
基于Transformer的英文粘连词还原方法
2023-09-04 09:32朱鑫洋迟呈英战学刚
计算机应用与软件 2023年8期
朱鑫洋 迟呈英 战学刚
(辽宁科技大学计算机与软件工程学院 辽宁 鞍山 114000)
0 引 言
自然语言处理包含许多任务,它们大多需要语料库的支撑,例如,神经机器翻译的性能就严重依赖于语料库的数据规模和数据质量[1],语料数据中往往存在重复、缺失和不一致等问题,任务性能会因此受到较大的影响。数据清洗的目的就是为了解决数据问题,保证数据质量,提高机器翻译性能。
通过对多语言的双语语料库研究分析发现,英文数据中经常存在一些空格丢失多词粘连的情况,以下统称为粘连词。如:“In just three years, more than 800 schools have been built to educate thousandsof girls.”中的“thousandsof”,很明显该词并不是复合词,而是短语相连。数据中还有大量的介词名词相连的粘连词。造成词粘连的主要原因有输入错误、转换错误(如删除换行符而不是用空格替换)、OCR错误(原始文档或手写文本质量差)和传输错误等。为了进一步保障数据质量,本文针对英文中出现的粘连词问题进行处理。经研究考察发现,并没有针对此问题的具体解决方案,仅在Towards Data Science学习网站上看到了由Wolf Garbe提出了使用贝叶斯分类器的方法,但并没有给出实验结果。我们尝试把该问题看成序列到序列的任务,2014年Sutskever等[3]为了解决神经网络对序列到序列任务不适用的问题,提出了一种端到端的神经网络机器翻译构架。它具有丰富的源于句表征和表示局部结构的灵活性。同年,Bahdanau等[7]使用固定长度向量提高编码器-解码器架构性能。2016年Google[5]提出了基于自注意力机制的模型构架Transformer,这种构架可以建模各种自然语言处理问题,更好地处理序列到序列的任务,并在多项任务中取得了最好成绩。
基于上述研究,本文尝试复现基于贝叶斯分类器的粘连词还原方法,并提出一种基于Transformer模型的英语粘连词还原方法。
1 基于贝叶斯分类的粘连词还原方法
一个字符串可以用几种方式划分。每个不同的划分称为“组合”,组合有很多种,在长度为n的字符串中,潜在字边界的数目为n′=n-1(在字符串的每个字符之间),这些位置中的每一个实际上都可以用作词界或不用作词界。每个长度为n的字符串可以被分割成2n-1个可能的组合。需要判定该组合是否是有效的分词,即它由真实的单词组成。
采用递归方法列举所有可能的组合,将字符串分割成子字符串(候选词),并在字典中查找这些候选词,所有子字符串都是有效词汇将作为结果返回。例如对于“ISIT”作为输入,生成所有8种可能的组合如表1所示。

