
基于改进YOLOv5的驾驶员手持手机检测算法研究
2023-08-21 09:44:03彩朔宋长明
现代信息科技 2023年12期
彩朔 宋长明


摘 要:针对驾驶员手持手机行为检测精度低问题,提出一种改进的驾驶员手持手机行为检测算法。首先,在YOLOv5骨干网络中引入改进的注意力机制模块,更好地获取上下文信息,提高小目标检测的精确度。其次,采用一种改进的特征融合方法,提取三个尺度的特征,并对特征进行融合,更好地提取局部信息。实验结果表明,与YOLOv5相比,该检测算法在自制数据集上的精确度达到71.9%,提高了2.1%,对小目标的检测效果显著。
关键词:目标检测;YOLOv5;残差模块;注意力机制
中图分类号:TP183;TP391.41 文献标识码:A 文章编号:2096-4706(2023)12-0066-04
Research on Driver Handheld Phone Detection Algorithm Based on Improved YOLOv5
CAI Shuo, SONG Changming
(College of Science, Zhongyuan University of Technology, Zhengzhou 451191, China)
Abstract: An improved driver handheld phone behavior detection algorithm is proposed to address the issue of low accuracy in driver handheld phone behavior detection. First, an improved attention mechanism module is introduced into YOLOv5 backbone network to better obtain context information and improve the accuracy of small target detection. Secondly, an improved feature fusion method is adopted to extract features at three scales and fuse them to better extract local information. The experimental results show that compared with YOLOv5, the detection algorithm achieves an accuracy of 71.9% on the self-made dataset, get an improvement of 2.1%, which has a significant detection effect on small targets.
Keywords: target detection; YOLOv5; residual module; attention mechanism
0 引 言
汽車已经成为生活中普遍使用的交通工具,驾驶员在驾驶过程中接、打电话等手持手机现象比较普遍,给交通安全带来极大的隐患[1]。因此,对驾驶员手持手机行为进行检测具有重要意义。目前,驾驶员手持手机行为检测算法分为:双阶段和单阶段。双阶段包括:SPP NET[2]、R-CNN[3]、Fast R-CNN[4],Faster R-CNN等一系列改进后,既保证了准确度,同时也提高了检测速度。单阶段检测算法:可通过端到端的方式直接得出检测效果,相较于双阶段目标检测算法,单阶段目标检测的速度更快。Redmon等最新提出了YOLO[5]、YOLOv2[6]、YOLOv3[7]、YOLOv4[8]一系列设计改进,得到的新模型检测精度更高,检测速度更快,但还存在检测精度低的问题。在小目标检测任务中YOLOv4检测精度还没达到理想状态,YOLOv5更适合检测小目标物体。
1 目标检测算法
1.1 传统的目标检测算法
驾驶员手持手机行为检测算法主要分为信号检测和机器视觉检测。基于信号检测是通过定位手机信号,通过手机信号来检测驾驶员是否使用手机来接打电话。TRAMER[9]等提出使用手机信号来检测是否在接打电话,该检测方法很容易受信号的干扰,导致检测准确度低。魏民国[10]提出采用人脸与手机的特征点,检测驾驶员接打电话的行为,很容易受天气的影响。后又提出了一种基于支持向量机的驾驶员接打电话行为检测方法,进而来判断是否在手持手机,但该方法需要大量的计算,需要较长的时间来检测,导致检测速度比较慢。
1.2 卷积神经网络目标检测算法
