
基于图像切块的多特征融合行人再识别模型
2023-09-04 09:22朱玉全
计算机应用与软件 2023年8期
张 羽 朱玉全
(江苏大学计算机科学与通信工程学院 江苏 镇江 212013)
0 引 言
行人再识别主要研究跨摄像头再识别的问题,即出现在摄像头中的行人能够在另外的摄像头中自动被识别出来。实际跨摄像头跟踪中,由于拍摄角度、视角、光照、图像分辨率、遮挡、相机设置的影响,可能会导致同一个行人在不同的摄像头下具有显著差异,因此行人再识别仍然是计算机视觉中的一项具有挑战性的任务。
早期基于深度学习的行人再识别主要关注全局特征[1-3](Global Feature),网络从整幅图像提取行人全局特征,通过学习全局特征来捕捉最显著的外观特征,从而表示不同行人的身份。目前大部分的卷积神经网络都是基于全局特征。随着监控场景中得到图像的复杂度越来越高,仅仅使用全局特征很难达到性能要求,一些非显著或不常见的细节信息很容易被忽略。因此提取更加复杂的局部特征(Local Feature)成为行人再识别一个研究热点。
目前利用局部特征进行行人再识别的方法主要分为两类。第一类是利用在其他数据集上训练好的姿势估计模型无监督迁移到行人再识别数据集上,得到行人身体关节的定位,然后根据身体关节的位置,获得感兴趣区域。其中CVPR2017的工作Spindle Net[4]是该类方法的典型代表,Spindle Net网络首先通过骨架关键点提取14个人体关键点,之后利用这些关键点来提取7个感兴趣区域(Region of Interest,ROI),并将这7个ROI区域和原始图片输入同一个网络提取特征,最后将原始图片得到的特征和7个ROI区域的特征进行融合。裴嘉震等[5]首先采用姿态估计算法定位人体关节点,然后对行人图像进行视图判别以获得视点信息,并根据视点信息与行人关键点位置进行局部区域推荐,生成行人局部图像,最后将整幅图像和局部图像同时输入网络进行特征提取。第一类方法虽然可以显式地定位人体的部件,但是由于姿势估计数据集和行人再识别数据集之间存在很大的数据偏差,导致姿势估计任务迁移到行人再识别任务过程中,会向行人再识别任务中引入新的误差。此外,大部分情况下引入姿势估计模型需要的标注成本较高,消耗的训练时间较长。
第二类方法采用统一的图像切块方式,按照人体特殊的结构,将图片从上到下均匀分成几等份。文献[6]是图片切块的一个典型示例,图片被垂直切分为若干个图像块,然后将图像块按照顺序输入到由Long Short-Term Memory网络[7](LSTM)和孪生网络[8]组成的网络中进行特征提取,最后的特征融合了所有图像块的局部特征。Zhang 等[9]提出的AlignedReID模型将图片水平切分为8个部分,然后利用卷积神经网络对每个部分提取局部特征,最后利用动态规划思想中的最短路径距离实现局部特征自动对齐。