表1 组合示例
其中两个组合由真实的英语单词组成,是有效的切分组合。那么,在返回的两种组合应该怎么选取,在此借助贝叶斯分类器选取最佳的组合。
应用贝叶斯分类器的基本思想是:在英文语料库中粘连词的组合结果取决于该词所处的上下文语境c,如果某个词w有多个组合方式si(i≥2),那么,可以通过计算argmax(si|c)确定w的组合方式。
根据贝叶斯公式:
(1)
计算式(1)时,可以忽略分母,并利用独立性假设得:
(2)
在实现中,将概率P(vk|si)和P(si)的乘积转换为对数加法得:
(3)
这里的概率P(vk|si)和P(si)都可以通过最大似然估计求得,因为训练语料数据量小,会存在概率参数没有被统计到的情况,存在数据稀疏问题[8]。为避免参数“0”对计算的影响,采用数据平滑技术(Data Smoothing Technique,DST),本文采用加法平滑方法(additive smoothing),其基本思想是使公式给出的方法通用化,假设发生的次数比实际统计次数多δ次,0≤δ≤1(本文选取δ=1),那么:
(4)
(5)
式中:N(w)是整个语料库大小;N(si)是训练语料中组合方式si出现的次数;N(vk,si)是训练语料中粘连词的组合方式si出现时,上下文vk出现的次数。
2 基于神经网络的粘连词还原方法
Transformer模型是2017年Google的Ashish Vaswani等[9]提出了一种基于自注意力机制(self-attention)的模型构架,其抛弃了传统的构架,可以完全地进行并行运算。Transformer模型构架如图1所示。
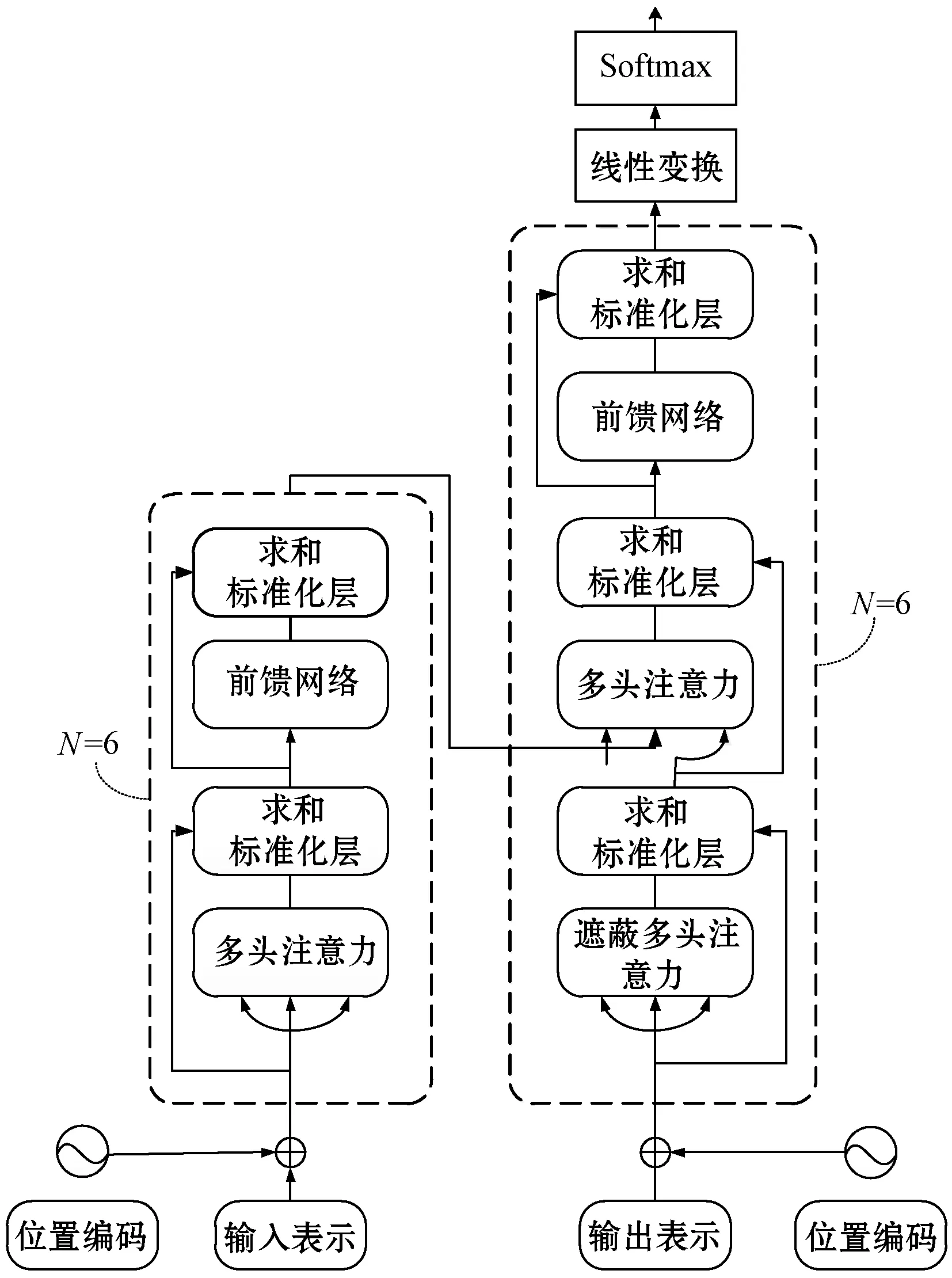
图1 Transformer模型框架图
可以看出,对于给定的输入数据,首先要转换成对应的Embedding,Transformer中的Embedding操作不是普通的Embedding而是加入了位置信息的Embedding,称之为Position Embedding。因为Transformer没有使用循环或卷积计算,能够并行处理输入序列,但缺失序列信息,需要利用序列的分词相对或者绝对位置信息,位置信息计算如下,其中:pos代表的是第几个词,i代表embedding中的第几维。
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(6)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(7)
编码器由多个相同的层堆叠在一起,每一层又有两个支层,第一个支层是一种多头的自注意力实现,输入序列x经d(dmodel=512)的嵌入矩阵映射为词向量矩阵e,词向量矩阵分别经过不同线性变换产生Q、K和V,将Q、K、V线性映射h次,并做h次点乘注意力运算后结果拼接起来。
