
基于改进DBSCAN 算法的船舶轨迹聚类与可视化应用
2023-09-08 01:44邱文轩许志远翟泽宇曲胜张晓鹏许航
中国水运 2023年8期
邱文轩,许志远,翟泽宇,曲胜,张晓鹏,许航
(大连海洋大学,辽宁 大连 116023)
航运业作为庞大的基础性产业,不断产生海量数据存储在船舶识别系统(Automatic Identification System,AIS)中,涵盖船舶时空信息[1],为船舶轨迹预测提供丰富的数据源。
刘涛[2]等人提出运用DBSCAN 算法对船舶轨迹进行聚类,分析航域交通流的拥挤区域,通过交通流评判交通拥挤区域;潘家财[3]等利用船舶信息的空间分布来发掘通航环境状况,得出航速变化率空间分布;Pan[4]等人对DBSCAN 算法进行改进,提出基于密度的对不同线路进行分类,在宏观视图上没有进行可视呈现。Ide K[5]利用AIS 数据计算船舶的港口吞吐量和全球海洋运输网络的拓扑结构。综上,专家学者在轨迹聚类领域做了很多工作,本文根据天津港水域解压清洗处理后的AIS 数据,改进DBSCAN 算法细化聚类簇后进行时空信息可视化呈现。
1 数据预处理
1.1 属性选择
AIS 收集的数据有用信息需要通过数据清洗来获取数据字段合理范围[6],如表1 所示。
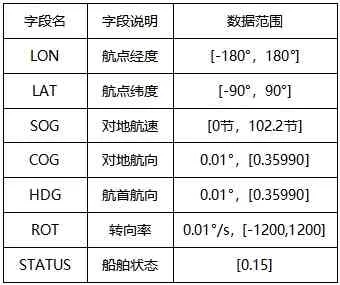
表1 船舶轨迹数据字段合理范围
1.2 数据清洗
假设同一轨迹段上的点pi-1,pi,pi+1为相邻点,pi对应的航行特征值(位置、航向、航速)为xi,基于pi,pi+1的航行状态预测pi+1处对应的航行特征值为x’i+1,即x’i+1=xi+f(xi,xi-1)。如果,表明数据发生漂移需要剔除[7]。
式1 为数据漂移算子,(x,y)代表船舶位置特征,v 代表航速特征,c 代表航向特征,w1、w2、w3对应位置、航速向异常阀值[8]。
2 改进DBSCAN 算法
2.1 DBSCAN 算法
DBSCAN 算法原理如图1 所示。

图1 DBSCAN 算法原理
2.2 算法改进
改进DBSCAN 算法,通过查询核心节点以及未标记的点,从而减少查询次数。在p 包含的对象数不小于MinPts 时,建立新簇C1,然后将点加入N,检查N 中每个点q,避免重复查询从而提升算法聚类执行效率。输入:数据集D,邻域半径Eps,最小邻域点数MinPts;输出:基于密度的簇的集合。
1:标记所有对象未unvisited;
2:Do;
3:随机选择unvisited 对象p;
4:If p 包含的对象数不小于MinPts;
5:创建新簇C1,把p 添加到候选集N;
6:For N 中每个点q;
7:If 点q 与对象p 不重叠不存在核心节点;
8:用新簇C2 标记;
9:Else if 点q 与对象p 重叠且存在核心节点;
10:将对象q 邻域内unvisited 的点归入C1;
11:Else if 对象q 与其他标记的节点邻域重叠;
12:将其中点加入候选集N;
13:End for;
14:Else 标记为噪声。
3 船舶典型轨迹相似性度量
融合距离MD(The Merge Distance)[9]表示融合后两条轨迹之间的最短距离,原理如图2 所示。

图2 最短子轨迹
通过假定a 和b 两条轨迹是二维空间内的一系列序列(a1,...,an),(b1,..,bm)构成,使用d(ai,bj)表示两点之间在二维平面上的欧式距离,通过序列和a 和b 的最短超轨迹s(a,b)是长度最短的轨迹,a 和b 是s(a,b)的子序列,其长度用L(a,b)表示。通过公式2 从轨迹a 和b 的长度L(a),L(b)获得融合距离MD(a,b)。
4 实验与分析
选取渤海湾西端的天津港作为实验航道,如图3 所示,公共泊位岸线长14.5 千米是良好的实验航道。

图3 天津港段实验航道卫星图
在运行64 位Windows10,InterICoreIi7-10700 CPU@和8G 内存的计算机硬件上操作。DBSCAN 算法依赖eps 和MinPts 参数,实验需要迭代选择最优参数区间。当数据密度不均匀时,原始聚类轨迹如图4 所示,效果较差信息呈现较片面且聚类过程耗时较长。

图4 天津港段船舶AIS 轨迹原始聚类轨迹
当eps=0.0030、MinPts=5 时可以产生良好的聚类效果。改进后的聚类结果如图5 所示,聚类簇通过细化聚类特征明显入港轨迹聚类质量较高。
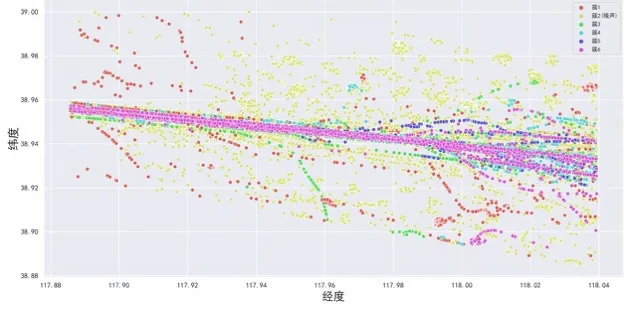
图5 天津港段船舶AIS 轨迹改进聚类轨迹
通过对DBSCAN 经典算法和改进后的算法进行对比如表2 所示,通过减少运行邻域样本点查询的次数和时间,从而提高效率减少计算时间消耗。
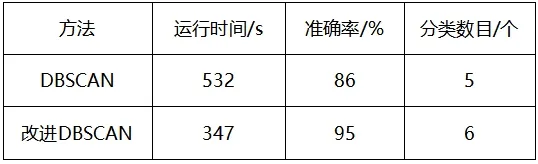
表2 两种算法对比结果
实验中对AIS 数据进行聚类,得出了渤海湾西端的天津港主要航道的四条典型轨迹,如图6 所示,船舶航行的典型轨迹遵循航道的设置,数据聚类分析结果可信,具备参考价值。
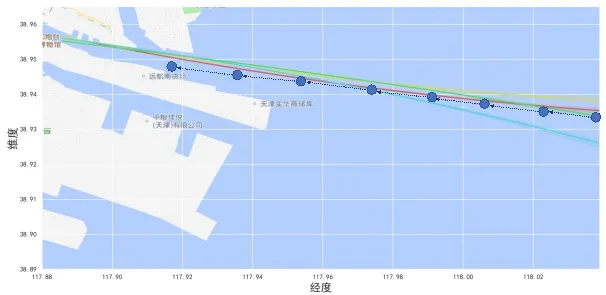
图6 船舶入港典型轨迹
猜你喜欢
水上消防(2021年4期)2021-11-05
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
留学(2017年5期)2017-03-29
周口师范学院学报(2016年5期)2016-10-17
灾害医学与救援(电子版)(2016年1期)2016-03-11
灾害医学与救援(电子版)(2016年1期)2016-03-11
IT时代周刊(2015年9期)2015-11-11
水道港口(2014年1期)2014-04-27
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
