
基于宽度学习的高校学生成绩预测模型研究
2023-08-26 04:13:24许杰倪文瀚兰洁周翔宇
电脑知识与技术 2023年20期
许杰 倪文瀚 兰洁 周翔宇


关键词:教育数据挖掘;宽度学习算法;成绩预测
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)20-0090-03
0 引言
作为一种新兴跨学科研究领域,教育数据挖掘涉及计算机科学、机器学习、数据挖掘和教育统计学等多学科内容。其中,实现高校学生成绩的预测是教育数据挖掘的重要目标,通过对学生日常行为数据的挖掘与分析,可以帮助学校管理者和教师及时了解学生的学习成绩,并做出针对性指导,改善学生的学习效率,尽可能避免出现课程不及格的现象,提高教学质量。因此,如何实现高校学生成绩的准确预测,是本文研究的重点内容。
高校学生成绩预测是指基于学生的相关信息,如历史成绩、行为数据、心理特征等,来预测其未来的学习表现,如分数、排名、考核等级等。这是教育数据挖掘领域的一个热点问题,也是提高教育质量和效率的一个重要手段。针对高校学生的成绩预测已经得到很多研究者的关注并取得相应的研究成果。文献[1-3]提出了基于统计模型的方法,這种方法利用统计理论和技术,如线性回归、逻辑回归、方差分析等,建立学生成绩与各种因素之间的数学关系,并进行参数估计和假设检验。这类方法简单易用,但需要满足一定的假设条件,并且难以处理非线性和复杂的关系。文献[4-6]设计了基于机器学习的方法,能够利用机器学习算法,如决策树、支持向量机、神经网络等,从大量的数据中自动学习出成绩预测模型,并进行优化和评估。这类方法能够处理非线性和复杂的关系,并且具有较强的泛化能力和鲁棒性。文献[7]利用深度神经网络,从多源异构数据中提取高层次特征,并进行端到端的成绩预测。这类方法能够处理高维度和复杂结构的数据,并且具有较强的表达能力和自适应能力。
上述方法虽然能够实现高校学生的成绩预测,但还存在一些预测精度低和速度较慢的问题。具体来说,首先是数据质量问题。数据质量是影响成绩预测精度的重要因素之一。如果数据存在缺失值、噪声值、异常值等问题,或者数据量不足、数据来源单一、数据分布不均等问题,都会导致成绩预测模型的训练和测试效果下降。第二是特征选择问题。特征选择是指从原始数据中筛选出与目标变量相关性较高且冗余性较低的特征子集,以提高成绩预测模型的泛化能力和解释能力。如果特征选择不合理,可能会导致信息损失或噪声干扰,从而影响成绩预测精度。第三是模型选择问题。模型选择是指从多个候选模型中选择一个最优模型来进行成绩预测。不同的模型具有不同的假设条件、参数设置、优化方法等,对于同一份数据可能会产生不同的预测结果。如果模型选择不符合当前数据特点或者没有经过充分的调优和验证,可能会导致成绩预测精度降低。最后是评估指标问题。评估指标是指用来衡量成绩预测模型好坏的数值或标准。常见的评估指标有均方误差、平均绝对误差、相关系数、准确率等。不同的评估指标反映了成绩预测结果的不同方面,例如:误差大小、正确率、覆盖率等。如果评估指标没有考虑到教育领域内特有的因素或者没有结合多种指标进行综合分析,可能会导致对成绩预测精度产生偏颇或片面的认识。