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)
(8)
(9)
(10)
第二个支层是一个简单的全连接前馈网络,在注意力机制之后,经过简单的正则化与残差连接,隐层向量进入全连接的前馈网络:
FFN(x)=max(0,xW1+b1)W2+b2
(11)
至此编码端单层结束,以上重复6次构成完整编码器结构。解码端与编码端类似,同样由6层注意力机制和全连接前馈网络构成,但多了一个多头注意力机制。
3 实验与结果分析
3.1 数据集
选取数据集UN corpus French-English(来源:July 15-16,in conjunction with ACL 2010 in Uppsala, Sweden)中的英文单语部分,对其进行乱码过滤、句首特殊字符替换、引号修正等数据清洗工作。从中随机抽取2 020 000条数据,其中2 000 000条数据用作训练集(贝叶斯分类器中的语料库),20 000条数据用作测试集,另选取200条真实数据,通过人工校正作为真实数据集进行测试。
深度神经网络具有大量的参数,需要海量的训练数据。利用真实数据进行训练,人工标注的成本会大大增加,因此我们需要使用一些技术对已有数据进行数据构造。数据构造基于训练集的句子,为了让神经网络模型通过大量的粘连词信息进行拟合,我们启发式的设置含有粘连词的数据占整体的0.7,后续会对粘连词占比做进一步分析;根据已有的问题数据进行抽样,统计出粘连词粘连个数如表2所示。

表2 粘连词粘连个数分布
在统计粘连位置时发现句首句尾粘连的概率更小一些,句首和句尾即第一个位置和最后一个位置的概率相等均为其余的1/3。
利用random()函数在遍历文件时,每读取一句得到一个0-1之间的随机数x,按照70%占比构造伪粘连词数据,即若x≤0.7则将该句子作为含有粘连词的句子,若x>0.7则不做处理,直接输出数据(句对)。构造粘连数据要确定粘连词数,根据粘连词数的分布,利用random()函数得到一个[0,1]均匀随机数m,m的不同取值对应着构造该句话粘连词的粘连词数gram,gram的取值结果如下:
(12)
确定可选取的粘连位置n,n的取值:n=words-gram+1,其中words为该语句的单词数目;根据粘连位置分布得知,句首和句尾即第一个位置和最后一个位置的概率相等均为其余的1/3,因此按比例构造随机数的范围[1,x],其中x=3×n-4,根据随机范围映射粘连位置的周期为T=x/(n-1),得到的随机数ran映射的位置信息为(ran-1)/T。按照得到的位置信息去空格构造粘连词,将构造好的数据进行输出,将经上述步骤处理后的数据作为源语,原始数据作为目标语输出。
3.2 数据预处理
