
基于数据生命周期的学术图书馆数据可重复性支持服务
2023-09-13 11:24:34孔祥辉王乙竹
新世纪图书馆 2023年7期
关键词:数据管理
孔祥辉?王乙竹
摘 要 当前可重复性危机日益严重,已经对科学研究事业的健康发展构成重大挑战。学术图书馆有责任和义务参与到化解这场危机的进程中。论文基于数据生命周期的整体视角,深入分析危机形成的数据因素,以可重复性为价值导向并结合学术图书馆服务优势,提出对应的数据支持服务建设思路与具体实施策略,包括数据预公开与规划服务、高质量数据采集服务、元数据开发与咨询服务、统计培训与协作服务等。
关键词 学术图书馆;数据生命周期;可重复性危机;数据管理
分类号G251;G258.6
DOI 10.16810/j.cnki.1672-514X.2023.07.010
Academic Librarys Data Reproducibility of Service Based on Data Life Cycle
Kong Xianghui, Wang Yizhu
Abstract The current reproducibility crisis is becoming increasingly severe, which has posed significant challenges to the healthy development of scientific research. Academic libraries have the responsibility and obligation to participate in the process of resolving this crisis. Based on the overall perspective of the data life cycle, this paper deeply analyzes the data factors that caused the crisis, takes reproducibility as the value orientation and combines the advantages of academic library services, and puts forward corresponding data support service construction ideas and specific implementation strategies, including data pre-disclosure and planning services, high-quality data collection services, metadata development and consulting services, statistical training and collaboration services.
Keywords Academic libraries. Data life cycle. Reproducibility crisis. Data management.
0 引言
可重復性是科学界的常用术语。根据美国国家科学基金会(NSF)发布的《科学中的可重复性与可复制性》(Reproducibility and Replicability in Science)研究共识报告[1]中的定义,它是指使用与原始研究相同的数据代码、程序、方法、步骤或分析条件获得一致的结果。伴随着数据密集型、数据驱动型科研范式的确立和兴起,可重复性已愈发成为衡量科研成果质量的重要标尺。然而目前科研领域正逐步陷入到可重复性危机陷阱之中,很多已经发表的论文成果都经受不起重现的考验。顶级学术期刊《Nature》的一项调查显示[2],科研人员有超过半数无法重现自己的研究结果,有70%无法重现他人的研究。这种情况不仅降低了自身对于研究工作有效性的信心,还严重威胁到公众对科学的信任感。如何提高研究成果的可重复性,从根本上防范并化解危机已成为各类科研主体及相关利益方所共同关心的重大问题。学术图书馆是科研交流创新体系的重要一环,有必要及时审时度势把握科研发展的脉搏,厘清当前所面临的危机态势,发挥自身的服务价值与优势来协助科研界推进危机的解决。
