
基于多通道注意力图卷积网络的微服务分解
2023-08-15 07:55来风刚羊麟威钱李烽
计算机技术与发展 2023年8期
张 攀,来风刚,周 逸,羊麟威,钱李烽,刘 昕,李 静
(1.国家电网有限公司信息通信分公司,北京 100053;2.南京航空航天大学 计算机科学与技术学院/人工智能学院,江苏 南京 211106)
0 引 言
伴随云计算技术的快速发展,为了充分利用云基础设施,灵活进行业务扩张和性能伸缩,降低维护成本,Amazon、IBM、Google等大型公司研究将单体应用软件系统迁移为基于微服务的架构[1-3]。与单体架构将系统各个模块紧耦合不同,微服务架构由许多独立的服务组成,每个服务可独立修改、开发、部署和维护。微服务分解是将现有代码重构为一组较小的独立代码组的过程。目前大多数微服务分解过程是手工完成的,代价昂贵、耗时且易于出错,其质量通常与专家经验和知识密切相关,因此,迫切需要自动化的过程来将单体应用转换成微服务系统,微服务分解已成为软件工程和云计算领域研究的重要问题之一。
近些年,已有许多工作研究单体应用系统的微服务分解方法。Levcovitz等人[4]于2016年提出一种基于人工经验功能分解的微服务分解方法。Chen等人[5]于2017年使用基于数据流进行候选服务分解。Baresi等人[6]于2017年提出了一种基于OpenApi规范规定的功能语义相似性的方法。Tyszberowicz等人[7]于2018年提出了一种基于软件需求功能分解微服务的方法。Munezero等人[8]于2018年提出一种使用领域驱动设计(DDD)模式分解微服务的方法。Ding等人[9]于2020年提出了一种场景驱动、自底向上的融合用户反馈的半自动化拆分方法。Zhang等人[10]于2020年提出一种围绕负载均衡作为优化目标的基于运行轨迹的多目标优化的微服务分解方法。Brito等人[11]于2021年提出一种基于主题建模的微服务分解方法。上述的大多数方法需要耗费大量的人力,并且依赖专家知识,微服务分解的效率与质量难以保证。另外,大多数方法存在只适用于一个数据集的情况,在多个数据集上缺乏可扩展性,或者缺少自动化实现的方法。
针对上述问题,受到多通道信息融合模型的启发,该文使用多通道注意力图卷积网络对软件实体进行建模和嵌入特征表示学习,提出基于多通道注意力图卷积网络和Java单体程序微服务分解联合学习框架MAGEMP。
主要贡献表现在:(1)提出一种多通道注意力图卷积网络微服务分解框架,用于建模Java源代码中提取的实体类信息的嵌入特征学习任务;(2)构建了基于注意力的多通道图卷积网络特征嵌入融合机制,可以实现多通道信息的有效融合,提升多通道特征表示能力;(3)在M2M[12]提供的公开通用数据集上进行了广泛的实验,表明多通道深度注意力图神经网络模型在微服务分解方面较同类算法COGCN[13]有了显著的提升。
1 相关工作
微服务分解的主要标准是每个微服务尽最大可能满足低耦合和高内聚标准[14]。采用聚类的方法进行微服务分解是目前的一个主流趋势,因此,本部分将主要介绍利用聚类算法进行微服务分解的相关工作。
Mitchell等人于2006年提出的Bunch[15],使用源代码分析工具将源代码转化为一个有向的模块依赖图(MDG),然后将微服务分解建模为MDG划分空间的聚类搜索问题。Gysel等人[16]于2016年引入了一个基于16个耦合标准的服务分解工具,这些标准来源于行业和文献,通过创建加权图,利用聚类算法分解潜在的微服务。Mazlami等人于2017年提出的MEM[17]模型使用逻辑耦合、语义耦合及贡献者耦合三种不同的耦合策略,将单体应用程序转换为一个无向加权图并使用基于KRUSKAL的最小生成树聚类算法确定可能的微服务。Amiri等人[18]于2018年提出一种使用业务流程模型和符号从业务流程中表示微服务的方法,实现过程中对结构依赖和数据对象依赖信息使用简单的矩阵加法进行了聚合。Jin等人于2019年提出的FoSCI[19]模型,采用非支配排序遗传算法-II进行多目标优化,将“功能原子”分组为每个候选服务的类实体,对每个候选服务识别带有操作的接口类,将它们与类实体结合生成一个候选服务。Desai等人于2021年提出的COGCN[13]方法使用Soot工具获得Java程序中类和类之间的调用关系图,利用深度图神经网络学习该图的嵌入表示,结合K-Means聚类算法实现微服务分解。Kalia等人于2021年提出了M2M[12]方法。通过运行时追踪数据,构建以类为节点的调用追踪关系。然后通过定义的直接调用关系、间接调用关系、直接调用模式和间接调用模式四种时空特征计算类和类之间的相似性矩阵,最后使用层次聚类方法将应用程序类划分成不相交的微服务。
2 问题描述
MAGEMP的目的是将Java单体应用程序根据代码中类之间的相似性进行划分。在Java应用程序中,程序都是由类组成的,类和类之间的调用关系可以表示为类之间的调用图形式,以图的结构来表示。为了充分利用多属性特征以构建更加高效的微服务分解方法,MAGEMP将该问题建模为一个多通道图神经网络知识表示学习和聚类过程。
2.1 基于多通道图的特征嵌入

