
基于图注意力卷积神经网络的推荐系统
2023-09-04 09:22:50柴文光张振杰
计算机应用与软件 2023年8期
柴文光 张振杰
(广东工业大学计算机学院 广东 广州 510000)
0 引 言
随着网络信息的爆炸增长,人们能非常方便地获取到大量的在线讯息,例如电影、新闻和商品等。在线平台面临的一个关键问题是用户如何在琳琅满目的物品中挑选出自己喜爱的物品,推荐系统应运而生。传统推荐系统使用的算法是协同过滤算法,该算法充分挖掘用户的历史交互记录,通过学习得到用户和物品的嵌入表示,然后通过内积、神经网络等方法对用户与物品之间的交互进行建模,最终得到用户对某个物品的喜爱程度。然而,基于协同过滤的方法存在用户与物品的交互矩阵的稀疏性和冷启动问题,当用户仅有少量的交互记录时协同过滤算法无法为用户提供推荐功能。为了解决这两个限制,将知识图谱(例如社交网络)的辅助信息[18-19]应用到推荐系统中往往能获得更高质量的推荐,并且目前获得了广泛的应用。
知识图谱是一个有向的异质图,图中的节点对应多种类型的实体(例如某场电影或某位导演),图上的边对应多种不同类型的关系,通过这些关系可以挖掘出用户感兴趣的物品,而且节点之间的边关系给推荐结果提供了一定解释性。由于每对节点之间的连接关系蕴含着巨大的语义信息,运用GNN、GCN、TransE等方法挖掘知识图谱的丰富语义信息能有效地找出实体之间潜在的关系,极大地提升推荐系统的性能。Yu等[2]提出用一个异质信息网络表示知识图谱,使用基于元路径的方法学习得到图谱中节点和边的嵌入表示。Wang等[1]提出将实体和边关系映射到低维的嵌入表示,但是只挖掘了粗略的语义信息。Harper等[4]受到图卷积神经网络的启发,提出了基于知识图谱的卷积神经网络(KGCN)。KGCN的核心思想是在学习知识图谱中实体的嵌入表示时,聚合了实体两跳以内的邻居节点的嵌入表示。在聚合的过程中,根据每位用户的兴趣赋予邻居节点的权重,但忽略了用户的具体兴趣。
尽管知识图谱具有很多的优点,但是将知识图谱应用到推荐系统具有很大的挑战性。本文提出了一个新颖的推荐算法,使用图卷积神经网络(GCN)聚合知识图谱中丰富的结构信息和语义信息,每一次的聚合迭代过程都引入了注意力机制,依据用户对图谱中每个节点的具体兴趣赋予特定的权重。提出的算法还包括应用深度神经网络(DNN)对学习得到的用户和物品的嵌入表示建立模型,以挖掘两者嵌入表示之间潜在的语义信息。本文在MovieLens-20M(movie)和Last.FM(music)两个公共数据集上开展实验,实验结果表明我们的算法优于其他主流的推荐算法。
本文的主要贡献有:提出了一个新颖的推荐算法框架,该框架结合GCN和Attention机制挖掘知识图谱丰富的结构和语义信息。应用DNN对学习得到的用户和物品的嵌入表示建立模型,重新编码用户的嵌入表示,生成特定于某样物品的用户偏好。
本文在MovieLens-20M和Last.FM两个公共数据集上开展实验,实验结果证明了算法的有效性。
1 相关工作
关于图神经网络(GNN)的研究表明沿着图拓扑结构的路径传播节点嵌入表示可以在多跳邻居内提取有用的信息,丰富节点的嵌入表示。首先Kipf等[21]提出图卷积神经网络(GCN)聚合图拓扑结构相邻节点的信息,但每次聚合过程是在全图的拓扑结构上聚合信息,这导致了计算复杂度极其庞大。潘承瑞等[8]提出融合知识图谱的图卷积神经网络(KGCN)迭代地聚合两跳节点内的节点相似性信息,并根据用户的兴趣在聚合过程赋予邻居节点特定的权重。虽然KGCN大大降低了算法的时间复杂度,但是该方法的注意力机制忽略了用户的具体兴趣,例如,它将所有导演都笼统地归类为同一类,用户可能喜爱某位导演,不喜欢另一位导演。
He等[11]提出轻量级的图卷积神经网络(LightGCN),该方法使用简单的加权聚合函数捕捉邻居节点的信息,聚合函数不使用对于协同过滤算法来说是比较冗余的特征转换和非线性激活,而且没有引入注意力机制,而是使用节点的度计算加权求和的权重。由于LightGCN是在全图的邻接矩阵上进行图卷积运算,而本文的方法是在局部拓扑结果上进行卷积运算,因而我们的方法更容易应用到大型的推荐系统中。
Sun等[23]提出基于邻居交互的图卷积神经网络(NIA-GCN),该方法在聚合两跳内邻居节点信息时,在所有同一跳节点上同时使用平均求和函数和两两同一跳节点逐元素相乘的聚合函数。本文也在局部拓扑结构内聚合两跳节点的信息,但引入了注意力机制,赋予用户感兴趣的物品更高的权重。
Wang等[22]提出图解缠层(Graph Disentangling layer)来聚合节点的邻居信息,在聚合邻居信息的步骤中引入了注意力机制。图解缠层用一个可学习的数值表示节点之间的连接权重,该权重反映了中心节点对邻居节点的重要程度。训练过程基于连接权重线性聚合邻居节点的信息,并且迭代地更新连接权重和节点的嵌入表示,最后使用内积函数得到用户对物品的预测评分。本文使用线性聚合函数捕捉邻居节点丰富的语义信息,但是我们使用中心节点与邻居节点之间的内积函数来表示连接权重,以减少模型的参数量,降低过拟合的风险。同时,本文不直接使用内积函数计算预测评分,而是提出对用户和物品的嵌入表示进行建模来获取预测评分,首先使用深度神经网络重新编码用户嵌入表示,重新编码后的嵌入向量描述了用户特定于该物品的偏好,然后将重新编码后的用户嵌入表示与物品嵌入表示作内积。
2 问题描述