1 研究综述
可重复危机问题进入公众视野并引起广泛关注,是由John Ioannidis在2005年所发表的一篇先导性文章所致,他声称高达90%的研究结果都是错误的[3]。此后针对该主题的研究焦点集中在以下三个方面:(1)对危机的本身认识及争论。以Daniele Fanelli[4]等为代表的少数学者认为,很多研究成果确实存在捏造、伪造、有偏见性、有选择性和不可复制等亟待解决的问题,但并不表明它们会破坏整个科学事业。“危机”一词的表述是错误的,应该用时代所赋予的新机遇和新挑战才更准确和令人信服。但无论是从机构层面,如美国开放科学中心(OSC)开展的大规模复制项目[5],还是学者个体层面开展的小范围重复性评估研究,都发现社会科学、行为科学、心理学、教育学、医学等众多学科领域已发表成果存在重现率偏低情况,并且已经引发了很多直接或潜在的负面问题。因此,大部分学者都认同危机的客观存在并已达到刻不容缓的地步。(2)危机起因的多维度分析。主要包括缺乏原始数据共享,可疑研究操作、P值滥用、选择性报告、糟糕实验设计、自由度失控、样本不足、技术偏见、数据可用性差、低效力研究、无法管理复杂数据集、认知偏差、报告不佳、出版偏倚等。(3)对策研究。危机形成的原因复杂深刻,涉及面广泛,学者们从技术、机制、方法、环境等多元化角度探寻化解危机的策略,代表成果有构建区块链技术方案、改进学术激励机制、引入人工智能成果评估技术、改进期刊研究指南、完善同行评审制度、改进统计方法、加强科学严谨性与可重复性教育等。
为科研服务是学术图书馆的中心任务,充分运用服务职能助力提升研究可重复性以解决危机成为了天然的职责和使命。Franklin Sayre[6]在回顾透明度和开放性促进(TOP)指南、美国统计协会(ASA)可重复性指南等内容时指出,学术图书馆员应凭借在文献检索、文献评估、系统综述、学术交流、数据管理及对数据密集型研究方法支持等方面的丰富经验,在推动研究更具可重复性方面发挥重要作用。Stodden等[7]强调图书馆可通过协助研究人员制定完善的数据管理计划、优化数据存档方案等手段,来支持其实现向开放与可重复研究文化的转变。然而目前研究成果数量有限,内容上仍处于服务思路构想的初级阶段,尚未建立系统的理论框架,也没有形成可执行的具体实施策略为实践提供参考指导。
在数据密集型科研范式时代,数据成为现代科学发现的核心要素。研究成果能否经受住重复性检验取决于数据的质量。学术图书馆必须坚持用数据视野来透视可重复危机的本质;同时由于数据具有完整的生命周期属性,还必须以系统化思维和方法,结合文献内容分析,利用现有的生命周期模型框架全面审视危机背后的数据因素,并立足于数据管理服务职能手段,通过重组优化、重点布局,形成一个崭新的、完整的服务策略体系。
2 科研数据生命周期
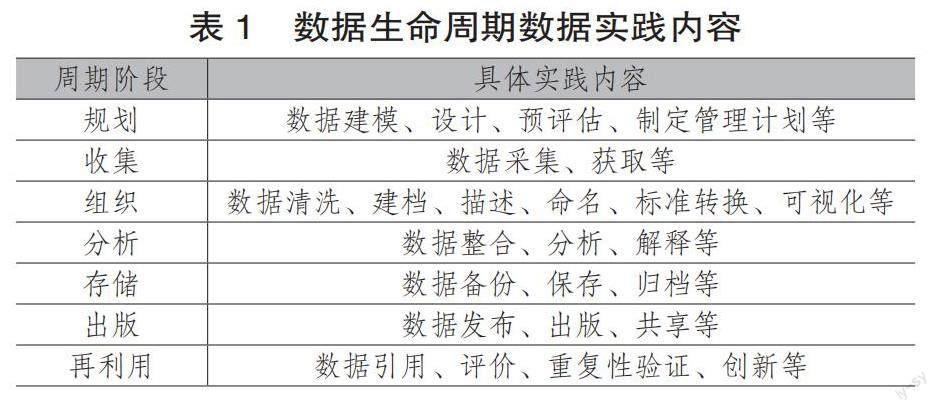
数据实践活动与科学研究工作密切相关,渗透进科研活动的各个环节,科研活动经过选题、计划、立项、实施、出版、结题等一系列活动构成了完整周期。因此,科研数据无论来自于哪种学科、以何种格式或载体存在,也都会体现出一定的循环过程,同样具有生命周期的普遍特性。目前学界已提出多个理论模型对数据的生命周期进行解释,如Data ONE研究数据生命周期模型、英国数据管理中心DDC模型、英国数据档案馆UKDA模型、美国地质调查局USGS模型、ICPSR社会科学数据存档生命周期模型等。通过对比整理这些模型核心要素,本文将科研数据生命周期划分为数据规划、数据收集、数据组织、数据分析、数据存储、数据出版、数据再利用7个阶段。各阶段数据实践内容如表1所示。