将英文句子按照标点符号、空格进行切分,并且整理了特殊的不需要切分的形式,如A.D、e.g、U.S等形式不做切分。在机器翻译任务中,为了解决数据稀疏以及集外词(Out of vocabulary,OOV)的问题,Luong等[10-13]曾提出字符集神经机器翻译解决此类问题,2015年Sennrich等[14]提出了子字单元(subword unit)序列模型和子字切分方法(Byte Pair Encoding,BPE),该方法可以将单词切分成子词单元,有效缓解了机器翻译中罕见词和未登录词较难翻译的现象。BPE子词切分可以有效减少词表的大小,帮助训练。
将含有粘连词的句子作为源语,将原始句子作为目标语。面对含有粘连词的句子,模型不能识别粘连词,学习信息会比较模糊,因此在预处理阶段对含有粘连词的源语句子采取不同的数据处理策略,首先想到的处理方式是将整个句子全部粘连到一起,这样模型能学习到最全面的还原信息,但这样的数据会词表过大,目前现有的机器翻译模型和设备都不足够支持训练,因此本文放弃这种处理方式。选定以下三种数据处理策略。
(1) 策略一:数据处理方式是将句子按照字符全切分,全切分的数据不需要对其进行分词、BPE字词切分等操作,面对全切分数据模型不需要判断哪些是粘连词,只需要学习如何拼接单词。策略一预处理如表3所示。

表3 策略一预处理示例
(2) 策略二:数据处理方式是借助外部的规则来帮助判定粘连词,在分词的基础上,将判定为粘连词的次按字符切分,其他词汇不变,同时为了区别于正常的空格,对于粘连词的切分标识设定为“^^”,e而后对数据进行BPE字词切分。策略二预处理如表4所示。

表4 策略二预处理示例
(3) 策略三:数据处理方式是只做分词和BPE子词切分。通过对策略二预处理后的数据观察发现判定的粘连词过多,有很多正常词汇会被认定为粘连词,因此尝试直接分词、BPE切分。策略三预处理如表5所示。

表5 策略三预处理示例
3.3 实验设置
本文采用Transformer模型完成训练,由于本文任务较小,采用标准的Transformer模型进行训练时,容易梯度爆炸,增加训练轮数,因此本文适当调整了Transformer的模型参数,使其更适于我们的任务。实验参数设置如下:编码端与解码端都使用4层隐藏层的结构,多头注意力[15]num_heads设置为8,隐藏层大小hidden_size为256,词向量加入位置编码信息,batch的类型为单词,单批数据量batch_size设置为4 096,学习率0.000 5,预防模型过拟合dropout设置为0.1,最大句长过滤为512,训练轮数为15轮。训练前使用BPE做字词切分,BPE参数设置为10 000。
3.4 结果分析
首先对比利用贝叶斯分类器的还原方法与在Transformer模型中不同的数据处理策略在两个测试集上的准确率,准确率如表6所示。
