
融合深度去噪自编码器和注意力机制的推荐算法
2023-09-04 09:31张卫国袁炜轩周熙然
计算机应用与软件 2023年8期
张卫国 袁炜轩 周熙然
(西安科技大学计算机科学与技术学院 陕西 西安 710000)
0 引 言
21世纪以来,随着科技的蓬勃发展,信息量与日俱增,人们很难找到自己真正需要的信息,这就是数据过载[1]问题。为了解决这个难题,研究人员建立推荐系统来帮助用户挖掘自己感兴趣的东西,近年来学术界对其展开了较为深入的研究,并广泛应用于工业界。20世纪90年代,Goldberg等[2]第一次提出协同过滤(CF)的方法,旨在为用户提供有用的数据参考从而解决数据冗余问题,协同过滤推荐由于其具有良好的可解释性和高效的实时个性化推荐而受到国内外专家学者的广泛关注。例如,Sarwar等[3]提出了奇异值分解(SVD)的方法,该方法通过构造用户和项目的交互矩阵来表示用户与项目的交互历史,具体是将复杂的用户项目评分矩阵分解成若干个简单的用户和项目矩阵;Deshpand等[4]提出了基于项目的k近邻算法(ItemKNN),该算法先计算目标用户已交互项目与未交互项目的余弦距离以得到项目间的相似度,再根据相似度将未交互的项目推荐给用户;Ning等[5]提出了稀疏线性算法(SLIM),该算法不用直接计算项目间的相似度而是通过模型训练的方式得到项目相似度矩阵,通过更新项目相似度矩阵得到最终项目间的相似度;Kabbur等[6]提出了基于项目相似度的推荐算法(FISM),该算法利用用户的历史交互信息来间接表示用户的潜在兴趣,将矩阵分解技术与基于项目相似度的算法相结合。由于自编码器神经网络不仅可以对高维数据进行降维和压缩操作,还可以学习到目标的深层特征,因此常被用来提取目标的隐含特征。近些年基于自编码器神经网络的推荐算法也层出不穷,Sedhain等[7]提出了一种基于自编码器的推荐算法(AutoRec),首次将自编码器与推荐算法结合,利用机器学习中的梯度下降法更新参数使得误差逼近最小值,实验验证了该算法更具高效性。
然而,基于自编码器的推荐算法仅仅使用单一的自编码器网络来进行推荐,没有与现有的推荐算法相结合[8],于是国外专家学者们开始尝试将自编码器融入到已有的算法中[9-11]。国内方面,霍欢等[12]提出了融合标签内容和栈式去噪自编码器的协同过滤推荐算法(DLCF),将栈式去噪自编码器融入到基于标签内容的协同过滤推荐算法中,解决了原始评分矩阵稀疏的问题;张杰等[13]提出了一种混合神经网络模型,通过栈式去噪自编码器与深度神经网络相结合的方式计算用户与项目的隐含特征向量,提高了传统推荐算法的精度;王东等[14]提出了一种融合自编码器和物品固有信息的推荐算法(AutoFISM),先用自编码器提取物品的低维非线性特征再融入到矩阵分解算法中,缓解了传统FISM的冷启动问题;