
基于时间和空间注意力机制的视频异常检测
2023-08-15 02:02付孟丹宣士斌李培杰
计算机技术与发展 2023年8期
付孟丹,宣士斌,,王 婷,李培杰
(1.广西民族大学 电子信息学院,广西 南宁 530006;2.广西民族大学 人工智能学院,广西 南宁 530006)
0 引 言
随着网络技术的快速发展,社会进入了崭新的数字化时代。面对生活中的海量信息,传统的监控系统只负责存储记录视频信息,便于以后调查,需要大量的人工,耗时耗力,而监控视频中的异常事件以及人体异常行为的检测能够有效降低检测成本,所以视频异常检测技术成为人工智能应用领域的一个重要研究方向。
视频异常检测是指通过算法检测视频中不符合预期的行为,比如人行道上的车辆等异常事件[1]。基于视频的异常检测存在诸多难点:视频帧内具有很强的空间连续性和时间连续性;异常事件具有不可预测性、多样性等特点;也具有很强的场景依赖性,不同的场景对异常行为的定义不同,部分场景下的异常事件在其他的场景下可能会变成正常事件。因此,往往通过半监督或者无监督的方法进行异常检测,先对仅包含正常样本的训练集进行训练,利用训练好的模型,再对测试集进行检测。
ViT(vision transformer)成功将自然语言处理的Transformer用于计算机视觉。该方法将输入的图片分成多个块(patch),每个块投影成固定长度的向量,获取这些块的线性嵌入序列后,输入到Transformer编码器中进行图像分类的训练。
该文引入基于时间和空间注意力机制[2]的异常检测学习方法。相较于处理图片数据的ViT,该方法增加了时间和空间注意力机制,先从各个视频帧图片中分离出图像块,再将这些块的线性嵌入序列输入到Transformer编码器。Transformer自注意力需要计算所有标记对(token)的相似性,由于视频中存在大量的图像块,为了降低相似性计算的复杂度,在时空体积上引入了可扩展的自注意力机制,同时学习视频帧上图像块序列的时空特征。尤其在视频数据集的实际检测过程中,异常现象总是出现在某一时间段内,引入时间注意力能更好地关注异常时间片段,从而提高检测效率。视频中的异常区域作为前景,正常区域作为背景,在检测过程中容易出现背景冲淡异常区域的现象,因此模型应该更加侧重于学习前景区域的特征,抑制无关背景的特征,提取整个图片的兴趣点,更好地关注局部区域,则引入空间注意力,提高检测效率。实验结果表明,在UCSD Ped2[3]、The CUHK Avenue[4]数据集上,该方法取得了较好的效果。
贡献如下:
(1)针对MNAD(learning Memory-guided Normality for Anomaly Detection)[5]中的记忆模块容量受到限制,特征信息易丢失的问题,以及记忆模块与Transformer关注的信息相冲突,在原模型中引入时空注意力模块代替记忆模块,学习高层特征信息和图像局部信息。
(2)考虑到异常检测任务精度取决于时间和空间两个因素,在原模型中加入时间注意力和空间注意力,关注时间和空间上下文信息。关注异常时间片段,同时集中关注局部区域,从而提高检测效率。
1 相关基础
(1)传统的异常检测方法。
传统异常检测使用手工提取特征空间,然后用机器学习方法检测异常。常用的特征提取方法有:方向直方图、光流直方图等,将提取的视频事件特征表示作为输入,利用经典的机器学习方法进行建模。比如,文献[6]将表示异常事件的特征向量输入单类别支持向量机(support vector machine,SVM)建立异常检测模型。
(2)基于深度学习的异常检测方法。
深度学习网络在图像和视频的复杂数据中自动学习特征,并使用端到端的神经网络模型检测异常。主要分为两种:①基于重构的异常检测方法,如递归神经网络[7];②基于预测的方法。
在异常检测过程中,传统方法并不能很好地处理高维数据的复杂分布问题。为了提升异常检测效率,目前很多方法都结合CNN,并提出重构模型进行训练。由于卷积神经网络具有强大的表征能力,容易造成数据的误判。针对捕捉序列数据的长期依赖关系,利用长短期记忆以及本地存储单元的方法,然而,记忆性能有限。针对这些问题,Gong等人[8]利用增强自动编码器(MemAE)进行异常检测,使用CNN功能。尽管这些方法已经取得了好的效果,但是没有考虑正常样本的多样性。而MNAD[5]使用连续的内存表示和键值对读/写存储器,提出特征紧凑性明确区分记忆项目,充分利用正常样本的多样性,同时削弱神经网络的表示能力,达到区分正常帧和异常帧的目的。该方法存在容量受限,信息丢失问题。
(3)Transformer。
Transformer结构[9]在捕捉单词之间的长期依赖关系以及训练可伸缩性方面表现很出色,因此也引入到图像分类、目标检测等领域。文献[10]将Transformer运用到图像分类中,利用监督方法对模型进行图像分类训练。
记忆模块更多关注的是全局信息,而Transformer关注的是视频帧的局部和全局的时序信息,两者作用产生冲突,并不能很好地处理局部特征信息。因此,引入基于Transformer的时间和空间注意力机制[2]取代记忆模块部分,将注意力集中于各视频帧主要的特征部分,各视频帧之间的联系更加紧密,有助于更好地预测,避免特征信息丢失。并且能够很好地结合空间和时间上下文信息,应用于视频,将注意力机制从图像空间扩展到时空三维空间。
2 文中方法
模型主要由两部分组成:编码器、解码器。图1(a)展示了预测任务的模型框架,图1(b)展示了Time-Space Transformer block(Temporal and Spatial attention mechanism)模块,从数据集中取出连续的五帧视频帧,输入前四帧视频帧到编码器,每帧图像大小为H×W×C,由CNN提取特征,输出H×W×C的特征图。为了得到图像中的关键区域,将特征图分解为N个不重叠的特征块(patch),每个小块的大小为P×P,将每个块投影成固定长度的向量,然后将这些块的线性嵌入序列输入到Time-Space Transformer block的编码器中,对数据序列进行归一化处理以及时间和空间注意力机制的加权处理,能够提取全局的时间和空间上的关键信息,多层感知机(MLP)将输出转换为与输入同样大小的维度,然后输入到解码器进行重构,计算第五帧和输出预测下一帧之间的误差。对于重构任务,输入单个视频帧到CNN中提取特征,得到特征图后,经过注意力模块提取全局的关键信息,然后读取到解码器中重构视频帧,计算重构视频帧与输入视频帧之间的误差。图1展示了模型框架,重构输入帧和预测下一帧,以便进行无监督的异常检测。然后连续输入四个视频帧来预测第五个视频帧。由于可以利用之前的预测对未来框架进行重构,因此使用几乎相同的网络结构,下文将描述重构任务细节。

