
基于Spark与混沌系统的图像加密算法
2023-09-04 09:23:00刘建东刘玉杰
计算机应用与软件 2023年8期
钟 鸣 刘建东 刘 博,2 刘玉杰 李 博
(北京石油化工学院信息工程学院 北京 102617) 2(北京化工大学信息科学与技术学院 北京 100029)
0 引 言
信息技术的迅速发展使得传统单机无法满足对大量数据进行快速计算处理的要求,而大数据技术的兴起为处理大量数据提供了新的方式,使用大数据技术可以轻易掌握并处理庞大的信息数据集[1-3]。常见的大数据平台有很多种,其中,Spark是一种混合式计算框架,可以进行批处理和流处理,能够快速实现对大数据的并行处理。其继承了主流大数据平台所具有的优点,同时在计算速度和工作负载等方面又表现得更加优秀。这些平台为用户提供了有效的大数据处理手段,但缺少了对于数据安全性问题的关注,如何保证这些数据集在传输和存储时的安全性也逐渐成为人们关注的一个热点问题[4-6]。
混沌系统对状态变化反馈极度敏感,导致系统变化呈现伪随机状态,且系统运行的轨道难以控制,这在一定程度上符合了密码学的相关要求,从而衍生出混沌密码。不同于其他密钥生成方法,通过对混沌系统进行迭代计算就可以得到满足要求的伪随机序列,可用作对图像进行加密的密钥。目前,基于混沌系统设计的图像加密方案较多,但很少有将其与Spark大数据平台结合进行研究的相关文献,且对于大数据平台与混沌系统相结合的加密研究多采用了Hadoop平台。文献[7]设计了一种高维度且离散的超混沌系统,同时采用闭环耦合控制和密文反馈的思想设计了一种基于Hadoop大数据平台中MapReduce并行加密的算法,具有良好的实现效率。文献[8]基于改进后的Logistic映射和Tent映射组成的双混沌系统设计了加密算法,这一双混沌系统的MapReduce并行编程能够安全高效地对数据进行加密。文献[9]针对Hadoop平台设计了一种改进对称密钥算法,该算法在私钥基础上加入了动态密钥,使用了双密钥机制,提高了安全性,同时Hadoop平台的读写机制也提高了算法的运行效率。
目前将大数据平台结合混沌系统的加密方法还存在着一定的不足。首先,在混沌系统的选取方面,部分方法采用的混沌系统性能不佳,低维系统无法快速生成多条伪随机序列,而高维生成的伪随机序列间独立性不够,使得加密效果大打折扣。其次,对大数据平台处理数据的方式理解不到位,没有充分发挥大数据平台能够并行处理大量数据的优势,导致单机计算时间和大数据平台计算时间之间差异较小,加密效率提升不明显。对于上述问题,本文提出一种基于Spark大数据平台和三维动态整数帐篷映射的加密算法。该算法采用三维动态整数帐篷映射作为伪随机序列发生器,可以快速生成多条独立性较强的序列。利用Spark大数据平台将图像数据切片,利用生成的伪随机序列作为密钥分别对每片数据进行加密,最后将得到的数据块进行整合分析。分析表明,采用Spark大数据平台进行多图片加密操作,可以发挥出其并行高效的特点,加密得到的密文图像具有一定的安全性。