2.2 多通道图聚类
给定属性图G',多通道图聚类的目的是在没有标签数据的前提下,使用非监督学习将图中节点分割为K个不相交的簇ζ={ζ1,ζ2,…,ζk},分解出K个簇,以满足:在同一簇内的节点之间在结构上距离更小且在同一个簇内的节点属性更具相似性。
3 MAGEMP
针对COGCN方法没有充分利用多通道信息建模的问题,对Java单体程序中获取的类和类之间的多属性关系建模,提出一个集成多通道信息的统一框架MAGEMP。如图1所示,模型框架的主要流程包括:

图1 MAGEMP框架
(1)多通道图构建。将Java单体应用中获取的类和类之间的多属性特征矩阵构建成多通道图;
(2)构建基于多通道图卷积神经网络的特征嵌入学习模型,每个通道得到新的特征嵌入表示,每个通道图卷积神经网络由编码器和解码器组成;
(3)基于节点重要性的注意力融合机制将融合得到新的嵌入表示。
通过联合学习框架不断优化参数,最后使用谱聚类算法进行聚类,得到微服务的分解方案。
3.1 多通道图构建
p是某应用中入口点集合。如果classi出现在入口点p所在的执行追踪中,则Xclass-trace(i,p)=1,否则Xclass-trace(i,p)=0。进一步计算某个入口点开始的调用链同时包含classi和classj的次数,获得属性矩阵Xclass-occurence。最后,通过分析类之间的继承关系得到继承关系矩阵Xclass-inheri,如果两个类存在继承关系,则Xclass-inheri(i,j)=Xclass-inheri(j,i)=1,否则,Xclass-inheri(i,j)=Xclass-inheri(j,i)=0。
为了能够捕捉到应用程序中类和类之间的全面深度关系,对三种关系矩阵进行新的组合形成多通道信息数据对,即:
X1=(Xclass-trac,Xclass-occurence)
X2=(Xclass-trac,Xclass-inheri)
X3=(Xclass-occurence,Xclass-inheri)
使用A∈R|V|×|V|表示该图的邻接矩阵,定义为:
因为本问题中类之间的调用图固定,因此三个通道属性图具有相同的邻接矩阵A。下一步,将(X1,A)、(X2,A)和(X3,A)分别输入到多通道注意力图卷积网络编码器模块中。
3.2 多通道图卷积神经网络架构
3.2.1 多通道图卷积神经网络编码器模块
MAGEMP中,每一个通道都使用了图卷积网络(GCN)[20]。图卷积神经网络从邻居节点聚合信息并学习图中每个节点的嵌入表示:
(1)

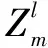
(2)