本文所做的工作是,给定用户与物品的交互矩阵Y和知识图谱G,预测用户u对从未交互过的物品v的潜在兴趣。
3 图注意力卷积神经网络
本文提出图注意力卷积神经网络的方法来捕捉知识图谱相邻节点之间的相似性信息,我们的方法不仅计算量较小,还考虑了用户的具体兴趣。对于图谱上每个物品节点v∈V,我们通过基于图注意力卷积神经网络的方法聚合知识图谱上邻居实体(e∈ε,e∉V)的信息,而且对于每个邻居实体,再次使用图注意力卷积神经网络捕捉邻居节点的信息。我们使用N(v)表示节点v的邻居节点,rvi,vj表示每队邻居节点之间的边关系。图注意力卷积神经网络使用的注意力函数g表示为:Rd×Rd→R(例如,内积),该函数计算用户u(u∈U)对知识图谱中实体e(e∈ε)的喜爱程度(见图1的②号圈所示):

图1 知识图谱节点信息聚合的示意图
(1)


(2)

(3)
v∈V和e∈ε都对应知识图谱中的实体,用户-实体分数是特定于某个用户的归一化权重,这组权重反映了用户专属的、具体的偏好。
在真实的知识图谱中,所有节点的邻居节点数量是不相同的,为了计算方便,在对邻居节点进行随机采样时[20],我们采集固定数量的邻居节点。在本文实验,由于我们不仅对物品节点v∈V做邻居节点信息聚合,还对节点v的邻居节点做信息聚合,在后者的信息聚合过程中,注意力函数g将会对用户u和物品e(e∈V,V⊆ε)做内积,这也反映了用户对某个物品的感兴趣程度。

(4)
算法1是以上步骤的伪代码实现。
算法1图注意力卷积神经网络算法
输出:融合邻居节点信息的物品嵌入表示Inew。
For (u,v) inY:
Node=[[v]]
Foriin range(H):
Node.append(M(Node[-1]))
Foriin range(H):
Forkin range(H-i):
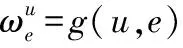
对于Node[k]中的每个节点v:
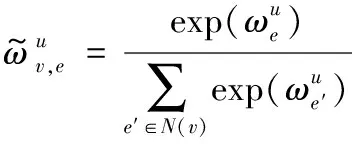
Returnvnew
4 深度神经网络
本文新颖地提出对知识图谱学习得到的用户和物品的嵌入表示进行建模,使用深度神经网络重新编码用户嵌入表示,重新编码后的嵌入向量描述了用户特定于该物品的偏好。图2是重新编码用户嵌入表示的示意图。