3 基于数据生命周期视角下的可重复危机数据因素
数据周期模型体现了数据实践活动整体逻辑结构、阶段内容与内在价值联系。可重复性是数据基于模型运行下的综合作用结果,可以说贯穿于整个数据生命周期过程之中,在不同阶段的不当实践行为或管理失位都会诱发潜在风险;通过对现有文献成果有关危机形成的各种因素的表述分析来看,其生成机制背后都有着数据因素推动或者体现出高度关联性。
3.1 缺乏数据规划与监管
科研成果不可重复的直接原因是数据本身存在的缺失、混乱、虚假、错误等一系列问题,而未能对数据实践全过程实施有效的计划和监管,维护数据应有的科学性、完整性和真实性,则是这些表象原因背后的深层原因。在尚无明确的规划指引和相应的制度监督约束背景下,科研人员在数据实践进程中会明显缺乏预判性和前瞻性,研究自由度变得很大甚至失去控制。研究自由度是指从生成假设、研究设计、分析处理数据和报告结果等研究过程中所體现的灵活性,表现为灵活择取方法或者临时决策行为[8]。通常情况下,由于缺乏精准定义的理论或者经验证据,这些行为具备一定合理性,但同时也会带来大量的随机和不确定性,可能会影响数据的显著性检验结果。例如,研究人员为了追求可供发表的阳性结果,会巧妙地利用自由度进行选择性报告(selective reporting)、P值篡改(p-hacking)、已知结果后提出假设(HARKing)等各类可疑研究操作,夸大统计学效能以产生自己想要的预期结果,最终造成结果呈现假阳性的隐患大幅增加,其结论失真失实而难以复制。有研究估计,因滥用研究自由度而导致研究成果的假阳性率高达61%[9]。
3.2 数据收集方式不足
数据收集是数据生命周期的核心阶段,即运用各种方法和渠道对研究所需的数据进行采集获取,为数据分析奠定前提。数据收集方式决定数据质量。而数据采样则是众多学科领域数据收集的最常见形式。在同等条件下数据样本量越大,越更能代表总体,扩大了可能的数据范围从而限制异常值或极端值的影响,提高统计效力和统计结果的精确性。
然而,多数学科研究普遍存在样本量不足问题。在数据采样模式上,研究人员更多采用小样本而非大样本进行研究,或从多个小样本挑选阳性结果进行报告,直接损害了其分析结果作为证据的有效性。许多发现尽管具有统计学上的显著意义,但其真实性存疑。此外,研究人员普遍缺乏盲法运用、样本量估算和使用方便样本等问题,数据收集质量很难得到有效保证,容易造成误导性的结论,进而影响研究潜在的可重复性。
3.3 数据揭示力度不够
数据组织阶段涉及活动广泛,决定了数据分析、存储、共享等活动效率。而科研活动日益复杂化、系统化,其数据实践条件的复杂性,如异构多源的原始实验数据、测量参数、实验设置、参与人员、软件参数、方法、步骤和结果等信息,只有通过全面有效的组织揭示帮助科研人员予以全面把握,才有可能保证结果的可重现。
元数据是目前数据组织的最重要工具。创建元数据是确保数据公开、透明、可用和揭示完整研究过程的有力手段,对于重现已发表的结果非常重要。遗憾的是,当前科研文献中普遍存在各类元数据不足的问题。一项针对不同学科的科学家调研显示[10],75%的受访者认为元数据可获取性较差严重阻碍了他们尝试重现他人结果的信心,而能够获得描述步骤型元数据仅有36%、设置型为38%、方法型为32%。同时,在创建元数据情况方面并不理想。为数据集增添合适的元数据或描述文档以实现长期存储与监护,会额外增加科研人员的时间成本和精力,因此只有在完成既定科研任务或成果产出时才会得到重视[11];而已创建的元数据质量也令人堪忧,在数据收集策略、处理来源,分析方法等细节普遍缺乏详细描述,数据可用性差,不能供他人充分理解并进行研究有效性评估。