(3)
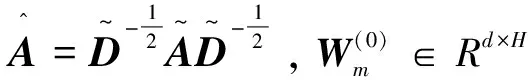
3.2.2 多通道图卷积神经网络解码器模块
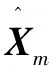
(4)
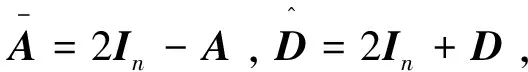
(5)
σ是激活函数。使用重建的信息数据对和邻接矩阵和原始的信息数据对和邻接矩阵的误差优化网络,定义为:
(6)
3.3 注意力融合机制和聚类模块
3.3.1 注意力融合机制
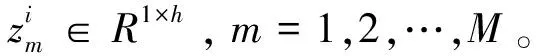
(7)

(8)
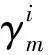
(9)
3.3.2 聚类模块
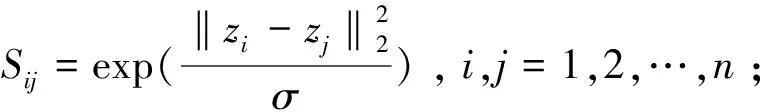
为了能够获得更具有判别性的嵌入表示和最优聚类结果,完成谱聚类后,构建簇的k-d树,借助k-d树实现最近邻的快速查找,找到与节点zi同一个簇中曼哈顿距离最近的邻居节点zj。定义损失函数[22]:
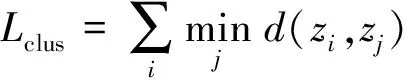
(10)
其中,d(zi,zj)表示节点i和节点j之间的曼哈顿距离|zi-zj|。
3.4 损失函数
根据MAGEMP网络模型结构,其损失函数由多通道图卷积网络的重建损失和聚类损失组成。定义为:
(11)
其中,γ>0,是超参数。通过最小化该损失函数训练整个多通道注意力图卷积神经网络的参数,得到较高质量嵌入质量表示和聚类效果。
3.5 训练过程
实验过程由三个步骤组成。第一步是对多通道图卷积神经网络模块网络参数进行预训练;第二步是对整个网络进行正式训练,得到最终的参数;第三步是使用学习到的特征嵌入表示Z进行聚类。

(2)正式开始训练过程。对GCN编码器、解码器和注意力层参数进行迭代优化,得到最终的参数。首先将多通道信息数据对和邻接矩阵输入到预训练好的GCN编码器网络。经过模型训练,获得隐含层嵌入表示和注意力层嵌入表示,使用注意力层嵌入表示数据谱聚类,得到划分结果,计算总体损失函数。通过最小化总体损失函数反向传播训练整体网络。
(3)通过学习到的嵌入表示Zm计算仿射矩阵S,进行谱聚类获得最终聚类结果。MAGEMP具体如算法1所示。
算法1:MAGEMP训练算法。
输入:多属性特征图G'=(V,E,Xm),簇的个数K,迭代次数N。
输出:聚类结果R。
/*预训练阶段*/
(2)利用公式(3)~公式(6)对多通道GCN编码器进行预训练,得到初始参数值;
(3)利用公式(3)计算每个通道图卷积编码器嵌入特征表示,利用公式(7)~公式(9)使用注意力机制得到融合的嵌入表示;
(4)对步骤3中经过融合得到的嵌入表示使用k-means算法初始化聚类;
/*在线训练阶段
(5)For iter∈0,1,…,N
(6)使用m通道GCN编码器计算Zm;
(7)使用注意力机制融合嵌入表示;
(8)使用谱聚类计算嵌入表示Z聚类结果;
(9)利用公式(11)计算总损失函数;
(10)利用Adam算法更新神经网络参数;
(11)End for
(12)根据嵌入表示计算仿射矩阵作为谱聚类的权值进行聚类;
(13)计算聚类结果R;
(14)返回R。
4 实 验
4.1 数据集
为了评估该方法,使用Mono2Mirco提供的4个公开数据集[15]进行测试。acmeair是航空公司订票应用系统,daytrader是在线股票交易系统,jpetstore是宠物商店系统,plants是植物商店系统。
4.2 评价指标
为了较好地量化评估MAGEMP模型微服务分解的性能,采用了微服务分解中较通用的满足上述要求的评价指标。评价指标主要有3个:
(1)IFN(independence of functionality)[19]评价微服务是否具有良好定义和独立性,可表示为:
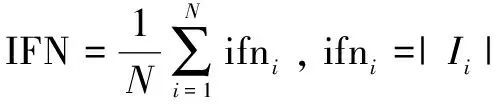
(12)
通常IFN值越小,表示微服务承担责任越单一。
(2)SM(structural modularity quality)[19]用于量化微服务内的类间结构一致性,表示为:
(13)

