
基于ResNet的彩色眼底图片分类算法研究
2023-09-04 09:22:54陈亚浩
计算机应用与软件 2023年8期
陈亚浩 张 东
(郑州大学河南省超级计算中心信息工程学院 河南 郑州 450000) 2(浪潮电子信息产业股份有限公司 山东 济南 250101)
0 引 言
视觉信息是人类获取外部信息的主要来源,感知外部世界的大部分信息都要靠眼睛。目前,世卫组织已经确定眼部的健康与否是人类三大生存质量问题之一[1]。眼部疾病的不可逆失明问题严重影响了人们的生活质量。随着医学影像分析算法的不断发展,计算机算力、存储能力的不断增强,通过对彩色眼底图像的分析,可以尽早预防因糖尿病、青光眼、白内障、许多其他原因引起的眼部疾病。现阶段,通过彩色眼底图片进行眼部疾病筛查的主要方式还是依赖医生的人工判断,此项工作不仅耗时耗力,而且对医生的临床经验要求极高。因此,用有效的方法检测眼部疾病是一个很有现实意义的课题。
在深度学习出现之前,传统的图像分类[2]识别算法在实施的过程中比较繁琐、效率低下、准确率不高,同时很多方法具有一定的局限性,近年来,卷积神经网络得到了研究人员的广泛关注,并且提出了Alexnet[3]、GoogLeNet[4]、ResNet[5]、VGG[6]等先进模型,此类模型能够从大量的样本中自动学习有用特征,具有较高的准确率。针对眼底彩照的分类识别任务,很多学者基于卷积神经网络尝试了各种方法并取得了一定的研究成果。丁蓬莉等[7]提出CompactNet对眼底图像进行识别分类,但由于实验样本有限,网络在训练的过程中并没有充分提取到相关特征,导致特征丢失,因此分类准确率并不高。庞浩[8]提出了一个多分支结构的卷积神经网络用于彩色眼底图像分类,主要将GoogleNet、VGGNet等作为特征提取网络,然后紧接着使用一个两级CNN对提取的特征进行分类从而实现对彩色眼底图像的检测。Raghavendra等[9]设计一个 18 层的卷积神经网络,经过有效训练提取特征之后进行测试分类。Chai等[10]提出一种多分支神经网络(MB-NN)模型,利用该模型从图像中充分提取深层特征并结合医学领域知识实现分类。徐至研[11]提出的双模态深度学习卷积神经网络模型将年龄相关性黄斑病变的二分类准确率提高至87.4%。黄潇等[12]提出的基于Inception-v3与SVM 结合的机器学习算法将眼底彩照二分类准确率提高至90.22%。
目前彩色眼底图像的分类工作已经有了比较深入的研究并且取得了不错的成果,但是在病变分类准确率方面依旧达不到临床要求。因此,本文提出一种基于深度残差网络的眼底彩色图像分类识别算法,为了提取更具有代表性的特征,对彩色眼底图像进行DSP-Fs眼底彩照数据集预处理流程,使用拉普拉斯滤波突出不同眼底彩色图片的特点,然后选择ResNet50作为主干网络结构,通过改进和微调实现对眼部疾病患者和正常人眼底图像的判别。该算法与其他的分类识别算法相比,具有更好的分类识别效果。
1 彩色眼底图像分类识别算法
本文提出一种基于ResNet的眼底彩色图像分类识别算法,整体的框架如图1所示,该算法由三部分组成:基于DSP-Fs的彩色眼底图像预处理、基于ResNet的特征提取和眼底彩照自动进行正异常分类。

