
基于YOLOv5 算法的施工现场不安全状态智能检测
2023-09-12 05:03李自强任磊刘莉苗作华
土木建筑工程信息技术 2023年3期
李自强 任磊 刘莉 苗作华,3
(1.上海工程技术大学化学化工学院,上海 201620;2.武汉科技大学资源与环境工程学院,武汉 430081;3.冶金矿产资源高效利用与造块湖北省重点实验室,武汉 430081)
引言
本文通过研究近些年来相关企业、事故发生数和事故发生率之间的数量变化关系,发现随着科学技术的发展与进步安全管理水平并未得到提高,事故年发生率稳定在7‰左右,提高相应的安全管理技术和降低事故发生率是当前亟待解决的问题。
关于施工现场工人的管控和风险的管理,国内外许多学者做过类似的研究。姜玥麒等[1]为了控制工人的不安全行为,对建筑工人不安全行为传播性强弱进行了研究。闫高峰[2]利用VR 技术,建立了集动态模拟、监督反馈、安全教育为一体的安全管理体系,为建筑工程安全管理提供新的研究视角。刘文平[3]提出了集成BIM 技术、定位技术和通信技术等对施工安全事故进行预防和预警,借助GPS 和UWB 定位技术对施工现场设定目标进行定位,并提出了适用于施工现场的综合定位方法。郭红领等[4]利用BIM 和RFID 技术构建了定位与安全预警系统模型,用于监测施工现场工人的安全状态,实现了施工现场人员的高效管控。赵一秾、李若熙等[5]改进双流卷积网络行为识别算法,将双流深度卷积神经网络和长短时记忆神经网络相结合,与传统算法相比实现了较高速度的工人异常行为识别,提高了人工监测的效率。赵挺生等[6]以ALARP原则为基础,构建了危险区域等级结构,优化了物联网定位技术,更好地实现了安全管理中安全分级预警。Dong 等[7]将硅胶单点传感器和压力传感器配设到安全帽中,根据传感器之间的信息交互,可判断工人是否佩戴安全帽。Khairullah 等[8]将蓝牙技术与传感器网络相结合对建筑工人进行识别与定位,实现了施工现场的工人位置分析。Kelm 等[9]将RFID 标签和RFID 读写器分别置于个人防护用品和施工现场进出口,用来获取工人出入施工现场信息和监察工人佩戴个人防护用品等情况,提高了工人佩戴个人防护用品的安全意识。胡松劲等[10]在专利中提出将RFID 电子标签置于安全帽设计,用于识别进入危险区域的预警。Barro-Torres 等[11]提出了一种由Zigbee 和RFID 技术开发的新型网络物理系统,以实时监测工人们使用个人防护设备的情况。
以上研究大都是利用跟踪和定位技术来获取工人以及机械的相对位置信息,比较局限于成对出现的实体之间的位置关系,很难全面的对风险进行管理和控制,而且跟踪与定位只能理论上解决或降低施工风险问题,因为工作过程中工人很难做到完全按照安全规范做事佩戴相关的传感器。基于此,许多学者开始将计算机视觉引入土木工程领域。张明媛等[12]基于Tensorflow 框架,利用Faster RCNN 目标识别算法,提出了一种具有高精度、实时性的安全帽检测方法。高寒等[13]利用双模单高斯模型,对危险区域的运动目标进行识别,用来检测危险区域的工人。Han 等[14]通过对人体骨骼的提取来识别人体攀爬过程中的不安全动作。Kolar 等[15]为了提高安全检查效率,利用卷积神经网络对安全护栏进行识别与训练构建了安全护栏检测模型。Fang 等[16]同样使用Faster R-CNN 算法来识别安全帽,实现了不同施工环境下的安全检查,提高了管理效率。王伟等[17]将BIM 技术和机器视觉技术进行结合,利用LEC 评价法构建了安全监管预警模型,并针对工程实例对该预警模型进行了具体应用。王毅恒等[18]利用卷积神经网络的方法,对固定目标进行特征的提取,然后由机器自动识别,解决了人工识别速度慢,易出错等问题。刘晓慧等[19]根据工人的面部及肤色的综合特征信息判定人脸位置信息,再根据头发与安全帽的颜色差异判断工人是否佩戴安全帽。Rubaiyat 等[20]将HOG 与Circle Hough Transform(CHT)进行结合获得了一种工人及安全帽识别的新方法。
本文利用计算机视觉结合倾斜摄影技术,实现了视觉定位,突破了传感器定位的局限性。
1 整体框架描述
1.1 模型描述
基于计算机视觉实现危险区域监控和风险评估模型的构建,需要对施工环境中相关目标进行数据采集,利用目标识别算法对数据进行机器学习的训练,从而实现对施工区域的实时监测。图1 是计算机视觉实现危险区域监控的整体框架。