方义秋等[15]提出了一种结合商品评分信息的多重去噪自编码器(MDAE),原始的评分矩阵经过多重去噪处理可以有效提高原算法的鲁棒性,解决了传统DAE算法精度不高的问题;杨丰瑞等[16]提出了一种融合去噪自编码器和社交网络信任关系的混合推荐算法,先利用去噪自编码器提取用户项目的隐含特征向量,再通过建立信任模型学习目标用户与其信任用户的兴趣偏好,最后根据用户兴趣聚类并分配不同的推荐权重进行推荐,该推荐方法更具解释性,用户满意度会更高。
本文则改进传统自编码器结构并融入基于项目相似度的协同过滤算法,主要贡献为以下三个方面:
(1) 构建改进的深度去噪自编码器网络。改进了传统自编码器的网络结构,将原三层自编码器网络增加为六层深度自编码器网络,并加入符合高斯分布的噪声并做去噪处理,进一步提升原传统自编码器网络的泛化能力和鲁棒性从而进一步提高推荐准确性。
(2) 挖掘并学习原始评分数据的非线性与线性特征。将原始的用户项目评分矩阵输入到改进的深度去噪自编码器网络中,学习用户与项目的非线性隐含特征;再将降维后的低维非线性隐含特征融入到基于项目相似度的协同过滤推荐算法中去,挖掘用户与项目的线性隐含特征,同时为了体现不同历史交互间的区别加入了注意力机制,惩罚活跃用户带来的影响。
(3) 实验对比多种推荐算法并在MovieLens和Pinterest数据集上进行实验分析。实验结果表明,相比传统推荐算法和近些年较新算法,该算法能够显著提升传统推荐算法的准确性,进一步提高推荐精度和用户满意度。
1 相关研究
1.1 基于模型的协同过滤算法
奇异值分解技术是一种典型的基于模型的推荐算法,该算法是将一个复杂矩阵分解成两个及两个以上简单矩阵乘积的过程,如式(1)所示。
(1)
将奇异值分解技术应用于实际电影推荐时,可能会出现某些用户评分标准过于严格的情况,该类用户不愿意给出高分,或者某部电影拍得很差,评分普遍都很低,这些情况会干扰预测缺失的评分值,从而导致推荐结果不准确。为了解决这个问题,考虑在原矩阵分解模型的基础上增加偏置项,如式(2)所示。
(2)
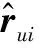
(3)
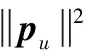
1.2 基于最近邻的协同过滤算法
基于最近邻的推荐算法可以根据用户和项目两个属性进行划分。其中,基于项目的推荐算法先计算项目间的相似度,再按照相似度的高低给目标用户推荐;同理,基于用户的协同过滤算法先计算用户间的相似度,再将与目标用户相似的用户所感兴趣的项目根据项目评分的高低推荐给目标用户。
由于不同人的兴趣存在各种差异,众口难调,即使给有相似行为的用户们推荐同一个物品,也很难满足不同人的需求,而且在实际推荐过程中很多用户的信息可能缺失或无法获取。因此,基于用户的协同过滤算法无论在可解释性上还是实际应用的效果远不如基于项目的协同过滤算法。
