
结合词典和句法依存树的地址场所实体分类
2023-08-26 04:13:24蒋言刘海毛雪宇
电脑知识与技术 2023年20期
蒋言 刘海 毛雪宇

关键词:地址数据;场所分类;中文地址分词;依存句法分析;POI词典
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)20-0083-04
0 引言
地址数据常见于生活中的方方面面,通常以文本的形式表示具体的地理空间[1]。在智慧城市的建设中,地址数据更是在城市安全、规划、生活等相关业务中作为数据支撑[2-3]。快递行业通过对收件人地址使用概率统计模型确定快递的收取点[4]。在城市治理领域,通过将水电煤气数据与地址数据进行关联可检测流动人口的聚集场所[5]。因此面对现实业务需求如何从业务地址数据中关联出场所是需要解决的难点之一。日常生活中,人们往往选择借助高德地图去定位地址数据中的场所,然而随着高德地图开放资源的限制以及描述地址的复杂多样性,需要人们从数据本身出发,探求新的方法实现地址数据关联到具体场所的功能。
传统的方法是基于规则对业务地址数据进行场所识别,确定地址数据中的场所实体[6]。然而此类方法是假设地址数据比较标准,描述方式为省、市、区到街道、路名、门牌号/POI场所实体的顺序。然而现实场景下的业务数据描述方式灵活多样,基于规则的识别方法不再适用,应用于业务场景中效果欠佳[7]。
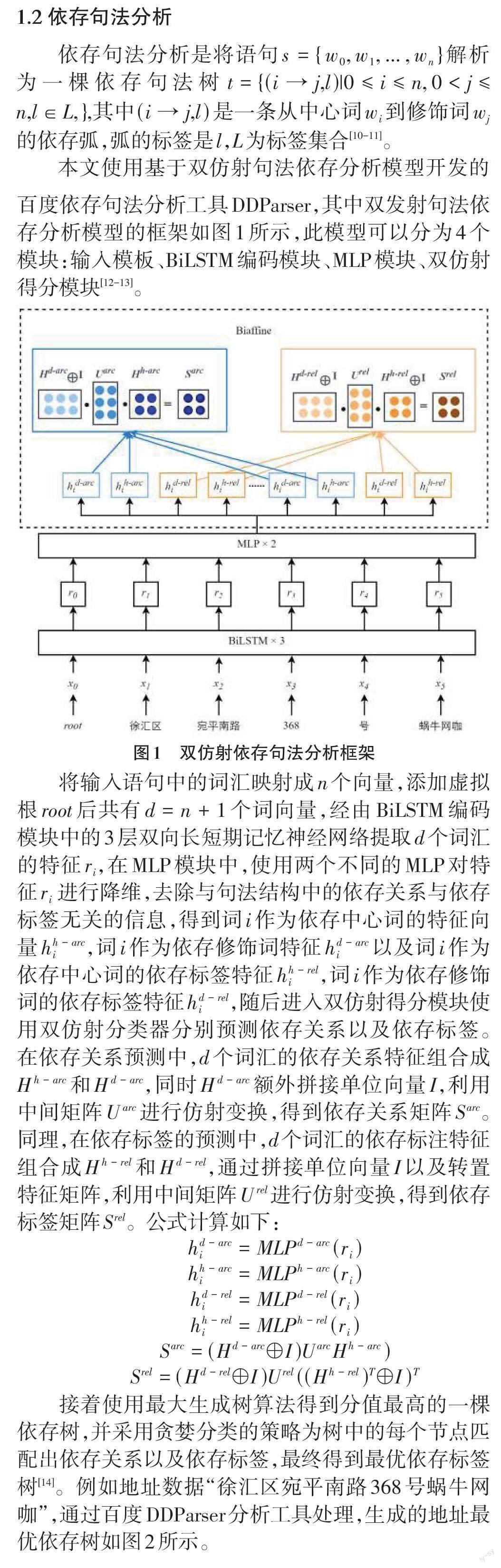
然而从语言学的层面分析,文本是由词构成,而地址数据的结构是由多个最小地址元素经过层层限定后指向唯一的最有效地址要素,即地图上的某个点或区域,对于具体业务数据来说就是目标场所实体[8]。例如某条数据为“徐汇区宛平南路368号蜗牛网咖”是通过“徐汇区”“宛平南路”“368”“号”等最小地址元素的修饰限定,指向“蜗牛网咖”这一目标场所实体。因此分析出业务地址数据中各成分词限定与被限定关系,即可获取目标场所实体。在自然语言处理的各项技术中,依存句法分析旨在从语言学的层面解析语句中各成分词之间的关系,从而辅助理解语句结构[9]。基于此方面的优势,本文首先将业务数据分词,随后引入依存句法分析进行解析,获取地址数据中的目标场所实体,进而通过场所类别词典匹配得到场所类别。
本文主要工作如下:
1) 为了保证前期对业务数据分词的准确性,本文通过添加上海市徐汇区道路名词典以及通过高德API 获取的场所类别词典作为分词辅助词典。
2) 使用依存句法分析对分词后的业务数据进行分析,获取最优地址依存树。
3) 设定规则,通过宽度优先搜索算法获取目标场所实体。
4) 将获取的目标场所实体与场所类别词典匹配,得到目标场所实体的类别。
