
人工智能的自动语言处理系统在社交网络分析中的应用研究
2023-08-31 18:40:24陆苗
互联网周刊 2023年15期
关键词:人工智能


摘要:在信息技术不断创新的今天,互联网已成为人们日常生活与工作生产的必备要素,尤其是在社交网络快速发展的背景下,社交网络越来越广,为人们言语交流提供了良好的网络平台,为言语交际提供了更多的便利。就社交网络分析来看,为准确提取社交网络中的语言,解决中文字词不准确及数据非结构化等问题,本文研究以人工智能技术应用为背景,分析自动语言处理系统在社交网络分析中的应用,为社交网络中字词校对、语法查错、语义校对及文本校对提供依据,以此来丰富有关社交网络语言处理的研究理论。
关键词:人工智能;自动语言处理系统;社交网络分析
引言
社交网络中汇聚了各种各样的语言信息,代表了不同人群的思想观点,这些语言具备一定的传播性与影响性,尤其是不利社会和谐发展的负面语言,或有伤害性的网络暴力语言,会对网络舆论环境造成影响。对此,为维护和谐、稳定的网络环境,构建健康的社交网络语言秩序,为社交网络健康发展提供保障,在社交网络语言处理中,提倡运用人工智能的自动语言处理系统,依靠科学技术处理的方式来对不符合社交网络发展的负面语言进行校对。本研究结合国内外文献资料,基于前人提出的研究成果,借鉴过往研究提出的思路来分析自动语言处理系统在社交网络分析中的应用,探究自动语言处理系统应用的价值与意义,从而为社交网络长效发展提供依据。
1. 自动语言处理系统在社交网络分析中的字词校对
1.1 构建语料库
为实现对社交网络语言字词的准确校对,自动语言处理系统可通过对社交网络中已发布的文章、文案等进行字词核查,对相邻字、相邻词及字词进行校对,自动检测当中错误的字词。研究以微博平台2022年某营销号发布的文章为例,字数共有326万字,运用自动语言处理系统构建容量为20.5MB的语料库。依托人工智能、大数据、云计算等先进技术分类整合相关数据,利用人工智能的特性,根据人们文章写作的用词习惯对语料库内容进行更新,为社交网络中字词校对提供保障。
1.2 查错接续关系
在语言处理中,字词存在二元接续关系,要想有效过滤社交网络中不合规的语言,在字词校对上还需结合字词间的接续关系进行查错处理,重点对字串相邻的字词关系进行校对。比如字串为S1S2…Si-1SiSi+1…Sn,自动语言处理系统在判断S和邻近字词关系时,可结合语言学二元模型理论,对Si-1与Si的关系、Si和Si+1的关系进行查错处理。基于前文构建的语料库,提出Si-1至Si转移率为P(Si/Si-1)的假设,若P达到一定阈值,可确定Si与Si-1为二元接续关系。自动语言处理系统的应用可准确认定Si是否出错,首先要确定Si-1和Si的接续关系,若为接续,则确定Si无错误,查错结果符合相关标准;若为不接续,就要还确定Si和Si+1的接续关系,若结果仍为不接续,就可确定为Si错误。
2. 自动语言处理系统在社交网络分析中的查错算法
基于社交网络语言快速传播的特点,媒体营销号在微博平台上发表的文章会快速发酵,且传播范围极广,若存在语法错误,就会产生负面舆论,从而影响营销号的运营。对此,应用自动语言处理系統的查错算法能够对社交网络中的语言语法进行分析与处理。以社交网络语言的规则库为基准,对语言的结构进行识别,明确划分语言的主谓宾结构,并以由下到上的处理方式来分别对语句结构进行校对,检测是否存在语法错误的问题[1]。从自动语言处理系统语法查错的过程来看,要先对句子进行预处理,使短句串联与捆绑,为语句的精准处理提供依据,确保查错算法在识别语法错误问题上,结果更加准确。比如对谓语语法的校对,查错算法的运用如下:
input语句:P=Q1…Qi…Qn
For i=1 to n do
if(词Qi不在语片中)
{结合规则库确定Qi能否充当谓语;}
if(Qi可充当谓语)
{添加谓语链Prdelink;
for (w=Predlink->firstword to Predlink->lasword)
if(Predlink->num=1)代表P谓语成分正确;
if(Predlink->num=0)代表P谓语缺失;}
3. 自动语言处理系统在社交网络分析中的语义校对
3.1 构建依存关系