1 三维动态整数帐篷映射[10]
帐篷映射定义为:
(1)
相对于Logistic映射难以遍历整个取值空间的缺陷,帐篷映射可以通过对数值的不断拉伸折叠将其限制在取值空间,并遍历取值空间,性能更加优秀。
通过扩展空间维度、增加计算精度、施加动态扰动可构建三维动态整数帐篷映射,表述为:
F:a(xi+1,yi+1,zi+1)=
(2)
该系取值空间为:
针对定义中参量gi、hi和si作如下表述:
(3)
式中:mi、ki和vi为动态参数,对定义于整数域空间的三维动态整数帐篷映射进行动态扰动;At表示随三维系统的迭代时间以及迭代得到的伪随机序列值,矩阵A对每行和每列做幻方变换,变换结束后仅取某一列向量,并表示为At,t=1,2,3。
矩阵A表示为:
(4)
对其进行幻方变换的过程可根据上一次迭代计算得到的x、y、z值来指定分别对每行和每列做循环位移,若值为奇数则每行每列循环左移,为偶数则每行每列循环右移。通过幻方变换并去某一列,从而将输出的值重新代入到迭代方程中,构成环形耦合。三维动态整数帐篷映射如图1所示。
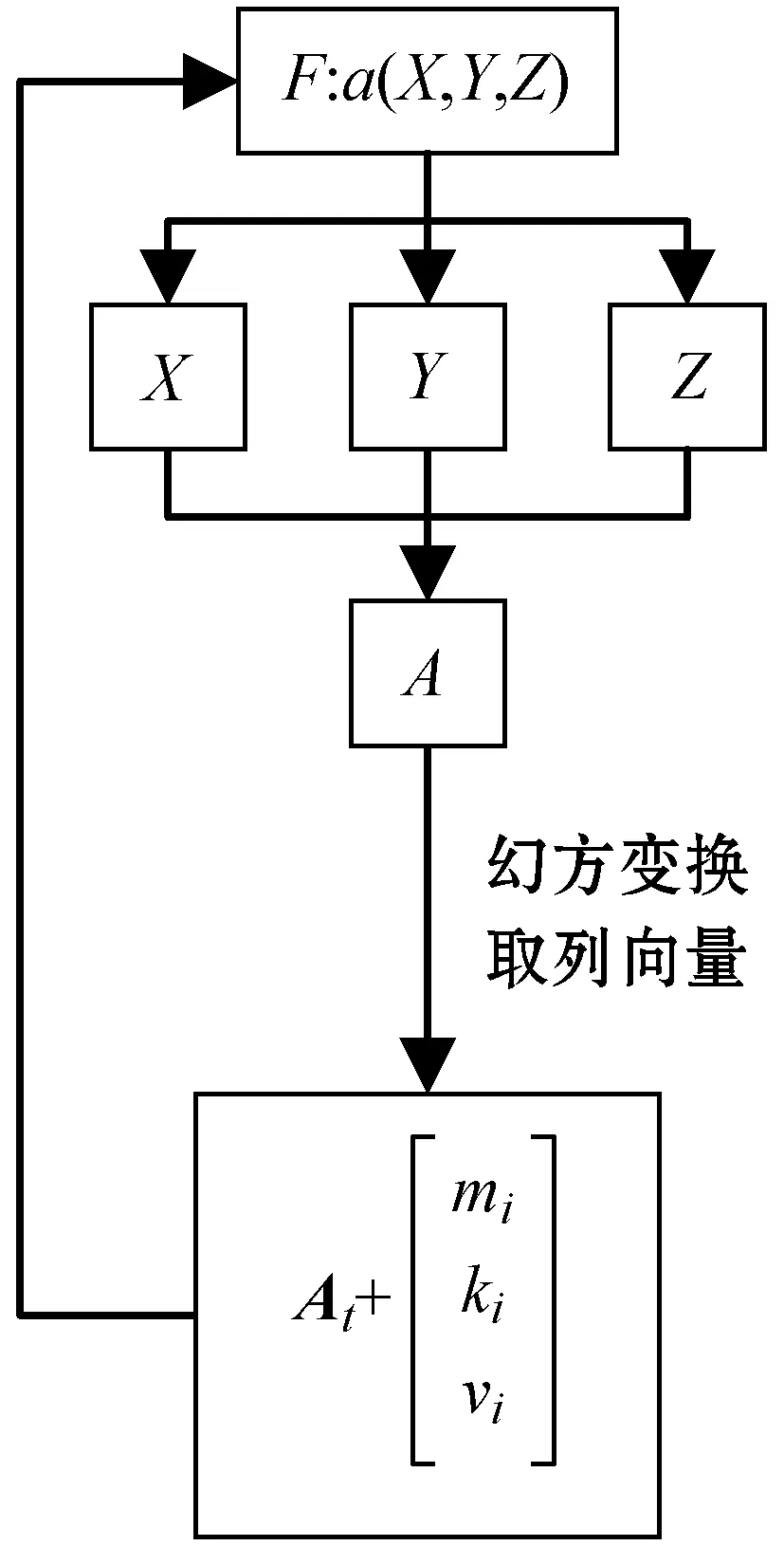
图1 三维动态整数帐篷映射
通过扩展维度可以将帐篷映射扩展至三维,增加运行混沌系统获得的序列数。增加精度可以扩大混沌系统的取值空间,增加取值的随机性。将帐篷映射由实数域转换至整数域进行计算会较快地产生短周期现象,可以通过施加动态扰动避免短周期影响。
2 Spark大数据平台
Spark大数据平台架构如图2所示,其中,任务控制节点负责构造任务执行的入口,并将其标注为SparkContext。任务进入后,需要集群资源管理器根据任务量进行资源的调度分配,并根据任务要求选择合适的模式工作,控制工作节点以及执行进程占有计算资源并进行任务处理。

图2 Spark大数据平台架构
Spark进行数据处理的基础是RDD。RDD有分区特性,可以分布于集群中的各个节点上,支持并行计算。Spark对RDD的Transformation操作采用了惰性操作,对于RDD的转化不会立刻执行,只有在调用Action操作执行数据操作时才会进行计算,有效节约了计算资源。在需要对数据进行多次操作时,也可以使用内置方法将RDD持久化,避开惰性机制,提高运行效率。
Spark针对Hadoop平台磁盘IO开销大、MapReduce操作时延高等问题进行了优化设计。为了降低磁盘的IO开销,Spark将数据块尽可能存放于内存,减少每次计算后将数据写入磁盘的次数。此外,Spark在实现Hadoop MapReduce操作的基础上,还提供了各种便捷的API,便于进行数据块操作,简化了Hadoop中Map操作和Reduce操作的编程,缩减了整体的代码量。此外,Spark平台支持多种编程语言,可以运行于独立的集群,也可以运行于Hadoop等生态环境中,同时能够读取HDFS、HBase等多种数据源,具有较强的灵活性[11-13]。