3.4 数据分析方法误用
数据分析是指为了提取有用信息和形成结论,用适当的统计分析方法对数据加以详细分析概括总结的过程。分析结果的可靠性取决于统计分析方法的正确选择使用和对结果的合理解释,而实现这两点必须有一定统计学知识为基础。对于非统计学专业或基础薄弱的科研人员在缺失教育的情况下极容易出现概念、原理理解上的偏差,导致p值滥用、不恰当地处理异常值、误用非参数和参数检验、忽视统计独立性等方法误用问题[12],而这种情况却在众多学科中普遍存在。方法误用的后果就是导致统计功效低下,p值丧失应有的统计学意义,分析结果偏离客观事实,得出的研究结论不科学,后人能够成功重复出来的可能性也就变得很低。
3.5 数据存储基础薄弱
数据存储是以存储库为基础,通过保存、归档等形式实现数据的长期保存和利用的活动,能够有效维护数据的安全性和完整性,提高数据可利用、可发现和可识别属性,为数据公开共享和可重复利用创造前提。技术进步促使科研领域生成愈发广泛、复杂的数据集,如果不能以标准化、规模化的方式对数据进行存储,就容易导致数据缺失、可读性差等问题,降低数据共享和再利用水平。
目前,科研领域数据存储基础较为薄弱。一方面是可供公开访问的数据存储率较低。有学者对50种科学领域发表在顶级期刊的论文进行分析,发现其中只有9%的作者将完整的论文原始数据实现在线存储[13]。即使很多顶级期刊制定了强制的数据共享政策,但依然无法改善这一现状。另一方面数据存储意愿低。即使多数研究机构或主体认可数据存储和共享对于研究的价值,但在缺乏存储经验、基础知识、产权保护,以及重视便利性忽略合理性的观念驱使下,将数据保留在个人存储设备不公开共享始终是科研人员的首选。
3.6 数据出版存在弊病
数据出版是数据实现共享的主要形式。在出版物和报告中披露数据分析过程、结果、各类决策和意图等详细信息,帮助后续研究者深入了解以便进行重复实验。而现有的学术出版物普遍通过发布最终的代表性数字或数据集快照来展现结果,既没有充分揭示如何生成这些数字和快照的原始数据,也缺乏支持重复性验证的关键信息。在某些竞争激烈的学科领域,数据甚至会被故意省略、模糊描述。即便很多研究人员或许从未伪造过数据,但在“不发表即灭亡”的出版压力下,也选择省略了不支持研究假设的结果,或者拒绝披露负面数据。因此,当前数据出版方式与内容的缺陷,使数据不适合重用、验证和复制。
3.7 可重复验证研究匮乏
可重复验证研究就是对数据进行的重复性验证分析,使其他研究人员能够以现有研究为基础提高方法和结果的可验证性 ,在科学研究中形成自我校正的良性机制。对于提高自身及其同行研究成果的严谨性、可重复性和透明度至关重要。
可重复验证研究的专业强度、技术难度、时间成本较高。检验一项他人研究成果的可重复性不仅要考虑原研究中所使用的分析工具、环境等是否变化因素,还需要雄厚的专业知识基础才能理解原研究中的数据、数学模型和统计技术,因此这些分析对于那些知识有限的人来说很难实现。大多数科研人员对此类研究只能望其项背;而且现有科研文化导向难以支持其实现普及化。当今科研体系鼓励创新成果的快速发表,只有新发现才会获得更多的关注与奖励,而负面结果(例如未发现显著相关性)则受到排斥。这种局面迫使研究人员将自身研究成果的重复验证变成一种投机行为,沦为发表论文的手段而非检验科学的准则,即只有发现不符合预期的结果才对数据自查自审,得到预期结果(更多的是假阳性)则立即停止[14],无法保证研究成果客观、准确、可靠。
4 基于数据生命周期的可重复性危机数据支持服务
4.1 指导思路
学术图书馆虽不是科研项目的主导者,但却是科研数据的天然中介方与监管者,凭借信息组织技术、专业人才、基础设施、数据资源等优势,提供完善的科研数据管理与服务。通过协调数据管理中心、实验室、科研管理部门、学术期刊、数据商等相关利益方促成广泛合作,建立以学术图书馆为中心的服务共同体,利用资源建设、宣传推广,完善设施,交流协作、用户教育等手段,对各阶段的数据问题予以精准击破,最终形成以提高科研可重复性为根本价值导向、覆盖全周期的数据支持服务体系。