稀疏线性算法(SLIM)是一种典型的基于项目的推荐算法,项目间的相似度计算如式(4)所示。
(4)
式中:Sij为项目i和j的相似度;ri和rj分别为项目i和项目j的评分。SLIM的评分预测模型和损失函数分别如式(5)和式(6)所示。
(5)
(6)
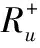
1.3 基于自编码器的推荐算法
鲁梅尔哈特等首次提出自编码器网络结构,用于对高维数据降维操作,以学习高维稀疏数据的深层特征。自编码器是一种特殊的神经网络,在数据输入到模型前建立编码器进行压缩处理,利用反向传播算法通过解码器将压缩处理好的数据重构原始输入,最后通过对模型增加约束,可以学习到输入数据的深层隐含特征。
基于自编码器的推荐是将高维稀疏的原始用户项目评分矩阵映射到低维空间压缩处理后再映射到正常空间,根据自编码器输入值和输出值无限接近的原理,重建出用户对未交互项目的评分值。
图1为传统自编码器的网络结构,编码部分如式(7)所示,从输入层x到隐藏层,该部分将高维稀疏的用户项目评分矩阵映射到低维空间进行降维压缩操作,并计算出用户的隐含特征向量y;解码部分如式(8)所示,从隐藏层到输出层r,该部分通过隐含特征向量y重构输入,以补全缺失的评分矩阵,从而完成对缺失评分的预测。
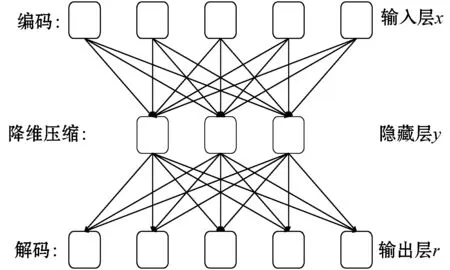
图1 传统自编码器网络结构
y=f(w1·x+b1)
(7)
r=g(w2·y+b2)
(8)
式中:y为输入数据的隐含特征向量;w1和w2分别为编码和解码的权重;b1和b2分别为编码和解码的偏移量;f(·)和g(·)为编码和解码的激活函数;r为经自编码器重构后的预测评分。
2 算法设计
传统协同过滤算法中用户与项目的隐含向量是随机初始化的,然而现实中的项目存在很多模型学习不到的非线性特征,因此考虑使用自编码器网络来提取项目的非线性特征,并融入到基于项目相似度的协同过滤算法当中,以提高该模型的准确度。
2.1 改进的六层深度去噪自编码器网络
为了进一步提高传统自编码器模型的泛化能力和鲁棒性,本文将原传统三层自编码器的网络结构扩展为六层如图2所示,这样可以使得反向传播算法可以适应复杂特征模式的表示和学习,有效缓解过拟合等问题。

图2 改进的六层深度去噪自编码器网络结构
(1) 编码阶段:x1为原始用户项目评分矩阵,在x1中加入符合高斯分布的噪声,且加噪率ρ∈[0,1],图中黑色数据为加入的高斯噪声。加入高斯噪声后为了保证原始评分矩阵的期望值无变化,需要对原始用户项目评分矩阵做归零操作,具体是将评分矩阵中包含ρ噪声数据的概率置为零,即将除噪声外的数据放大1/(1-ρ)倍,x2为最终加噪处理后的用户项目评分矩阵,如式(9)所示。
