
改进DeeplabV3+模型的河流水体提取
2023-09-02 02:25:46张晗涛胡荣明姜友谊胡亚轩
遥感信息 2023年3期
张晗涛,胡荣明,姜友谊,胡亚轩
(1.西安科技大学 测绘科学与技术学院,西安 710000;2.中国地震局第二监测中心,西安 710054)
0 引言
随着遥感技术在自然资源监测的广泛应用,如何准确地获取河流水体信息已经成为遥感应用领域的一个关键研究方向。当前,利用DeeplabV3+[1]网络模型进行遥感信息提取已取得了较多的成就,如陈前等[2]利用DeeplabV3网络对高分遥感影像水体提取进行研究,证明了深度学习方法的有效性。Li等[3]通过密集局部特征压缩网络融合遥感图像的空间和光谱信息,从不同的遥感图像中提取水体,并与传统的水体提取方法以及U-Net、DeeplabV3+等模型进行了对比。苟杰松等[4]通过利用DeeplabV3+方法证明了在养殖水体信息提取方面,DeeplabV3+方法均高于归一化差分水体指数法和最大似然监督分类法。Chen等[5]通过改进LinkNet模型进行了寒旱区河流水体提取,并与U-Net、DeeplabV3+等神经网络模型进行了对比。
综上所述,DeeplabV3+网络虽然在遥感信息提取领域有些许成就,但是针对于高分辨率遥感影像进行河流水体信息提取仍存在研究不足。本文通过建立不同骨架网络模型的DeeplabV3+网络,探究不同骨架网络模型在河流水体提取的应用能力,同时针对研究中所存在的小目标河流提取精度不足的问题,对DeeplabV3+网络模型进行了优化,提出了一种基于改进DeeplabV3+网络的河流提取方法。
1 研究区概况与数据源
1.1 研究区概况
为了探究深度学习模型在不同遥感影像中河流提取的应用能力,选择山区、城市、云雾等4种不同遥感影像下的河流水体作为研究对象。
1.2 数据源
本文遥感影像数据集采用的是高分二号和高分七号影像。实验数据集主要是由遥感影像数据以及人工经过目视解译,利用Labelme图形图像注释工具进行标注的二值图标签数据组成。影像标签数据采用的是Pascalvoc数据集格式,影像分辨率为1 024像素×1 024像素,共由7 551张训练数据构成。该数据集主要由长江流域水系构成,影像采集时间主要为第二季度,去除了结冰水面干扰。河流水体语义分割训练数据集如图1所示。

图1 河流水体语义分割训练集
2 研究方法
2.1 DeeplabV3+网络结构