图1 彩色眼底图像分类流程
在本文对彩色眼底图像判断是否正常的二分类任务中,第一步是对图像进行预处理操作。采用的是DSP-Fs预处理流程,将其处理结果作为深度残差网络的输入,提取深层次的特征,最后将提取到的特征送入分类器进行最后的分类,从而实现彩色眼底图像的正异常识别。
1.1 基于DSP-Fs的图像预处理
由于获取的原始数据集存在镜头污染、尺寸不统一、背景过多、样本分布不均匀等问题,若直接将数据集输入模型进行训练,所得结果将不仅没有研究价值而且没有意义。因此为了使此研究更有研究价值,训练模型能够获得更高的准确率,就需要对原始眼底彩色图片数据集进行诸多步骤的预处理操作。本文提出针对彩色眼底图像的DSP-Fs预处理流程,具体如图2所示。其预处理步骤为:首先对图片进行D处理操作:将无使用价值的眼底彩照从原始数据集中删除,如图3(a)所示;然后进行S化处理:将数据集中所有图片中的眼球做外切裁剪处理,如图3(b)所示;再使用opencv对图片S化处理之后的方形图片进行224×224、448×448,或者N×N多种规格的图片压缩处理,如图3(b)所示;最后压缩处理后的图片进行多维度滤波器图形图像处理,结果如图3(c)所示,(目前在Fs盒中我们加入了Laplacian、锐化滤波、黑白二值、黑白二值反转等滤波)。

图2 预处理流程

(a) D处理
1.2 Laplacian滤波
在1.1节关于眼底图像的预处理过程中,采用Laplacian滤波[12],运用拉普拉斯算子来增强图像的细节,找到图像的边缘。面对有噪音增强的情况,我们可以在图片锐化前对要使用的图像进行平滑处理。Laplacian滤波与图像某个像素的周围像素到此像素的突变程度有关。
拉普拉斯算子定义:
(1)
该二阶导数近似为:
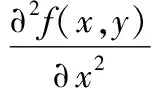
(2)

(3)
因而有
▽2f=[f(x+1,y)+f(x-1,y)
f(x,y+1),f(x,y-1)]-4f(x,y)
(4)
通过卷积图像,该表达式可在图像中的所有点(x,y)处实现:
(5)
至于对角线元素,可用以下掩模来实现:
(6)
用来增强图像的拉普拉斯算子基本公式如下:
g(x,y)=f(x,y)+c[▽2f(x,y)]
(7)
式中:f(x,y)为输入图像;g(x,y)为处理后增强的图像;若掩模的中心系数为正,我们取c=1,若不为正,我们取c=-1。经过微分运算,图片常量区域转化为0,同时使图片锐化。
1.3 基于RestNet的图像特征提取网络
众所周知,在深度学习技术不断发展的今天,许多网络结构在ImageNet竞赛中脱颖而出,取得了令人瞩目的成绩,例如VGGNet、Google、NetResNet等。其中,作为里程碑式模型的ResNet一经出世,就在竞赛中获得了图像分类、定位、检测三个项目的冠军。同时近些年来,ResNet网络在工业中的应用日渐成熟,应用领域也在逐步扩大,所以,本文算法的主干网络选用ResNet,实现对眼底彩色图片进行特征提取。
ResNet最主要的贡献在于提出的残差学习的思路,这种残差结构解决了梯度在深度网络中方向传播时可能会遇到的梯度消失的问题[13]。即便是非常深的网络也能够得到很好的训练,而且层数加深之后网络的效果更好。残差学习单元改变了ResNet网络学习的目标,网络中直连通道的加入,使原始输入的信息允许直接传到后面层中。假设卷积神经网络的输入是x,经过处理后输出H(x),如果将x传入输出作为下一段网络的初始结果,我们学习的目标就变为F(x)=H(x)-x,具体如图4所示。

