
农产品评价观点抽取和情感识别系统设计实现
2023-08-15 02:02周梓豪吴军辉
计算机技术与发展 2023年8期
陈 杰,周梓豪,吴军辉
(同济大学 电子与信息工程学院,上海 201804)
0 引 言
随着电子商务的普及,更多的消费者通过在线平台购买农产品,例如京东生鲜、天猫超市、每日优鲜等,并持续地产生海量的评价信息。观点挖掘作为NLP领域的分支,是典型的文本数据挖掘技术,能够发挥大数据的“4V”特征优势[1]。将该方法运用于农产品评价分析中,有助于消费者了解产品画像,经销商和电商平台掌握消费者的需求,监管部门及时发现产品的问题。
观点挖掘被定义为判断作者对特定实体发表意见的情感倾向的任务[2]。按照面向对象的不同可以划分为粗粒度和细粒度目标[3]。先前的研究主要集中在对评价整体进行粗粒度的分析[4]。细粒度任务是一个新兴的方向,目前已被应用在旅游景点、在线论坛等领域[5-6],其主要分为方面观点目标提取和目标情感识别两个子任务[7]。在模型的选用上可以分为基于知识的方法和学习的方法[8]。在基于学习的方法中,先前研究通常使用支持向量机、隐马尔可夫模型等统计学习方法[9]。随后,基于目标依赖和关联的长短期记忆神经网络和注意力机制运用于该任务中[10]。但基于学习的方法需要大量人工标注的领域数据集进行训练,且对于结构复杂句子的拟合效果不佳。在基于知识的方法中,Qin等[5]根据外部知识库提炼出游客关心的旅游景点属性,构建三级评价体系的决策系统进行观点挖掘。万岩等[11]在微博评论分析中构建了融合情感词典和语义规则的模型。上述方法能够较好地提取并识别显式观点,但忽略了评价语法表达的多样性而导致隐式观点的遗漏,在短评价观点挖掘任务中最为常见[12]。目前已有通过有监督、半监督和无监督学习的方法识别隐式观点的研究。Li等[13]从领域内语料库中检索出带情感标注的数据集进行有监督的对比预训练,通过将隐含情感特征表示和具有相同标签的情感表达对齐,来捕捉评价中的隐式观点特征。Xu等[12]构建融合SVM和主题模型的半监督方法提取隐含观点。相比之下,无监督方法具有无需人工标注训练集的优势,在该方法中往往使用包括层次结构、本体识别、主题建模、共现、依存关系分析、关联规则挖掘和聚类等各种NLP模型[14]。Hu等[15]根据近邻关系将评价中的属性词与情感词对应,但忽略了语法元素的依赖而造成抽取观点的效果较差。在此基础上,Sun等[16]提出属性词和情感词之间的上下文语境关系对识别隐式观点具有一定帮助。也有研究将词对依存规则与词法分析结合,以更精确地抽取方面观点[17]。
目前的观点挖掘技术已取得较多应用成果,但少有在农产品领域开展应用的文献和开源数据集。为解决上述问题,该文结合爬虫技术获取多源电商农产品评价数据,构建了一种基于无监督学习框架的评价观点抽取和情感识别系统。在算法层面,对传统单一模型进行改进,组合了LDA主题模型、SO-PMI算法、依存句法规则和词嵌入相似度计算的NLP技术,以更好地识别隐式的方面观点并进行情感识别。在应用层面,根据分析结果构建可视化平台,从品类、品种、品牌和店铺的不同角度挖掘消费者偏好,通过词频统计比较产品的优势和缺陷,以期服务于消费者、经销商、电商平台和监管部门四个主体。
1 观点抽取和情感识别方法实现
该文构建无监督学习框架的观点抽取和情感识别方法,如图1所示,包括了数据采集和预处理、主题识别和词典构建、方面观点抽取和情感识别算法以及可视化平台搭建应用四个模块。以下将详细介绍上述流程运用的技术。

