
融合Graph state LSTM与注意力机制的跨句多元关系抽取
2023-09-04 09:22:50衡红军姚若男
计算机应用与软件 2023年8期
衡红军 姚若男
(中国民航大学 天津 300300)
0 引 言
信息抽取旨在从非结构化或者半结构化的数据中提取出结构化的信息[1]。而关系抽取作为信息抽取重要的子任务,其主要目的是解决原始文本数据中的实体关系之间的分类问题,是构建知识图谱(knowledge graph)的重要步骤之一。基于深度学习和强化学习是当前最受欢迎的方法,现有的基于深度学习、强化学习方法的关系抽取模型,大都局限于单个句子内的二元实体的关系抽取。图1中的两个句子表达了这样一个事实,即在治疗由EGFR-TKIs基因上的T790M突变引起的疾病时,更多使用到了阿法替尼(afatinib)药物。两个句子中包含三个已标注的实体(图中加粗表示),即三个实体之间存在响应关系,但这在任意一个单独的句子中都没有体现。抽取这些知识显然需要跨越句子边界以及二元实体。
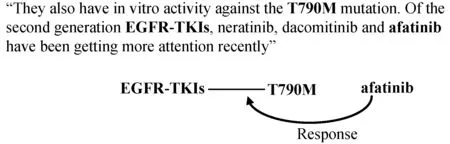
图1 跨句多元关系抽取举例
N元关系抽取和跨句关系抽取在之前并没有引起太多关注。当前已有的N元关系抽取工作集中在单个句子上进行。跨句抽取通常使用共指来获取不同句子中的参数对象,而没有真正对句子间的关系建模。直到Quirk等[2]使用文档级图融合句间关系,将远程监督应用于一般的跨句关系抽取,但该研究依旧仅限于二元关系。近年来,Peng等[3]进一步检测多个实体之间的关系来拓展跨句关系抽取(跨句多元关系抽取),并提出了一种Graph Long Short-Term Memory Networks(Graph LSTMs)的框架。该框架将输入文本表示为一个文档图,集合句内和句间的各种依赖关系,利用图结构对丰富的语言知识建模。为实体学习到一个鲁棒的上下文表示,作为分类器的输入,简化了对任意关系的处理,并使与关系相关的多任务学习成为可能。通过在一个重要的精确医学数据集上对该框架进行评价,证明了该框架在传统监督学习和远程监督下的有效性。这个方法的缺点是将完整的文档图分割成两个方向上的有向无环图(Directed Acyclic Graph,DAG),再分别使用Graph LSTM,会造成信息的丢失。Song等[4]针对这一问题提出了一种Graph state Long Short-Term Memory Networks(Graph state LSTM)模型,它将完整的图结构建模成为单个状态,使用并行状态对每个单词进行建模,通过消息传递递归地更新状态值。与DAG上使用的Graph LSTMs相比,Graph state LSTM保留了原有的完整图结构,并允许更多的并行化,从而加快了计算速度。
在现实世界中,包含多个句子依存关系和语篇关系的图结构既可能很大又可能嘈杂,如何有效地利用相关信息,同时又从图结构中忽略无关信息仍然是一个具有挑战性的研究问题。现有方法使用基于规则的硬修剪策略来选择相关的部分依赖结构,并不总能产生最佳结果。问题的有效解决方法是将注意力机制整合到模型中。注意力机制会自动专注于图中与任务相关的部分,从而帮助其做出更好的决策。
本文将Graph state LSTM与注意力机制进行结合进行跨句多元关系抽取,探索不同的注意力机制对使用Graph state LSTM进行关系抽取时所产生的影响。在一个医药领域的三元实体关系数据集以及其二元子关系数据集上分别进行实验,显示本文提出的模型无论在多元的关系抽取上还是二元的关系抽取上都表现出了较好的性能。