Sun等[10]提出一种能够精确划分身体区域的PCB网络模型,该模型利用水平切块,将特征图均匀切分为六块,通过这种切块方式可以提取更细节更具有鲁棒性的特征。但是其后续需要使用精确部分池化网络(RPP)对分块特征进行精炼,导致网络不能进行端到端的训练。Chen等[11]在PCB网络的基础上加入了高阶注意模块,对注意力机制中复杂的高阶统计信息进行建模和利用,从而捕捉行人之间细微的差异。Miao等[12]提出了姿态引导特征对齐(PGFA)方法,该方法包含姿态引导全局特征分支和局部特征分支,姿态引导全局特征分支中利用人体关键点坐标来生成注意力图,引导模型关注有用的信息,局部特征分支中将特征图水平切为6个部分,每个部分引入一个分类损失,引导模型关注局部特征。
为了让网络既可以学习到不同层级下的行人全局特征,又可以学习到具有区分力的细节特征,本文提出基于图像切块的多特征融合行人再识别模型(Image Partition Multi-feature Fusion,PMF-ReID)。PMF-ReID模型使用三个分支分别提取行人的全局特征和局部特征,并将三个分支的特征进行深度融合实现行人身份预测。本文的贡献如下:1) PMF-ReID模型同时提取图像低层和高层的全局特征,在保留高分辨率图像特征的同时,网络可以提取到更深层的语义信息;2) 在局部特征提取过程中,分支3仅将图像进行二分块就可以较好地提取局部特征避免复杂的模型设计和引入额外的姿态评估模型;3) 在模型端到端训练过程中,本文联合三种损失函数,并对不同的特征使用不同的损失函数,从而将提取到的特征进行有效融合,使得网络可以互补地进行学习。
1 网络架构设计
1.1 网络框架
本文的网络架构如图1所示,PMF-ReID模型主要分为前后两个部分:前半部分为提取图片特征的骨干网络(Backbone network),后半部分为多特征融合的行人身份分类架构。多特征融合主要融合了图像的三个全局特征和两个局部特征,根据不同类型的特征应用合适的损失函数进行网络模型训练,最后根据提取出来的特征实现行人身份预测。

图1 本文网络架构
1.2 骨干网络架构
当前的行人再识别网络模型大多以现有的ResNet[13]、VGG-Net[14]、Dense-Net[15]、GoogleNet[16]等网络作为骨干网络进行研究,上述网络模型的有效性已经在 ImageNet[17]数据集上得到了验证。由于ResNet-50相比于传统的卷积神经网络(如VGG-Net)复杂度降低且需要的参数下降,网络可以做到更深,因此本文使用ResNet-50作为骨干网络并对其进行修改。