图1 计算机视觉实现危险区域监控
本小节将从危险区域定义与划分、目标检测算法的选择、数据收集与处理等方面详细介绍运用计算机视觉技术实现施工现场的人员监管及数据输出与实现。
1.2 目标检测模型构建过程
为了获得更加符合实际情况的数据信息,本人求助了多位已经参加工作的同学,为其寻求工程现场图像数据,用来制作本实验的数据集,所以和网上一些通用数据集相比较本实验的数据集更具有实际参考价值,前期训练集的制作也是工作量比较大的一部分内容,需要手动对每张图片的每个目标进行逐个标记。
模型的整个训练过程包括了前期的数据采集及预处理中期的数据存储及训练和最后的模型训练结果的展示,图2 为目标识别具体实现过程。

图2 目标识别实现过程
1.3 危险区域定义与划分
施工现场危险区域是事故发生的环境因素,控制工人在危险区域的停留时间能够预防事故的发生,本文的目标识别模型能够准确识别出施工现场存在的工人、安全帽和施工机械,结合倾斜摄影所提供的场景空间位置信息可以确定工人和危险区域的相对位置信息以及工人和施工机械的相对位置信息,对工人是否出现在危险区域做出及时的判断。表1 是对危险区域的具体划分[21]。

表1 危险区域划分与类型
2 目标识别算法实验探究
2.1 目标检测算法的选择
CNN、Faster R-CNN、YOLO 和SSD 是目前深度学习领域中应用最广泛的四种目标检测算法,前两种属于两阶段算法,其中,Faster R-CNN 的局限性在于速度较慢,并且它使用单个深层特征图进行最终预测,难以检测不同比例的物体,特别是很难检测到小物体。这两个特点使得该算法的速度较慢且容易遗漏。YOLO和SSD 均属于一阶段算法,相对比两阶段算法具有较快的速度。
在以上算法中均能实现动态监测,但由于算法性能的不同,造成了在图像处理速度上存在较大差异。根据施工现场的安全管理的特点,处理和解决问题的及时性是安全问题最重要的一部分,更好地解决时间问题才能更好地做到事故的预防和隐患的及时消除。在以往的研究中可以发现,一阶段检测算法在该方面具有较好的表现能力。本文所研究的区域范围大小不一,检测对象不仅有工人机械还有目标较小的安全帽,YOLO 算法无论在检测速度还是小目标的捕捉方面都具有较好的检测效果,更容易实现本文的研究目标,这也是本文最终选择YOLO 算法的主要原因,YOLOv5 是YOLO 系列最新的单阶段目标检测算法,所以选择YOLOv5 进行实验探究。
2.2 YOLO 算法网络结构
YOLOv5是目前YOLO系列最新的目标检测算法,和YOLOv4 具有相同的网络骨架,从精度和性能上考虑,在YOLOv4 的基础上加入了几点改进思路。具体改进思路包括以下几个方面:
(1)输入端:通过数据增强、自适应锚框计算和图片放缩,从算法的初始阶段提升模型的稳定性;
(2)基准网络:根据目标检测算法的基准网络特点融合了CSP 结构与Focus 结构;
(3)Neck 网络:YOLOv5 在其网络结构的初始层和输出层之间添加了FPN+PAN 结构,用于辅助目标的检测;
(4)Head 输出层:改进训练时的损失函数GIOU_Loss 和预测框筛选的DIOU_nms,使相同的输出层锚框机制达到更好地识别效果。YOLOv5 整体网络结构如图3 所示。

图3 YOLOv5 网络结构
2.3 实验环境配置
实验环境配置是实现深度学习的前提,本文在Windows10 系统上配置了深度学习运行环境,实验环境的配置参数如表2 所示。

