
基于通信的协作型多智能体强化学习算法综述
2023-09-04 03:02:36田琪,吴飞
航天控制 2023年4期
田 琪,吴 飞
浙江大学计算机科学与技术学院,杭州 310000
0 引言
令智能体拥有类似人类的行为决策能力一直是人工智能研究人员追求的终极目标之一,近年来深度强化学习技术的快速发展使得这个目标成为可能,例如2017年5月,基于深度强化学习技术训练的AlphaGo[1]智能体在中国乌镇围棋峰会上击败了排名世界第一的世界围棋冠军柯洁,这预示着单智能体在特定决策任务上已经拥有超越人类的能力。自从AlphaGo出现后,激发了深度强化学习社区的研究热潮,其中一个重要的研究方向就是协作型多智能体强化学习[2](Cooperative Multi-Agent Reinforc-ement Learning,CMARL)技术。不同于AlphaGo这种单智能体决策模型,协作型多智能体强化学习旨在为多个智能体训练其对应的策略模型,从而使得这些智能体能够合作以完成一个共同的目标任务。
传统的协作型多智能体强化学习在训练阶段允许访问环境的全局信息和每个智能体的局部信息,但在执行阶段只允许每个智能体根据自身的局部观测执行下一步的动作,如图1(a)所示。这显然不是最优的方式,因为在多智能体环境中每个智能体的决策不仅仅与自身观测有关,还与其他智能体有关。为了缓解这个问题,如图1(b)所示,在传统的协作型多智能体强化学习的基础上,近期许多研究者指出如果允许多个智能体在训练和执行期间相互交换信息,那么每个智能体就能更好地执行下一步的动作,这种学习范式被称为基于通信的多智能体强化学习算法。
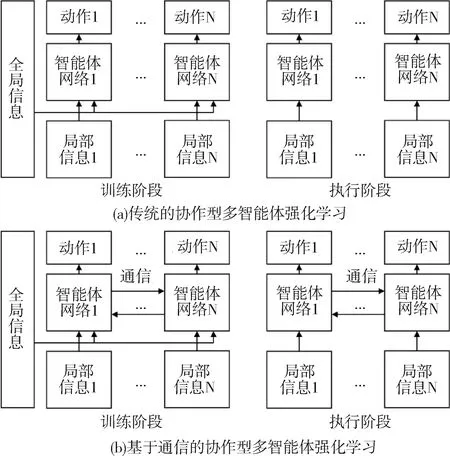
图1 传统/基于通信的多智能体强化学习训练/执行阶段
本文将针对这种通信类的算法进行综述。即首先介绍基于通信的协作型多智能体强化学习技术基础,然后列举出这个领域中具有代表性的工作,包括传统的通信算法、受限带宽下的通信算法,接着说明基于通信的协作型多智能体强化学习技术在航天领域的应用,最后对本文的内容进行总结。
1 通信机制
1.1 问题定义