1 相关工作
1.1 二元(句内)关系抽取
传统的关系抽取就是对单个句子内的两个实体间的关系进行分类,主要使用的方法有三种:(1) 基于特征的方法,根据设计好的词汇特征、句法特征、语义特征来学习良好的关系抽取模型。黄鑫等[5]融合了词汇、实体和语法等特征,实验结果证明词法、句法和语义特征的融合可以提高关系抽取的性能。基于特征的方法需要人工设计能够有效表示语料特性的特征,耗费大量人力。(2) 基于核函数的方法,不需要构造特征向量,而是把结构树作为处理对象,通过计算它们之间的相似度来进行实体关系抽取。Zhao等[6]采用组合核(composite kernel)方法,先使用单独核,然后不断地组合核组合了多个不同的语法特征来进行关系抽取。基于核函数的方法在训练和预测环节速度过慢。(3) 基于神经网络的方法。近年来,基于神经网络的模型通过自动学习具有强大的特征表示功能,在众多领域都有了令人瞩目的表现。Zeng等[7]建立了分段最大池化的CNN模型(Piecewise Convolutional Neural Networks,PCNN),应用在英文实体关系抽取任务上,通过与传统最大池化的CNN模型的对比,该模型显著提升了关系抽取的性能,并在远程监督的多示例学习中取得了优异的成绩。
1.2 跨句关系抽取
现存的大部分关系抽取方法局限于句内的关系抽取,而忽略了句子间的实体交互关系,当实体出现在不同的句子中,只有将多个句子合并起来才能表达出他们的关系。Quirk等[2]首次利用远程监督实现跨句关系抽取。该文将依存关系和语篇关系结合形成一种图结构,提供了一种统一的方法来对句子内部和句子之间的关系建模。Gupta等[8]提出了一种新的基于句际型依存的神经网络,通过循环和递归神经网络对最短和增强的依赖路径进行建模,以提取句子内部和句间的关系。
1.3 n元关系抽取
早期对于两个以上参数的关系抽取可追溯到MUC-7[9],重点是从新闻文章中提取事件。近些年,神经网络模型广泛应用到了语义角色标注领域,Roth等[10]使用神经网络对语义角色标记建模,同时学习依赖路径和特征组合的嵌入,将n元关系分解为谓词和每个参数的二元关系,但只考虑到了单个句子中的实例。
1.4 基于图神经网络模型的关系抽取
现实世界中很多重要数据都是图形式存储的,代表着各种对象及其相互关系。图具有复杂的结构,也具有丰富的价值。如何使用深度学习方法学习图数据,引起了相当多的关注,除了使用图结构的LSTM进行图编码外,近年来很火爆的图卷积神经网络(Graph Convolutional Network,GCN)更是被广泛应用到了机器学习的各个领域。Fu等[11]提出一种端到端关系抽取模型GraphRel,堆叠Bi-LSTM和GCN来考虑线性结构和依赖结构,而且采用第二阶段关系加权GCN进一步建模实体与关系之间的相互作用,对实体和关系进行端对端的联合建模。Zhang等[12]提出了一个专用于关系抽取的图卷积神经网络的扩展,可以并行地在任意依赖结构上有效地聚集信息。并提出一种新的修剪策略用于输入树,最大限度地去除不相关内容的同时合并相关信息。
1.5 注意力机制