因此,本文提出了一种基于宽度学习网络的高校学生成绩预测方法,通过建立数据处理、网络训练和成绩预测三个模块,改善了数据质量、模型选择和评估指标等问题。
1 宽度学习网络
宽度学习网络是基于随机向量函数链接神经网络(RVFLNN) 的一种改进和扩展,RVFLNN是一种单隐层前馈神经网络,其输入层到隐层的权重和偏置是随机生成的,不需要训练,只需要求解隐层到输出层的权重矩阵。RVFLNN虽然简单高效,但也存在一些问题,比如输入数据的映射特征不够丰富和稳定,导致网络性能受限。为了解决这些问题,陈俊龙教授及其团队[8]在2018年首次在学术界提出了宽度学习系统(BLS) ,并在之后不断进行改进和扩展。与深度学习网络的复杂结构有所不同,宽度学习网络可以利用较少的网络层数量来实现大规模数据的处理,同时利用伪逆矩阵的计算,一次求解得到训练网络的权重参数,避免了庞大的计算量,提高了运算速度。因此可以将宽度学习网络应用到教育大数据领域,实现学生成绩的高效与准确预测。
1.1 宽度学习网络结构
宽度学习网络的结构如图1所示,其中包括输入层、特征层、增强层和输出层。特征层和增强层包含两种节点,分别是特征节点(feature node)和增强节点(enhancement node)。特征节点由输入数据计算得到,增强节点根据特征节点进一步计算得到。两种节点直接组合起来连接到输出层节点。由于这种相对简单的结构,宽度学习网络在训练时只需要求解单层的最优权值,避免了复杂的反向传播过程,有效降低了模型训练时间。
当特征层和增强层需要增加新的网络节点,或者收集到新的训练数据时,宽度学习网络无须复杂的重新训练过程,只需要通过一些高效的增量计算来动态地更新已经学习到的权值。宽度学习网络的增量学习包括添加特征节点、添加增强节点以及添加输入数据等情况。
1.2 宽度学习网络训练
宽度学习网络需要通过训练来生成特征节点和增强节点,这两类节点分别负责提取输入数据的线性和非线性特征。同时,宽度学习网络需要通过训练来求解特征节点和增强节点到目标值的伪逆矩阵,这相当于神经网络的权重矩阵,并调整稀疏表示和正交规范化等技术,以提高特征节点和增强节点的表达能力和稳定性。宽度学习网络的训练方法主要采用梯度下降法,这是一种最常用的训练方法,它根据损失函数对神经网络的参数进行迭代更新,使得损失函数达到最小值。梯度下降法可以分为批量梯度下降、随机梯度下降和小批量梯度下降等不同的变体,根据每次更新时使用的数据量的不同。梯度下降法也可以结合一些优化技术,例如动量、自适应学习率、正则化等,来提高训练效率和稳定性。
1.3 常见应用领域
经过近几年的快速发展,宽度学习网络已在很多技术领域都有展开应用,并且有良好的发展潜力,比如时间序列、高光谱分析、脑机信号分析、容错、基因鉴定与疾病检测、步态识别、3D打印以及智能交通等。其中,在安防领域[9],宽度学习网络可以提升人工智能识别的可靠性和场景适应能力。2020年Feng等人[10]提出了宽度学习网络可以通过增量学习来适应系统的变化和故障,这种方法应用在容错系统中解决了机器人控制系统存在的故障率高等问题。同时,由于宽度学习网络可以处理不同长度和频率的时间序列数据,在股票预测[11]和灾害预报[12]中也有较好的应用价值。