基于通信的协作型多智能体强化学习由去中心化的部分可观察马尔可夫决策过程[3](Decentralized Partially Observable Markov Decision Process,Dec-POMDP)扩展而来,它可以被定义为一个元组〈N,S,A,T,R,O,M,Ω,γ〉,其中N表示智能体的数量、S表示环境的全局状态空间、A={ai}i=1,2,…,N表示动作集合、T(s′|s,a):S×A→S表示状态转移函数、a=[a1,a2,…,aN]表示联合动作空间、R={ri}i=1,2,…,N:S×A→N表示一组奖励函数,在某些设置下可以是1个共享奖励、O={oi}i=1,2,…,N表示所有智能体的局部观测集合、Ω(s,i):→Oi是决定智能体i局部观测的观测函数、γ表示折扣因子、M={mi}i=1,2,…,N表示消息空间,其中mi表示智能体i发送的消息,它通常通过神经网络编码局部观测oi获得。每个智能体都会收到由其他智能体发送消息m-i=[m1,…,mi-1,mi+1,…,mN]以做出更好的决策,最终的目标是最大化奖励函数。
1.2 训练框架
目前基于通信的协作型多智能体强化学习主要使用Q-学习[4]风格的训练框架和演员家-评论家[5]的训练框架。Q-学习风格的训练框架将智能体网络建模为Q函数Qi(oi,ai,m-i),典型的训练方法是QMIX[6],该方法的损失函数如下:
(1)
其中:Qtot表示混合网络,(·)-表示目标网络,(·)′表示下一个时刻的变量。这种智能体的建模方式主要处理离散动作空间的问题。
演员家-评论家的训练框架将智能体网络建模为策略πi(ai|oi,m-i),典型的训练方法是MAPPO[7],该方法中具有参数θi的每个策略πi的更新策略梯度如下:
(2)
2 深度强化学习算法
基于通信的协作型多智能体强化学习的重点是如何处理智能体之间传递的消息。具体来说,对于智能体i,其接收的消息可以被表示为m-i=[m1,…,mi-1,mi+1,…,mN],这些来自其他智能体的消息mj(∀j≠i)应该通过怎样的交流模块进行聚合是基于通信的协作型多智能体强化学习算法关注的重点,当m-i聚合完成后,代入到式(1)或式(2)的训练框架中即可完成多智能体系统的训练。目前已经涌现了许多基于通信的协作型多智能体强化学习算法的文献,本文将这些文献分为传统通信方法和受限带宽通信方法2类,前者的目的是希望多智能体系统在加入通信模块后可以最大化提升系统的整体性能,后者是希望通信模块在增益系统性能的同时尽量占用更少的通信带宽,从而压缩冗余的通信消息。下面本文将依次介绍这2类算法。
2.1 传统通信方法