x2={x2|x2=x1/(1-ρ)}
(9)
(2) 解码阶段:加噪后的高维用户项目评分矩阵经隐藏层y压缩降维后得到低维评分矩阵x5,x5经三层解码器重构出与原始评分矩阵相同规模的最终输出矩阵x7。
根据输入的原始评分矩阵x1与输出的重构矩阵x7重构两者间的误差,实验采用随机梯度法来最小化损失函数,改进后的深度去噪自编码器的目标函数如式(10)所示。
arg minl(x1,x7)+R(w1,w2,b1,b2)
(10)
(11)
式中:l(x1,x7)为损失函数,R(w1,w2,b1,b2)为正则项,控制模型的复杂度。本实验编码与解码采用全连接层,改进后的深度去噪自编码器相对于传统的自编码增加了深度,可以有效提高该模型训练的鲁棒性。
2.2 用户项目评分矩阵的线性与非线性特征
传统推荐算法对目标项目i的隐含特征向量是随机初始化的,本文首先通过改进的深度去噪自编码器网络来学习用户项目评分矩阵的非线性特征。我们将原始用户项目评分矩阵输入到改进的深度去噪自编码器网络中,即将高维稀疏的评分数据降维操作,如式(12)所示。
(12)
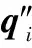
(13)
其次,通过基于项目的协同过滤算法来挖掘用户项目评分矩阵的线性特征。这里的协同过滤算法模型我们以FISM为优化目标,FISM是一种基于项目的协同过滤算法,属于LISM的增强版,它根据用户已交互项目的隐含特征向量来重构矩阵分解中用户的隐含特征,项目间的相似度是通过项目间的隐含特征向量的内积来计算的,该模型如式(14)所示。
(14)
2.3 算法模型
融合深度去噪自编码器的协同过滤模型既可以利用去噪自编码器提取项目的非线性特征又可以利用基于项目相似度的协同过滤算法提取线性特征,深度去噪自编码器可以充分挖掘用户和项目的非线性特征,在FISM模型中融入深度去噪自编码器如式(15)所示,通过用户已交互的项目来表示用户的隐含特征,在一定程度上可以缓解冷启动问题。
(15)
虽然融合深度去噪自编码器的FISM可以有效挖掘用户的隐含特征,但是没有体现出不同历史交互项目间的区别,例如预测某用户对某灾难片的偏好时,历史交互中灾难片的权重理应更高,而预测该用户对古装片的偏好时,历史交互中灾难片的权重理应变低,用户的历史已交互项目对目标项目的影响也有所不同。
因此,为了突显不同历史已交互项目对目标项目的影响不同,在融合深度去噪自编码器的FISM中加入注意力权重Wij,通过神经网络的注意力机制来解决FISM的这种局限性,并结合深度去噪自编码器来学习原始项目的非线性特征,得到融合深度去噪自编码器和注意力机制的项目相似度推荐算法如式(16)所示。
(16)
(17)