图1 基于时间和空间注意力机制的异常检测
2.1 网络架构
2.1.1 编码器和解码器
提出的模型利用U-Net[11]架构(广泛用于重构[12]和未来帧预测[13])从输入视频帧中提取特征元素,并获取重构帧。由于ReLU截断了负值,限制不同的特征表示,因此编码器前半部分的CNN层应用该架构,并删除最后一批归一化[14]和ReLU层[15],添加了L2正则化层,使特征具有共同的比例。另外,U-Net架构中的跳跃连接无法从视频帧中提取有用的特征。因此,移除重构任务的跳跃连接,同时保留输入视频帧来预测未来的帧。
2.1.2 时间和空间注意力

每个Space-Time Transformer block中的计算过程主要由Attention和MLP两部分组成。其主要流程如图2所示。

图2 时间和空间注意力机制
2.1.3 Attention部分
原模型编码器提取特征后输出是批次、帧数*通道数(channel)、宽、高,为了更好地关注局部和全局信息,文中方法利用MLP来处理维度之间变换,将帧数和通道数分开处理,方便注意力机制层对视频帧的操作,分别从时间和空间关联角度对视频帧提取特征信息。
视频帧的输入:时间和空间注意力模块[3]从原始视频中采样,模型输入为X∈RH×W×3×F,表示大小H×W的F帧RGB图像。
分解成块:将每一帧分解为N个大小为P×P的非重叠块的序列,即N=HW/P2。然后将这些块拉平为向量x(p,t)∈R3P2,其中p=1,2,…,N表示空间位置,t=1,2,…,F表示坐标系上的索引。
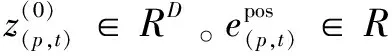

(1)

(2)

(3)
(4)

(5)
(6)
softmax操作结束后,把得到的注意力值a和value值相乘、求和,按照公式(7)计算得到当前的块与相邻空间和时间上块的关联信息。
最后,时间和空间注意力模块中的每个编码器中都对应多个多头注意力的加权和,并经由残差神经网络输出。其中,把单个注意力结构的s连接起来,然后乘上权重Wo,与第l-1个编码器输出的z(l-1)相加,如公式(8)。
(8)
MLP部分按公式(9)计算,通过感知机嵌套LN计算得到的值与计算注意力得到的z'(l)值相加,得到输出值z(l)
(9)
对于z(l),所提方法剔除类别值,转置后,利用MLP转换维度,然后输入到解码器中进行重构。