4.2 具体策略
4.2.1 数据预公开与规划服务
可重复性始于规划,而在科研項目启动前编写数据管理计划(DMP)则有助于将规划从构想转变为具体方案,即在开展数据实践之前将数据采集规则、分析方法、统计指标、相关测试、数据存储等细节,预先进行科学地论证分析和记录,探索所有潜在的风险和后果,使数据实践具备可预见性。
学术图书馆应以建立以DMP为核心的数据规划服务。(1)协助科研人员加强DMP内容建设与质量控制。加大资源推广力度,充分发挥各类学科的DMP标准模板、研究指南、预研究清单、政策文件等资源的指导性作用,帮助科研人员建立标准化与规范化的DMP,明确从数据设计、执行和解释等各环节操作所需的量化指标和具体要求,并以此为基准开展后续的数据实践,确保在真实、可控的轨道上进行,减少数据欺诈、伪造等行为以便获得可重复结果。(2)积极开展预注册服务,推动DMP预公开和透明化。数据管理规划存在霍桑效应,即研究人员在意识到他们的研究方案将被公众审查时,会主动加强对研究方案的自我审查力度[15]。如果能实现数据规划的公开透明,将有助于研究人员把注意力集中到方法改良和确保成果真实有效上来。预注册是实现这一目标的有效途径,它促使科研人员在开始科研项目启动之前,在平台提前注册并公开研究设计,数据假设、DMP等内容,利用平台的公共监督功能,最大程度减少研究自由度、区分假设探索性研究与假设检验研究,具备科研过程监督的价值属性。因此学术图书馆应积极引入技术平台,开展引导和咨询服务,帮助科研人员增强预注册的价值感知、积极践行预注册行为,使数据实践的全过程都能得到有效监督,避免各类可疑的研究操作,有序实现计划预期的客观数据成果。
4.2.2 数据高质量采集服务
学术图书馆应以帮助科研人员最大程度提高数据采样数量和质量,降低低样本量对研究的不利影响为目标,开展数据搜集服务。(1)数据资源获取服务。加大科研数据资源建设,如各类实验、统计、模拟、观察类数据库购买整合力度,拓展第三方数据获取渠道,夯实科研项目所需的数据基础。(2)数据采样协助服务。发挥学术图书馆的学术联络优势,协调各研究团体之间开展合作,克服研究个体在数据搜集过程中的有限性与局限性,建立以图书馆为中心的的分布式协作数据采集网络,为更大规模、更高性能的数据采样创造条件。(3)开展元分析服务。元分析是通过统计方法对大量的相似研究进行量化评价并得出综合性结论的方法[16],不仅有效扩大样本量,提高统计检验力,还可以缩小置信区间的范围,使对总体效应量的估计更加精确。在医学、社会科学、教育科学、心理科学等领域得到普遍应用。图书馆员或学科馆员可凭丰富的文献检索经验介入科研团队,帮助研究人员改善检索策略,使用明确系统的方法,最大限度地减少偏见,产生更可靠的元分析结果,为决策提供信息并创建可重复的研究。(4)方法指南服务。通过学科指南建设提供数据收集方法的专业指导,提高数据采样的规范性和科学性。例如布朗大学学术图书馆就生物医学领域的数据、图像、定量免疫印迹等采集方法进行汇总并提供资源引荐。
4.2.3 元数据开发与咨询服务
在数据组织阶段,必须发挥元数据的重现功能,充分揭示数据要素和研究过程,实现研究透明化。为此学术图书馆应做好:(1)元数据模型开发与应用服务。通过加强对外合作,以实现可重复需求为中心积极研发并推广全新的科研元数据模型,协助科研人员全方位提高数据可识别程度和解释能力。例如芝加哥大学学术图书馆与分子工程研究所共同开发的再现性科学论文监护与探索系统(Qresp)[17],用以指导研究人员在创建科学论文时,对使用的数据集、脚本、工具和笔记本之间关系的过程进行可视化记录,实现研究数据—元数据,扩展到个人数据文件—密集大数据环境的全方位揭示维度,建立数据与数据来源之间的关系,通过链接将研究中的所有数据信息得以集中,便于输出引用和重复性使用。