注意力机制现已被广泛应用在自然语言处理(NLP)领域的各项任务中,并已取得不错的成就。Zhou等[13]提出一个基于注意力机制的双向LSTM神经网络模型进行关系抽取研究,注意力机制能够自动发现那些对于分类起到关键作用的词,使得这个模型可以从每个句子中捕获最重要的语义信息,简单有效。Zhang等[14]提出了一种针对关系抽取任务构建的位置感知的神经序列模型,充分结合基于语义相似度和位置的两种注意力机制,来解决现有关系抽取模型中未对实体位置建模或只对局部区域位置建模的问题。随着图神经网络的发展,Zhang等[15]提出了一种以全依赖树作为输入的注意力引导图卷积网络(Attention Guided Graph Convolutional Networks,AGGCN)模型。该模型充分利用了依赖树中的信息,以便更好地提取出相关关系。
2 问题定义
本文研究跨句多元实体之间的关系抽取问题,以三元实体为代表提出解决方案。有一个预定义的关系集R=(r1,r2,…,rL,None),文本中的实体之间存在关系集R中的某一关系,其中None表示实体间不存在任何关系。此任务可以表示为识别实体间是否有关系的二分类问题,或者是一个多分类问题,即检测实体之间存在的具体关系。以图1中的实例为例,二分类任务是确定afatinib对EGFR-TKIs基因上T790M突变引发的疾病是否存在影响,多类别分类任务是检测确切的药物作用是“resistance or non-response”“sensitivity”“response”“resistance”和“None”中的哪一种。
3 本文模型
3.1 Graph state LSTM
传统的关系抽取方法多数针对于单句二元的关系抽取,不能够直接用在跨句多元的关系抽取问题上。因为表示跨句多元实体关系的词汇和句法是稀疏的,为了处理这种稀疏性,传统的基于特征的方法需要大量的特征工程和数据,当文本跨越多个句子时,这一挑战则会变得更加严峻。所以本文使用Graph state LSTM对文档图进行编码。
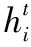

图2 文档图
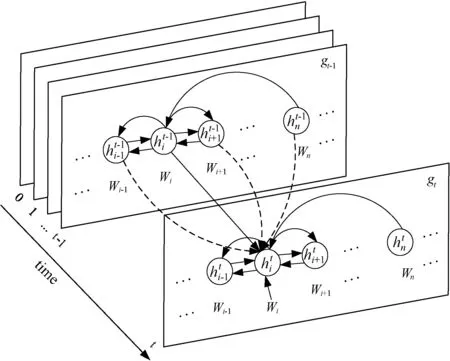
图3 graph state LSTM[4]
每个文档图包含输入文本中的所有单词与边两部分信息,分别用V、E两个集合表示。每个边e∈E连接两个具有依赖关系或彼此相邻的单词,使用式(1)将每条边映射到向量空间。
(1)
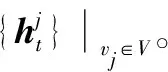
LSTM在解决梯度消失的同时可以学习长时依赖关系,所以Graph state LSTM使用门控LSTM来对状态转换进行建模。从gt-1到gt,每个单词与直接连接到该单词的所有单词进行信息交换,在每个迭代过程中,对于单词vj的输入包括与vj连接(输入与输出)的所有边的表示,如式(2)和式(3)所示,(i,j,l)代表源单词索引为i,目的单词索引为j,边标签类型为l的边,Ein(j)和Eout(j)表示单词j的输入和输出边集,以及其所有连接词(输入与输出)的隐藏状态,如式(4)和式(5)所示。
(2)
(3)
(4)
(5)
根据式(2)-式(5)的定义,从gt-1到gt的循环状态转换公式为:
(6)
(7)
(8)
(9)
(10)
(11)
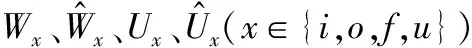
3.2 关系抽取模型