传统通信方法旨在通过交流模块帮助多智能体能够更好地完成一个合作任务,如图2所示,其可以分为全连接通信、局部连接通信和加权连接通信3种类别。全连接通信是指每个智能体会接收来自其他智能体传输的所有消息,如图2(a)。局部连接通信是指每个智能体只会接收部分智能体传来的信息,因为并非所有消息都对自身决策有用,过多的冗余消息反而会成为噪声,对决策产生负面影响,如图2(b)。加权连接通信是每个智能体按重要性权重采纳其他智能体传来的消息,而不是完全接受或者完全否定,是一种更合理的方式,如图2(c)。下面介绍这3类传统通信方法的代表方法。

图2 传统通信方法的分类
对于全连接通信,CommNet[8]是其典型代表,也是该领域最早的工作之一,后续的许多工作都是基于该方案的改进。
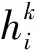
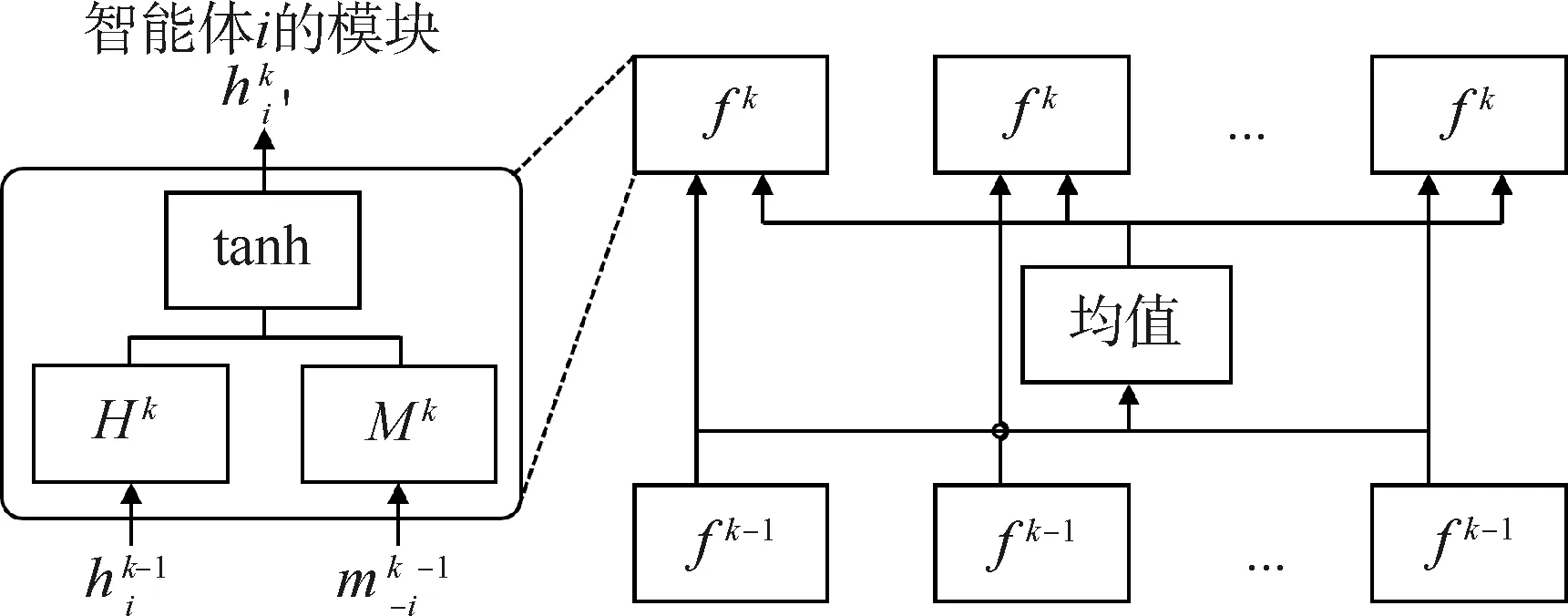
图3 CommNet的消息聚合机制
(3)
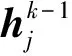
对于局部连接通信,IC3 Net[10]是典型代表。如图4所示,该方法的总体训练框架和CommNet非常相似,主要的不同是每个智能体在第k轮交流时都会学习一个神经网络fgk,该神经网络将智能体上一层的输出数据作为输入,并从0或者1中预测一个值,如果结果为0表示对应智能体的信息不参与聚合,如果结果为1表示对应智能体的信息参与聚合。它就像一个门控开关一样,因此被称为基于门机制的神经网络。
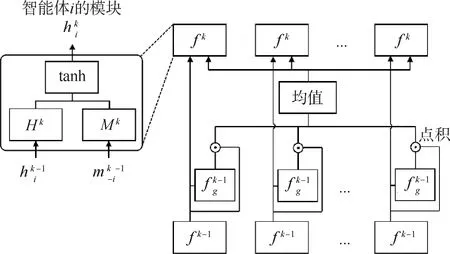
图4 IC3 Net的消息聚合机制
(4)


表1 传统通信方法的总结
对于加权连接通信,TarMAC[15]是其典型的代表,它主要是将自然语言处理领域中的注意力机制引入到多智能体交流模块中。
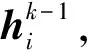

图5 TarMAC的消息聚合机制
(5)
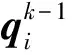
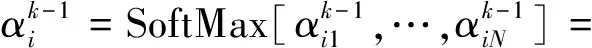
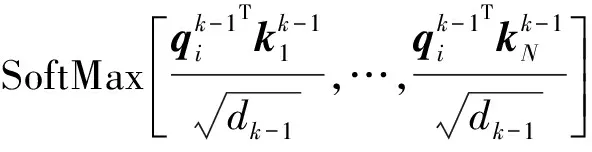
(6)
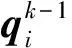
(7)