图2 重新编码用户嵌入表示的示意图
对于学习得到的用户和物品的嵌入,物品嵌入表示与用户嵌入表示进行级联运算:
vconcat=concat(vnew,u)
(5)
新的嵌入表示vconcat输入到三层的DNN后,得到重新编码后的用户嵌入表示:
unew=f(w2·g(w1·vconcat+b1)+b2)
(6)
式中:w1、b1、w2、b2分别属于输入层到隐藏层,隐藏层到输出层的权重矩阵和偏置项,unew是重新编码后的用户嵌入表示,f、g是两个激活函数,分别是线性函数和ReLU函数。
最后,重新编码后的用户嵌入表示unew和经过信息聚合的物品嵌入表示vnew输入到函数f:Rd×Rd→R,得到用户对物品的交互概率,即感兴趣程度:
(7)
式中:函数f是内积函数。
5 学习算法
模型的损失函数由两部分组成,分别为交叉熵预测损失和L2正则化项:
(8)
θ是模型参数,包括聚合函数agg的权重和偏置,用户的嵌入表示和知识图谱中所有节点的嵌入表示,以及深度神经网络的模型参数。Lbase是二分类问题的叉熵损失函数:
(9)

6 实 验
6.1 数据集
我们在以下两个公共数据集上开展实验,实验结果表示本方法的性能超过KGCN、KGNN-LS等主流方法。
MovieLens-20M[4]:该数据集是在电影推荐中广泛使用的基线数据集,描述了电影推荐服务MovieLens的5星评级和用户评分记录。包含138 159名用户对16 954场电影的13 501 622条评分数据(评分从1到5),所有用户都评价了至少20部电影。依据该数据集构建的知识图谱包含102 569个节点,32条不同类型的边,以及499 474条三元组数据。知识图谱中包括了不同类型的节点,有的节点表示某场电影,有的节点表示某位导演等。
Last.FM:该数据集包括Last.FM在线音乐平台两千多个用户的收听数据,包含1 872名用户对3 846首音乐的42 346条交互数据。依据该数据集构建的知识图谱包含9 366个异质节点,60条不同类型的边,以及15 518条三元组数据。
由于以上MovieLens-20M公共数据集的交互记录是用户与物品的显式评分数据,需要将其转化隐式的交互,我们将评分大于阈值(设置为4)的交互数据归类为正例样本,反之划分为负例样本,然后将所有交互数据的60%划分为训练集,20%划分为验证集,20%划分为测试集。

表1 数据集统计
本文在点击率预测(CTR prediction)的实验场景下,使用AUC和F1评估指标预测模型的好坏。实验的软件环境为Windows 10操作系统、Python 3.5、TensorFlow 1.5.0和NumPy 1.16.0,硬件环境为i7-5500U,内存4 GB。
6.2 实验参数设置
本文将模型训练轮数设置为10轮,知识图谱邻居信息聚合中随机选择的邻居节点数量为6个,用户和知识图谱实体的嵌入表示维度为16(电影数据集设置为32),每批训练样本的数量为128(电影数据集设置为65 536),L2正则化超参数为1×10-4,学习率设置为5×10-4,重新编码用户嵌入表示的DNN的三层模型分别为16、64、16(电影数据集设置为64、64、64)。
6.3 对比模型
(1) CKE[5]:该模型通过将知识图谱、纹理信息和视觉信息融合到协同过滤模型,获得物品的嵌入表示向量,本文仅考虑融合知识图谱辅助信息的CKE模型。
(2) PER[2]:将知识图谱看作一个异质的信息网络,通过基于元路径的方法获得用户与物品之间的交互的嵌入表示。
(3) RippleNet[7]:用户的爱好在知识图谱多跳节点的范围内传播,基于嵌入表示的方法获得图谱节点的嵌入表示,基于元路径的方法丰富用户的嵌入表示。
(4) KGCN[8]:基于图卷积神经网络的方法,在知识图谱上聚合邻居节点的信息,来丰富每个节点的嵌入表示,以获得更好的推荐。
(5) KGNN-LS[21]:在KGCN的基础上,使用标签平滑的方法平滑知识图谱节点的标签,通过学习得到图谱节点的嵌入表示。
(6) LightGCN[11]:该方法提出一个去掉对于协同过滤算法来说是冗余的特征转换和非线性激活函数的轻量级图卷积神经网络,为防止节点特征的过度平滑,节点的最终嵌入表示由各层学习到的嵌入表示线性组合得到。
6.4 实验结果
本文在MovieLens-20M和Last.FM数据集上,将我们的模型与以上几种模型做性能比较。我们在点击率预测推荐情景下,使用AUC和F1两个评估指标评价模型,表2是实验结果。