在社交网络分析中的语义校对中,自动语言处理系统的应用能够以实例语义查错为基础,研判语句语义是否正确,分析语句结构,并通过采集网络系统中相关语句案例,通过建立集合n,对集合n中所有的语句实例和未校对语句相似度进行计算,从中选取相似度较高的实例i。比较i和未校对的语句,从中获取语义校对的查错结果。从校对操作来看,自动语言处理系统整个运作的过程虽简便,但考虑到集合n中存有较多实例,在计算语义相似度方面,需要处理的语句较多,会使工作量增加,延长了语义相似度计算的时间。对此,为充分发挥自动语言处理系统在社交网络语义校对中准确判断的效能,通过构建依存关系,能够以语义依存语法的形式来对字词句进行准确判断,依托字词句之间良好的依存关系来确定语句的语义特征,为语句相似度计算的准确性提供保障[2]。
3.2 语句相似度计算
为实现精准高效的语义查错,自动语言处理系统在语义校对中,要通过对语句相似度的计算来确保语义准确无误[3]。在语句相似度的计算中,要从字词句有效搭配相似度的角度进行考虑,须抓住每一个语句的核心词和语句中依存的有效字词。从语句结构来看,有效词可看作形容词、名词及动词等类型,此类词组能够准确表达出一段语句的语义,对这些词组的相似度进行计算是社交网络语言中语义查误的重点[4]。例句:事发后,伤员被及时送往就近医院救治。这句话中的关键词为“送往”,其搭配的字词可表现为送往-伤员、送往-医院及送往-救治等,通过对关键词和有效词相似程度的计算,不仅简化了传统语句相似度计算繁杂的工作量,在省略多个计算过程后,还能保障语句相似度计算结果的准确性,这便是语义校对中应用自动语言处理系统的价值与意义。文中公式(1)为语句相似度计算公式:
(1)
基于上述式子来看,SIM(Sen1, Sen2)是语句相似度,代表了语句字词有效搭配对匹配的总权重,PairCount1与PairCount2则为语句有效搭配数,不同情况下的权重设计见表1。
Word1为语句1,Word1为语句1的相似语句;Word2为语句2,Word2为语句2的相似语句。在多种例句相似度计算情况下,对比未校对语句和相似度最高语句,由此来对语句语义正误进行判断,完成语义校对。
4. 自动语言处理系统在社交网络分析中的文本校对
4.1 构建易混淆词典
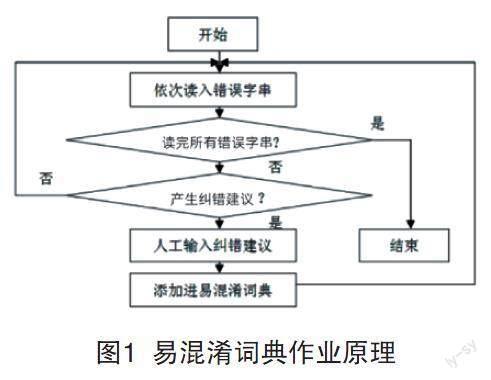
文本的校对和字词、语法、语义的校对有较大差异。应用自动语言处理系统对社交网络文本校对,分别有纠错与查错两种校对方式,前者是通过检测出文本的错误,根据错误的内容提出对应措施进行纠正,基于中文文本的常见错误,自动提取错误特征,收集相关词典内容,从而为系统自动识别错误用词提供参考;后者则为文本错误内容的提取,通过指明文本的错误点和特征,以供文本错误内容的修改进行参考[5]。易混淆词典的构建要依托纠错的校对方式,混淆词典的内容包含了文本错误字词与纠错建议,图1为混淆词典作业原理。
4.2 纠错算法编程
为凸显自动语言处理系统智能化、自动化高效运作与处理的效能,在校对社交网络语言文本上,一般都以纠错的校对方式为主[6]。通过对文本字词错误的判断,能够根据不同的错误特征提出针对性纠错建议,但针对文本校对中,未发现文本错误的情况,就无法给出客观合理的纠错建议。所以,在自动语言处理系统的应用中,还需进行纠错算法编程处理,比如力矩我们认为可以延长时间[7]。将“可疑延长”作为系统文本校对中判断出的字词错误,设计纠错算法的编程如下:
string[ ]zc correct;//定义数组用作纠错建议缓冲区
inti=0;//纠错计数器为0
//x系统检测的错误字串
//易混淆词典中提出纠错建议
for(intm=0;m<=errmatchco rrect.leng th;m++)
//易混淆词典中未找到纠错建议
if(i==0){
for(m=0;m<=zctx.length;m++)
if(e.gerErrword()==zctxcorrect[m].getErrword())
//字词同现概率表
Zccorrect[i]=zctxcorrect[m].getCorrect();}
5. 自动语言处理系统的搭建与实验
5.1 文本自动校对的流程
为实现对社交网络语言文本的准确校对,选用的自动语言处理系统,要具备查错、预处理及校对纠错等模块功能,系统功能实现流程如下:(1)输入与打开文本,以正向的顺序读入单句,预处理文本结构和内容,并通过双向模式匹配处理,根据事先构建的词库,对文本结构进行识别,明确字词句的词性;(2)构造字频向量与二元词性同现频率表,创建完善的文本查错知识库。基于系统查错、纠错的模块,对文本字词进行识别与查误,判断文本字词是否存在连接方式与连接顺序的错误,并判断语句结构是否完整,语法和语义的表达是否正确;(3)利用易混淆词典,准确定位自动语言处理系统查询中得出的错误内容,提出相应的纠错建议,进行纠错处理;(4)在完成纠错处理后,要执行判断程序文本处理是否结束。当完成处理后,则流程解锁;若未完成处理,系统将自动跳转至步骤(1),反复处理指导文本处理无误,完成整个文本自动校对的程序。