这种基于注意力的方法也启发了后续一系列工作,如DGN[16],SymbC[17],它们具体的建模方式与TarMAC略有不同。实际上局部连接通信和加权连接通信并不矛盾,一些工作将它们的思想融合,实现了更优的性能,比如G2A[18],MAGIC[19],MAIC[20]。表1简单总结了传统通信方法,其中类型A/B/C分别表示全/局部/加权连接通信。
2.2 受限带宽通信
传统通信方法不限制通信带宽,只要对多智能体系统有利的消息都允许进行传递,然而在现实场景中如果通信占用太多的带宽,将消耗大量的资源,因此以受限带宽下的多智能体交流为主题的研究方向逐渐受到研究者的重视。这一研究领域的关键是如何对通信消息进行压缩,为了将这部分的工作放在一种统一的视角下讨论,可以将多智能体交流看作交流图上的信息流动,其中图的节点就是每个智能体需要传递的消息,图的边是信息流动的方向,那么交流图的信息压缩可以被分为结构压缩和节点压缩。结构压缩是指每个智能体应该尽可能少地和它们智能体交流,节点压缩是指当确定两个智能体需要交流时,传输的信息也应该是简洁的。
对于结构压缩类的工作,GACML[21]是典型代表。
如图6所示,GACML与图4中的IC3 Net非常相似,对于智能体i,其输出hi可以表示为:
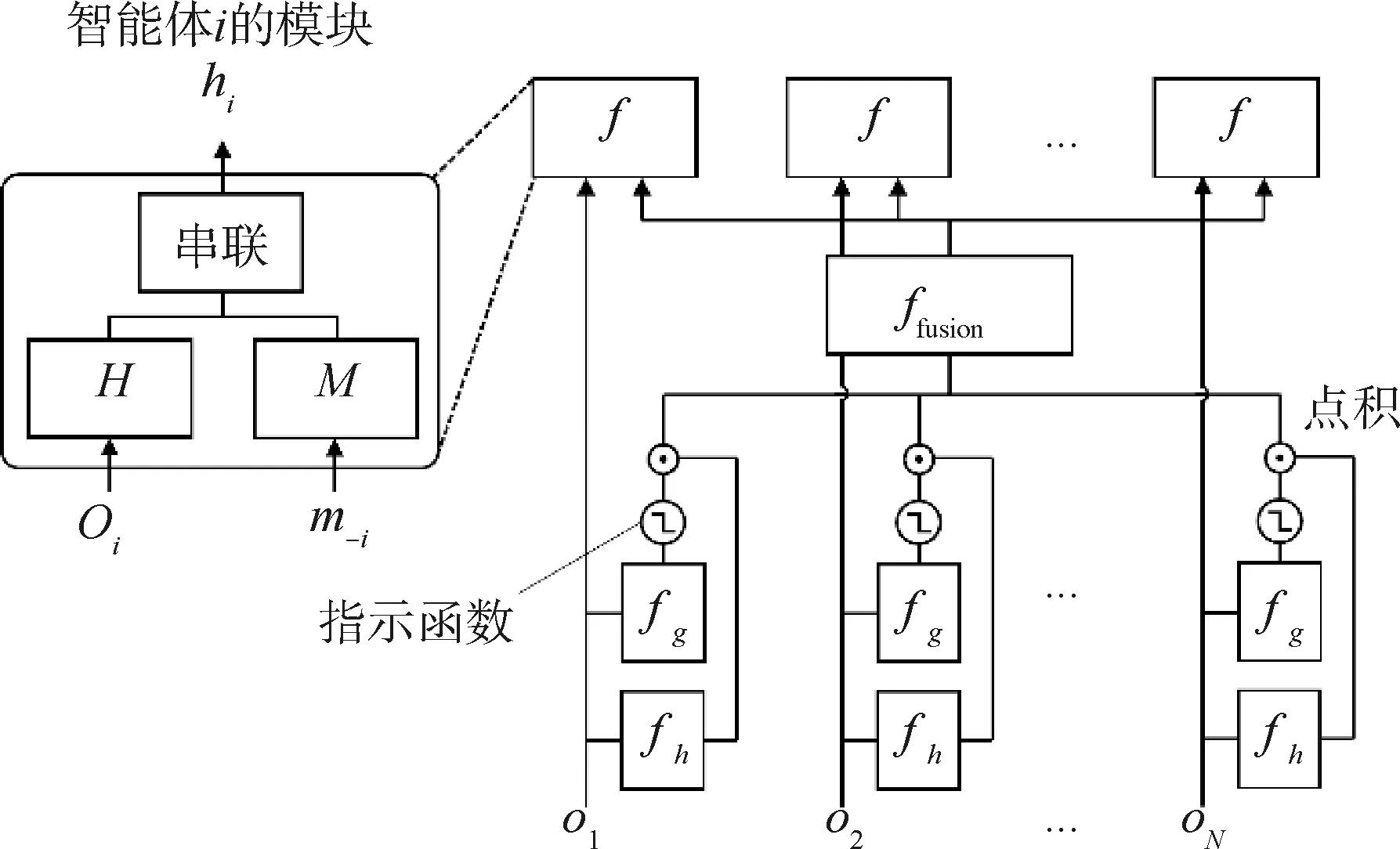
图6 GACML的消息聚合机制
(8)
GACML与IC3 Net主要有如下几点区别:1) 由于带宽受限,GACML只考虑单轮通信而不像IC3 Net那样建模为多轮通信。2) 消除了IC3 Net中f函数的tanh激活单元。3) 消息融合方式从IC3 Net中简单求均值变为一个融合网络ffusion。4) 门控单元函数的学习不再是与智能体策略网络联合训练,而是建模为二分类的监督学习,其标签可以表示为:
(9)
(10)
对于节点压缩类的工作,IMAC[24]是典型代表。它的主要思想是利用信息瓶颈理论[25]构建如下有约束的优化问题:
LMARLs.t.MI(oi;mi)≤Ic
(11)
其中:优化目标是原始的多智能体强化学习损失函数LMARL,它可以被实例化为式(1)或式(2)、MI(·;·)表示互信息、Ic表示约束的信息项、s.t.表示在优化过程中局部观测oi和消息表征mi的互信息应该限制到信息量Ic以下。从总体上看,该式子的含义是希望消息表征mi在满足多智能体任务的前提下,尽可能地压缩消息表征mi的信息量,从而减少消息对带宽的占用。为了求解这个问题,需要用拉格朗日方程将这个带约束的优化问题转换为无约束优化问题,然而即使进行了这样的转换,损失函数中的互信息项依然难以优化,因此研究者通过变分推理获得了互信息项的变分上界,使整个损失可以实现端到端的优化。后续提出的NDQ[26]借鉴了上述思想,并设计了2个互信息项以同时约束消息表征的简洁性和紧凑性。表2简单总结了所有受限带宽的通信方法,其中类型A/B分别属于结构压缩/节点压缩类型的文献。