DeeplabV3+网络结构主要分为编码层和解码层两部分。编码层的主体由两部分组成,首先是深度卷积神经网络(deep convolutional neural networks,DCNN)[6],其通常采用的是Xception或ResNet[7-8]等常用的分类骨架网络,其次是带有空洞卷积的空间金字塔池化模块(atrous spatial pyramid pooling,ASPP)[9]。空洞卷积是在不改变特征图大小的同时控制感受野,多尺度地获取影像关键信息。空间金字塔池化模块则是通过采用不同空洞率的空洞卷积来进一步提取多尺度信息。解码层主要是通过采用1×1的卷积对提取到低层次(low-level)特征信息进行压缩,然后通过与高层次(high-level)特征信息进一步融合,其次将融合后的结果通过3×3的卷积来细化特征,最后经过一个4倍上采样来输出最终结果,进而提升分割边界准确度。
2.2 改进的DeeplabV3+网络结构
本文针对河流提取研究,对DeeplabV3+网络结构进行了改进,改进后的模型结构如图2所示,网络主体同样分为编码层和解码层两大部分,其中深度卷积神经网络所采用的是在本河流提取研究中表现较为优秀的ResNet-50骨架网络,具体的改进由编码区改进ASPP模块和解码区增加不同层次的输入图像特征构成。
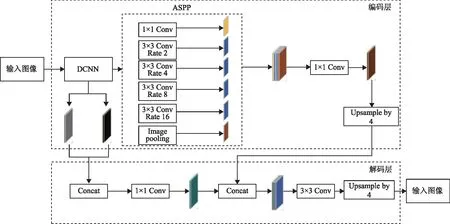
图2 改进的DeeplabV3+网络结构
1)编码区改进空间金字塔池化模块。空间金字塔池化模块主要作用是对输入的特征图进行多尺度语义信息提取,其由多个卷积操作和全局平均池化操作并行构成,其中除了1×1的卷积外,其余的卷积核都带有不同的空洞率来进行卷积操作[10]。之所以要带有不同的空洞率进行卷积,是因为随着网络模型逐步提取图像特征,原始特征图的分辨率会逐渐变小。此时,携带着空洞率值较大的卷积核,更加适合分割大尺寸目标物。同样地,携带着空洞率较小的卷积核更加适合分割小尺寸目标物。因此,本研究为了增加模型分割不同大小目标的能力,在ASPP模块中使得网络结构具有多尺度的卷积核。如图2所示,在该模块,本研究为了能够提取出小目标的狭长河流水体,将原始DeeplabV3+网络空间金字塔池化模块中空洞率值为6、12、18的空洞卷积优化为空洞率值分别为2、4、8、16的空洞卷积操作。
同时,本研究将空间金字塔池化模块中原有的标准卷积替换成深度可分离卷积。深度可分离卷积中每个卷积核只考虑自己所负责的通道,而不像标准卷积那样,每个卷积核要考虑所有通道的语义信息。首先通过在逐个通道中进行深度卷积学习空间相关性,然后进行点卷积操作学习特征。深度可分离卷积以其较低的参数数量和运算成本取得了较大的优势,在训练过程中大大减少了所需参数量,同时深度可分离卷积还在对预测精度影响不大的前提下提高了网络模型的训练效率。