式中:{i}为已交互项目中去除掉目标项目i;Wij是一个可训练的参数,表示预测用户u对目标项目i的偏好时项目j的attention权重;ξ为平滑指数,ξ∈(0,1],当ξ=1时,该公式为softmax函数,可对权重进行归一化,当ξ<1时,活跃用户不会被过度惩罚。
本文注意力机制主要用于计算项目相似度,将目标项目i与已交互项目j特征向量的点积输入到注意力模型训练得到权重Wij,模型采用SeLU(缩放指数线性单元)激活函数和交叉熵损失函数,并通过MLP网络和随机梯度法更新参数,该注意力函数和损失函数如式(18)-式(19)所示。
(18)
(19)
式中:w为输入投影到隐藏层的权值矩阵;b为偏移量;N为训练集个数;δ为用户u将和目标项目i可能产生交互的概率;λ为正则项系数。
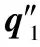
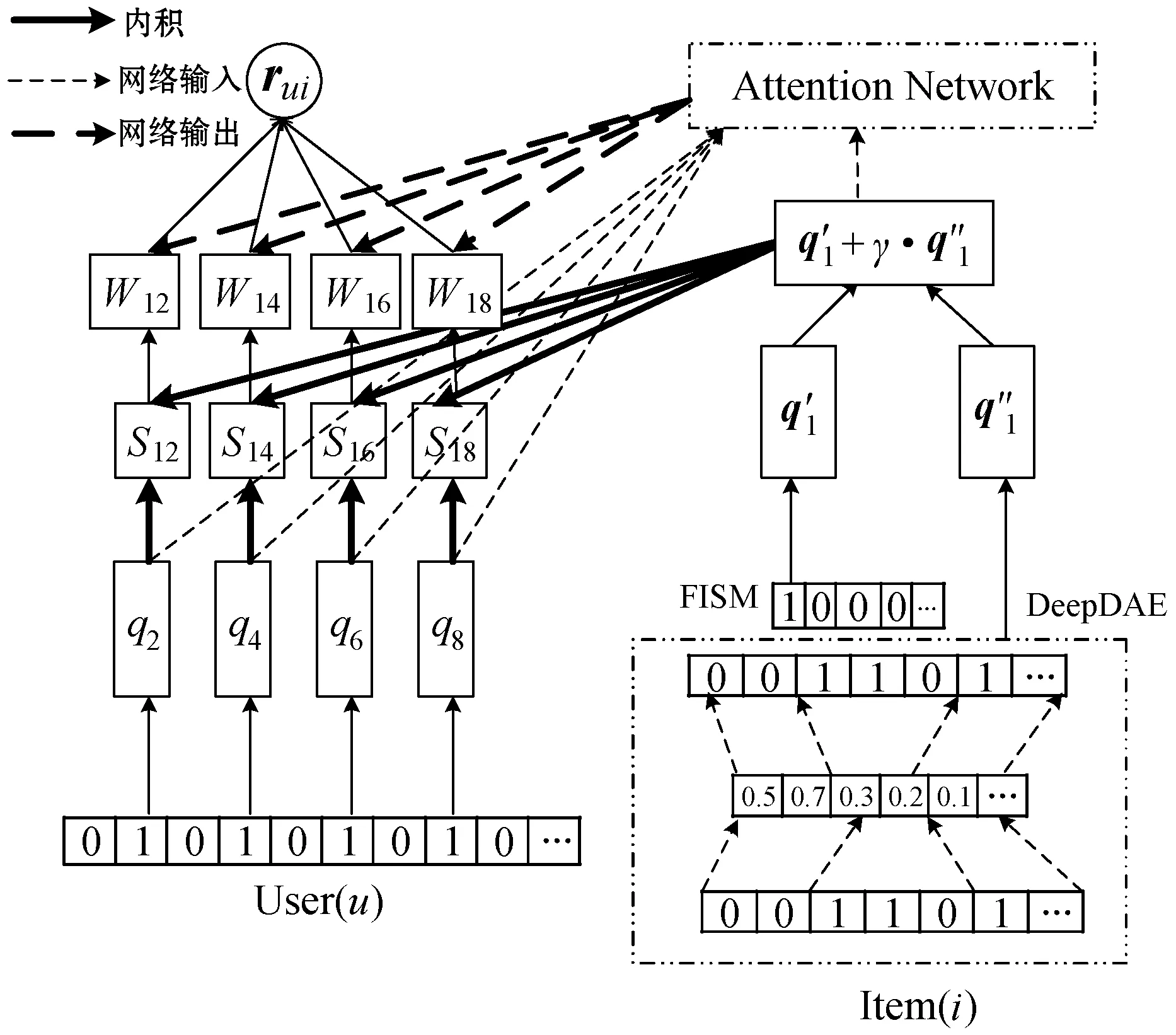
图3 融合深度去噪自编码器和注意力机制的推荐算法模型
3 实验与结果分析
3.1 实验数据集
实验选取推荐领域常用公开数据集MovieLens数据集和Pinterest数据集,MovieLens是一家专门统计用户对电影的影评并提供电影推荐的网站;Pinterest是一家基于图片推荐的网站,用户可以将感兴趣的图片发布到该网站上。其中MovieLens-1M数据集是由6 040个用户和3 706个电影组成,影评数高达到一百万条,评分值为1-5分。为了体现用户与电影相互的情况,需要对MovieLens数据集进行预处理操作,具体是将用户电影交互矩阵中的显式评分转换为隐式评分,如果用户与电影之间有过交互行为的设为1,反之设为0。实验环境参数和数据集的信息统计情况分别如表1和表2所示。
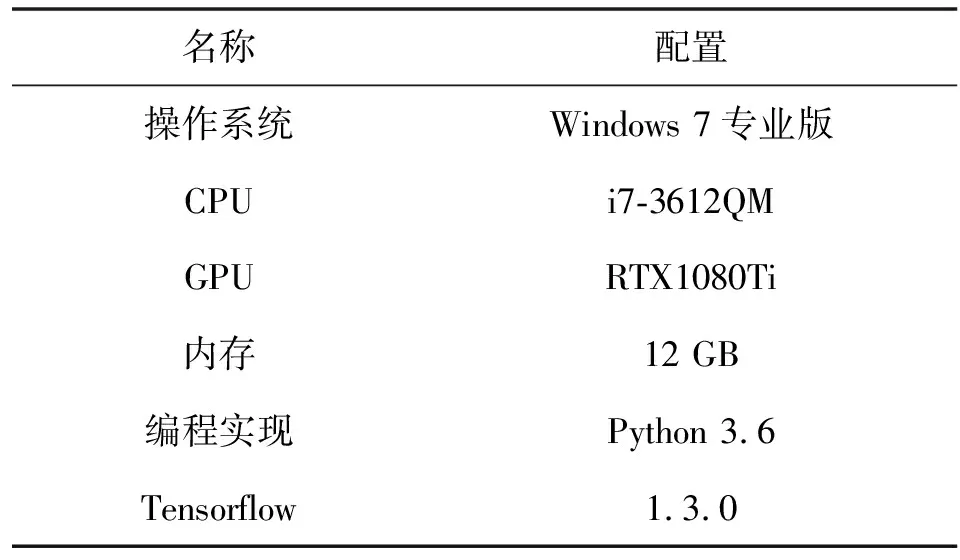
表1 实验环境参数
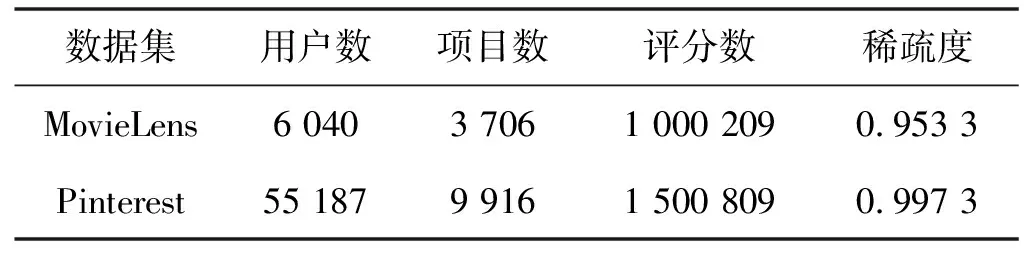
表2 实验数据集
3.2 评价指标
为了评价推荐模型的性能,本实验用到推荐系统常用评价指标归一化折损累计增益(NDCG)和命中率(HR)。在生成推荐列表时,列表中项目的排名顺序能充分反映用户可能感兴趣的程度。推荐列表的排名情况用累积增益CGn表示如式(19)所示,由于实际推荐需要将推荐相关性高的结果排在前面,因此需要在CGn的基础上引入位置影响因素,用折损累积增益DCGn表示如式(20)所示,推荐列表中用户返回的最佳推荐结果即DCGn的最大值用IDCG表示,需要对其做归一化处理,则最终的归一化折损累积增益(NDCG)如式(21)所示。
(20)
(21)
(22)
命中率HR为最终推荐列表中的项目占总测试集的比例,如式(22)所示。命中率越高说明推荐结果越准确,越能符合用户的兴趣和需求。
(23)
3.3 实验设置