图4 ResNet的残差学习单元
ResNet有不同的网络层数,在本文中,主要选择了ResNet34、ResNet50、ResNet101作为主干网络来进行眼底图像的特征提取效果对比。它们具体的网络结构如表1所示。
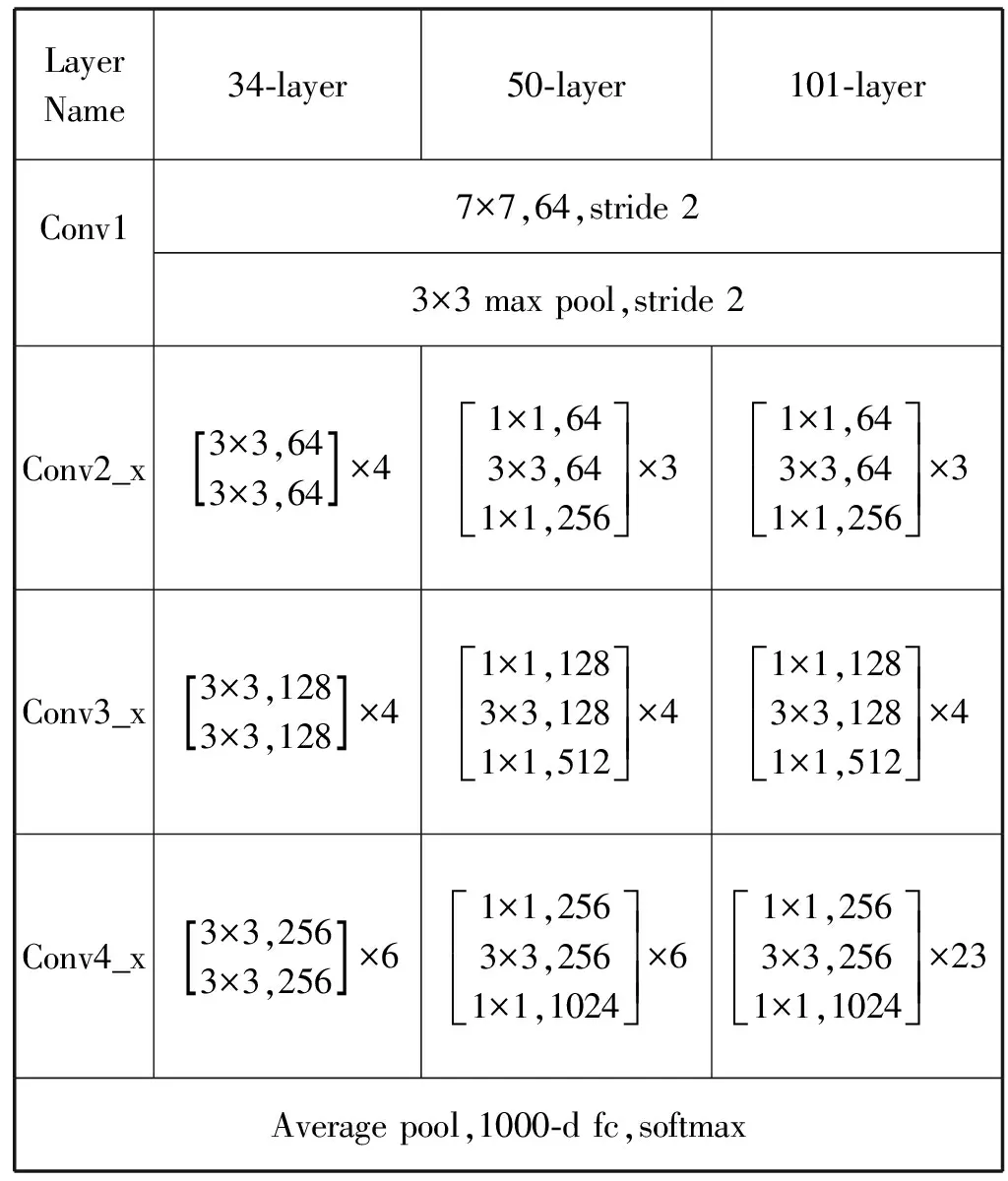
表1 不同层数时的网络配置
针对具体的彩色图像的分类识别任务,将最后全连接层改为两个神经元,然后送入分类器,便于后续的分类。
2 实验与分析
本实验依托于河南省超级计算机中心,采用目前主流的深度学习框架Pytorch作为开发环境,硬件配置为:GPU:Nvidia GeForce GTX 1660,内存:24 GB,显存:6 GB。软件环境:CUDA10.2,CUD NN7.6,Python 3.6。
实验中所使用到的数据集为北京大学“智慧之眼”国际眼底图像智能识别竞赛公布的眼底彩照数据集(ODIR-5K),包含5 000名患者双眼的彩色眼底照片及医生的诊断关键词。其结构化眼科数据示例如图5所示,具体分为8个类别。其中:N代表正常眼底;G代表青光眼;D代表糖尿病病变;C代表白内障;A代表黄斑性病变;H代表高血压;M代表近视;O代表其他病变。但是由于眼底病变因素太多,难度较大,目前本文实现的是眼部疾病患者和正常患者的分类识别,所以要对标签进行预处理,变成二分类问题。标签0表示正常眼睛,标签1表示病变眼睛。数据集中彩色眼底图像如图6所示,图6(a)表示正常眼底,图6(b) 表示异常眼底。