(3)ICP(inter-partition call percentage)[25]用于评估微服务之间的交互百分比。可表示为:
(14)
其中,ci,j表示不同微服务之间的调用数目。ICP值越小,说明服务之间调用纯度越好。
4.3 基线设置
为了评价所提方法的性能,将其与目前最先进的方法进行比较。第1个基准方法是Bunch[15],它是较早提出的将服务划分问题描述为一个搜索问题的方法,利用爬山搜索技术找到一个能够最大化两个特定度量的划分(微服务),该划分可以最大化结构模块化质量。MEM[17]是基于逻辑、语义和变更历史的耦合构造一个图,将微服务分解建模为图割问题,然后使用最小生成树从构造的图中寻找最小割划分。每个min-cut中的类代表分解出的微服务。FoSCI[19]使用运行时追踪数据作为数据源,利用跟踪规约算法删除冗余的跟踪,然后通过层次聚类来创建“功能原子”,再使用多目标优化算法对这些功能原子进行合并。M2M[12]通过不同的业务用例收集运行时追踪数据[26],使用层次聚类方法将单体应用划分为不同微服务,并公开了相应的数据集。COGCN是第一个使用图神经网络进行微服务分解的深度学习方法,并利用多个损失函数构成了一个端到端的学习框架,再使用K-Means聚类方法分解微服务,也是主要对比的同类方法。
4.4 性能比较
为了验证模型对于微服务分解的效果,分别在四个公开数据集上进行了测试,结果如表1~表4所示。性能测试的结果是在参数设置的范围内运行100次,然后取每个性能指标的中位数[12-13]。其中↑表示该指标值越大越好,↓表示该指标值越小越好。表中粗体表示性能最好。在所有数据集上,MAGEMP取得了显著的效果。
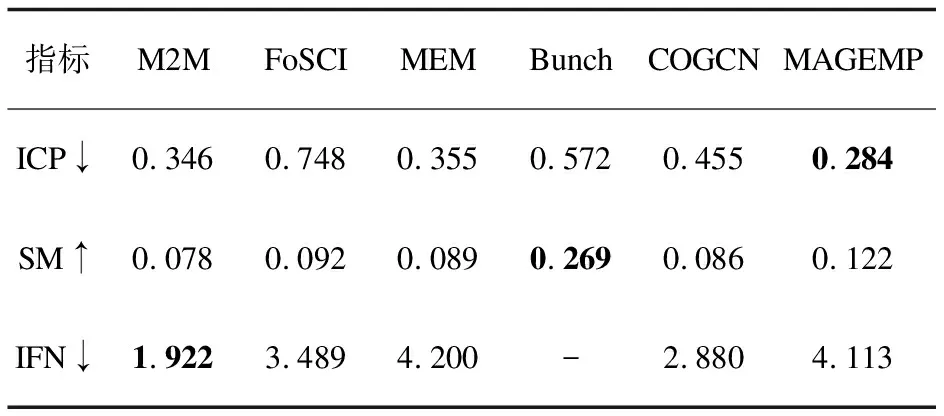
表1 daytrader数据集上的结果
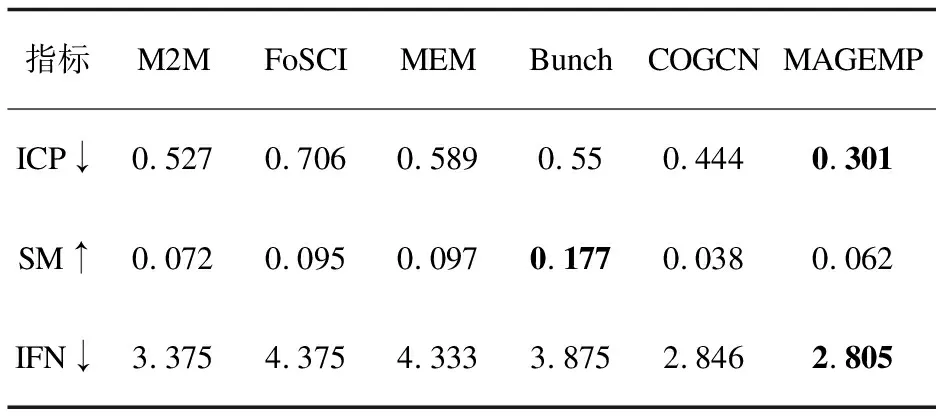
表2 acmeair数据集上的结果