本文移除了ResNet-50中Layer3后面的Layer4层、池化层和全连接层,只保留了Layer3之前网络作为骨干网络,并使用ImageNet预训练模型的参数。骨干网络包括卷积层,批正则化(Batch Normalization, BN)、ReLU层、最大池化层、Layer1、Layer2和Layer3层。图片输入后,将由一个7×7的卷积核负责进行特征的抽取,卷积核的步长为2,所以图像的长宽会降低为原先的1/2;随后,再经过最大池化层进一步降低图像的分辨率;最后经过Layer1、Layer2、Layer3卷积得到特征图Q。其中,每个Layer层中包括若干个下采样块和残差块[13](图2为Layer1层中的下采样块和残差块),通过残差块和下采样块的跳跃连接,网络可以提取到图片更深层次的语义特征。
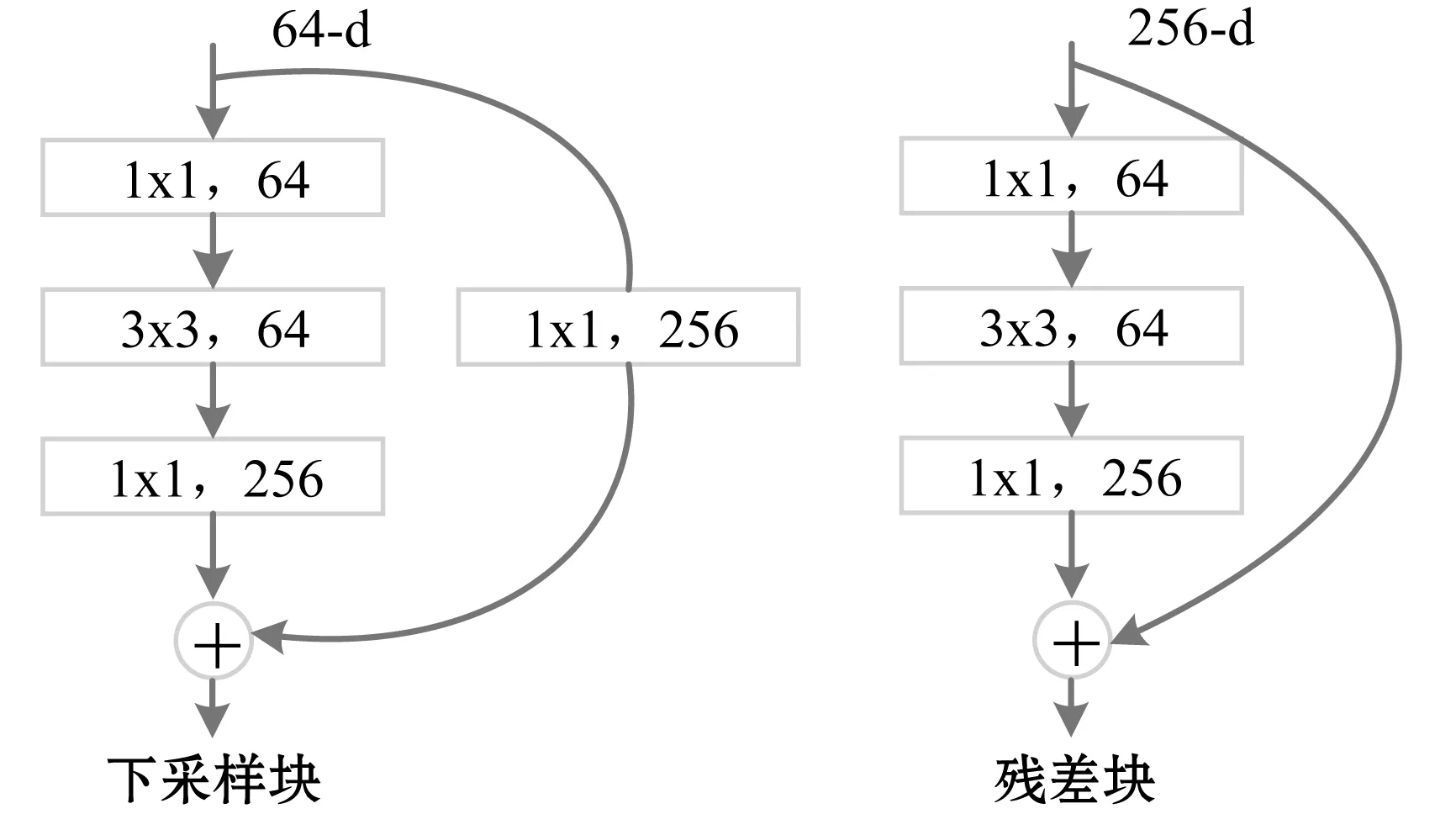
图2 下采样块和残差块
1.3 多特征融合的行人身份分类网络架构
为了从图片中获取不同层级的全局图像特征和更具有区分力的细节特征,本文设计多特征融合的行人身份分类网络架构。如图3所示,输入图像经过骨干网络后得到特征图Q,然后将Q输入到多特征融合网络架构进行全局和局部特征提取。该架构由三个分支组成,分支1(Branch1)和分支2(Branch2)用来提取不同层级的全局特征G1和G2;分支3(Branch3)用来提取全局特征G3和局部特征P1、P2;最后,融合所有特征实现行人身份预测。

图3 PMF-ReID网络模型
在端到端的训练阶段,本文对不同的分支使用不同的损失函数,注重于让模型学习到有区分性的有益部件信息。对于局部特征P1和P2,本文使用交叉熵损(cross-entropy loss)和中心损失(center loss)进行监督训练;对于全局特征G1、G2和G3,本文使用三元组损失(triplet loss)优化网络参数。整个网络模型损失函数如式(1)所示。
(1)
式中:λ为平衡中心损失的权重,实验中设为0.000 5。
1.3.1提取不同层级的全局特征
随着网络深度的增加,高层特征具有更强的语义信息,但高层级特征的分辨率较低导致其对细节的感知能力较差。多数行人再识别网络模型仅在高层级特征上进行分类,忽视了低层特征的作用。因此,分支1和分支2分别从两个不同的层级提取行人的全局特征,从而让网络既可以学习到高层的语义信息,又可以学习到低层的细节特征。
为了获得更多的位置和细节信息,本文在分支1中保留了低层特征,即对特征图Q不进行卷积下采样,直接将特征图Q水平区域内所有列向量进行全局最大池化(Global Max Pooling,GMP)得到低层全局特征。本文在全局最大池化的基础上添加了全局平均池化(Global Average Pooling,GAP)[18],通过对每个通道内的像素求取均值来整合全局空间信息,在一定程度上解决了全局最大池化只保留最显著信息的问题。最后通过Add操作将两个低层全局特征进行融合得到全局特征G1。
由于分支1经过的卷积层较少,导致其所得特征的语义性较低。为了获得具有更高语义信息的特征,分支2首先使用Layer3和Layer4层继续对特征图Q进行卷积,其中每个Layer层由若干个下采样块和残差块构成,下采样最初的卷积步长设置为2,通过这样的方式对特征图进行下采样后,特征图Q的通道数扩展为原来的一倍,图像大小缩减为原来的一半。最后将卷积后的特征图经过全局最大池化得到全局特征G2。本文使用三元组损失函数分别对分支1和分支2进行监督学习,其中三元组损失函数如式(2)所示:
(2)
式中:‖*‖为欧氏距离;P代表每一个训练批次ID数目;K代表同一个ID的图片数;fa、fp和fn分别表示锚点、正样本和负样本的特征表达;α为三元组损失的margin值,设置为0.3。
1.3.2局部特征的提取
受PCB网络的启发,本文的网络在提取局部特征时采用水平切块的方式。分支3中,先让特征图Q经过Layer3层和Layer5x层,然后在水平方向上将得到的特征图分为上下两个部分,最后对这两个部分进行特征提取得到局部特征P1、P2,其中每一个局部特征都享有一样的权重。与分支2中Layer4层不同的是,Layer5x层少了下采样操作,因此不改变图像的分辨率,切块后的图像仍具有较高的分辨率,保留了适合该局部特征的感受野。本文在使用图像分块提取局部特征时,保留了同尺度下图像全局特征G3,使得模型既可以学习到行人的局部细节信息,又可以学习到该尺度下的行人的整体信息。
本文使用Softmax激活函数作为每个局部特征的分类器,表达式如式(3)所示。
P(id)=softmax(w(id)·x+b(id))
(3)
式中:w(id)和b(id)分别是全连接层的权重矩阵和偏差向量;x为特征;P(id)为输出的行人身份的预测概率。
由于局部特征块只包含行人的部分特征,对局部特征使用三元组损失可能会使得局部特征块的类间距离小于类内距离,影响模型性能,所以对于局部特征本文使用交叉熵损失和中心损失函数进行监督训练。
交叉熵损失具有较强的类间判别力,但对类内差距的减少效果并不明显。为了增加类内的紧凑性,本文在使用交叉熵损失函数的同时,添加了中心损失函数对局部特征进行监督,从而让网络模型学习到的特征具有更好的泛化性和辨别能力。通过惩罚每个种类的样本和该种类样本中心的偏移,使得同一种类的样本尽量聚合在一起。交叉熵损失函数和中心损失函数的定义如式(4)和式(5)所示。
(4)
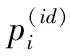
(5)
式中:m是最小批次图片的数量;xi表示第i幅图片的特征向量;yi表示第i个图像的标签;cyi为第yi个类中心。
2 实验结果与分析
2.1 数据集
Market-1501[19]数据集包含1 501个类别,总共36 036幅图片。该数据集在清华大学校园中采集,图像来自六个不同的摄像头,包含五个高分辨摄像头和1个低分辨摄像头,每个类别的图片最多能被六个摄像头捕捉到,最少能被两个摄像头捕捉到。训练集(training)中有751个行人ID,包含12 936幅图像,平均每个ID有17.2幅训练图片;测试集(testing)中有750个行人ID,包含19 732幅图像,平均每个ID有26.3幅测试图片;查询集(query)中共有3 368幅图像。