图1 基于无监督学习的分析技术框架
1.1 数据采集与预处理
该文采用Python语言的Selenium框架爬虫技术,分别从京东生鲜和天猫商城网站获取多源农产品评价数据。根据产品销量排序分别获得包括花生、玉米、苹果、梨、猕猴桃、橘子、芒果、竹笋、茶叶、茶油的10个农产品品类商品的评价数据。在进行数据融合的同时进行数据清洗,首先去除重复评价和空评价,然后运用正则化表达式去除评价中的数字和表情符号,导入停用词典去除评价中的无效信息,并去除字符数量少于3的过短评价和大于200的过长评价,最终得到1 147 861条评价作为该文的数据集,并附带有评价对应的商品链接、店铺、品牌和品种信息,采集结果写入MySQL中。
1.2 领域主题识别和词典构建方法
1.2.1 基于LDA模型的领域主题识别
为确定消费者所关注的电商农产品主题属性,该文根据获取的评价数据使用LDA模型进行主题挖掘,通过调用Gensim库下的LdaModel方法完成上述任务。在构建LDA模型的过程中,采用基于困惑度的方式确定最优主题数K的取值,困惑度取值越小说明生成模型效果越好[18]。其计算方法如公式(1)所示:

(1)

1.2.2 领域属性词典和情感词典构建
筛选出LDA模型输出结果中每个主题的名词、动词关键词作为核心属性词,在此基础上,引入中文工具包Synonyms对每个核心属性词进行近义词扩充,对部分没有主题意义的噪声词进行过滤,最终形成包含275个词汇的领域属性词典,示例如表1所示。
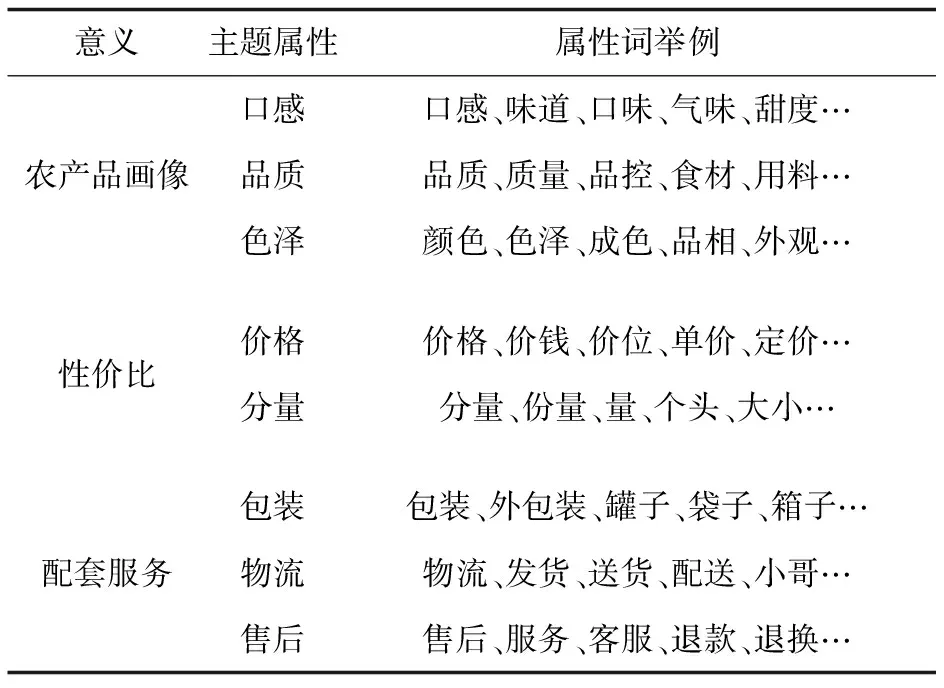
表1 领域属性词典构建结果
另一方面,需要构建的情感词典包括基础情感词典、领域情感词典和情感修饰词典。首先选用HowNet发布的“情感分析用词语集”中的中文正负面评价词典作为基础情感词典 ,包含3 730个正面情感词和3 116个负面情感词。为了识别评价中未与属性词搭配的情感词,即隐式方面观点,构建有效的领域情感词典是必要的。根据领域属性词典,运用分句和字符串匹配将农产品评价按照8个主题属性切分形成子句集,使用TF-IDF算法识别各属性下的词频排序前100的形容词和名词,公式如式(2)所示:
(2)
式中,TFw,Di表示词汇w在文档Di中出现的频率,IDFw表示其逆文档频率,count(w)统计词汇w出现的频次,|Di|为Di中所有词的频数,N为文档总数,I(w,Di)表示Di中是否包含词汇的0/1变量。剔除在多种属性下共同出现的高频词汇,得到相应属性的候选情感词集。然后根据基础情感词典判断词汇的情感倾向,筛选出对应属性的种子情感词。针对部分未被基础情感词典收录的词汇,结合种子情感词运用SO-PMI算法确定情感极性[19]。基础SO-PMI公式如式(3)(4)所示:
(3)
(4)
式(3)中,P(word1)和P(word2)分别表示候选情感词汇和种子情感词出现的概率,P(word1&word2)表示它们共现的概率,式(4)中pwords和nwords分别表示正面和负面的种子情感词集。先前普遍认为SO-PMI算法得到的SO_PMI值大于0标注词汇为正面情感,小于0标注为负面情感,但实际情况中存在大量情感值接近于0的中性情感词,因此对SO_PMI值进行Min-Max标准化线性转换,公式如式(5)所示:
(5)