3 基于Spark平台的图像加密算法
采用三维动态整数帐篷映射作为伪随机序列生成器,结合Spark大数据平台处理数据的特点,设计一种彩色图像加密方案,流程如图3所示,其中主要包括了三维动态整数帐篷映射生成伪随机序列、图像RGB分量异或运算、Arnold置乱、DNA编码混淆。基于Spark的加密算法操作流程如图4所示,主要包括了明文图像分片成为RDD数据集、map函数对数据块进行加密操作、数据块合成密文图像三个部分。

图3 基于三维动态整数帐篷映射的加密算法流程

图4 基于Spark平台的加密算法流程
根据图4,基于Spark平台和三维动态整数帐篷映射的加密算法具体流程表述如下:
1) 在准备阶段,创建Spark应用程序接口SparkContext,读取待加密明文图像L,同时利用三维动态整数帐篷映射运行两次,生成长度为M×N的伪随机序列X1、Y1、Z1、X2、Y2、Z2,M×N为明文图像L的大小。
2) 在分片阶段,创建RDD数据集合,使用Spark中的parallelize函数对明文图像进行分片,为了充分利用Spark集群并行处理数据的特性,提高运行的效率,可以设置数据分片数目为h,h为集群中Executor的数目,每片中包含的像素点数为b。
数据分片操作如下:
输入:明文图像L。
输出:明文图像L的RDD。
RDD←parallelize(L,h)
3) 在图像加密阶段,使用map函数实现对RDD数据的并行处理。输入量为分片处理后得到的RDD数据集,使用伪随机序列X1、Y1、Z1对应每块数据中RGB各通道的像素点LRj、LGj和LBj做异或运算,得到中间密文CRj、CGj和CBj,其中,j=1,2,…,h,对应了分片后得到的RDD数目。
对中间密文CRj、CGj和CBj中的像素点及伪随机序列X2、Y2、Z2做任意一种DNA编码,编码规则如表1所示。
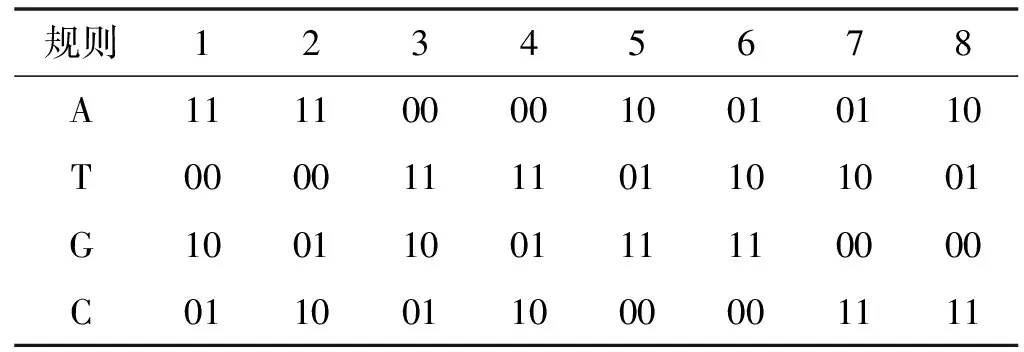
表1 DNA编码规则
针对每个像素点和伪随机序列数,按照一定的规则从DNA加法、DNA减法、DNA异或中取一种方法进行计算,计算遵循二进制计算规则,结果仅保留最后两位。以表1中第一种规则为例,DNA加法、DNA减法、DNA异或的计算结果如表2至表4所示。
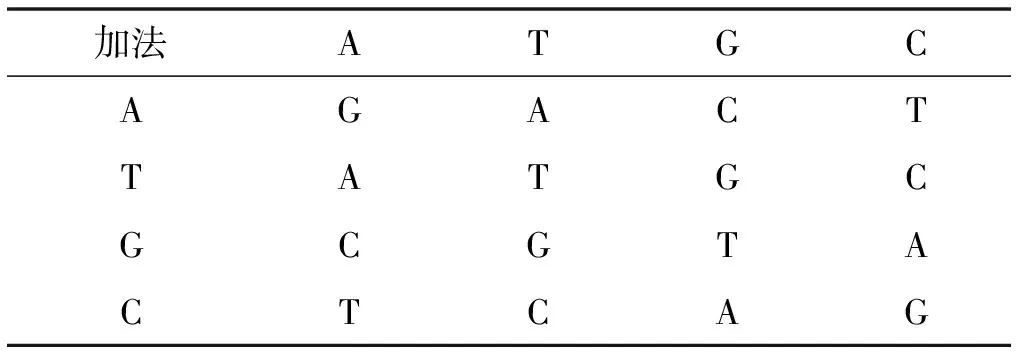
表2 规则1做DNA加法

表3 规则1做DNA减法

表4 规则1做DNA加异或
对经过DNA编码处理的做DNA解码获得像素点数值,对每个像素点分解出八个位平面,对位平面中的每个比特位使用Arnold映射进行置乱,Arnold映射定义如下:
(5)
式中:参数x和y表示比特位的坐标值;x′和y′表示原比特位坐标值经过Arnold映射变换后得到的新比特位坐标值;p和q为参数,可以从对应的X、Y、Z序列中任意取值为p和q赋值。