(2)元数据指导咨询服务。采取开设微课程、微视频、文本指南等多元途径宣讲元数据标准、元数据政策等,提高科研人员元数据构建意识,并在元数据规范化操作规则指引下,正确记录研究流程,揭示上下文信息、有关设备、协议、数据处理或实验室条件的细节,确保科学记录的可靠性并提高研究過程的透明度。同时,积极推广实验室电子笔记本(ELN)、版本控制(Git)等技术工具,以工具为载体实现元数据记录自动化,减少时间成本和精力。
4.2.4 统计培训与协作服务
为夯实研究人员的统计学基础,使数据分析结果的可靠性得到有效保证,学术图书馆可开展:(1)学科统计培训。定期举办短期培训、学术报告或公开演讲,邀请学科资深人士、统计学专家或第三方专业统计咨询机构开展基于学科的统计培训,对本学科研究适用的统计学原理、常用统计方法、统计分析计划、使用规则、常见误区等给予及时指导,积极引领其他学者对该问题的重视及修正。(2)统计协作支持服务。如图书馆要通过多种协作手段介入来满足数据分析过程中的各类需求。重点应包括①技术需求。杜兰大学图书馆注重与校外统计顾问、统计公司的合作,运用来自NC3R的实验设计助理(EDA,Experimental Design Assistant)为研究人员提供统计方法推荐,随机化和盲法支持、样本量计算等服务,助力设计更能产出可靠和可重复结果的稳健实验。②预估需求。如佛蒙特大学图书馆针对本校学生、博士后和科研人员,建立统计分析需求自检清单,要求在数据分析之前进行自我评估,根据评估结果提供统计指标解读、分析结果解释等一系列对应的信息支持,保证统计分析方法使用的正确性。③资源需求。对涉及各学科的统计学相关教材、期刊、会议、报告、数据库等文献资源集中予以整合,建立专题书库或数据库,通过一站式检索及时获得最新最全的统计学指导资源。
4.2.5 立体多维式数据存储服务
实现研究可重复的关键是要确保数据的完整性和开放性,而这依赖于数据存储力度和存储质量。作为数据存储的重要承担机构,学术图书馆应继续创新存储服务,不断提高自身在科研数据存储应有的价值和地位,助力科研界改善数据存储基础薄弱的局面。服务创新的落脚点在:(1)加强各类存储库建设。通过依托机构知识库改造、第三方商业库(如Dryad、Zenodo、Figshare、protocols.io等)、开源数据存储平台(如开放科学框架OSF)引入以及自筹自建的方式健全数据存储体系,协助科研人员与管理者能够将科研全过程中所涉及到的所有数据,如原始数据集,软件、研究代码、分析脚本、研究协议、实验记录、工作流程、文档注释和元数据等都视为不可或缺的整体,实现全方位、全过程存储,以独立方式保存高度完整,并能通过DOI链接增强与出版物的引用,支持预印本服务器、实验室笔记本、版本控制软件等研究工具的数据共享,支持在开放、协作互动讨论中来提高研究的可重复性。(2)建立学科导航。学术图书馆应积极按照学科门类整合各类存储库资源,提供索引与指南以满足差异化、精细化的学科数据存储需求。如欧美国家的学术图书馆都提供re3data、FAIRsharing等门户信息或搜索引擎,帮助不同专业学科科研人员快速查找和锁定存储范围,实现精准有效的存储。(3)存储标准化引导。加大数据存储标准格式的宣传和解释力度,引导研究人员更多地采用“研究纲要”模式[18],按照一定的逻辑标准且易于识别的方式来储存研究项目的数据材料,使其他研究人员能够进行有效审查、复制和其他扩展研究。
4.2.6 数据独立与开放出版服务