表2 领域情感词典构建结果
情感修饰词包含程度副词和否定词,其作用是影响评价情感语义强度[20]。例如程度副词“非常”能够加强情感词的强度,“略微”对情感词强度起减弱作用,而否定词“没有”逆转了情感词的语义。该文以HowNet词汇为基础,选取了220个程度副词和58个否定词构成情感修饰词典,根据各个情感修饰词对情感表达的加强、减弱或逆转的作用,将词典划分为7个等级并赋予从-1到2不等的情感权重。例如“非常”“极其”“极度”等69个词的情感权重设定为2,“很”“太”“特别”等42个词的情感权重设定为1.5,“稍微”“相当”“有点”等29个词的情感权重设定为0.6,“不”“没有”“并非”等58个词的情感权重设定为-1。
1.3 方面观点抽取和情感识别
1.3.1 基于依存句法规则的方面观点抽取
方面观点是评价中针对领域属性的情感特征表示,一般由属性词、情感词和情感修饰词组成。先前研究总结方面观点表达通常存在于主谓关系、动宾关系、定中关系、并列关系、动补结构、状中结构的依存句法关系中[21],该文额外地补充了省略属性词的隐式观点表达和同义转述的潜在观点表达两种情况,示例如表3所示。

表3 方面观点表达形式举例
该文使用哈工大语言技术平台(LTP)提供的功能,首先将评价按照标点符号划分为子句后进行分词和词性标注,通过识别句子的核心词成分和句法结构来分析词汇之间的语法依赖关系。然后融合领域属性词典和情感词典制定了7条依存句法规则,分别对显式方面观点、隐式方面观点、潜在方面观点和情感修饰词进行抽取,尽可能地挖掘评价中的情感信息。
规则1:当评价同时存在属性词和情感词时,若满足SBV、ATT或CMP,提取<属性词,情感词>作为显式方面观点。若有多个满足条件则按照最近邻关系搭配。
规则2:当评价中仅存在领域情感词典中的词汇,而没有关联的属性词时,将所有的领域情感词分别抽取出来,形成
规则3:识别未被属性词典概括的未登录词。当核心词词性在[‘n’,‘v’,‘nz’]中,提取作为属性词。然后抽取满足VOB或CMP的形容词作为情感词,形成<属性词,情感词>表达潜在方面观点,若匹配失败则舍弃属性词。
规则4:识别未被情感词典概括的未登录词。当核心词词性在[‘a’,‘u’,‘d’]中,提取作为情感词。然后抽取满足SBV或ATT且词性在[‘v’,‘n’, ‘j’,‘nz’]的词汇作为属性词。若匹配失败也将情感词保留,形成<属性词,情感词>或
规则5:识别核心词周围的潜在情感表达。首先提取和核心词满足VOB且词性在[‘v’,‘n’, ‘j’,‘nz’]的词汇作为属性词,匹配和该词关联的形容词作为情感词,若匹配失败则舍弃。然后提取和核心词满足VOB或CMP的形容词作为情感词,匹配和该词关联的词性在[‘v’,‘n’,‘j’,‘nz’]的词汇作为属性词,若匹配失败也将其保留,形成<属性词,情感词>或
规则6:在规则1到规则5的基础上,寻找与方面观点满足COO的元素。抽取出的元素与属性词共享情感词和情感修饰词,或与情感词共享属性词,形成新的方面观点。
规则7:在规则1到规则6的基础上,提取和情感词满足CMP或ADV的副词作为情感修饰词,最终的方面观点列表以弹性三元组格式存储。在该格式中,属性词可能不存在而情感词必须存在,情感修饰词可能不存在或存在多个。其表达方式有<属性词,情感修饰词,情感词><属性词,null,情感词>
1.3.2 基于词嵌入和情感值计算的情感识别
(1)词嵌入模型。
抽取评价的方面观点列表后,需要识别每个方面观点表达的主题属性和情感倾向。对于显式和隐式的方面观点,可以通过词典匹配得出识别结果。对于潜在方面观点,需要判断属性词、情感词与领域词汇是否为同义词,区分其是有效的情感表达还是噪声。首先需要把文本数据转化为词向量表示,word2vec是一种经典的词嵌入方法,与one-hot编码相比解决了维度灾难问题[22],该文使用Gensim库建立word2vec模型。将农产品评价数据集与开源的wiki百科语料库合并对模型进行预训练,设置参数size=250,min_count=5。然后导入模型将词汇转化成词向量的形式,计算潜在方面观点中属性词、情感词与领域词典词汇的余弦相似度,计算方法如公式(6)所示。
(6)
式中,w1和w2表示两个词汇的词向量,size表示维数,cos(w1,w2)表示两词的余弦相似度。经过反复实验,设定相似度阈值为0.85,匹配相似度最大且大于0.85的领域属性词汇对应的属性作为潜在方面观点属性,若匹配失败,进一步选取相似度最大且大于0.85的领域情感词汇对应的属性作为其属性,若匹配失败则将该潜在方面观点判定为噪声数据。
(2)情感强度计算。
实际情况中,方面观点可能存在多个情感修饰词同时搭配一个情感词的情况,且“否定词+程度副词+情感词(ne+dg+se)”与“程度副词+否定词+情感词(dg+ne+se)”的情况表达不同的情感态度。例如评价句“口感不是很好”与“口感很不好”相比,后者的负面情感强度更大。针对单个方面观点中5种不同搭配情况,情感强度的计算方法如公式(7)所示。
qi=
(7)