表2 实验环境的配置参数
2.4 YOLOv5 算法实验探究
针对YOLO 系列最新的YOLOv5 的几个版本进行在精度和识别效果等方面进行对比,探究目前哪一个版本最适用于施工环境下的工人识别,以便在实际应用中选择最合适的目标检测模型,实现现场安全监管高效有序的进行。
为了衡量模型训练效果的好坏,通常用P(精确率)、R(召回率)、ACC(准确率)mAP(均值平均精度)作为评价指标,评价指标的计算方法如下式:
上式中TP、FP、TN、FN 分别表示分类器能否正确识别出目标的四种情况,为了更清晰地描述这四种情况,假设分类目标只有两类,计为正例(positive)和负例(negative),表3 直观地表达了四种识别情况。

表3 预测的四种类别
图4是YOLOv5 的五个版本针对施工环境下同一数据集工人识别精度对比,从图中可以看到YOLOv5的五种型号中YOLOv5n 的精度达到了96.9%,在施工环境中对于目标的识别精度远远超过了其他型号。
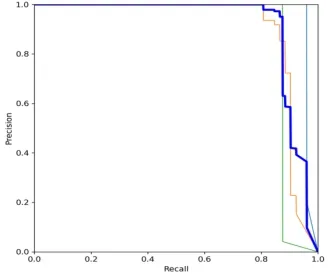
图4 五种型号精度对比
YOLOv5n 在精度上高与其他几个版本,从识别效果上看,是因为YOLOv5n 具有较低的漏检率和误检率,也就是上面提到的FN 被错误划分为负例的个数和FP被错误划分为正例的个数,从公式(1)(2)(3)可知,FN和FP数值过高将严重影响精确率、召回率和准确率,现针对同一影像展示各个模型的识别结果如表4 所示。

表4 各个模型结果
2.5 基于YOLOv5n 的多目标识别
通过以上的对比分析,无论是从精度、训练效果还是识别效果YOLOv5n 在施工环境中都具有较好的表现能力,所以选择YOLOv5n 对施工场地进行多目标识别,由于施工环境中机械伤害也是比较常见的工伤事故类型,个人防护用品的佩戴是事故发生时可以减小事故后果的有效手段,所以本文通过对施工环境中工人、安全帽和施工机械的识别与管控从而从技术上提高施工现场安全管理水平。
图5是三种识别对象的PR 曲线图,曲线与坐标轴所围成的面积表示该类别的精度,其中工人的识别精度达到了96.8%,安全帽的识别精度达到了90.2%,施工机器的识别精度达到了87.8%,所有类别均值平均精度达到了91.6%。由于工人的特征比较明显所以在三个类别当中精度最高,安全帽的特征虽然也比较明显但是目标较小所以识别精度低于工人,由于施工环境中存在较多不同种类的机械,机械之间特征变化较大所以在三个类别当中精度最低,实验结果比较符合理论猜想,且三种目标的识别精度均达到了较高水平,识别效果如图6 所示。

图5 P-R 曲线

图6 多目标识别效果图
3 无人机倾斜摄影
倾斜摄影三维模型可以真实地反应具体场景的外观以及各个点的位置、高度等信息,借助无人机可以快速获取具体场景的影像数据,利用相关三维建模软件实现倾斜摄影三维模型的构建,同时有效提升了模型的生产效率,大大降低了三维模型数据采集的经济代价和时间代价。
3.1 实验条件
本节主要通过无人机倾斜摄影技术实现对目标的定位,通过对施工场景进行三维建模获得其准确的位置信息,判断目标物体所处的空间位置,从而判定是否处于不安全状态,以便及时发出预警信息。
为了确定这种视觉定位的准确性,必须要对倾斜摄影的准确性进行探究,以保证定位误差在可接受范围内。由于条件有限和考虑到无人机在人口密集处飞行具有非常大的安全隐患,并未获取实际施工环境下的倾斜摄影数据,而是通过现场考察和无人机的实地飞行获得了武汉市江夏区乌龙泉矿采矿环境下的倾斜摄影数据来进行倾斜摄影准确性的探究。两者都是对实际场景的三维建模,所以在误差方面本质上完全相同。
3.2 倾斜摄影三维建模
无人机倾斜摄影三维建模,主要包括利用无人机进行倾斜摄影数据的采集、各建模软件优缺点对比选择建模软件和具体操作软件进行三维模型的构建,笔者已在参考文献[22]中对该内容进行了详细介绍。三维建模生产路线如图7[22]所示。