实现可重复就意味着数据应保持其最初的丰富性,不应为了解释某一特定出版物中的发现而降低内容属性[19]。学术图书馆必须坚持以提高数据披露程度和开放性为目的,综合运用多种服务手段积极介入出版进程,优化数据出版环境,提高科研人员数据出版意识。举措有:(1)数据出版资源建设。积极与学术期刊、数据库商展开对话合作,加大数据期刊购入力度,建立研究项目的数据关联出版服务。如爱荷华州立大学图书馆为推动数据独立出版行为,提供专门发表数据论文的期刊资源导航。鼓励科研用户采用数据论文的形式,通过文档描述的数据集,数据库或数据包,描述数据及其收集的情况,与研究文章一起发表。(2)数据出版咨询服务。加强对于学术期刊的数据出版政策、出版指南、可重复性研究指南的追踪与解读,形成咨询报告在论文即将发表、数据出版之际进行推送,协助科研人员清晰地掌握数据出版标准,采取更科学的表述,尽可能排除存在偏差的数据操作,确保数据内容得以真实、有效和可重复利用状态呈现。(3)预印本服务。加强对以预印本为核心的OA学术出版资源揭示力度,如哈佛大学Countway图书馆开辟信息专栏介绍预印本的科普知识问题答疑、政策查询、服务器资源索引等。同时提供预印本-后印本平台托管服务,使研究人员能利用平台对各类科研项目所产出的所有数据成果进行无限制访问,并提高以预印本作为主流出版方式的认可程度,实现公开透明的发布、共享、讨论和评估数据成果,同时提高对于一些负面或无效数据结果的包容性,克服发表偏倚带来的消极影响。
4.2.7 可重复验证全面支持服务
可重复验证研究作为科研进程的有益补充,其价值重要性不言而喻。要真正在广大科研群体之间实现可重复验证研究的普及,使可重复性分析、对无效结果的发掘成为研究项目自我纠正的常态化机制,就需要对其提供全方位服务支持,激发研究动力,促进研究交流、降低研究成本,为研究创造空间、技术、硬件环境。学术图书馆对此可提供:(1)学术交流服务。要真正促使科研主体将可重复这一黄金准则内化成自身科研行为标准,就必须强化对可重复验证研究的宣传力度,促成理念方法的广泛认同。借助空间场域、学科联络、活动组织优势打造可重复验证研究交流平台。定期开展学术研讨,圆桌会议、竞赛交流等活动,如南安普敦大学学术图书馆的ReproducibiliTea 每周例会讨论、莱登大学学术图书馆的可重复黑客马拉松(ReproHack)活动,都极大提高了参与者对此研究的认知和参与程度。(2)信息门户服务。通过汇总各类资源建立研究指南,揭示和报道可重复研究的基本概念、流程方法、最佳实践、工具与资源索引。目前,北美地区很多学术图书馆都开辟了研究门户并且关联培訓、新闻动态信息,以达到推广普及的效果。(3)数据开放许可服务。确保可重复验证研究合法合规开展的前提是必须有明确的数据许可或使用协议作担保。学术图书馆应联合知识产权部门,提供数据开放许可协议的渠道和资源。普林斯顿大学图书馆科研数据管理中心强调在重用现有数据时必须明确获得所有权的许可,并要求了解许可证设置的限制,以便于数据正确使用、减少数据的错误假设导致无效分析。(4)验证平台服务。可重复验证的技术难点在于实现研究数据和环境的可移植性。学术图书馆应加快利用Docker、code ocean、GitHub等可重复性云计算平台构筑一站式在线数据验证和实习空间,方面科研人员将研究产出如代码、数据和计算执行环境、配置信息等打包到一个“胶囊”中并提供DOI,使多方主体都能实现获取并直接开启验证。同时,围绕平台建立配套的教育课程,邀请专业人员定期组织培训教学。
5 结语
解决可重复危机问题刻不容缓。学术图书馆以科研数据管理基础与服务职能优势自然成为应对危机的有力支持者。基于数据生命周期视角解构危机并建立全新服务框架,既为新形势下数据管理服务转型提供新思路,也体现出学术图书馆在顺应变革中推动科研进步的应有之义。
参考文献:
NationalAcademies| R&R.pdf [EB/OL].[2023-03-18].https://nap.nationalacademies.org/resource/25303/R&R.pdf.