实验采用留一交叉验证的方法,将每个用户最近的一条交互数据作为测试集,剩下的所有交互数据作为训练集。具体是将每个测试集与99个随机采样的训练集组合,每个算法都将输出对100个电影的预测分数,最后每个测试集由HR和NDCG来判别。实验参数设置为隐含向量的维度k=16,平滑指数ξ=0.5,λ=0,为了评价本文算法的性能,实验对比了以下方法:
(1) ItemPOP:基于项目流行度的推荐算法。该算法以项目的流行度作为判断标准,越流行的项目越容易受到关注和推荐。
(2) SVD[3]:奇异值分解又叫矩阵分解。该算法将复杂的用户项目评分矩阵分解成若干个简单的用户和项目矩阵。
(3) ItemKNN[4]:基于项目的k近邻算法。该算法计算用户已交互项目与未交互项目的余弦距离得到项目的相似度,根据项目相似度推荐项目。
(4) SLIM[5]:稀疏线性推荐算法。该算法不用直接计算出项目的相似度而是通过模型训练的方式得到项目相似度矩阵,最终间接得到项目间的相似度。
(5) FISM[6]:基于项目相似度的推荐算法。该算法利用用户的历史交互信息来表示用户的兴趣特征,将矩阵分解应用到了基于项目的协同过滤算法中。
(6) eALS[11]:基于元素的交替最小二乘推荐算法。该算法同时考虑了用户和项目两个属性,既可以基于用户推荐又可以基于物品推荐。
(7) BPR[17]:基于贝叶斯的推荐算法。该算法利用了贝叶斯后验的知识对用户自身感兴趣的项目进行排序并推荐。
(8) NAIS[18]:基于神经网络的项目相似度推荐算法。该算法是目前最先进的基于项目相似度算法,属于FISM的增强版,比FISM更具表现力。
3.4 算法性能分析
为了便于直观比较各算法的性能,实验将上述所有算法隐含向量的维度都设为16,本文从多个方面进行实验分析。
3.4.1模型训练分析
为了充分说明本文注意力机制的有效性,实验选取FISM算法为基线算法,对比了本文算法(Ours)与本文无注意力机制的算法(DAE+FISM)在两个不同数据集上前50次迭代训练的结果。
图4展示了两个不同数据集下算法的迭代性能,由于注意力模型的参数需要学习,因此在前5次迭代过程中,DAE+FISM要优于本文算法,但在随后的迭代过程中,本文算法均优于DAE+FISM,两种算法的迭代曲线均位于FISM算法之上,性能明显优于传统FISM。以MovieLens数据集为例,在最优情况下本文算法比DAE+FISM在HR@10上提升1.51%,NDCG@10上提高2.12%,前10次训练快速迭代收敛,之后缓慢上升直至趋于平稳,随着训练迭代的逐步进行,本文模型性能更优更稳定,证明引进该注意力机制可以有效提高推荐性能。

(a) MovieLens前50次迭代的结果
3.4.2各算法性能分析
实验将上述所有算法隐含向量的维度都设为16,分别计算出推荐个数为5和10条件下的NDCG和HR,上述算法在MovieLens和Pinterest数据集下NDCG和HR评价指标的条形对比情况如图5和图6所示。