DukeMTMC-reID[2]数据集是一个大规模标记的多目标多摄像头行人跟踪数据集,包含36 411个图像,1 812个不同ID的行人,其中1 404个不同的ID行人出现在不同摄像机视野中,剩余的408个不同ID的行人是一些误导图片。该数据集于杜克大学采集,图像来自8个同步摄像头,其中702个行人ID用于训练,其他ID用于测试。
MSMT17[20]数据集是当前最大的公开可用的行人再识别数据集,数据集总时长约180 h,图像来自15个摄像头,其中:12个室外摄像头;3个室内摄像头。数据集总共有4 101个行人ID,共126 441个边界框(bounding boxes)。训练集有1 041个行人ID,共32 621个边界框,测试集有3 060个行人ID,共93 820个边界框,其中测试集中有11 659个边界框被随机选出来作为查询集,其他的82 161个边界框作为底库(gallery)。数据集以Faster RCNN[21]作为行人检测器,将检测到的边界框进行手工标注。
2.2 评价指标
为了评估本文模型性能,采用业内最常用的两种评价指标:rank-n(accuracy)和mAP(mean Average Precision)。rank-n是指所查询的图像与底库图像匹配度最高的前n幅图片中命中查询图片的概率,rank-1即首次命中率。mAP是更加全面衡量行人再识别算法效果的指标,它反映检索的图片在底库中所有正确的图片排在结果队列前面的程度。
2.3 实验相关设置
本文基于PyTorch框架实现网络模型,并在GTX 1080 Ti GPU上完成实验。输入图像分辨率为128×384,宽高比为1∶3。训练时的batchsize大小设置为32,测试的batchsize大小设置为256。本文使用SGD优化器对每个样本进行梯度更新,训练到收敛时结束。本文将momentum设置为0.9,weight decay设置为0.000 5。
训练策略具体包括:1) 本文对训练数据进行随机裁剪、水平翻转和概率为0.5的随机擦除,从而进行数据增强;2) 标签平滑,用于降低模型过拟合的风险,提高模型的泛化性能;3) 动态调整学习率,初始学习率为3E-2,每step_size步之后衰减lr,多个参数共用step_size,step_size大小设置为60,130。factor设置为0.1。warmup_epoch设置为10,warmup_begin_lr设置为3E-4。
2.4 本文方法分析
为了验证本文方法的有效性,本文在Market-1501数据集上进行了4组对比实验。第1组实验使用分支1提取全局特征;第2组实验使用分支1和分支3分别提取浅层的全局特征和局部特征并进行融合;第3组实验使用分支2和分支3分别提取深层次的全局特征和局部特征进行融合;第4组实验使用3个分支同时进行特征融合,实验结果如表1所示。从第1组和第2、3、4组的对比中可以发现,同时提取行人的全局特征和局部特征准确率明显提升;从(组2,组4)和(组3,组4)的对比中可以发现,与单一层级的全局特征和局部特征融合相比,将不同层级下的全局行人特征和局部特征进行融合可以获得更好的识别结果。