表3 jpetstore数据集上的结果
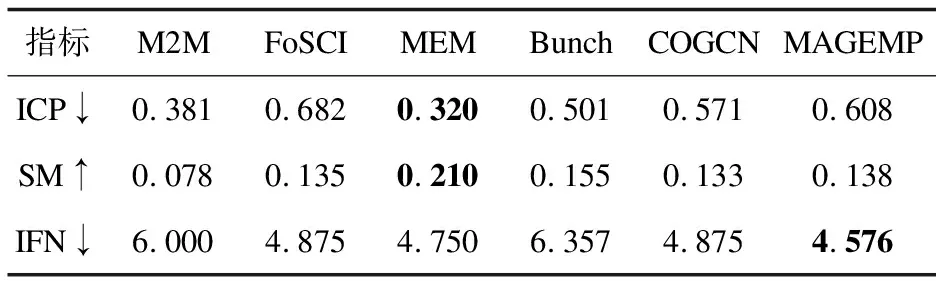
表4 plants数据集上的结果
与同类方法COGCN相比,在daytrader数据集上,ICP提升了37.6%,SM提升了41.86%。在acmeair数据集上,ICP提升了32.21%,SM提升了63.16%,IFN提升了1.44%。在jpetstore数据集上,ICP提升了54.81%,SM提升了27.47%,IFN提升了15.2%。在plant数据集上,ICP提升了6.48%。MAGEMP的多通道信息的充分利用和有效融合显著提升了微服务分解在功能性和模块性上的性能。
与另外四种非深度学习模型比较,MAGEMP在daytrader数据集的ICP指标,在acmeair数据集上的ICP指标、IFN指标,在jpetstore数据集上的ICP指标,在plants数据集上的IFN指标都取得了最好的实验效果,而在一些其他的指标上,例如acmeair数据集上的IFN和plants上的ICP效果并不理想。这很大一部分原因是MAGEMP中类调用图的节点属性过于简单,从而无法挖掘更深层次的信息。
从整体实验效果上来看,MAGEMP具有一定的优势,但也有可提升的空间,并且进一步验证了图神经网络在微服务分解问题上的可行性。
4.5 消融分析
为了进一步评估MAGEMP模型中不同模块的贡献,对MAGEMP进行了消融实验,考虑了MAGEMP的几种变体:
(1)MAGEMP(mean):无注意力融合机制的MAGEMP。
(2)MAGEMP(m1):只使用通道1的MAGEMP。
(3)MAGEMP(m2):只使用通道2的MAGEMP。
(4)MAGEMP(m3):只是用通道3的MAGEMP。
MAGEMP在不同数据集上消融实验结果如表5~表8所示。从实验结果中可以看到,在所有数据集和指标上,带有注意力融合机制的MAGEMP模型性能更好,表明MAGEMP中的注意力机制可以利用多通道的嵌入特征表示的不同贡献,进一步提高聚类(微服务分解)的性能。从表中还可以看出,MAGEMP的性能优于单通道图卷积模型,充分验证了多通道图卷积网络模型可以利用多种信息更好地达到微服务分解的目的。
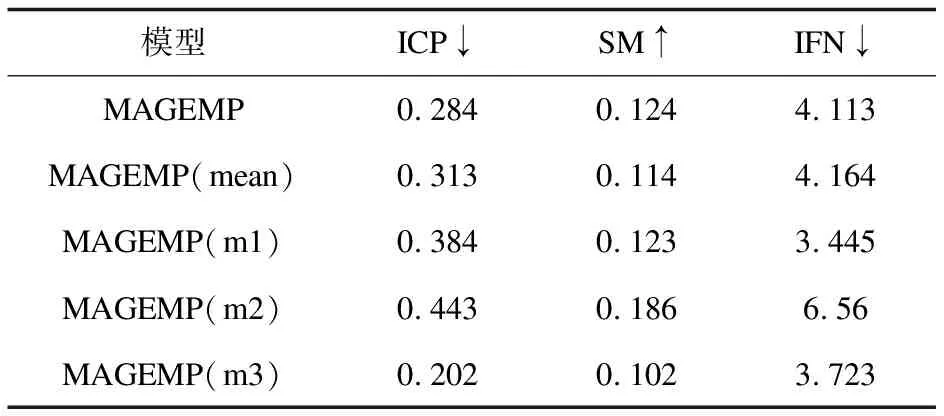
表5 daytrader数据集上消融分析