经过map函数中的异或运算和Arnold映射置乱后,得到结果,输出量为加密操作后得到的RGB各通道的密文矩阵。
RDD数据map操作如下:
输入:明文图像L的RDD。
输出:图像L各密文通道的RDD。
(LRj,LGj,LBj)←split(RDD)
fori=1;i≤b;i++ do
forj=1;j≤h;j++ do
CRj(i)=X1(i)⨁LRj(i)
CGj(i)=Y1(i)⨁LGj(i)
CBj(i)=Z1(i)⨁LBj(i)
end
end
(X2(i)′,CRj(i)′)←DNA(X2(i),CRj(i))
(Y2(i)′,CGj(i)′)←DNA(Y2(i),CGj(i))
(Z2(i)′,CBj(i)′)←DNA(Z2(i),CBj(i))
forj=1;j≤h;j++ do
ifX2(i)′%3=0 then
RDD←Arnold(CRj(i)′+X2(i)′)
else ifX2(i)′%3=1 then
RDD←Arnold(CRj(i)′-X2(i)′)
else ifX2(i)′%3=2 then
RDD←Arnold(CRj(i)′⨁X2(i)′)
ifY2(i)′%3=0 then
RDD←Arnold(CGj(i)′+Y2(i)′)
else ifY2(i)′%3=1 then
RDD←Arnold(CGj(i)′-Y2(i)′)
else ifY2(i)′%3=2 then
RDD←Arnold(CGj(i)′⨁Y2(i)′)
ifZ2(i)′%3=0 then
RDD←Arnold(CBj(i)′+Z2(i)′)
else ifZ2(i)′%3=1 then
RDD←Arnold(CBj(i)′-Z2(i)′)
else ifX2(i)′%3=2 then
RDD←Arnold(CBj(i)′⨁Z2(i)′)
end
map操作中,split为数据分片,RDD表示明文或密文的弹性数据分布集,Arnold表示将加密像素点的每个位平面的比特位进行位置变换,DNA表示将伪随机序列和像素点转二进制后按照从规则1到规则8的顺序依次做相加、相减和异或的运算,运算法则同表2至表4,最后解码得到加密像素点。
4) 在输出阶段,调用PIL库中的fromarray函数将RDD数据处理为矩阵形式,将各分量的矩阵进行合并可以得到密文图像L′。
4 实验及结果分析
4.1 Spark平台环境及算法实现
Spark平台安装于VMware虚拟机中,共搭建了三个虚拟节点模拟集群效果。其中,两个节点作为Worker节点,用于并行处理明文图像分块后得到的Application数据块,另一个节点既作为Worker节点处理数据块,还作为Cluster Manager节点,负责监控管理Worker节点的状态,控制集群的运行,并获取各个节点的资源调度信息。