(10)
(11)
εt分数高于阈值γ时,将其视为异常样本,并且该权重函数能够关注重构误差较大的区域。
2.2 损失函数
(12)
2.3 异常分值
异常分值[16]表示量化视频帧的正常或异常程度的一种度量。在检测视频帧的异常分值时,公式(13)重新计算输入视频与其对应重构帧之间的峰值信噪比(Peak Signal to Noise Ratio,PSNR),N表示视频帧的像素数,视频帧出现异常情况时,PSNR值会很低,利用最小-最大均方差将误差归一化到[0,1]范围内。最终,视频帧的异常分值st可按公式(15)计算。其中公式(14)中g(·)为整个视频帧的最小最大归一化公式:
(13)
(14)
(15)
3 实 验
3.1 实验数据集
在两个基准数据集USCD Ped2和The CUHK Avenue上进行评估。USCD Ped2行人数据集[3]包含ped1和ped2,分别为16个训练视频以及12个测试视频,每帧像素为240×360。该文使用ped2数据集,其中包含12个不规则事件,包括骑自行车、滑板等。The CUHK Avenue数据集[4]包含由16个训练视频和21个测试视频组成的47个异常事件,比如错误行走方向、跑步等,像素大小为360×640。
3.2 实验环境
将每个视频帧的大小调整为256×256,将其标准化为[-1,1]的范围。设定特征图的高度H和宽度W,以及特征通道数C,分别为32、32、512。使用Adam Optimize[16],β1=0.9和β2=0.999。在UCSD Ped2[3]、The CUHK Avenue[4]上epoch分别设置为40、60,batch_size设置为1,设置重构任务的初始学习率分别为2e-5和2e-4。重构任务和预测任务,分别设置第一次步长为1和5,结合余弦退火法[17],设置阈值分别是γ=0.015和γ=0.1。所有模型都使用Quadro RTX 8000进行端到端训练。
3.3 评价指标
在视频异常检测领域中,为了进行定量比较,实验中通常计算相应受试者工作的特征曲线ROC(receiver operating characteristic)下的面积AUC(area under the corresponding ROC curve)和等错误率EER(equal error rate)来评估性能。
曲线下面积(area under curve,AUC):用于测量ROC曲线下的面积。取值在0~1,值越大,分类性能越好。ROC曲线横坐标为假阳率(FPR),纵坐标为真阳率(TPR)。其中,P、N代表实际值为正例和反例,TP:预测为正例实际为正例的样本个数,FP:预测为正例实际为反例的样本个数,FN:预测为反例实际为正例的样本个数,TN:预测为反例实际为反例的样本个数,如公式(16)和公式(17):
(16)
(17)
AUC计算如公式(18):
(18)
其中,(xi,yi)为ROC曲线坐标,xi代表FPR,yi代表TPR。
等错误率:FPR与假阴性率(false negative rate,FNR)相等时的错误率。当分类器中真阳率和假阳率满足FPR=1-TPR时,被错分的视频帧数量占所有视频数量的比例,其数值越小表明方法的性能越好。
3.4 结果分析
模型在UCSD Ped2和The CUHK Avenue上与异常检测的最新技术进行了比较。“—”中展示了其他检测方法的结果,“Recon”和“Pred”表示重构和预测任务,表1展示了实验结果对比。