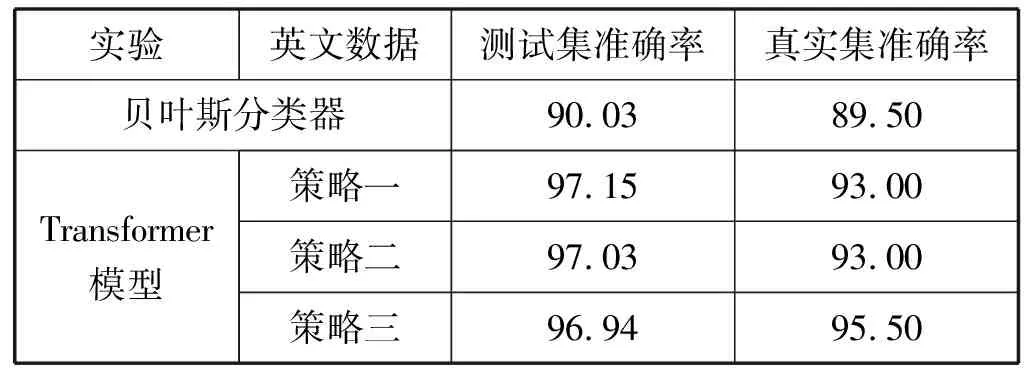
表6 两个测试集上的准确率(%)
基于贝叶斯分类器的方式,在两种数据集上的差异最小,但是准确率比较低,经分析发现原因有两个:其一是介词在整个语料库中(训练语料)出现的频数较多,在通过贝叶斯计算时,会因为介词在上下文出现的频数大,导致计算结果会有一个很大的偏向,致使结果并不准确;其二是该方法更倾向于将复合词切分开,如:timeout->time out,虽然这类复合词被切分开并不影响理解,但是在计算准确率时会判定切分错误,并且如果所有复合词均被切分,在后续的自然语言处理任务中会导致训练从没见过复合词,这样是不合理的。
基于Transformer模型的方式,从结果来说,整体准确率都高于基于贝叶斯分类器的方法,但不同的数据处理策略准确率有了差别:
(1) 策略一:训练集按字符切分在测试集上的准确率是最高的,但在真实数据中的准确率却是最低的,根据结果分析发现两个问题,其一是同贝叶斯分类一样,复合词被切分开,其二是有“抢字母”的情况,模型更倾向于组合一个最大长度的词汇,如表7所示。

表7 错误示例
模型输出的结果是将‘Pradesh’中的sh拼接到了are上形成单词‘share’,从结果上讲,新的组合方式确实是两个完整的单词,但是很明显这是错误的。
(2) 策略二:粘连词按字符切分在测试集上的准确率仅次于第一种策略,但在真实数据中的准确率相比全字符切分有提升,根据结果分析发现该种方式存在有增译漏译的情况,这里说的增译漏译是指在原有的词汇基础上,对词汇本身增加或减少了字母,使其与原词汇不一致。除此之外,在判定句子中粘连词的过程中借用了外部词典,但没有字典是完整的,字典中缺少不常见的单词,如:新单词、外来单词等,常见词与这些不常见词粘连,就会判定不出该词是粘连词,而将其作为未登录词,因此外部词典所包含的词的丰富性也影响了训练结果。
(3) 策略三:训练集做分词、BPE的方式在测试集上的准确率最低,但在真实数据中的准确率却最高,根据结果分析在错误句子中有增译的情况,模型偏向将动词转换形态。
针对增漏译的问题,我们合理怀疑,在构造数据时设定粘连词占比过高(0.7),导致模型更倾向于更愿意更改句子。为了验证粘连词占比是否对准确率有影响,分别构造了粘连词占比10%、20%、…、90%的伪粘连词数据,在不更改模型参数的情况,使用在真实数据上表现更好的策略三处理数据进行训练,训练后准确率如图2所示,横坐标是粘连词汇占比,纵坐标是准确率。

图2 不同粘连词占比的准确率变化情况
图2中,模型准确率随着训练集中粘连词占比的增加大致呈上升趋势,在粘连词占比70%时,准确率最高,经过70%之后逐级降低,在90%的地方降低幅度较大。不同的粘连词占比在各自的测试集上表现良好,在真实测试集上表现略差,相较于测试集平均低了2百分点,准确率的浮动趋势与测试集基本相符合。由此可以看出增漏译等情况的出现受训练集中粘连词的占比影响不大。