(8)
式中,Nb表示评价中提及属性b的方面观点个数,qi_c表示第i个方面观点的情感强度,Vb表示评价在属性b的方面情感强度,若Vb大于0表示评价在属性b的正面表达,小于0表示负面表达,等于0表示无情感表达。根据计算结果对每条评价进行方面情感倾向标注。
1.4 消费者偏好挖掘
1.4.1 关注度分析
统计评价的观点抽取和情感识别结果,可以反映消费者的偏好。一方面,现有研究指出消费者对不同主题属性有不同的重视程度[23],该文引入关注度的概念衡量这方面的差异,计算方法如公式(9)所示。

(9)

1.4.2 满意度分析
另一方面,现有研究集中在从评价中提取消费者偏好信息衡量对产品的满意度[24]。该文计算在每个领域主题属性下的正面情感评价数量与评价总数的比率,量化消费者对农产品属性满意度差异,计算方法如公式(10)所示。

(10)

1.4.3 产品优势与缺陷分析
将方面观点三元组的抽取结果按照主题属性和情感值是否大于0进行划分,分别对属性词、情感词与整体方面观点表达进行词频统计,选取正面方面观点的高频表达作为农产品的主题属性优势,选取负面方面观点的高频表达作为农产品的主题属性缺陷。
2 模型性能分析与实际应用
2.1 实验设计
2.1.1 验证集来源
由于目前还没有开源的农产品评价标注数据,该文从农产品评价数据集中随机抽取1 000条数据,提取其中包含的方面观点后,人工标注每条评价的情感标签作为验证集,1表示正面情感,-1表示负面情感,-2表示无情感,验证集的示例如表4所示。