BAKER M. 1,500 scientists lift the lid on reproducibility[J]. Nature:International weekly journal of science, 2016, 533(7604): 452-455.
IOANNIDIS J P A. Why most published research findings are false[J]. PLoS medicine, 2005,2(8): 696-701.
FANELLI D. Is science really facing a reproducibility crisis, and do we need it to?[J]. Proceedings of the National Academy of Sciences, 2018, 115(11): 2628-2631.
OSF | Reproducibility Project: Psychology[EB/OL].[2023-03-10].https://osf.io/ezcuj/.
SAYRE F, RIEGELMAN A. The reproducibility crisis and academic libraries[J]. College and Research Libraries, 2018, 79(1): 2-9.
STODDEN V, BORWEIN J, BAILEY D H. Setting the default to reproducible[J]. Computational science research. SIAM News, 2013, 46(5): 4-6.
EPSKAMP S. Reproducibility and replicability in a fast-paced methodological world[J]. Advances in Methods and Practices in Psychological Science, 2019, 2(2): 145-155.
LARAWAY S, SNYCERSKI S, PRADHAN S, et al. An overview of scientific reproducibility: consideration of relevant issues for behavior science/analysis[J]. Perspectives on Behavior Science, 2019, 42: 33-57.
SAMUEL S, K?NIG-RIES B. Understanding experiments and research practices for reproducibility: an exploratory study[J]. PeerJ, 2021, 9: e11140.
黄鑫,邓仲华.国外高校学术图书馆科学数据的元数据服务研究[J].图书与情报,2017(2):84-90.
LINDSEY M L, BOLLI R, CANTY Jr J M, et al. Guidelines for experimental models of myocardial ischemia and infarction[J]. American Journal of Physiology-Heart and Circulatory Physiology, 2018, 314(4): 812-838.
ALSHEIKH-ALI A A, QURESHI W, AL-MALLAH M H, et al. Public availability of published research data in high-impact journals[J]. PLOS ONE, 2011, 6(9): 1-4.
刘佳,霍涌泉,陈文博,等.心理学研究的可重复性“危机”:一些积极应对策略[J].心理學探新,2018,38(1):86-90.
MUNAF? M. Open science and research reproducibility[J]. ecancermedicalscience, 2016, 10.
张力为,彭凡.体育科学如何应对可重复性危机?[J].体育学研究,2021,35(6):1-11.
Scientific reproducibility, data management, and inspiration [EB/OL].[2023-03-03].https://www.lib.uchicago.edu/about/news/scientific-reproducibility-data-management-and-inspiration.
ALSTON J M, RICK J A. A beginners guide to conducting reproducible research[J]. Bulletin of the Ecological Society of America, 2021,102(2): 1-14.
The FAIR data principles[EB/OL].[2022-03-21].https://www.ands.org.au/working-with-data/fairdata.
孔祥辉 锦州医科大学图书馆馆员。 辽宁锦州,121000。
王乙竹 锦州医科大学人文与健康管理学院讲师。辽宁锦州,121000。
(收稿日期:2022-12-29 编校:陈安琪,谢艳秋)
猜你喜欢
中国特种设备安全(2022年5期)2022-08-26 09:18:46
汽车实用技术(2022年10期)2022-06-09 11:33:52
汽车实用技术(2022年5期)2022-04-02 09:36:52
海洋信息技术与应用(2021年2期)2021-11-02 06:59:10
铁道通信信号(2020年4期)2020-09-21 09:15:24
中华建设(2019年8期)2019-09-25 08:26:24
自然资源信息化(2019年3期)2019-03-29 03:17:48
铁道通信信号(2018年4期)2018-06-06 03:31:46
电子测试(2018年6期)2018-05-09 07:31:49
中国交通信息化(2016年8期)2016-06-06 03:56:29