2)解码区增加不同层次的图像特征。在解码区部分,本文将两个经过编码区骨架网络不同层次的输入图像特征图提取出来,相比于原始DeeplabV3+网络结构实现了同时提取两个特征图映射作为解码器的特征输入信息,并将提取出的两个低维特征以融合的方式使其更具有丰富的低维特征信息。然后,对融合后的低维特征和编码器中获取的高维特征进行处理融合,再次丰富完善特征信息。最后,在经过3×3卷积和4倍的上采样处理后,将特征信息进行细化,恢复特征所应具有的空间信息,最终将得到的分割结果图进行输出[11]。
3 实验结果与分析
实验程序所采用深度学习框架为PyTorch。超参数[12]设置为:初始学习率0.003,权重衰减0.000 2,总共进行100次训练迭代,批尺寸大小(batch size)为12。本次研究中采用平均交并比(MIoU)为主要的评价指标。MIoU是语义分割领域常用的评价指标,代表模型语义分割预测的结果与其人工创建的标签真值之间的像素重合度。本文中MIoU的取值范围为[0,1],如果MIoU值越大,则说明预测的分割结果图越准确[13]。
3.1 不同骨架网络模型对比
通过目视解译表1中的不同骨架网络结构分类结果可以发现,4种骨架网络结构对于大面积区域范围的河流水体均进行了有效的提取,但是对于小面积区域范围的河流水体,不同骨架网络结构之间的提取能力相差较大,这一点在区域(a)和区域(b)中表现明显。其中Xception骨架网络的河流水体提取结果与ResNet骨架网络的河流水体提取结果相比差距较大,提取结果不够完整,存在着明显的间断与缺失漏提,在小面积河流水体研究区表现最为严重。纵观4块区域的影像分类结果,ResNet-50的河流水体提取效果相较于其他网络结构存在着小幅提高,这一点在区域(b)和区域(d)中有明显的体现,同时在云雾的山区河流水体研究区表现出较好提取效果,但在城市区域的细长河流水体区域存在明显的漏提。

表1 不同骨架网络结构分类结果
3.2 不同方法河流水体提取对比
本文选取了最邻近分类法、随机森林分类法、支持向量机分类法(support vector machines,SVM)[14]、原始DeeplabV3+模型法、改进DeeplabV3+模型法5种分类方法进行对比,各算法提取结果如表2所示。其中区域(a)、区域(b)、区域(c)以山区河流水体为主,区域(d)以城市河流水体为主,各区域中均包含了难以提取的小目标河流水体。区域(b)包含了云雾阴影干扰,区域(c)和区域(d)更是在河流水体颜色上与区域(a)和区域(b)进行了区分,以此验证本研究模型在不同河流水体的提取适用性。
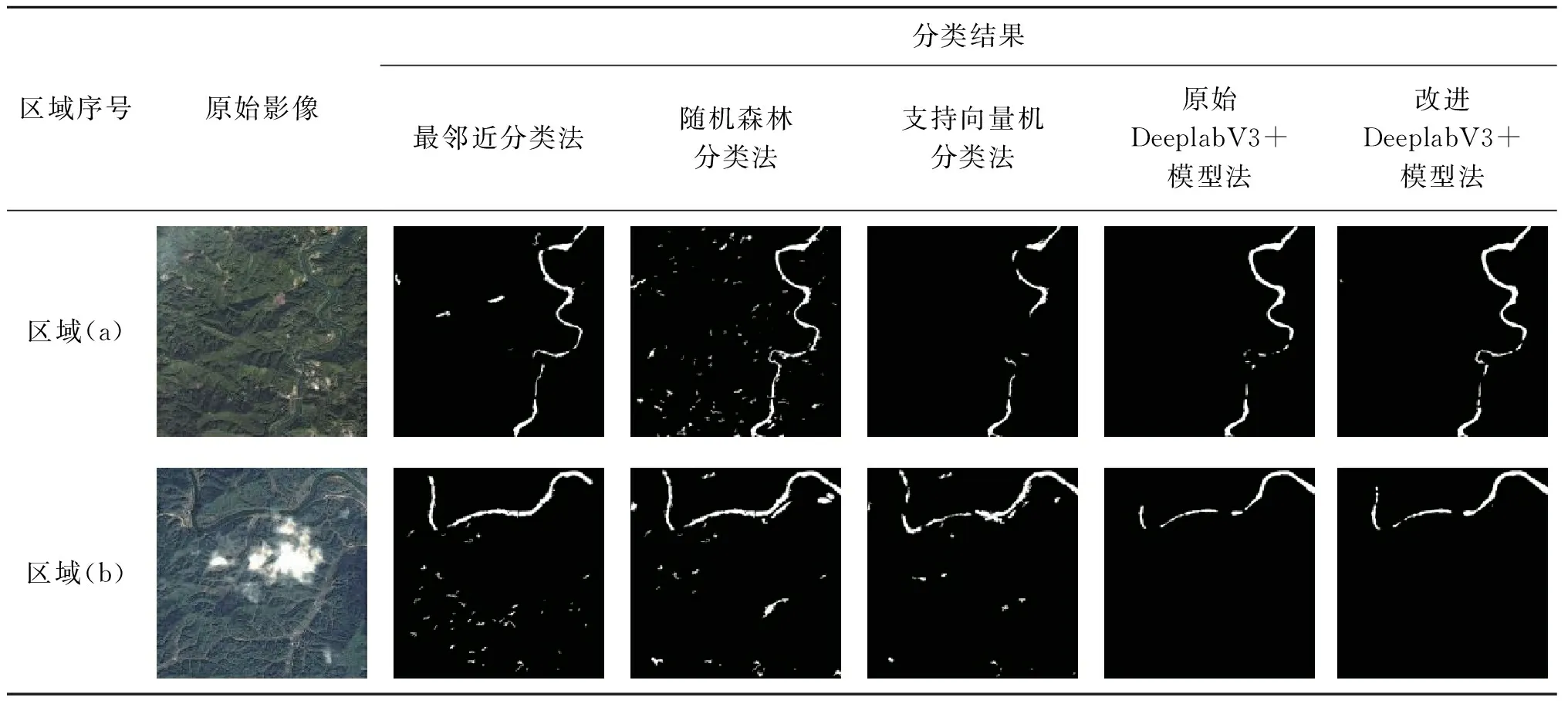
