
Adaboost M2+HOG 算法在肖像类唐卡图像头饰检测分类中的应用
2023-08-16 05:01王菽裕宋俊芳张春玉
无线互联科技 2023年11期
王菽裕,宋俊芳,张春玉
(西藏民族大学 信息工程学院,陕西 咸阳 712082)
0 引言
唐卡图像是我国藏区特有的艺术作品[1],享有藏族“百科全书”的美誉,装裱之后可悬挂的宗教卷轴画其内容涉及历史、医学、政治、文化和社会生活的诸多方面,是千百年来西藏文化乃至中华民族民间文化艺术中极其珍贵的非物质文化遗产,具有极高的艺术性和观赏性。 此外,也是学者研究西藏文化宝贵的形象素材和实物资料,在国内外具有很高的学术价值。
随着现代数字技术的迅猛发展,唐卡图像的数字化保护是一个重要的研究领域[2-3]。 建立类别清晰的唐卡数据库,是一项意义重大且工作量繁重的工作,如何从唐卡数据库精准地检索到需求的唐卡图像是一个迫切需要解决的现实问题。 由于唐卡图像内容、画面色彩极其丰富,对整幅唐卡图像的全局特征的描述就显得异常困难。 肖像类唐卡图像的头饰基本可以分为3 类[4]:发髻、僧帽和头冠。 现有的检测分类方法中的一些方法过度依赖分割出头饰区域[4-5],使得检测分类效果不佳,甚至一些方法仅依据3 类头饰的轮廓和颜色特征进行检测分类[6-7]。 由于头饰的颜色特征容易受到光照干扰,使得应用性不足,需要在分割和特征提取两个方面进行改进;利用多种分割方法提取多种特征,再结合分类算法进行检测分类,这需要准确的区域分割和多种图像特征。 为此,本文直接选取肖像类唐卡图像中的头饰区域作为训练样本,提取该区域的全局图像HOG 特征[8],结合Adaboost M2 算法对肖像类唐卡图像进行检测分类。一方面可以避免区域分割带来的影响,另一方面可以避免对3 类头饰特征描述不全面的影响。 与其他方法相比,本文算法可以很好地应用于肖像类唐卡图像的检测分类。