实验用物理机使用的处理器为Intel(R) Core(TM) i5-9300H CPU @ 2.40 GHz,物理机的内存大小为8 GB。虚拟机VMware版本为12.5.9,为了在不影响物理机性能的基础上最大化虚拟机性能,考虑将VMware中的每个虚拟机节点内存配置为1 GB,处理器个数设置为1,每个节点安装的操作系统版本为64位Linux Ubuntu 16.04.6,JDK采用了JDK1.8,Scala版本为Scala2.11.11,搭载的Hadoop版本为Hadoop2.7.3,使用Spark版本为Spark2.2.0。
对算法使用Python编程实现,其中需要调用PIL、numpy、matplotlib库进行图像处理。Spark启动后采用Standalone client模式调用Python程序,相较于Standalone cluster模式,Standalone client模式将任务进程驱动运行在客户端,便于对程序进行相关操作。
4.2 Spark平台运行效率分析
测试数据使用aerials标准测试图像,其中包括了Lena、Peppers、Lake、Baboon等常用于图像加密测试的图像,图像集中单幅图片大小为768 KB,分辨率为512×512。
在Spark集群中对多幅图片进行加密处理,记录处理过程所消耗的时间,同时在单机环境下对相同数量的图片进行加密处理,并记录所消耗的时间。将两种不同情况下图像加密处理所消耗的时间作对比,对比结果如图5所示。

图5 不同环境下图像加密的时间消耗
可以看出,当需要处理的图像数据量较小时,单机环境下所消耗的时间与集群并行环境下所消耗的时间差别很小,运行环境的差别对加密算法的效率影响很小。当图像数据量逐渐增大到20幅时,Spark并行环境下处理数据所消耗的时间要小于单机环境下的耗时,两者的时间差距也逐渐增大到约28 s。当使用分辨率更高、数据量更大的图片进行加密时,集群并行对于加密效率的提升会更加明显。
设置数据分片数为h=1,2,3,4,研究不同分片数对运行时间的影响,结果如表5所示。

表5 分片数对运行效率的影响
由表5可得,当分片数h取值越接近集群中Executor的数目,效率的提升越明显,用时越短,当分片数取值超过Executor的数目时,集群运行效率不再有显著提升。
4.3 NIST测试
对密文图像做NIST随机数测试可以判断密文图像像素点的随机程度。若得到的15项测试结果均大于1%,则表明密文图像像素点总体的随机性较好,复杂度较高[14]。
利用本文提出的基于Spark平台和三维动态整数帐篷映射的算法对图像Peppers进行加密,加密效果如图6所示。对得到的Peppers密文图像的RGB各通道做NIST测试,测试结果如表6所示。
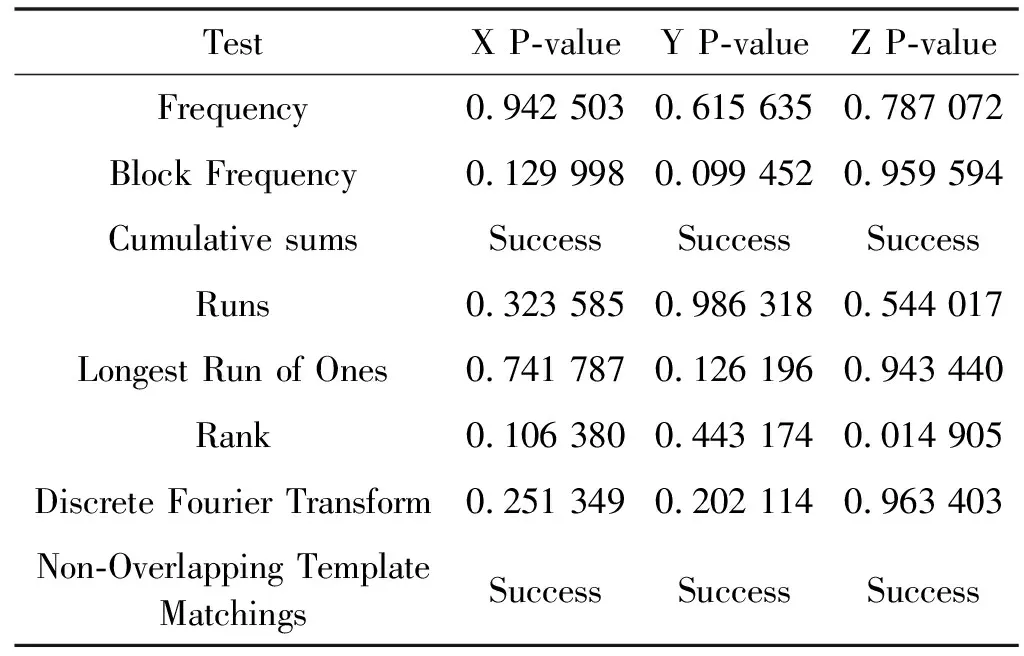
表6 Peppers密文RGB通道NIST测试

图6 Peppers明文图像和密文图像