图5 结构化眼科数据示例

(a) 正常眼底
实验中所采用评价指标一律采用训练集损失(train_loss)、验证集损失(valid_loss)、错误率(error_rate)和单位训练时间四项指标对实验内容进行综合评价。其中,loss值代表的是模型的收敛程度,loss值越小,预测值和标签就越接近,错误率也就越小。单位训练时间指的是模型训练一个循环所需要的时间。
为了对比不同网络结构对分类精度的影响,实验分别使用ResNet34、ResNet50、ResNet101对预处理之后的数据集进行训练,其中预处理只包含最基本的筛选、裁剪、压缩等。表2为不同模型下结果。

表2 不同模型下的实验结果
可以看出,随着网络层数的不断加深,训练集和测试集的loss值在不断减小,错误率也在不断下降,最终达到了0.860 8的准确率,说明模型收敛的效果越来越好,分类的准确率也越来越高。但是,网络层数越多,相应网络的复杂度也就越高,训练时长有所增加。在相同条件下,就分类效果而言,选择深度神经网络的分类结果要较好于浅层神经网络,但是由于硬件性能原因,最终选取ResNet50作为本次实验的特征提取网络。
为了验证不同尺寸的图片对分类效果的影响,保持ResNet50模型不变,分别使用224×224、448×448的图片输入进行训练,在进行了100次训练之后,表3为实验结果。

表3 不同图片尺寸下的实验结果
由表3中的两组实验结果对比可知,在同一训练方式、硬件允许且网络模型合适的条件下,图片的尺寸越大,网络提取到的特征越丰富,分类的效果也就越好,所以,本次实验选取448×448的图片作为网络的输入。为了验证Laplacian滤波分类效果的影响,本组实验在ResNet50模型,分别使用Laplacian滤波处理过的图片和没有经过Laplacian滤波处理的图片作为输入进行训练。未经过Laplacian滤波处理的图片如图7(a)所示,处理之后的效果如图7(b)所示。经过了100轮的迭代训练之后得到的结果如表4所示。

表4 不同预处理下的实验结果

(a) 原始图片
可以看出,由于经过Laplacian滤波处理过的图片变为单通道,训练的时间明显少于没有经过Laplacian处理的训练时间,错误率也有一定程度的减小,故而由此可得,Laplacian滤波在一定程度上能够降低网络模型训练的时间复杂度,并且能减少错误率,提高分类精度。
对本文算法的有效性进行进一步验证,首先保证实验环境相同,预处理环节一致的情况下,对不同的识别方法进行对比实验。表5总结了不同方法的分类准确率。

表5 不同方法的分类准确率
由表5中的实验结果可知,与其他模型相比,本文提出的对原始图片首先经过DSP预处理之后,再进行Laplacian滤波处理后输入模型进行训练的方式能够获得较高的准确率。
3 结 语
针对彩色眼底图片的分类识别问题,本文提出一种基于ResNet的自动分类识别算法,该算法首先对原始彩色眼底图片进行了基于DSP-Fs的预处理操作,使用拉普拉斯滤波突出异常眼底图片的特点,有效地提高了神经网络学习的质量,在降低了分类的错误率的同时又减少了训练的时间复杂度。其次,选取ResNet50作为特征提取的主干网络,重写全连接层使其适用于彩色眼底图像的分类识别任务,提取更深层次的特征。与现有的分类识别算法相比,本文算法有效地降低了分类的错误率。但是本文算法在分类识别准确度上仍有提升空间,后续将会做进一步优化。
猜你喜欢
小主人报(2022年24期)2023-01-24 16:49:29
儿童时代·快乐苗苗(2022年6期)2022-08-06 07:24:16
学生天地(2019年33期)2019-08-25 08:56:18
小天使·二年级语数英综合(2018年7期)2018-09-11 10:32:54
制导与引信(2017年3期)2017-11-02 05:16:56
工业设计(2016年11期)2016-04-16 02:50:19
环境科技(2015年6期)2015-11-08 11:14:26
空间控制技术与应用(2015年3期)2015-06-05 14:30:31
遥测遥控(2015年2期)2015-04-23 08:15:18
电网与清洁能源(2015年2期)2015-02-28 16:03:07