1 3 类头饰训练样本的构建
1.1 训练样本的采集
训练样本来源于两个部分,第一部分是通过课题组学生手工采集网络上肖像类唐卡图像的头饰区域,并进行3 类头饰数据的标记;第二部分是学校藏族学生通过拍摄西藏旅游场所、家庭、庙宇等地的肖像类唐卡图像获得,选择图像的头饰区域作为训练样本,并进行3 类头饰数据的标记。
1.2 训练样本的扩大
本文实际采集的训练样本数据集包括:发髻区域训练样本431 张/jpg,僧帽区域训练样本360 张/jpg,头冠区域训练样本518 张/jpg;分别对应的标签数据431 个/xml,360 个/xml,518 个/xml。 为增大训练样本的数量,笔者对原有的牦牛样本图片实施水平翻转操作,最后的数据集如表1 所示。

表1 数据集 (单位:个)
2 特征提取
方向梯度直方图(Histogram of Oriented Gradient,HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子[7]。 此方法的基本观点是:局部目标的外表和形状可以被局部梯度或边缘方向的分布很好地描述。 具体特征提取步骤如下。
第一步,为减少光照因素的影响,降低图像局部的阴影和光照变化所造成的影响,首先采用Gamma校正法对输入图像的颜色空间进行标准化(或者说是归一化)[9]。 Gamma 校正可以理解为提高图像中偏暗或者偏亮部分的图像对比效果,能够有效地降低图像局部的阴影和光照变化。