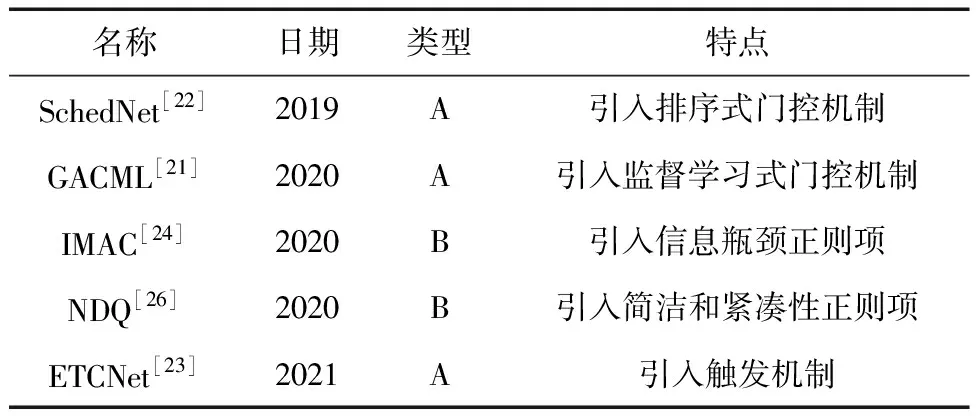
表2 受限带宽通信方法的总结
3 在航天领域的应用
基于通信的多智能体强化学习在合作型的卫星群控制领域拥有广阔的应用前景,比如美国太空探索技术公司SpaceX近期提出了一种名为“星链”的项目,该项目计划2019~2024年间在太空搭建由约1.2万颗卫星组成的“星链”网络提供互联网服务,其中1584颗将部署在地球上空550 km处的近地轨道,并从2020年开始工作。在这个场景下,每个“星链”卫星可以看作为一个智能体,为了使卫星群尽可能多地有效覆盖地球表面,需要精密控制卫星群的行动轨迹;另一方面,避免不同卫星间的碰撞也是非常重要的环节,而交流机制可以很好地使每个智能体理解其他智能体下一步可能的动作,从而优化多个卫星的群体运行轨迹。
4 结论
首先介绍了基于通信的协作型多智能体强化学习与传统协作型多智能体深度强化学习的区别,然后详细说明了多智能体强化学习中的通信机制,接着对常见的基于通信的协作型多智能体深度强化学习算法进行了分类和介绍,指出这类算法在航天领域的应用前景,最后对文章进行总结。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22 22:13:22
数学物理学报(2021年2期)2021-06-09 08:54:42
通信产业报(2020年43期)2020-01-15 06:38:43
作文成功之路·小学版(2019年8期)2019-09-18 01:12:04
读者(2017年14期)2017-06-27 12:27:06
发明与创新(2016年38期)2016-08-22 03:02:50
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31 19:42:13
读写算(下)(2016年9期)2016-02-27 08:46:31
电子工业专用设备(2015年4期)2015-05-26 09:10:39
中国卫生(2014年12期)2014-11-12 13:12:26