1 相关模型方法
1.1 场所类别词典的构造
现实业务需求需要判斷获取的目标场所实体的所属类别例如“星游城”对应类别标签为“商场”,因此为了有效地对场所实体进行分类,通过高德API接口获取上海市徐汇区境内的所有POI地址数据,并根据高德地图提供的类别标签以及现实业务需要,按照一级行业分类与二级行业分类对POI场所数据进行详细分类,构建场所类别词典,具体类别如表1所示。
构建的场所类别词典形式例如“{ 公司”:“光大物业”“上海电气集团”,……,“国家电网”}。同时对一些场所的简称或别称进行对应补充,例如“上海第六人民医院”简称“第六人民医院”“六院”。最终使用场所类别词典与搜索到的场所实体进行匹配,得到场所类别,满足具体的业务需求。
场所类别词典前期可以作为自定义词典辅助业务数据分词,保证了分词结果的正确性;同时与获取的目标场所实体进行匹配,得到场所类别,满足业务需求。
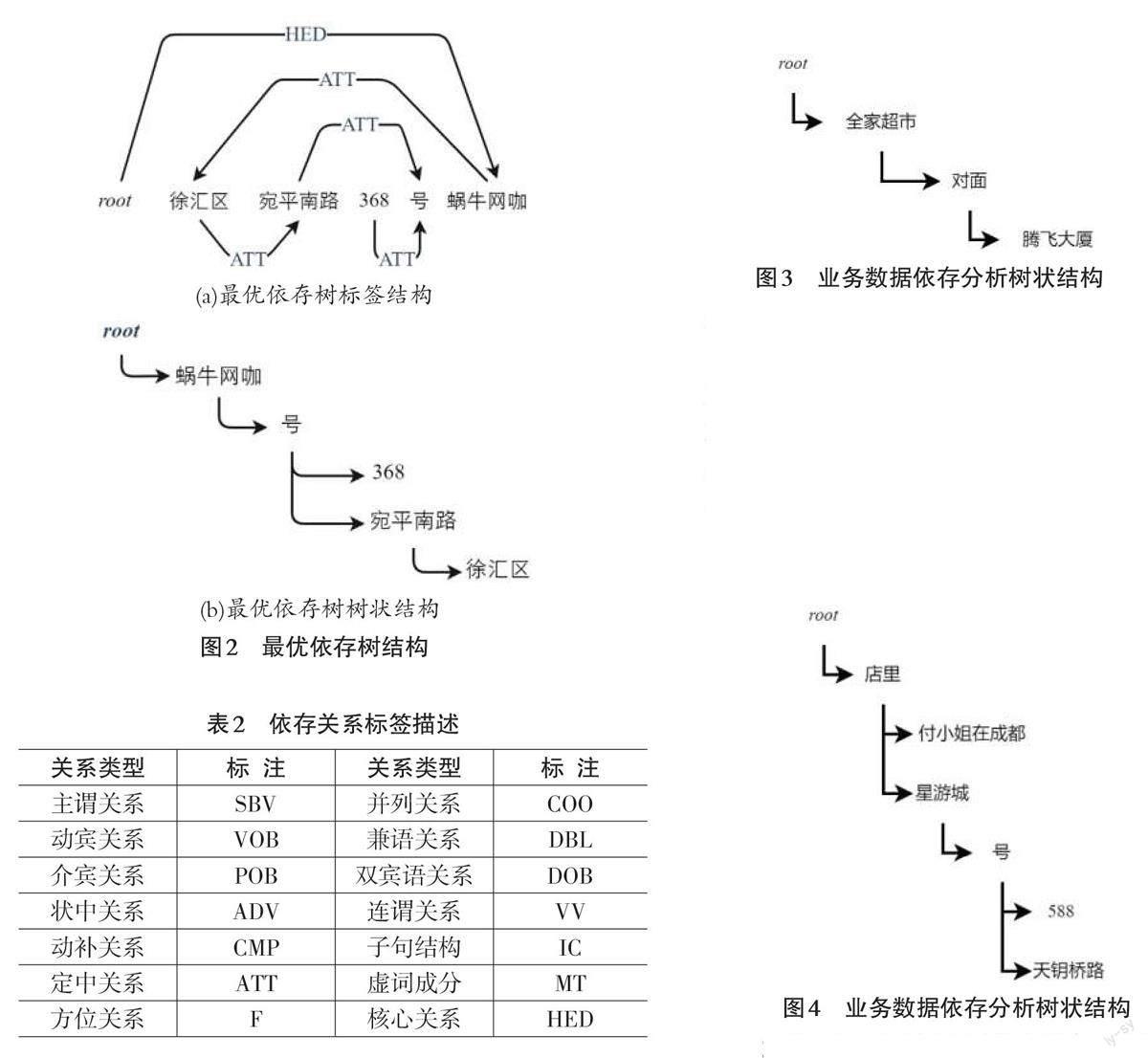
从图2展示的最优依存树结构图中可以看出,“蜗牛网咖”是被“徐汇区”“宛平南路”“368”“号”层层限定,因此“蜗牛网咖”是本条业务地址数据中的目标场所实体,其在整棵依存树中也处于核心关系(HED) 。同时百度DDParser工具提供14种依存关系标签。
1.3 目标场所匹配规则
通过依存句法分析能够得到地址数据中各成分词之间的依存关系,通常依存树中处于核心关系的场所实体词即为目标场所实体,如图2样例所示。然而由于现实业务中地址数据的多样性以及复杂性,业务地址数据中可能不包含场所实体,也可能场所实体经依存句法分析后不在核心关系所处位置,而是在最优依存树的某个节点上。因此需要对生成的地址最优依存树进行宽度优先搜索将可能的场所实体尽数列出,并根据现实业务需求,设定相关规则进行筛选。规则如下:
1) 在不同节点搜索到多个场所实体,取最小节点处对应实体。
例如业务数据为“天钥桥路腾飞大厦对面全家超市”,经过DDParser依存句法分析后可生成的树状结构如图3所示,经由宽度优先搜索可得到场所实体“全家超市”与“腾飞大厦”,从节点位置层面分析,“全家超市”处于节点1处,“腾飞大厦”位于节点3,因此选取节点1处的“全家超市”场所实体,即最小节点处的场所实体,从现实语义理解上来说,本条业务数据所指的场所为“全家超市”符合规则设定后的结果。
2) 在相同节点搜索到多个场所实体,且实体间存在包含关系,取被包含的场所实体。
例如业务数据为“天钥桥路580号星游城付小姐在成都店里”,经过DDParser依存句法分析生成的依存树的树状结构如图4所示,经由宽度优先搜索可得到场所实体“星游城”和“付小姐在成都”,两者位于同一节点,然而“付小姐在成都”被包含于“星游城”,从现实语义理解层面出发,也应选择“付小姐在成都”场所实体。