第二步,边缘方向计算。 计算图像每个像素点的梯度,包括方向和大小。
上式中Gx(x,y)和Gy(x,y)分别表示输入图像在像素点(x,y) 处的水平方向梯度值和垂直方向梯度值,所以在该像素点的梯度幅值和梯度方向就分别是:
第三步,将输入图像划分成小单元(Cell),如8×8,然后统计每一个小单元的梯度直方图,再将几个小单元组成一个块区域(Block),如2×2 个小单元组成一个块区域,将每一个块区域中的小单元的梯度直方图串联起来,就可以得到一个块区域的HOG 特征。
统计一个细胞单元的梯度直方图时,一般考虑采用9 个bin 的直方图来统计8×8 个像素的梯度信息,即将cell 的梯度方向0~180°(或0~360°,即考虑了正负)分成9 个方向块,如图1 所示。
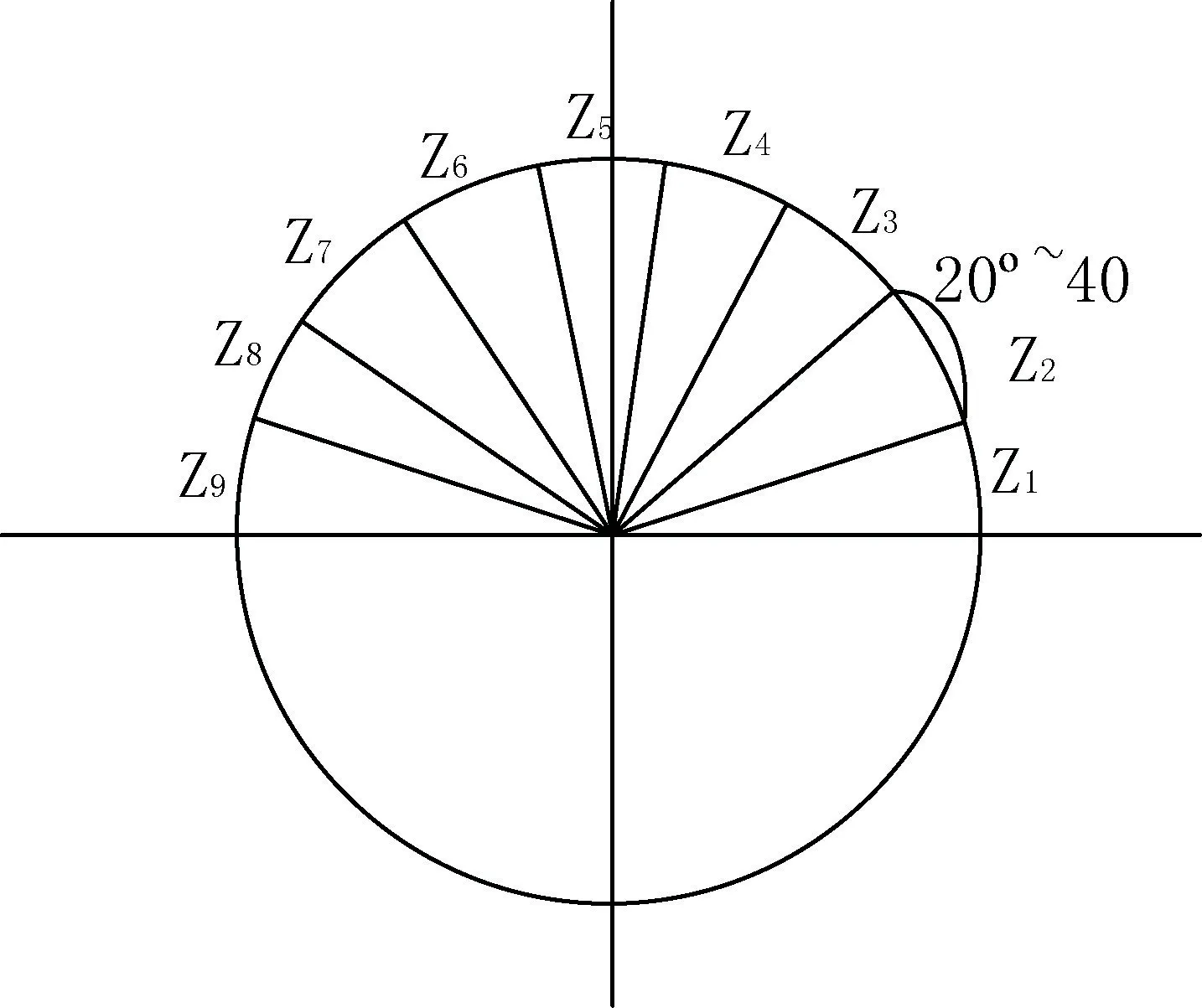
图1 梯度信息统计
第四步,对块区域归一化。 由于局部光照的变化以及前景背景对比度的变化,使得梯度强度的变化范围非常大,这就需要对梯度做局部对比度归一化。 归一化能够进一步对光照、阴影、边缘进行压缩,使得特征向量对光照、阴影和边缘变化具有鲁棒性。
具体的做法是将小单元组成更大的块区域,然后针对每个块区域进行对比度归一化。 最终的描述子是检测窗口内所有块内的小单元的直方图构成的向量。
如图2 所示,一个块区域由2×2 个小单元组成,每一个小单元由8×8 个像素组成,每一个小单元有9 个直方圆通道,所以一个块的特征向量长度为2×2×9。
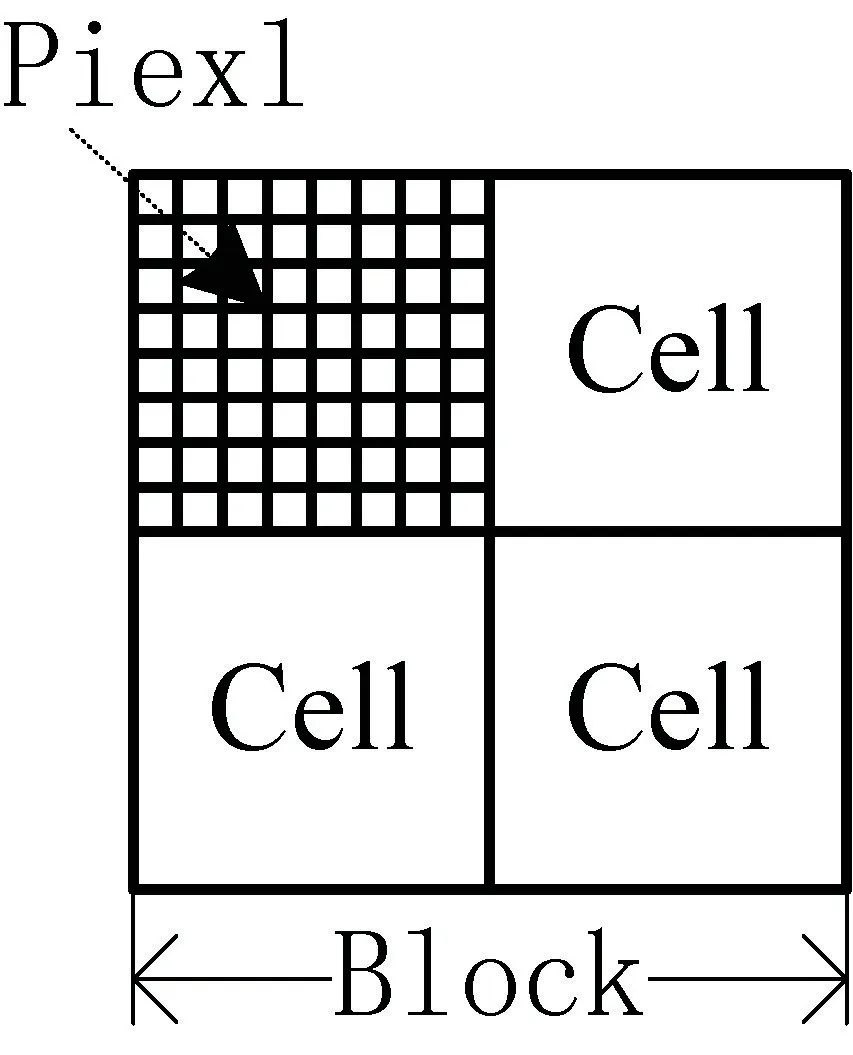
图2 2×2 个小单元组成的块区域
假设v 是一个没有归一化的向量,‖v‖k表示v的k 范数,对向量进行归一化公式为:
上式中ξ 是一个很小的常数,主要是防止分母为0。
第五步,提取HOG 特征。 最后一步就是收集所有块区域的HOG 特征向量,并将它们结合成最终的特征向量送入分类器。
3 Adaboost M2 算法
Adaboost 是由Schapire 等[10]首先提出来的一种用于二分类问题的集成方法,紧接着出现了adaboost M1 将二分类扩展到多分类问题,而adaboost M2 不仅可以处理多分类问题,还引入了置信度的概念,进一步扩展了adaboost 算法,提高了算法在分类过程中的准确度。
假设训练集S ={xi,yi},i =1…N;其中样本xi对应的标签yi∈C,C ={c1…cm};T 是迭代次数;I 是弱分类器。
第一步,训练参数初始化:
上式表示第i 个样本在初始条件下占训练样本集的比重。
上式表示第i 个样本在初始条件下某个错误标签y 的权重。
第二步,进入循环,迭代次数从1 到T,在第t 次,弱分类器I 所需要的参数如下:
上式表示在第t 次迭代中样本i 的错误标签的权重和。
上式表示第i 个样本在所有样本中占的权重。ht= I(S,Dt)
第三步,进入第t+1 次循环时,更新权重参数如下:
上式中,i =1…N,y ∈C - {yi} 。 其中在第三步中,Adaboost M2 算法考虑了样本被错分的权重,从而进入下一次循环中,得到了权重参数的修正。
第四步,输出训练器:
在本文算法当中,表1 中列出了3 类头饰训练集,对应的相应的标签是3 种类别,分别是发髻(Hairpin)、僧帽(Monk-hat)和头冠(Crown)。
4 实验
本文实验过程的数据集如表1 所示,有3 种类别,分别是发髻、僧帽和头冠,每一种类别都有训练数量和测试数量。