表6 acmeair数据集上消融分析
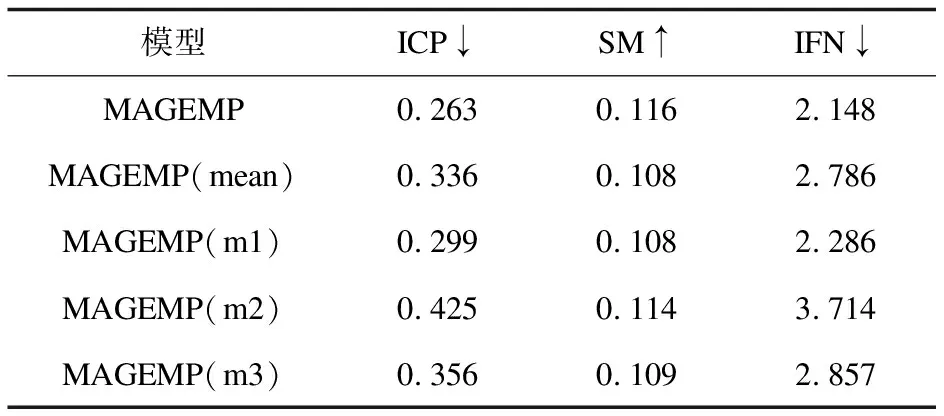
表7 jpetstore数据集上消融分析

表8 plants数据集上消融分析
4.6 注意力系数分析
注意力融合机制是MAGEMP模型的一个关键组成部分,它可以衡量和量化不同通道的重要性和不同通道中不同节点的重要性。图2可视化了在acmeair数据集上三个通道中每个图节点的注意力系数。从图2可以看出,三个通道具有不同的重要性,在不同数据集上,通道1和通道3的权值比通道2的权值高。实验结果表明MAGEMP可以很好地利用不同通道的不同特征进行聚类。

图2 acmeair数据集上三种模态的图节点注意力系数热图
5 结束语
受多通道信息处理模型启发,针对Java单体应用程序微服务分解问题,对面向对象程序设计中的类实体关系特征表示进行建模,提出了一种基于多通道注意力深度图卷积网络聚类的微服务分解方法MAGEMP。针对Java单体应用程序的特点,类和类之间的关系除了调用关系外,还可以充分利用源代码中的主题建模等信息,因此将会继续研究更加有效的多通道信息,进一步提升微服务分解模型的泛化能力。
深度学习方法具有很好的扩展性,但是在运行时间和效率上,与其他类方法相比,仍然有很大的提升空间,如何改进深度图卷积网络的性能,获得特征表示和运行时的高效,也是一个很好的研究方向。另外,如何在微服务分解领域拓展深度卷积网络的研究方法,提出新型的图卷积神经网络模型,也是值得深入研究的方向。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
数学物理学报(2017年5期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