注意力神经网络近年来被广泛应用在了自然语言处理的各项任务中,并取得了不错的成绩。注意力机制能够自动聚焦对关系抽取起到决定性作用的关键词上,获取句子中重要的语义信息,降低噪声信息的影响。在本节中,将Graph state LSTM分别与单层词级注意力机制和位置感知的注意力机制融合,比较不同的注意力机制对使用Graph state LSTM进行关系抽取时的影响。
1) Graph state LSTM+attention。模型结构如图4所示,Xn指索引为n的单词嵌入,en表示当前单词所有连接边的嵌入,an为注意力权重,令H为由Graph state LSTM层产生的输出向量[h1,h2,…,hT]组成的矩阵,其中T为文本总长度。句子的最终表示r由这些输出向量的加权和组成。
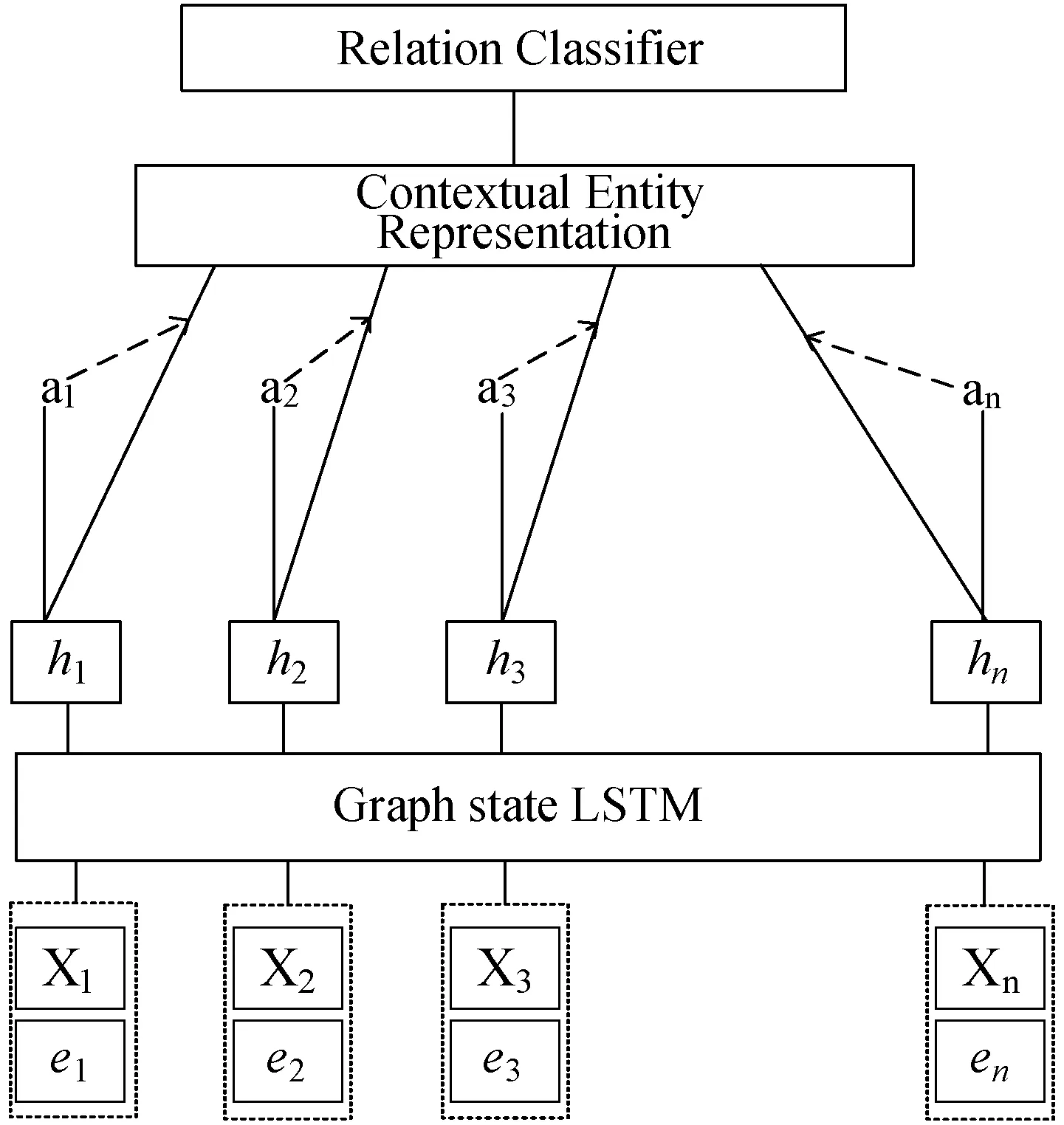
图4 Graph state LSTM+attention
M=tanh(H)
(12)
α=softmax(ωTM)
(13)
r=HαT
(14)
式中:α为权重矩阵,H∈Rdw+de,dw指词向量的维度,de是指边向量的维度,ω是一个可训练的参数向量,而ωT是ω的转置。最终获得句子的表示:
h*=tanh(r)
(15)
从句子表示中根据实体的索引筛选出实体的表示,作为最后预测的输入进行关系预测。


图5 PA-Graph state LSTM关系抽取模型
句子中已标识的三元实体,每一个实体可能会由多个单词组成,三元实体分别用Xd=[d1,d1+1,…,d2],Xg=[g1,g1+1,…,g2],Xv=[v1,v1+1,…,v2]表示,d1、d2分别表示实体的开始和结束索引。给定句子s以及句子中三个实体的位置,可以使用式(16)计算每个单词到实体的相对位置:
(16)
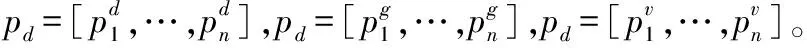
(17)
(18)
式中:Wh、Wq、Wd、Wg,Wv是网络训练过程中需要学习的参数。注意力权重ai可被视为特定单词对句子表示的相对贡献。最终句子表示z的计算式为:
(19)
3) 关系分类。Graph state LSTM+attention和Graph state LSTM+位置感知注意力两个关系抽取模型采用同样的关系分类方法。从最终的句子表示中选出实体的最终状态作为逻辑回归分类器的输入,可以很容易地推广到任意数量关系类型。使用式(20)以进行预测:
(20)
式中:hEN是第N个实体的隐藏状态表示,W0和b0是模型参数。
4 实验与结果分析
4.1 实验数据集
本实验使用的数据集来自Peng等[3]远程监督获取的一个生物医学领域的数据集。该数据集中包括6 987个关于drug-gene-mutation的三元关系实例,以及6 087个关于drug-mutation二元子关系实例。表1显示了数据集的统计信息,Avg.Tok和Avg.Sent分别是token和句子的平均数量。Cross是指所有实例中包含多个句子的实例所占的百分比。数据集中实例大多数包含多个句子,每个实例对应五个预定义关系标签中的一个,这五种关系包括:“resistance or non-response”“sensitivity”“response”“resistance”和“None”。在本节中,进行两个特定任务的评估实验,一个是n元实体的多分类任务,以及n元实体的二分类任务。在进行二分类时,对关系标签进行二值化[3],将“resistance or non-response”“sensitivity”“response”和“resistance”四种关系归为“YES”类,将“None”视为“NO”类。