3) 核心关系对应的词汇类似“旁边”“对面”“中间”等方位词,舍弃搜索到的实体。
例如业务数据为“龙华中路卜蜂莲花拆迁处对面”,经过DDParser依存句法分析后可生成的树状结构图如图5所示,核心关系对应的词为方位词“对面”,经由宽度优先搜索可得到场所实体为“卜蜂莲花拆迁处”,然而在真实场景中,该业务数据指代的是“卜蜂莲花拆迁处”对面的某个实体,该实体在业务数据中并没有出现,因此将此类情况下搜索到的“卜蜂莲花拆迁处”场所实体舍去。
2 实验
为验证本文提出的方法在现实场景下的有效性,实验数据来源真实脱敏后的上海市徐汇区的业务地址数据共计18 126条。其中剔除掉不含有场所实体的地址共计3 604条,例如:徐汇区小木桥路440弄48 号402室、徐汇区衡山路东平路。保留地址数据中含有场所实体的作为实验数据,共计14 522条。例如:徐汇区零陵路721号徐家汇派出所。
针对含有场所实体的14 522条实验数据,本文在对地址数据进行分词后,通过百度DDParser依存分析平台解析,生成最优地址依存树,继而对地址依存树进行宽度优先搜索,通过规则过滤获取目标场所实体并匹配场所类别词典得出目标场所实体类别。最终的匹配成功率为89.2,而对于无法匹配的数据,主要原因在于对场所描述时存在简称或俗称以及错别字,需要完善场所类别字典中对某些场所约定俗成的简称或俗称,以及改善数据质量。
3 结论与展
本文引入依存句法分析对业务地址数据进行分析,得出最优地址依存树,继而通过规则确定业务地址数据中的目标场所实体,通过词典匹配的形式得到目标场所实体对应的类别。然而由于业务数据中往往会使用场所实体的简称或俗称,从而存在匹配失误的情况,因此需要收集场所的简称或俗称完善场所类别词典。
同时对于不含有明确场所实体的数据,需要思考采用其他方法,挖掘出数据背后所表示的场所。
猜你喜欢
小学生优秀作文(低年级)(2023年4期)2023-05-09 02:41:22
党政论坛(2022年5期)2022-10-14 12:06:44
少先队活动(2021年9期)2021-12-01 14:49:18
文苑(2019年24期)2020-01-06 12:06:50
智富时代(2019年6期)2019-07-24 10:33:16
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
科学生活(2017年7期)2017-08-14 21:33:20
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