表4 验证集的示例
2.1.2 实验方案
中国改革开放40年来取得的巨大减贫成就,既内含着特定的时空因素和中国独特的政治制度与治理体系的影响,也形成了一些可与其他国家分享的经验。中国减贫经验中可复制、可分享和可持续的部分,应该成为中国未来减贫和世界减贫事业的重要知识财富。本文主要从扶贫者(政府)视角,基于官方公开数据,总结改革开放40年来中国农村扶贫开发所取得的成就,讨论和分析中国农村减贫的基本经验及其对世界减贫事业的意义。
一方面,将文中模型与传统的无监督识别方面级情感的方法进行对比,对比模型选用Zhang等[25]提出的基于PMI统计方法模型(Baseline_pmi),Sun等[16]提出的基于共现矩阵相似度模型(Baseline_co_sim),以及张林[26]提出的基于Hanlp工具的依存句法规则和情感值计算的模型(Hanlp_model)。另一方面,通过消融试验验证文中模型中各个方法所起的作用。在依存句法规则的基础上使用领域情感词典和词嵌入是关键的,前者侧重于识别隐式观点,后者侧重于识别潜在观点。因此设定其它三种模型分别为:仅运用依存句法规则的模型(Ltp_dp)、加入词嵌入相似度判别的模型(Ltp_dp_vec)、加入SO-PMI构建领域情感词典的模型(Ltp_dp_sopmi),并与文中模型进行对比。
2.1.3 验证指标选取
选取机器学习验证指标(查准率、召回率和F1值)对模型进行性能度量[27]。查准率指正确识别情感标签占所有识别出情感标签数量的比例,召回率指正确识别情感标签占所有情感标签的比例。F1值是准确率与召回率的平均值,并根据每类情感标签分类结果计算宏平均值反映模型整体性能。上述验证指标的计算方法如公式(11)~(13)所示。
(11)
(12)
(13)
式中,P表示查准率,R表示召回率,Macro_F1表示所有情感标签类别的宏平均F1值。
2.2 模型性能比较
模型性能比较结果如表5所示。传统Baseline_pmi和Baseline_co_sim模型查准率和召回率较低,原因是基于统计或共现的方法忽略了词汇句法关系造成大量噪声,且无法较好地关注到低频词。单独使用依存句法的模型Ltp_dp召回率较低,这是因为忽略了评价中的隐式和潜在情感信息。加入词嵌入相似度的模型Ltp_dp_vec与加入SO-PMI构建领域情感词典的模型Ltp_dp_sopmi,召回率和F1值均有所提高,前者召回了部分潜在情感信息,后者抽取了更多隐式情感信息。文中模型的查准率、召回率和F1值分别为85.08%,78.50%和81.66%,尤其是召回率和F1值提升显著,达到了最优的模型性能。相比之下,基于Hanlp工具的模型在分词和依存句法标注上的精确性不如LTP,且忽略SO-PMI和词嵌入相似度最优阈值的设定也将降低模型性能。
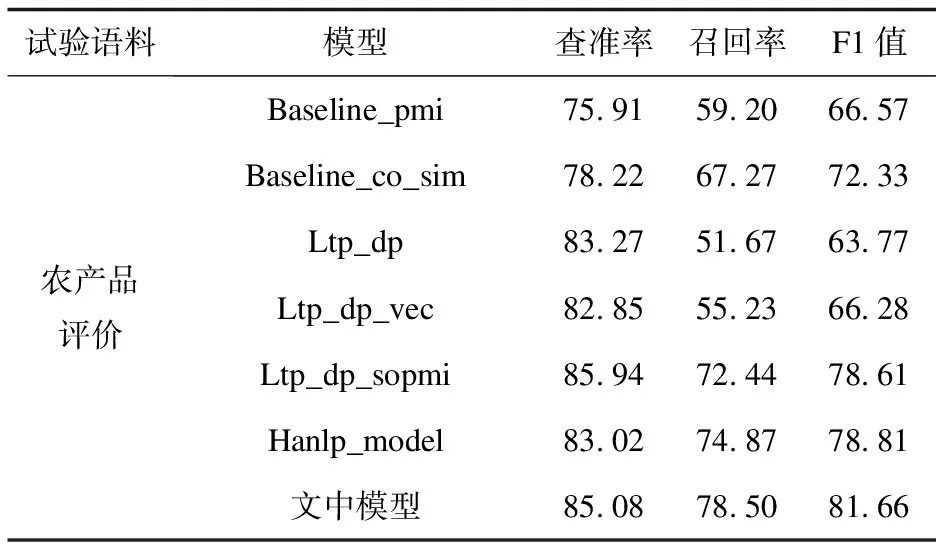
表5 不同模型试验结果对比 %
2.3 系统的搭建与应用
基于该文设计的算法,使用Django后端+Booststrap前端框架作为主体框架进行观点抽取和情感识别系统的搭建,使用Layui和Echarts组件进行分析结果可视化展现。在系统的前端部分,分别设计了文本输入模块与根据农产品品类、品种、品牌、店铺名称进行条件筛选模块,用户提交表单后实时返回查询的结果。在系统的后端部分,设计了数据接收、数据处理和数据提交功能,前后端之间通过ajax进行JSON数据的传输。根据系统功能的不同,可分为观点抽取和情感识别功能、消费者偏好挖掘功能两类。
2.3.1 观点抽取和情感识别功能
该功能可以分为在线分析与离线分析,在线分析功能的界面展示如图2所示。系统用户输入需要判别的农产品评价数据、选择品类并点击提交后,前端向服务器发送请求,Django后端实时调用该文的算法接口,返回面向农产品主题属性的有效方面观点三元组抽取结果和对应的情感强度得分结果。