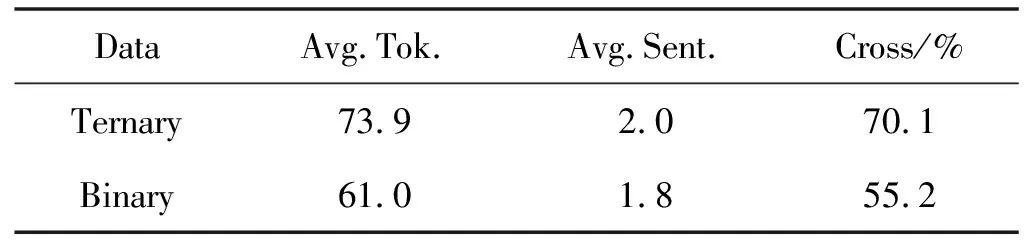
表1 数据集统计信息表

表2 实验参数设置表
4.2 模型参数
由于本文中使用的数据集是构造平衡的,所以仅保留最终测试准确率作为模型最终的评测指标。实验过程中,使用五折交叉验证对模型进行评估,并通过平均五折验证的准确率来计算最终测试准确率。对于每一折验证,从训练集中随机分离出200个实例作为验证集。
为了与基模型进行对比,本文的实验参数选取与Song等[4]保持一致,关系分类器使用逻辑回归分类器。使用batch size为8的mini-batched随机梯度下降进行训练,训练至多30个epochs,根据验证集的结果实施早停法(Early stopping)。
4.3 实验结果对比与分析
本文使用两类模型作为基线模型:(1) Quirk等[2]提出的基于特征的分类器,Miwa等[17]提出的基于实体对之间的最短依赖路径建模的分类模型;(2) 图结构化LSTM方法,包括Peng等[2]提出的Graph LSTM,以及Song等[3]提出的双向DAG LSTM(Bidir DAG LSTM)和Graph State LSTM(GS LSTM)。
1) 实验一:n元二分类实验。首先关注n元二分类的结果,如表3所示,其中,Single表示仅针对包含一个句子的实例进行的实验,而Cross表示针对所有实例的实验。在三元实体的关系抽取任务中,本文提出的Graph state LSTM+attention(GS LSTM+attention)模型在单句(Single)和所有实例(Cross)中的准确率分别达到82.5%和84.4%,Graph state LSTM+位置感知注意力(PA GS LSTM)模型,在单句关系抽取和跨句关系抽取的准确率分别达到83.1%和85.8%。在二元实体的关系抽取任务中,GS LSTM+attention模型在单句实例和所有实例中的准确率分别达到84.0%和85.8%,PA GS LSTM模型在单句实例和所有实例中的准确率分别达到84.9%和86.7%。两个模型的准确率均优于基线模型,说明本文的模型是有效的。

表3 n元二分类的平均测试准确度
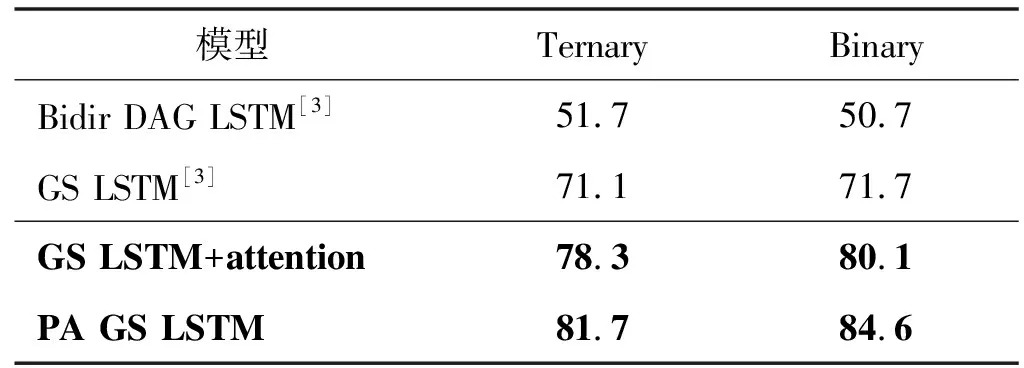
表4 n元多分类的平均准确率
验证1:注意力机制可关注到图结构中重要的节点信息。
因为在大规模的图结构中节点较多,复杂的背景噪声会对Graph state LSTM性能产生不良影响。在注意力机制的作用下,模型会关注到文档图中最重要的节点或者节点中最重要的信息从而提高信噪比,能够增强任务中需要的有效信息,减弱噪声信息的影响。所以加上注意力机制的Graph state LSTM用在关系抽取任务上的效果更好。
验证2:引入位置信息与全文信息可以更好地评价每个节点对图最终表示影响。
为了分析不同组件对模型的影响程度,本文在基础的GS LSTM+attention模型上分别加入表示全文信息的和向量(Q)和相对位置向量(P)分别进行三元跨句二分类(Ternary)与二元跨句二分类(Binary)实验并进行比较。实验结果如表5所示,五个模型使用的网络结构都保持一致。