由表6可得,明文图像经过Spark并行加密处理后,得到的密文图像的RGB各通道像素值均可以通过NIST测试,各项测试的P-value值均在1%以上,说明密文图像具有一定的安全性。
4.4 直方图分析
通过图像直方图可以分析密文图像中灰度值的分布情况,进而分析加密算法对图像的置乱程度,评估密文图像所包含的信息量。对明文Peppers和密文Peppers的RGB各通道进行直方图分析,分析结果如图7至图8所示。

(a) 明文R分量直方图

(a) 密文R分量直方图
可以看出,Peppers明文图像的直方图落差较大,说明明文图像中像素点的分布包含了较多的信息量,不同数值的像素点分布不均匀。经过Spark平台加密处理后,得到的密文图像直方图较为均匀,各个像素点被置乱,明文信息被隐藏到置乱的像素点中。
4.5 信息熵分析
通过对图像进行信息熵测试,可以分析图像的置乱程度。理想的信息熵值为8,计算结果越接近8,图像整体的混乱程度越高,各像素点的排列越接近于无序[15-16]。信息熵定义为:
(6)
式中:p(Ai)表示序列A中第i个数出现的频率。
利用式(6)分别计算Peppers明文图像和Peppers密文图像RGB各通道的信息熵值,计算结果如表7所示。
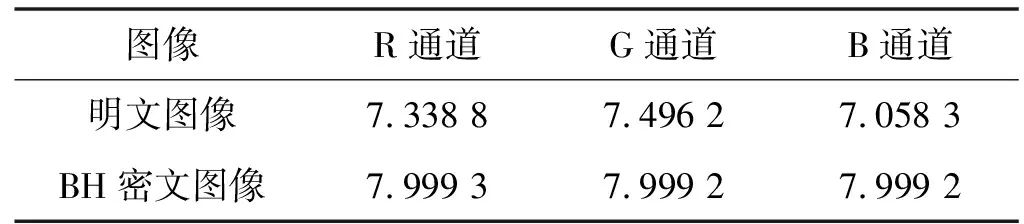
表7 Peppers明文图像和密文图像信息熵
分析表7结果,相对于明文图像,密文图像的计算结果更趋近于理想值,说明密文图像达到了理想的置乱效果。
5 结 语
本文提出一种以三维动态整数帐篷映射为伪随机序列发生器,基于Spark大数据平台运行的混沌并行图像加密算法。研究的主要目的在于解决大数据安全问题,同时提高加密算法的运行效率。实验研究表明,三维动态整数帐篷映射的引入使得密文图像具有良好的安全性,Spark大数据平台的引入显著提升了大数据量图像信息的加密效率。
本文方法针对Spark大数据平台的安全问题以及图像加密的效率问题提出,但不局限于Spark平台,在Hadoop、Storm等平台中也有一定的适用性,在海量机密图像数据的高效加密和安全传输方面具有一定的应用前景。
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
阅读(低年级)(2019年2期)2019-04-19 09:54:46
火控雷达技术(2018年4期)2019-01-15 05:07:22
民间故事选刊·上(2018年1期)2018-01-02 20:41:38
小小说月刊·下半月(2016年6期)2016-05-14 15:23:24
火控雷达技术(2016年1期)2016-02-06 02:18:04
中国资源综合利用(2016年11期)2016-01-22 02:01:25
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:20