图5 MovieLens数据集下各算法的HR和NDCG

图6 Pinterest数据集下各算法的HR和NDCG
以MovieLens数据集且在推荐个数为5和10的条件下为例,本文算法的推荐命中率(HR)上要比SVD算法分别提升14.16%和13.45%,比FISM算法分别提升4.2%和4.25%,比NAIS算法提升1.4%和1.27%。本文算法的归一化折损累计增益(NDCG)上要比SVD算法分别提升15.23%和12.67%,比FISM算法分别提升4.28%和2.76%,比NAIS算法提升1.55%和0.44%。
为了充分反映本文算法的先进性,本实验选取了多个推荐算法进行对比,以SVD、FISM、NAIS和DAE+FISM为代表,无论是在MovieLens数据集还是Pinterest数据集下本文算法在NDCG@5、NDCG@10与HR@5、HR@10推荐性能指标上能明显优于经典的SVD算法和著名的FISM算法,且优于目前最新算法NAIS和DAE+FISM,可以充分说明注意力机制的有效性和本文算法的先进性。
4 结 语
本文首先改进了原传统三层自编码器的网络结构,改进后的六层深度去噪自编码器可以有效地提高传统自编码器网络的泛化能力和鲁棒性。通过深度去噪自编码器学习原始项目的隐含特征,将原始用户评分矩阵作为该深度去噪自编码器的输入,减少了原始评分矩阵稀疏的影响,解决了数据稀疏等问题。再将降维压缩后的低维项目隐含特征融入到基于项目相似度的推荐算法中,通过分析用户已交互项目来构建用户的隐含特征向量,这样既可以获取项目的线性特征还可以挖掘到项目的非线性特征,缓解了推荐系统的冷启动问题。同时为了突显不同历史已交互项目对目标项目的不同影响加入了注意力机制,以惩罚活跃用户对实验结果的影响,极大地提高了推荐算法的鲁棒性同时提升了推荐的效率。然而本文算法只涉及到用户项目的交互信息并未利用到年龄、性别等用户的固有属性。因此,未来的研究工作可以从用户项目多样性出发,考虑加入兴趣迁移模型和语义分析等模型进一步提高算法的推荐准确性。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
成都信息工程大学学报(2018年3期)2018-08-29
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
电子设计工程(2017年20期)2017-02-10
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
电子器件(2015年5期)2015-12-29
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