在工程实践中,尤其是数据清洗的工作,理想情况是更改的句子都是正确的,并且不会因为该清洗造成其他错误问题,因此在结果处添加后处理操作,即判断输出句子与源语句子的全连接是否一致,不一致则输出原句,这样就可以新的错误句子的出现,后处理操作如图3所示。
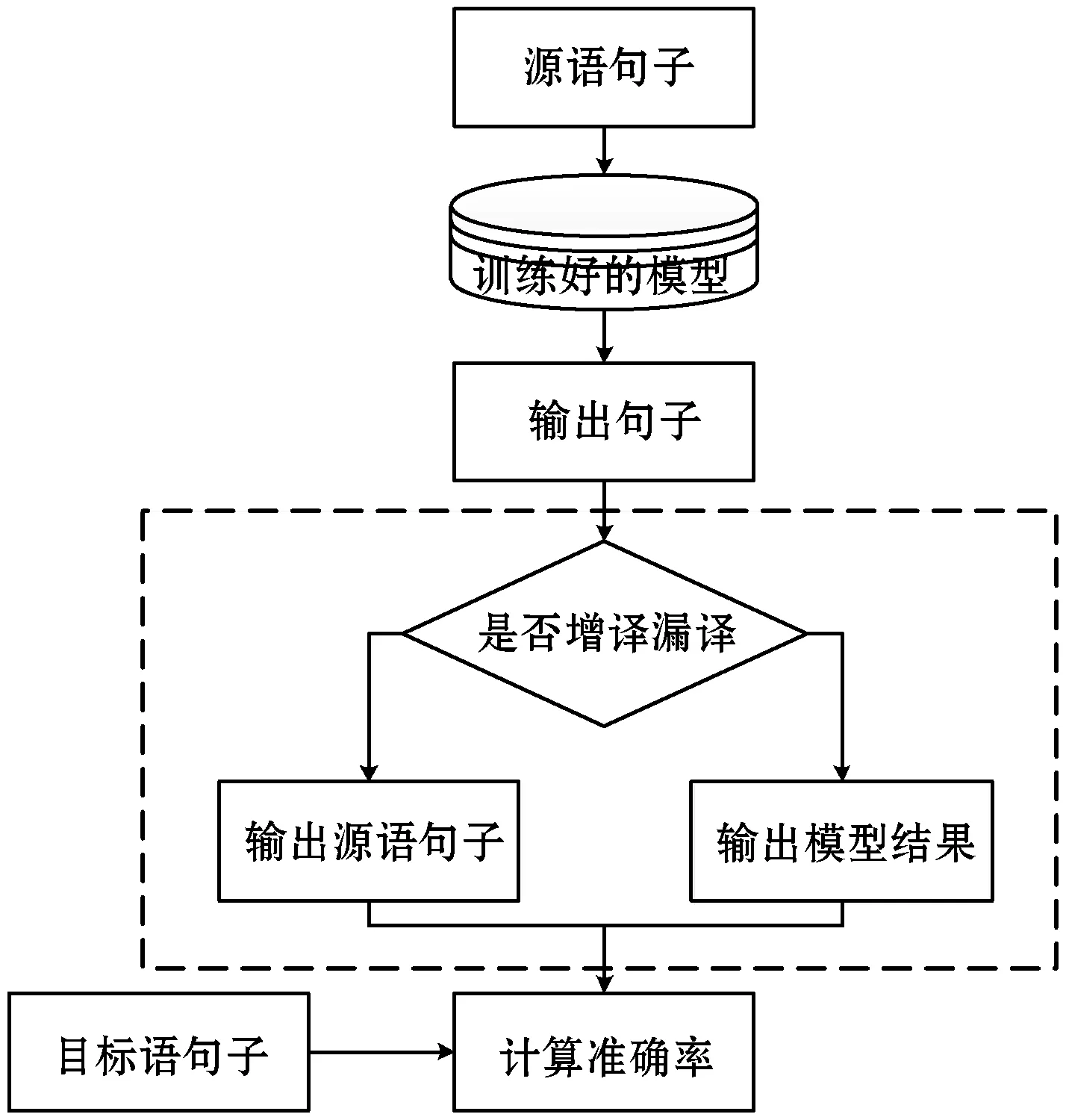
图3 后处理流程图
添加后处理后,统计准确率结果如表8所示。
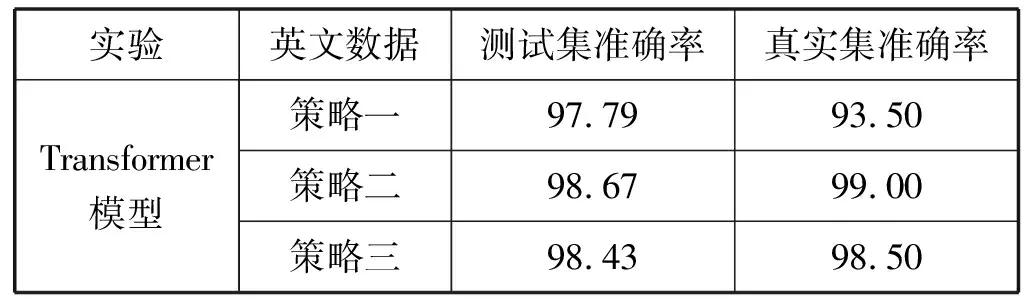
表8 添加后处理操作后的准确率(%)
经过后处理之后,准确率都有明显的提升,通过对实验结果的分析发现99%以上的粘连词都能被准确识别并还原,但在同一句话中,会出现其他复合词被切分开,或者增译的问题,这类句子会被判定为错误句子,即使真正的粘连词已经被还原。经过后处理,对粘连词按字符切分的策略二训练出的模型准确率最高,相较于之前提升了6百分点,提升最快,这说明该种策略导致模型更容易出现增译漏译问题,排除增译漏译的情况后,该策略的准确率提升到了99%。整体表现最佳的是只对数据做分词、BPE的处理策略三,该策略在测试集和真实测试集中均有很好的表现,并且经过后处理后准确率达到了98.5%。
4 结 语
本文复现了基于贝叶斯分类器的粘连词还原方法,同时实现了基于Transformer模型还原粘连词的方法,该方法结合原神经机器翻译模型的数据拟合特点,经过数次迭代和筛选,最终训练出了一套适用的模型。
实验结果表明,基于Transformer模型的粘连词还原方法行之有效,相较于基于贝叶斯分类器的方法能够更准确地识别并还原英文粘连词。基于Transformer模型的粘连词还原方法中,对训练数据采取不同的处理策略,达到了不同的效果,其中直接对训练数据进行分词、BPE之后训练,得到的模型效果在真实测试集上表现最佳;在Transformer基础上添加后处理操作后,对粘连词进行字符切分的数据处理策略训练出的模型效果最佳。本文方法具备可迁移性,其他单词之间使用空格分隔的语言,面对粘连词问题,可以采用同样的方法清洗数据。在未来的工作中,我们会依照此方法,尝试构建其他语言方向的粘连词还原规则,同时考虑在模型训练中引入数据增强技术。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子测试(2018年1期)2018-04-18
数学物理学报(2017年5期)2017-11-23
数理化解题研究(2017年4期)2017-05-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
电测与仪表(2014年15期)2014-04-04