表5 具有不同组件的模型性能
可以看出,注意力机制考虑到全文信息时,两个实验准确率分别比之前高了0.4%与0.3%,注意力机制考虑到实体相对位置信息时,两个实验准确率分别比之前高了0.7%与0.5%,GS LSTM+attention+P结果比GS LSTM+attention+Q结果更好一些,两者融合效果更佳。
在多句文本的文档图中,每个词节点往往要经过多跳才能到达表示实体的词节点。PA GS LSTM通过引入单词到实体的相对位置信息,对单词位置信息直接建模。对于评价每个节点对最终图的表示影响不单从当前词节点本身考虑,根据位置信息、当前词信息,以及整个文本信息三个方面每个单词节点对图的最终表示做调整,并且从语义信息和序列中实体的相对位置两方面评价每个单词对句子表示的影响,获得对关系抽取更有意义的上下文表示,获取更高的关系抽取准确率。
2) 实验二:n元多分类实验。同时对n元多分类结果进行评估,结果如表3所示。由于细粒度的分类任务要比粗粒度的分类任务难得多,所以根据表4中的数据可以看出来在多分类上的结果比二分类的结果要普遍降低。本文提出的GS LSTM+attention模型在三元和二元实体的所有实例中实验的平均测试准确度分别达到了78.3%和80.1%,PA GS LSTM模型在三元和二元实体所有实例中实验的平均测试准确率分别达到了81.7%和84.6%,仍然比没有使用注意力机制的Graph state LSTM进行关系抽取时的结果要高一些,进一步说明了模型的有效性。
4.4 实例分析
表6将本文提出的模型与基模型在数据集中两个实例上进行关系抽取的结果进行比较,并根据模型产生的注意权重不同使用不同大小和粗细的字体区别显示单词,越大越粗的单词代表注意力权重越高,例句中的(d)、(g)、(v)分别代表该词为数据集中标记的药物、基因、突变实体。可以发现,对于数据集中的复杂实例,加上注意力机制的模型也能够很好地注意到对关系分类有贡献的词。其次,由于标记实体对关系分类是至关重要的,所以模型向标记实体施加了非常高的注意力权重。然而,对于某些关系指向不明显的实例,如表6中实例2,未指明三个实体之间的关系,而是使用基因部分丢失这一隐含说明来暗示三者之间的关系,只加上词级注意力的模型分类效果就不如PA GS LSTM,会关注到一些噪声词上,从而导致错误分类。

表6 关系分类实例
5 结 语
本文提出了引入注意力机制的Graph state LSTM模型用于跨句多元关系抽取,并研究了不同注意力机制对使用Graph state LSTM进行跨句多元关系抽取的影响。实验结果表明,使用注意力机制对Graph state LSTM进行关系抽取有一定的提升作用。位置感知的注意力机制通过对实体的相对位置建模,同时考虑到整句信息对句子最终表示的影响,对Graph state LSTM进行关系抽取的效果提升更加明显。未来可以尝试采用目前主流的自注意力将注意力机制与图神经网络相结合进行跨句多元关系抽取,探索不同注意力机制与图神经网络结合时,对关系抽取效果的影响。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
传媒评论(2017年3期)2017-06-13 09:18:10
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