随着深度学习的发展,卷积神经网络目标检测算法也得到了很大的提高。目标检测算法大致可以分为两大类:一阶段和两阶段。双阶段Fast R-CNN网络是以VGG16为基础进行训练得出的模型。在2016年,Ren等在Fast R-CNN的基础上提出Faster R-CNN网络模型,该网络架构实现了端到端的两阶段目标检测,两级检测器很难实现实时推理。为了解决两级检测器的问题,Redmon等提出了YOLO系列检测算法,得到的新模型检测精确度更高,检测速度更快,但对小目标的检测还存在不足。文献[11]提出了用于特征增强的特征图融合机制,融合得到检测能力更强的特征图来构建特征金字塔来增强小目标特征。YOLOv5增加了感受野弥补了YOLOv4对小目标检测的不足。TPH-YOLOv5[12]是基于YOLOv5的改进,该模块在小目标检测上性能表现显著。因此,在小目标检测任务上,YOLOv5在检测速度和精度上都能取得显著效果。
2 改进的YOLOv5的模型结构
YOLOv5网络的骨干网络对特征提取不足,随着深度网络层次的不断增加,小目标会损失更多的语义信息,导致检测精度低无法达到预想的结果。为了解决浅层特征语义信息不足而导致检测小目标物体精度低的问题。本文提出一种改进的网络结构,如图1所示,通过在YOLOv5骨干网络中引入改进的注意力机制模块,更好地获取上下文信息,减少语义信息的损失,更好地提高小目标检测的精确度。其次,采用一种改进的特征融合方法提取三个尺度的特征,并对特征进行融合,以更好地提取局部信息。
2.1 骨干增强网络
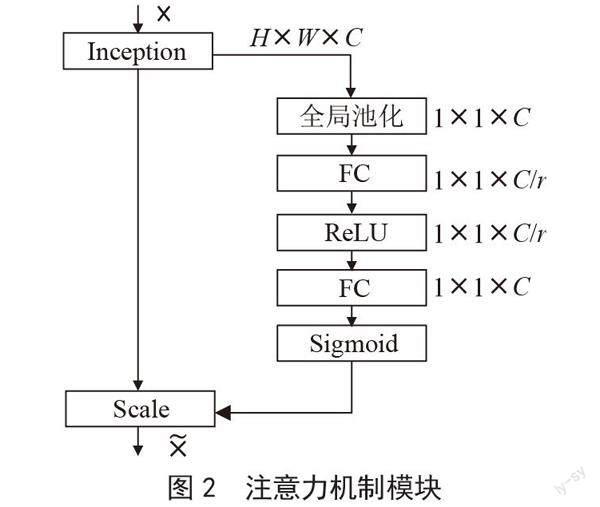
根据检测驾驶员手持手机行为目标小、检测距离比较远的问题,为了提高模型的提取能力和检测精确度,本文在YOLOv5目标检测网络模型不同特征提取层中分别添加坐标注意力机、通道注意力机制、空间注意力机制,通过添加多注意力机制使得新的检测模型能够更好地检测小目标,同时也提高了模型的检测速度。首先输入特征图并进行全局池化,得到(1×1×c)大小的特征图。其次,把新的特征图在进行全连接层操作,接着进行ReLU,再进行一次全连接,把高维变到低维,并且可以增加非线性因子,把有用的信息保留下来,更好的提取上下文信息。最后,经过Sigmoid激活函数得到(1×1×c)大小的权重比例,通过最后得到的权重值和原始特征图(h, w, c)相乘得出结果。流程如图2所示。
2.2 改进的特征融合模块
为了解决小目标物体检测精度低的问题,本文通过不同特征层之间相互融合,再通过自上而下提取特征,最后将两者进行融合从而进一步提高小目标的检测精度,增强了浅层的语义信息,特征金字塔是自上而下的特征融合方式,增强了浅层特征的语义信息,但还存在不足。浅层的语义信息会随着网络结构层的增加而语义信息不断减少,如何减少语义信息的损失,本文提出了一种改进模型。特征金字塔只对相邻两个尺度的特征图进行融合,随着网络层次的加深,深层特征的会损失更多的信息,此时在融合相邻特征层也不能达到理想的结果,影响特征融合的效果。可以通过提取后不同层级尺度的特征进行融合,更充分地融合局部信息和全局信息。结构如图3所示,P2特征图利用卷积提取局部信息;P3使用反卷积增强局部信息,进而提高其分辨率;P4表示大小为1×1的特征图,含有全局特征,通过通道注意力机制使P4的通道数和P2通道数相同,最后通过融合操作得到F1。F1中包含了局部信息和全局信息,从而使浅层的语义信息更丰富。
3 实验结果与分析
实验流程图如图4所示。
3.1 准备工作
本实验采用自制的道路监控拍摄的不同时间段、不同车型监控图像构成的数据集。训练集图像采用labelimg工具进行标注,共使用1 000个数据,训练集、验证集、测试集划分比例为7:2:1。实验环境为64位Windows 10专业系统,GPU大小为12 GB的NVIDIA GeForce RTX 3060显卡,处理器为Intel(R) Core(TM)i5-12490F。采用PyTorch深度学习网络框架,在GPU上进行实验。训练后的损失函数曲线如图5所示。
图5中纵轴代表损失值,横轴代表训练次数。从图中可以看出,随着训练次数的增加,损失值逐渐收敛。
3.2 评价指标
本实验评价指标采用准确率(Accuracy, Acc)、精确率(Precisio, P)、召回率(Recall, R)、平均精度(Average Precision, AP)、平均精度均值(mean Average Precision, mAP)。
3.3 实验结果与分析
为了检验训练出目标检测模型的性能,实验对比了RetinaNet-50、YOLOv3、YOLOv4、YOLOv4-CA、YOLOv5-FIRI等算法,采用IoU阈值为0.5作为评价指标,实验结果如表1所示。
通过表1实验结果可以得出结论,本文改进的YOLOv5算法的准确度值达到了71.9%,与原先的算法相比,本文提出的改进YOLOv5网络模型,精度提升了2.1%,RetinaNet-50、YOLOv3、YOLOv4三个类别的平均精确度均有所提升,YOLOv-CA和YOLOv5-FIRI的mAP也有了明显的提高,改進的YOLOv5则在YOLOv-CA和YOLOv5-FIRI的基础上mAP值仍有提高。这表明本文提出的改进的算法是有效的。