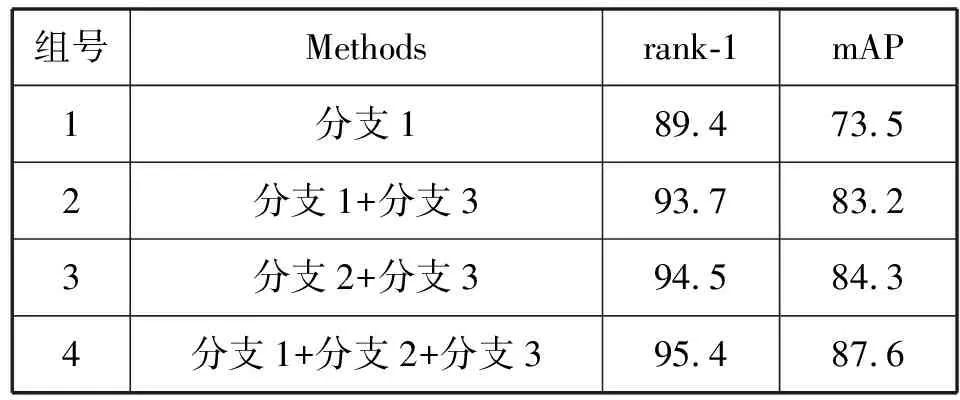
表1 深度特征融合消融实验(%)
为了进一步讨论图像分块数量对实验结果的影响,本文在公开的大型数据集Market-1501进行了3组对比实验,实验结果如表2所示。第一组实验(Global)不对图片进行分块,仅使用分支1和分支2对整幅图片进行全局特征提取;第二组实验(Global+Part-2)中的网络分为3个分支,第1、2个分支使用整幅图像提取图像全局的特征,第三个分支将图像水平切成两块,从上下两个部分分别进行局部特征提取;第三组实验(Global+Part-3)同第二组一样,网络分为三个分支,第一、二个分支提取图像全局特征,第三个分支则把图像水平切成三块,上中下三个部分分别提取图像的局部特征。从实验结果可以看出:1)组2、组3相比较组1在rank-1和mAP有明显的提高,说明将全局特征和局部特征融合的方法是有效的;2)在rank-1和mAP上组2比组3分别高出0.6百分点和2.3百分点,说明本文中将图像切分两块的效果更好。
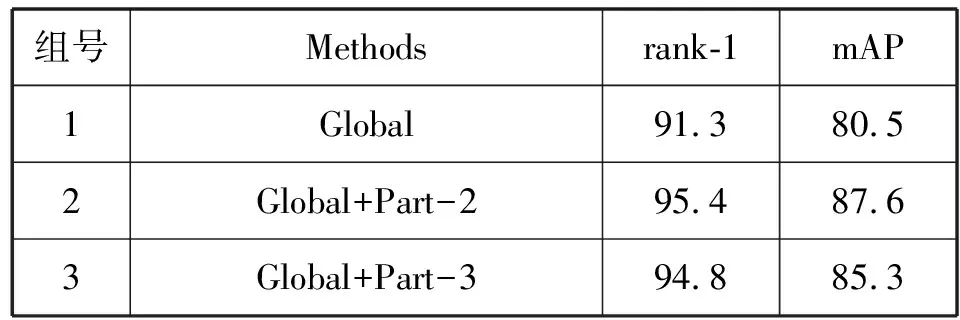
表2 图像分块实验结果比较(%)
为了验证多损失函数的有效性,本文在Market-1501数据集上使用不同损失函数进行了三组对比实验,如表3所示。组1是三个分支均使用交叉熵损失训练网络;组2是对3个分支中全局特征和局部特征分别使用三元组损失和交叉熵损失指导多特征学习;组3在第2组实验的基础上对局部特征增加了中心损失来辅助多特征学习。可以看出,第3组实验的mAP和rank-1值分别达到87.6%和95.4%,联合三个损失函数比使用单个损失函数在mAP和rank-1值上分别提高3.4百分点和1.2百分点,说明使用多个损失函数联合学习对行人再识别任务起到了促进作用。

表3 不同损失函数性能比较(%)
为验证采用水平切块的局部特征提取方法中,本文提出的网络模型的优势,本文在Market-1501数据集上与其他模型进行了比较。第一组AlignedReID[9]模型把图片切分为8个部分;第二组GLAD[22]模型把图片分为头部、上身和下身三个部分提取特征;第三组MHN[11]、PCB[10]和PCB+RPP[10]模型将图片水平切块为6个部分,分别对每个小部分提取特征。从图4中可以看出,在基于水平切块的局部特征提取方法中,本文在没有使用复杂图像切块的情况下,所提出的网络模型比目前先进的MHN模型在rank-1和mAP上分别高出0.3百分点和2.6百分点。
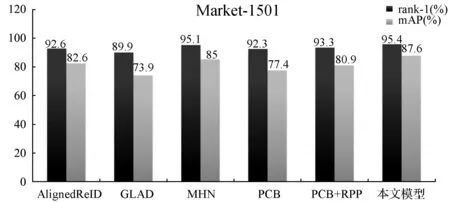
图4 不同网络模型在Market-1501数据集上的识别率