文中算法的测试,通过在样本内、外进行,样本内就是测试样本和训练样本重合,样本外就是测试样本和训练样本不重合,实验结果如表2—3 所示。

表2 样本内分类实验结果
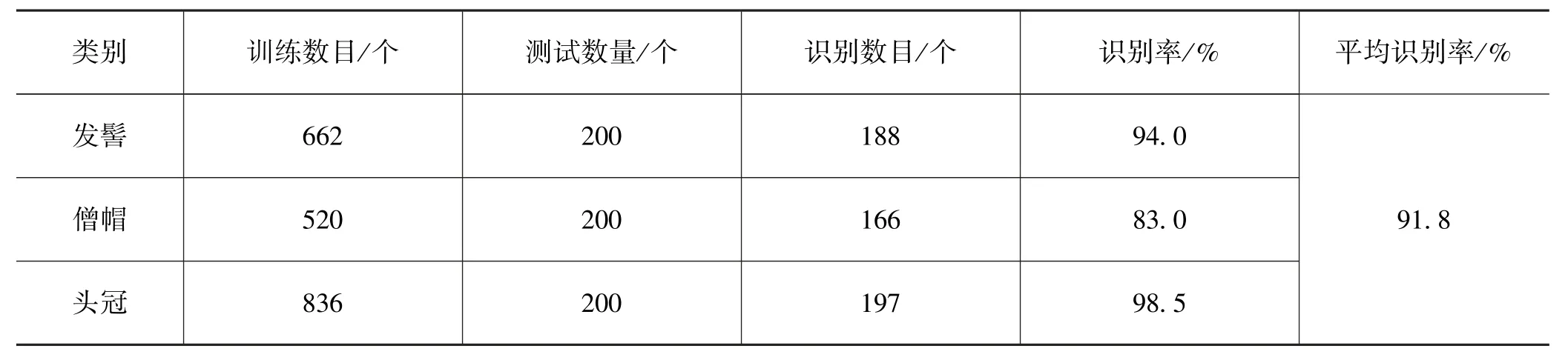
表3 样本外分类实验结果
将本文算法Adaboost M2+HOG 和SVM[5]、leastsquares curve fitting[6]、最大类间[7]3 种方法在同一测试集下进行样本外的检测精度对比,可以看出,本文算法优于其他方法,实验结果如表4 所示。
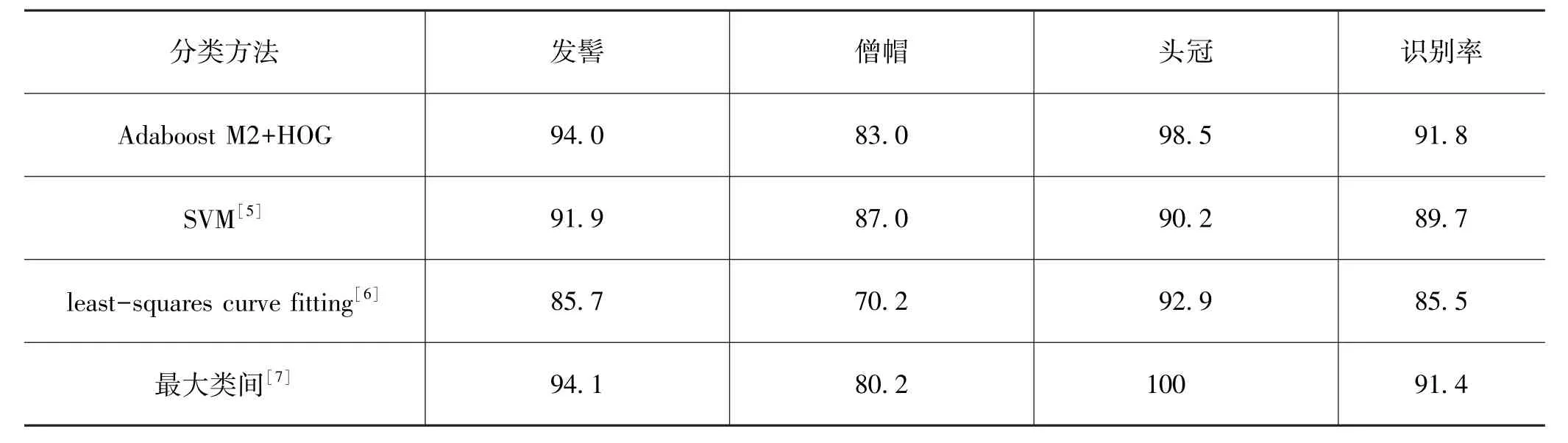
表4 不同方法识别精度比较(单位:%)
5 结语
本文算法的提出,对肖像类唐卡图像在数字化保护过程中分门别类的归档具有重要意义,为后期学者对唐卡图像的研究,进行海量数据的精确检索,提供了可行的算法保证。 当然,对肖像类唐卡图像的3 类头饰元素进行标注,如何综合图像的深层信息,在图像标注过程中更明确、更细致,是今后研究的重点工作。
猜你喜欢
玩具世界(2022年3期)2022-09-20
艺术品鉴(2020年6期)2020-08-11
紫禁城(2020年3期)2020-04-26
科技创新与应用(2020年6期)2020-02-29
娃娃乐园·综合智能(2019年11期)2019-12-18
中国三峡(2016年10期)2017-01-15
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
自然与文化遗产研究(2016年2期)2016-05-17