为了进一步验证方案的有效性,该算法也在不同类别上进行对比,实验结果如表2所示。
从表2可以得到,本文所提出的改进算法模型相比于YOLOv5-FIRI在不同类别上的准确率、精确率和召回率均有所提升。表明融合多注意力模块后,改进算法能增强对深层特征显著区域的检测性能,减少深层特征的位置信息在传递过程中丢失的问题,通过精确的位置信息增强模型对目标感兴趣区域的关注,有助于增强前景信息的学习同时抑制背景信息的干扰。
3.4 消融实验
为了验证本文所提算法对各个模块的作用,在自制的数据集上进行了消融实验,实验结果如表3所示。
由表3可知,通过在Darknet53主干网络上加入改进的特征金字塔模块相比基准网络的平均精度均值(mAP)提升了2.8%、CSPDarknet53主干网络上加入改进的特征金字塔模块相比基准网络的平均精度均值(mAP)提升了2.5%、Resnet18主干网络上加入改进的特征金字塔模块相比基准网络的平均精度均值(mAP)提升了2.3%:证明了改进的特征融合方法对不同层级的特征进行了更好地融合,丰富深层了特征的语义信息。
3.5 实验结果
为了验证模型的准确度、可靠性、有效性,本实验采用自制的道路监控拍摄的不同时间段、不同车型监控图像构成的数据集进行验证,实验效果如图6所示。
4 结 论
针对驾驶员手持手机行为检测过程中存在拍摄距离远、目标较小等导致的检测精度低问题,本文在YOLOv5的基础上提出一种改进的驾驶员手持手机行为检测算法。在YOLOv5骨干网络中引入改进的注意力机制模块,能够更好地获取上下文信息,从而提高小目标检测的精确度。其次,采用了一种改进的特征融合方法,提取并融合三个尺度的特征,更好地提取局部信息。实验结果表明,该算法对于小目标的检测精度有很大的提高。
参考文献:
[1] 刘卓凡,付锐,马勇,等.高速跟车状态下驾驶人最低视觉注意力需求 [J].中国公路学报,2018,31(4):28-35.
[2] HE K M,ZHANG X Y,REN S Q,et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[3] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision(ICCV).Santiago:IEEE,2015:1440-1448.
[4] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,39:1137-1149.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2015:779-788.
[6] REDMON J,FARHADI A. YOLO9000: Better, Faster, Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2016:6517-6525.
[7] REDMON J,FARHADI A. YOLOv3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].[2023-01-03].https://doi.org/10.48550/arXiv.1804.02767.
[8] 熊群芳,林军,岳伟,等.基于深度学习的驾驶员打电话行为检测方法 [J].控制与信息技术,2019(6):53-56.
[9] TRAMER F,KURAKIN A,PAPERNOT N,et al. Ensemble Adversarial Training: Attacks and Defenses [J/OL].arXiv:1705.07204 [stat.ML].[2023-01-03].https://doi.org/10.48550/arXiv.1705.07204.
[10] 魏民國.基于机器视觉的驾驶人使用手持电话行为检测方法 [D].北京:清华大学,2014.
[11] 陈欣,万敏杰,马超,等.采用多尺度特征融合SSD的遥感图像小目标检测[J].光学精密工程,2021,29(11):2672-2682.
[12] ZHU X K,LYU S C,WANG X,et al. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios [C]//2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW).Montreal:IEEE,2021:2778-2788.
作者简介:彩朔(1995—),男,汉族,河南周口人,硕士研究生在读,主要研究方向:图像处理;宋长明(1965—),男,汉族,河南郑州人,教授,中理学院院长,硕士研究生,主要研究方向:偏微分方程的理论及应用、图像处理及其教学。
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
