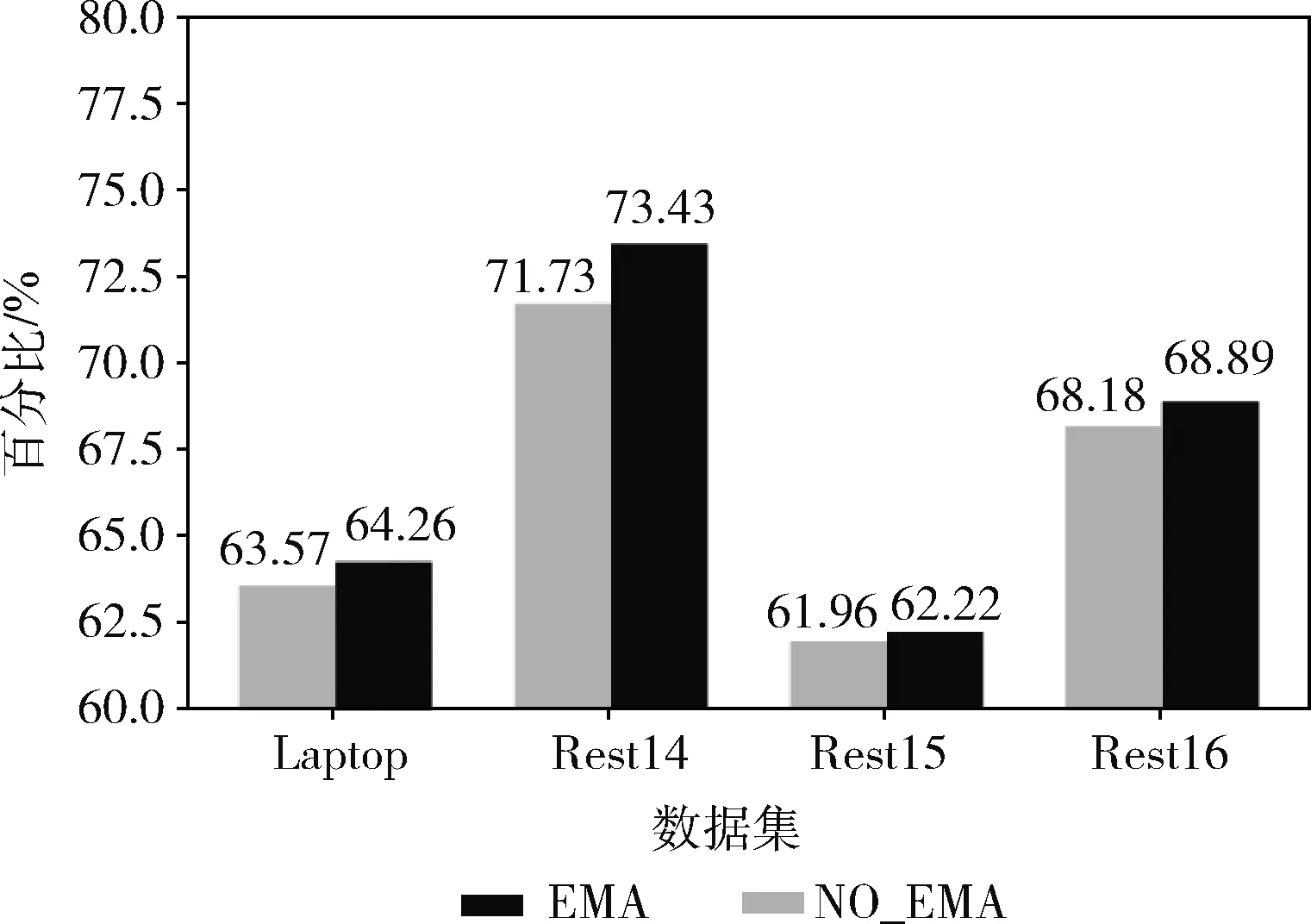
4 结束语
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38应用数学(2020年2期)2020-06-24 06:02:50数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52车迷(2018年11期)2018-08-30 03:20:32海峡姐妹(2018年3期)2018-05-09 08:21:02公民与法治(2016年10期)2016-05-17 04:12:58新校长(2016年8期)2016-01-10 06:43:59计算机工程(2015年8期)2015-07-03 12:20:27商事法论集(2014年1期)2014-06-27 01:20:42中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