图2 在线分析功能界面展示
另一方面,系统启动时后端通过调用评价爬虫模块、观点抽取和情感识别模块对MySQL中的评价数据进行持续的增量更新。离线分析功能的界面展示如图3所示,系统用户可在前端通过下拉框筛选需要查询的农产品品类、来源、店铺、品种、商品链接所对应的评价数据,每条评价都展现所抽取的方面观点三元组和生成的方面情感倾向信息。

图3 离线分析结果查询界面展示
2.3.2 消费者偏好挖掘功能
对农产品评价语料进行观点抽取和情感识别后,可根据公式(9)和(10)分别计算不同农产品品类、品种、品牌和店铺下消费者对领域主题属性的关注度和满意度差异。图4以农产品品类为例分析了上述区别。在关注度方面,与其它属性相比,消费者更侧重于关注口感和价格属性, 平均值分别达到0.29和0.26。但不同品类之间存在关注度的差异。例如,消费者对于竹笋和花生的口感属性关注度分别为0.40和0.26,显著高于其它农产品;对于猕猴桃的价格属性关注度达到了0.30,与之相比消费者对茶叶的价格属性关注度较低,仅为0.19。在满意度方面,在线农产品的包装和物流属性被多数消费者认可,满意度均值分别达到了0.84和0.86。在具体的口感属性方面,花生品类得到了最多消费者的喜爱,满意度达到了0.90,但猕猴桃的口感满意度仅为0.61;在色泽属性方面,茶叶品类的满意度最高达到了0.89,但芒果和猕猴桃的满意度较低,分别仅为0.54和0.57。

图4 消费者关注度和满意度分析界面展示
另一方面,对海量评价数据抽取的有效方面观点三元组进行词频统计和排序,为平台用户提供产品的属性级优势与缺陷分析,以售卖猕猴桃品类的店铺“绿美生鲜专营店”的口感属性缺陷的高频情感词为例进行分析,图5展示了分析结果,可以看出该店铺在口感方面的缺陷主要体现在“硬”“酸”“不甜”“难吃”等。

图5 具体店铺的口感属性缺陷分析界面展示
该系统面向的用户主要分为消费者、经销商、平台和监管部分四个主体。消费者可以通过历史消费者的评价观点挖掘结果进行购买选择,农产品经销商和平台可以根据消费者偏好挖掘结果更有针对性地对产品进行具体属性的改进,监管部门通过查询具体店铺的农产品属性级缺陷,及时发现问题并进行管控。该平台上线后取得了良好的应用效果。
3 结束语
针对如何在缺少标注数据集的情况下对农产品评价进行观点抽取和情感识别的问题,提出了一种组合NLP方法的无监督学习框架。采集多源评价数据后,首先采用LDA模型对领域主题进行识别,运用改进的SO-PMI算法构建领域词典,然后结合依存句法规则和词嵌入相似度对评价中的隐式和潜在方面观点进行更好地召回,并定义了情感强度的计算方法标注方面级情感倾向。相较于传统模型,该文的分析识别框架在性能上得到明显的提升,在农产品评价语料中查准率、召回率和F1值分别达到85.08%、78.50%、81.66%。基于该算法框架搭建的可视化系统具有在线、离线识别功能和基于不同角度的消费者偏好分析功能,分析结果致力于为不同的主体提供信息价值。
猜你喜欢
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
文苑(2019年24期)2020-01-06
中华胰腺病杂志(2019年4期)2019-08-29
军营文化天地(2018年1期)2018-08-15
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
营销界(2015年22期)2015-02-28
清风(2014年10期)2014-09-08
当代修辞学(2013年4期)2013-01-23