2 基于宽度学习的高校学生成绩预测模型
为了实现高校学生成绩的准确预测,本文提出了一种基于宽度学习的高校学生成绩预测模型,成绩预测流程如图2所示。该模型主要包括数据处理、网络训练和成绩预测三个模块,每个模块的具体功能如下。
2.1 数据处理模块
这个模块的功能是处理影响学生成绩的日常行为数据,包括数据的获取、存储、更新、提取等操作。由于影响学生成绩的日常行为数据维数较多,其中部分数据对成绩并无参考价值,所以在数据处理模块中需要进行特征提取,以获取对本文研究有用的行为特征。
2.2 网络训练模块
在网络训练模块中,首先需准备数据,将类别变量进行编码,把数据集划分为训练集和测试集,然后建立宽度学习网络模型,设置各层的激活函数、单元数、学习率、正则化等参数,在训练过程中,将训练集数据输入模型,设置迭代次数,并使用测试集数据计算预测误差,调整参数优化模型。
2.3 成绩预测模块
经过数据處理和网络训练后,成绩预测模块可以快速准确地预测学生成绩。
3 实验结果与分析
3.1 实验准备
为了训练和测试成绩预测模型,把数据集按照7∶3的比例划分为训练集和测试集。在对数据进行预处理后,分别采用线性回归、支持向量机和本文提出的宽度学习网络建立模型,并对模型参数进行优化,以保证方法对比的公平。本文的实验在以下硬件和软件环境下进行:处理器是Intel(R) Core(TM) i7-9700,主频是3.2GHz,内存是16.0GB;软件环境是Py?thon3.8。在使用宽度学习算法的成绩预测模型中,设置每个窗口有10个特征节点,共有20个窗口,增强节点有200个。
3.2 不同预测模型的对比结果与分析
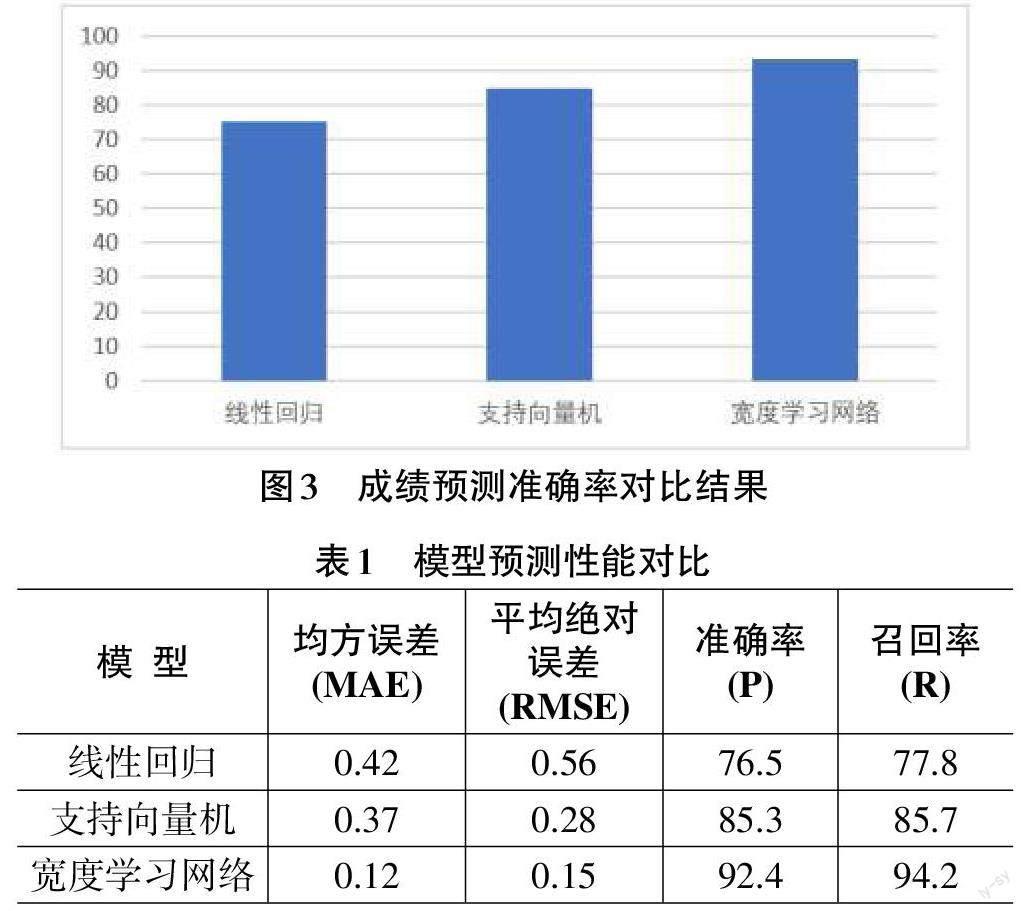
在本文实验中,首先将采集到的数据进行预处理,解决数据缺失、异常和噪声问题,然后将训练数据导入预先设计好的宽度学习网络模型,通过网络训练调整网络中的节点数量和权重参数,最终通过训练好的宽度学习网络模型输出数据得到学生成绩的预测值,并与已有的两种方法进行对比,实验对比结果如图3所示。
由图3中可以发现,经过数据预处理和模型训练后,采用线性回归的学生成绩预测准确率为75.2%,支持向量机的预测准确率为84.7%,而本文提出的宽度学习预测模型准确率达到了93.5%,验证了本文所提出预测模型的有效性。
同时,为了评估高校学生成绩模型的预测性能,主要用到的评标指标包括均方误差(MAE) 、平均绝对误差(RMSE) 、准确率(P) 和召回率(R) 。三种不同方法的预测性能对比结果如表1所示,从中可以看到,同线性回归和支持向量机两种方法相比,本文提出的宽度学习网络预测准确率达到了92.4%,召回率达到了94.2%,同时具有最低的MAE值和RMSE值,说明本方法提高了成绩预测精度。
4 总结
本文设计了一种基于宽度学习的高校学生成绩预测模型,通过数据处理和网络训练,最终实现了高校学生成绩的快速准确预测,能够帮助高校教育管理人员及时了解学生的学习状况,提高学生成绩。