5.2 实验内容
选取微博平台某营销号发布的136篇文章进行实验分析,从中挑选出230个正确句子与200个错误句子,其中60个有字词级错误,100个有语法级错误,40个有语义级错误。病句举例如下:
(1)他是本地一家知名企业的总载。(“载”应为“裁”,属于字词级错误);(2)本县苹果的品种非常多,这里无法一一例举。(“例举”应为“列举”,属于语义级错误);(3)巴西总理授予法院获得签发“禁止未成年人进入酒吧证”的权力。(应删除“获得”,属于语法级错误)。
实验引入以下参数:(1)召回率=正确发现句子数/实际错误句子数×100%;(2)误报率=(发现错误句子数-正确发现句子数)/发现错误句子数×100%;(3)准确率=1-误报率。
实验结果见表2。
利用自动语言处理系统校对社交网络语言的文本,发现召回率与准确率较高,基本在60%以上,在语法错误句子的判断中,召回率与准确率较理想,分别为81%和84.4%。
结语
基于上述研究分析可以看出,社交网络在蓬勃发展的背景下,网络体系中传播的语音信息还需从语言结構、字词准确性、语法正误、语义正误及文本正误等方面进行充分考虑。为利用社交网络来传播符合社会主义核心价值观的语言信息,应用人工智能的自动语言处理系统,能够以科学化处理的方式准确判断社交网络中各类账户在文章发表中语言的准确性,有效过滤一些不符合社交网络语言规则库的违规语言,及时纠正在字词、语法、语义等方面的错误,以完善的语料库来优化语言规律,为语言自动处理系统在社交网络中的应用与推广提供依据。同时,社交网络还能依托自动语言处理系统,减少网络暴力语言的产生,维护和谐、稳定的网络语言秩序,构建良好的网络语言环境,从而为社交网络的健康发展提供保障。
参考文献:
[1]张洪忠,王競一.社交机器人参与社交网络舆论建构的策略分析——基于机器行为学的研究视角[J].新闻与写作,2023, (2):35-42.
[2]薛飞.人工智能在计算机网络技术中的应用研究[J].现代雷达,2022,44 (12):125-127.
[3]古天龙,郝峰锐,李龙,等.社交网络中负责隐私协商的智能体行为追责[J].软件学报,2022,33(9):3453-3469.
[4]李小伟,舒辉,光焱,等.自然语言处理在简历分析中的应用研究综述[J].计算机科学,2022,49(S1):66-73.
[5]Girish K,Pushpavathi M,Abraham A,et al.Automatic speech processing softwareNew sensitive tool for the assessment of nasality:A preliminary study[J].Journal of Cleft Lip Palate and Craniofacial Anomalies,2022,9(1):62-88.
[6]郭九霞.基于自然语言处理的空管系统危险源文本分类方法研究[J].安全与环境学报,2022,22(2):819-825.
[7]张志勇,荆军昌,李斐,等.人工智能视角下的在线社交网络虚假信息检测、传播与控制研究综述[J].计算机学报,2021,44(11):2261-2282.
作者简介:陆苗,博士研究生,讲师,研究方向:人工智能。
猜你喜欢
西安航空学院学报(2022年2期)2022-07-04 07:45:42
汽车零部件(2020年3期)2020-03-27 05:30:20
表面工程与再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技术(2018年9期)2018-11-02 05:31:34
IT经理世界(2018年20期)2018-10-24 02:38:24
通信电源技术(2018年3期)2018-06-26 06:33:30
军营文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
学与玩(2017年12期)2017-02-16 06:51:12