表2 不同方法河流水体分类结果
通过目视解译表2中的河流水体提取结果可以发现,采用最邻近分类方法进行河流水体的提取,可以较为精确地提取到大面积区域的河流水体,但是在阴影和小面积河流水体区域的容易造成漏提,同时在光谱和纹理与河流水体相似的区域容易造成误提。采用随机森林分类方法和SVM方法进行河流水体的提取,虽然能很好地区分出了水体,但是在非水体区域,尤其是山林区域、小面积河流水体和狭长状地物区域,由于光谱和纹理相似性问题容易出现误提和漏提,同时影像噪声还会干扰分类结果,导致小面积河流水体提取困难。原始DeeplabV3+方法模型较好地提取出了大面积的河流水体,同时还没有受到非水体区域的影响,很好地将河流水体和非水体区域区分了出来,河岸边缘处的分类结果也比较理想,较随机森林分类方法和SVM方法的分类结果更加光滑和精确,但是原始的DeeplabV3+模型方法对于小面积区域的河流水体和细长河流水体的提取能力不足,存在较为严重的漏提现象。本文针对此现象,提出了改进DeeplabV3+模型方法来提取河流水体,整体效果得到了一定的提升。改进后的DeeplabV3+方法不仅延续了原始方法能够很好地区分水体和非水体区域,较为精确地提取到河流水体区域的同时,通过增强对小面积的河流水体的提取,有效地对小目标、小面积河流和细长河流提取能力不足的问题进行了改善。
3.3 不同方法提取结果精度评价
本文通过人工标注的河流水体数据作为参考图像,分别对实验中的5种提取方法和4块研究区域进行了精度评价,结果如表3和表4所示。根据表中数据可以得出,在误提率方面,随机森林分类方法的误提率最高,达55.74%;SVM方法和最邻近分类方法的漏提率次之,达51.37%和45.85%,主要是因为小目标河流水体区域的周围存在较多的干扰以及区域(b)中河流水体和植被纹理相似,导致传统方法提取结果不够精确。但是在区域(b)中,原始DeeplabV3+和改进DeeplabV3+模型方法的误提率明显低于传统提取方法。同时在其他研究区域,深度学习的误提率也明显低于传统方法。可以由此得出,深度学习方法在分类精确度上是明显优于传统分类方法的。在漏提率方面,改进DeeplabV3+模型方法的漏提率最低,达2.61%;SVM方法的漏提率最高,达42.36%。通过对比原始DeeplabV3+模型方法和改进DeeplabV3+模型方法的漏提率,可以看出本研究DeeplabV3+模型方法的改进取得了明显成效,漏提率相比于原始DeeplabV3+模型方法平均降低了46.97%,明显低于传统提取方法。在总体精度和Kappa系数方面,最邻近分类方法略优于随机森林分类方法和SVM方法,但都低于深度学习方法。