表2 点击率预测的实验结果
我们提出的方法和以上6种基准模型相比,在两个公共数据集的4个评价指标均排在第一位,AUC和F1 Score比KGNN-LS模型分别提高了0.2%、0.4%、0.4%和1.5%,其中F1 Score评价指标优于目前最新的基于图神经网络的方法(LightGCN),由于LightGCN是在全图的拓扑结构上进行卷积运算,该方法在现有硬件设施下无法扩展到MovieLens-20M这个比较庞大的数据集上开展实验。实验结果证明本文提出的方法甚至优于KGCN、KGNN-LS这两个主流方法。
本文模型的性能全面优于以上方法的原因是:(1) 结合知识图谱辅助信息,利用图卷积网络,迭代地聚合知识图谱中邻居节点的信息,挖掘潜在的节点之间的相似性;(2) 引入了注意力机制,在聚合邻居节点信息的过程中,根据用户对知识图谱中各个节点的具体兴趣赋予不同的权重进行信息聚合;(3) 本文使用一个DNN网络结构对用户嵌入表示重新编码,先通过将用户嵌入表示和物品嵌入表示连接起来,输入DNN,再利用重新编码后的用户嵌入表示与物品嵌入表示做内积。而KGCN和KGNN-LS这两个方法中的注意力机制是用户嵌入表示和图谱中边关系的嵌入表示作内积的,该注意力机制忽略了用户的具体偏好,不利于性能的提升,以观看电影为例,用户会喜爱某部电影的原因一般是喜欢电影的某位主角、导演或者某种类型,其原因是具体的、多种多样的,而不能笼统地认为用户偏爱主角或者导演这一抽象的概念。因此,我们的方法能获得比其他方法都大的性能提升。
表3展示了使用DNN对用户的嵌入表示重新编码,然后使用内积运算计算用户对物品的感兴趣程度的优越性。

表3 用户嵌入表示重新编码的性能对比
重新编码用户嵌入表示可以获得较大的性能提升,AUC和F1两个评价指标在Last.FM数据集上分别提升了1.8%和2.8%。本文认为能获得较大性能提升的原因有:(1) DNN网络结构学习的内容是用户特定于某个物品的感兴趣程度,首先在已知用户嵌入表示的基础上(即了解用户的偏好),结合物品的嵌入表示,最后输出特定于该物品的用户偏好;(2) 用户嵌入表示与物品嵌入表示之间存在丰富的语义信息,如何对嵌入表示进行有效地建模以生成高质量的推荐是一个重大问题。
同时,我们还对聚合邻居节点信息时选择的邻居节点数量进行分析,表4是不同的邻居节点数量下的模型性能比较。结果表明邻居节点数量选择6时模型性能最佳,这是因为当邻居节点数量较小时,没有充分挖掘相邻节点的信息,当数量较大时,邻居信息可能会混入噪声。
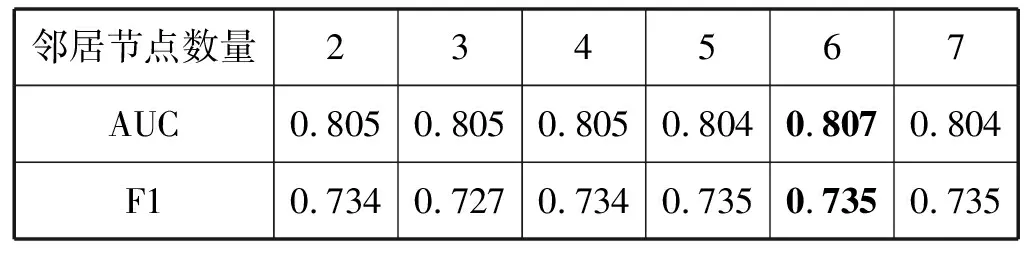
表4 不同的邻居节点数量下的AUC和F1评价指标
7 结 语
本文将知识图谱的辅助信息结合到推荐任务中,通过基于图卷积神经网络的方法迭代地聚合图谱中每个节点两跳以内的邻居节点信息,还在聚合邻居信息的过程中应用了注意力机制,根据用户的具体偏好赋予邻居节点不同的权重,使每个节点都获得丰富的邻居语义。此外,本文还对知识图谱学习得到的用户和物品的嵌入表示进行建模,通过深度神经网络重新编码用户嵌入表示,重新编码后的嵌入向量描述了用户特定于该物品的特征。我们提出的方法在MovieLens-1M和Last.FM两个数据集上都取得了较好的效果。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少先队活动(2020年12期)2021-01-14 01:47:40
电子制作(2019年11期)2019-07-04 00:34:38
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