2.5 与现有模型的比较
表4和表5将本文方法与其他模型在Market-1501、DukeMTMC-reID和MSMT17数据集上的识别准确率进行了比较,其中“—”表示原文献没有给出实验结果。可以看出,本文方法取得较好的实验结果。其中与目前state-of-the-art 的MHN(CVPR2019)的模型相比,本文模型在Market-1501数据集上的rank-1和mAP分别比其高出0.3百分点和2.6百分点;DukeMTMC-reID数据集上的rank-1与其相近但mAP比其高出1.3百分点。在MSMT17数据集上rank-1和mAP上也有明显的提升。

表4 Market-1501、DukeMTMC-reID数据集上本文模型与现有模型的比较(%)
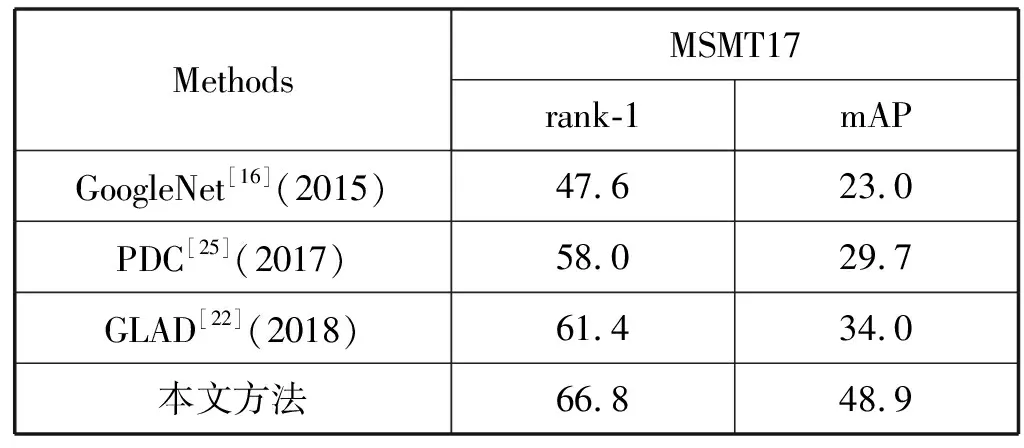
表5 MSMT17数据集上本文模型与现有模型的比较(%)
2.6 模型可视化分析
本文将实验的结果进行了可视化操作,图5(a)是仅使用整幅图片提取全局特征得到的可视化结果,图5(b)是本文网络的可视化结果。其中:rank是命中率核心指标;rank-1就是排在第一位的图是否包含目标本人;rank-8是1至8幅图片中是否至少一幅包含目标本人。

(a)
从图5(a)可以看出,输入查询图片,其中第7幅图片和第8幅图片并不是目标本人,属于识别错误的图片。图5(b)中所有查询出来的图片都是目标本人,即全部查找正确。从可视化结果可以看出本文提出的网络模型对于行人再识别的准确率有明显的提高。
3 结 语
本文从行人再识别应用场景复杂、行人外观差异大,需要提取更多细节的行人特征这一问题着手,提出一种基于图像切块的多特征融合的行人再识别网络模型。本文设计的网络模型分为三个分支,全局特征提取分支把整幅行人图像作为输入,分别提取图像不同层级的外观特征;局部特征提取分支则把图像分为上下两个部分,分别对其提取细节特征。此网络模型既能够关注到行人的外观特征,又能关注到行人的局部特征,使得网络具有很好的行人特征表示能力。此外,本文使用三种损失函数联合学习代替单一的损失函数指导网络学习。在几个大型数据集上进行了验证实验,结果表明本文提出的PMF-ReID模型能够提高行人再识别的准确率。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
意林(2021年5期)2021-04-18
学生天地(2019年28期)2019-08-25
扬子江(2019年1期)2019-03-08
金桥(2018年4期)2018-09-26
数学物理学报(2018年1期)2018-03-26
小天使·一年级语数英综合(2017年6期)2017-06-07
中国卫生(2014年5期)2014-11-10
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