改进后的DeeplabV3+方法较其他4种方法在总体精度和Kappa系数指标上均有提升,总体精度相比于传统方法提升了1.22%,相比于原始DeeplabV3+模型方法提升了0.19%;Kappa系数相比于传统方法提升了0.23,相比于原始DeeplabV3+模型方法提升了0.04。可以发现,改进后的DeeplabV3+模型方法的精度评价均优于其他方法。本研究所改进的DeeplabV3+模型方法可以有效区分河流水体和非河流水体区域,提高了原始DeeplabV3+模型方法的提取精度,对于原始DeeplabV3+模型方法进行了一定程度上的改善。
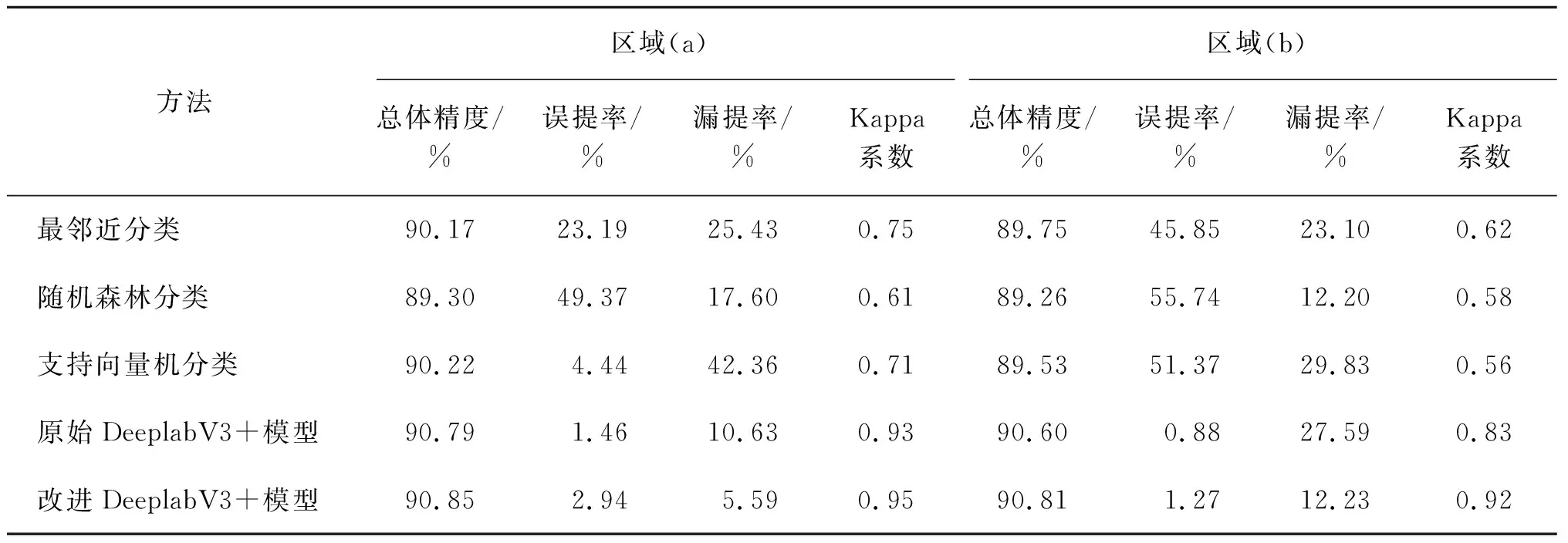
表3 区域(a)和区域(b)河流水体提取精度评价
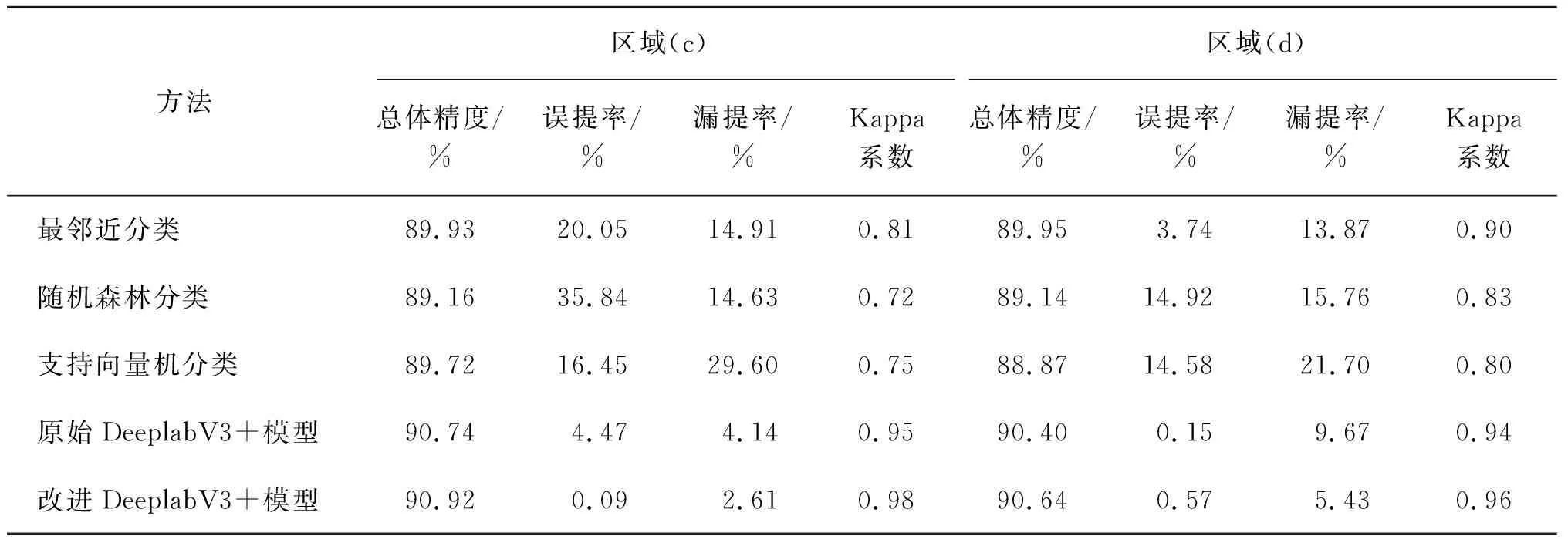
表4 区域(c)和区域(d)河流水体提取精度评价
4 结束语
本文基于高分辨率遥感影像,探究了DeeplabV3+模型在不同骨架网络模型时的河流水体提取能力,通过构建ResNet-50、ResNet-101、ResNet-152、Xception 4种不同骨架网络的DeeplabV3+模型进行河流水体提取研究的分析对比,得出了ResNet-50骨架网络相比于其他骨架网络模型具有更高的河流水体提取精度和较低的时间消耗,在河流水体提取更具有适用性。
同时本文针对小目标的河流水体,对DeeplabV3+模型方法进行了一定的改进,能有效地对小目标河流水体信息进行提取,而且具有抗云雾阴影和建筑物等干扰影响的提取适用性,且相对于原始DeeplabV3+模型方法有了小幅的精度提升,同时精度更优于最邻近分类法、随机森林分类法和支持向量机分类法等分类方法。
但是本文针对于小目标河流水体的提取研究仅获得了一定的精度改善,未能完整地提取出小目标河流水体信息。因此,如何完整地提取出小目标河流水体信息,将是进一步研究的重点。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09 22:18:32
中国新技术新产品(2020年5期)2020-05-06 03:36:28
小太阳画报(2019年4期)2019-06-11 10:29:48
散文诗(2018年20期)2018-05-06 08:03:44
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
少儿科学周刊·少年版(2015年11期)2015-12-17 20:49:15
中国煤层气(2014年3期)2014-08-07 03:07:45