图7 三维建模生产路线
本文在获得乌龙泉矿倾斜摄影数据之后对矿山表面进行了三维建模,建模效果如图8 所示[22]。

图8 模型展示
3.3 倾斜摄影准确性的验证
在目标识别的基础上需要进一步借助倾斜摄影三维模型确定目标的相对位置关系,所以这种视觉定位的准确性由三维模型的准确性所决定,因此本实验通过验证倾斜摄影三维模型距离测量的准确性以保证这种视觉定位误差在可接受范围内。本实验选取了多组不同大小的模型测量值和实际测量值进行对比和分析,从相对误差和绝对误差两个角度去分析这种视觉定位的准确性,图9 是12 组数据的误差变化曲线[22]。

图9 误差变化曲线
从理论上讲,测量都会有误差的存在,随着测量范围的变大绝对误差也会变大,而相对误差会逐渐变小,当测量范围足够大时,相对误差会趋近于零,这主要是由于测量时模型中点未能与实际中的点完全吻合所引起的,本实验的误差变化曲线完全符合这种趋势,证明了本实验数据具有较高真实性,也证明了实际误差要小于本数据所表现出的误差,从本次实验结果来看误差大小也仅有1.5%左右,满足本研究对误差的要求。
倾斜摄影获得的三维场景中每个点都有具体的位置信息,从而可以确定目标识别算法所识别出物体的具体位置,当人员出现在所划分的危险区域或工作机械所造成的危险区域时系统会向现场安全管理人员发出预警信息以便管理人员及时地做到有目标的安全巡检,并且倾斜摄影技术所获得的工人高度也可以向管理者提供是否存在高处作业信息使安全管理人员及时地做好现场监督。
3.4 不安全状态整体识别流程
利用计算机视觉可对施工环境中多个目标多个危险区域进行一体化监管,管理者可以实时查看施工现状,当有危险行为及不规范操作和需要实时监督的作业时,系统可主动向管理者提供相关位置信息,现场安全管理人员可以及时到达指定管理区域,使安全管理工作更加有序的进行,避免了现场安全管理的盲目性。在以上目标识别算法达到较好的实验效果和无人机倾斜摄影三维建模具有较高准确性的基础上绘制了对不安全状态进行识别的简易流程图如图10 所示。

图10 安全监管实现流程
图10为一个实现智能检测与安全监管的整体流程,监控数据输入到智能检测模型中,实现对目标的识别和位置关系的确定,从而判断不安全状态类型及存在位置。
4 结论
多目标识别算法的实际实验结果符合理论猜想,倾斜摄影模型误差具有较高的精确度,三维视频融合已拥有较为成熟的技术,基于此本文有如下实验成果和结论:
(1)结合事故发生的主要因素的特点引入计算机视觉用于对施工现场风险的识别与定位,运用目标识别算法构建了多目标识别模型;
(2)通过对多种目标识别算法的实验对比分析,确定了在施工环境中无论是在精度还是识别效果上均最优的目标识别算法,为以后该场景的实际应用提供了理论依据;
(3)通过实验验证了无人机倾斜摄影所构建的三维模型的测量误差在1.5%左右,范围长度大于35m 测量误差将小于1%,从而说明了目标识别模型所识别出物体的距离具有较高的准确性;
(4)利用计算机视觉的目标识别和倾斜摄影的位置定位功能对施工场景的风险进行识别和定位,实时监测是否有不安全行为和不安全状态的出现,实现了多目标多区域一体化安全监管,避免了单纯人工监管的盲目性,在一定程度上提高了安全监管的效率。
猜你喜欢
机电安全(2022年4期)2022-08-27
商品与质量(2021年43期)2022-01-18
现代企业(2021年2期)2021-07-20
建材发展导向(2021年7期)2021-07-16
课外生活·趣知识(2019年4期)2019-09-10
劳动保护(2018年5期)2018-06-05
工会信息(2016年4期)2016-04-16
读写算(下)(2015年11期)2015-11-07
中国火炬(2015年11期)2015-07-31
中国火炬(2014年3期)2014-07-24