表1 视频异常检测算法AUC对比 %
(1)不同方法对比。
在UCSD Ped2[3]和The CUHK Avenue[4](Avenue)数据集上,文中的模型任务达到了最好的效果,平均AUC分别是95.4%和85.8%,展示了利用基于时间和空间上的注意力机制进行异常检测的方法的有效性。在The CUHK Avenue数据集上,与其他重构方法相比,文中模型的重构能力具有更强的竞争性。
UCSD Ped2数据集包括的异常事件主要有汽车、骑自行车等情景。提出模型的预测能力在该数据集上表现得尤为突出,但是在重构任务中表现欠佳,主要原因是由于注意力机制具有单向性或对某些环境不敏感。
文献[25]中提出了加入注意力的模型,对特征图重新分配权重,达到抑制无关背景区域,突出前景运动的目标,没有有限的时间轴相关性的局限性。该文提出的时间和空间注意力模块能很好地关注异常时间段中异常运动目标,提升模型的检测效果。在The CUHK Avenue数据集中,文中检测模型的视频异常检测效果更好,AUC精度会高出0.5%,由于视频中环境的差异性和模型适用性,在UCSD Ped2数据集中,文献[25]提出的模型检测精度好一些。
文献[7]提出了一种时间相干稀疏编码(TSC)强制使用相似的重建系数对相似的相邻帧数进行编码,用堆叠递归神经网络映射TSC优化了参数并加速了异常预测,适用于一段时间内的特征处理。该文结合Transformer的思想,在异常检测过程中增加时间和空间注意力的方法,解决了时间轴相关性的局限性,适用于处理中长视频,对中长时间的时空特点进行建模。在两个数据集的实验表明,提出的方法能够提高异常判别性和样本检测效率。
图3和图4是关于数据集UCSD Ped2评估指标(曲线下面积ROC、等错误率)的对比。
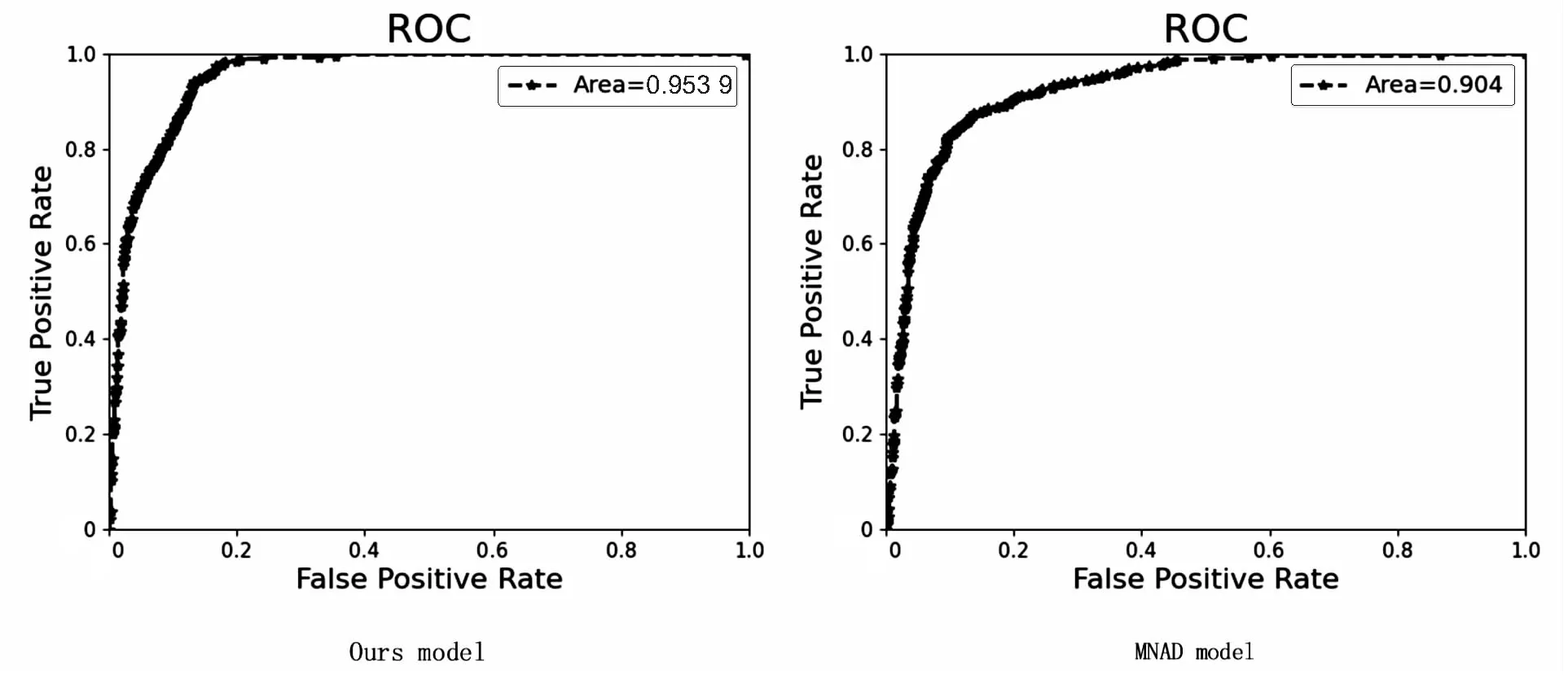
图3 绘制ROC曲线
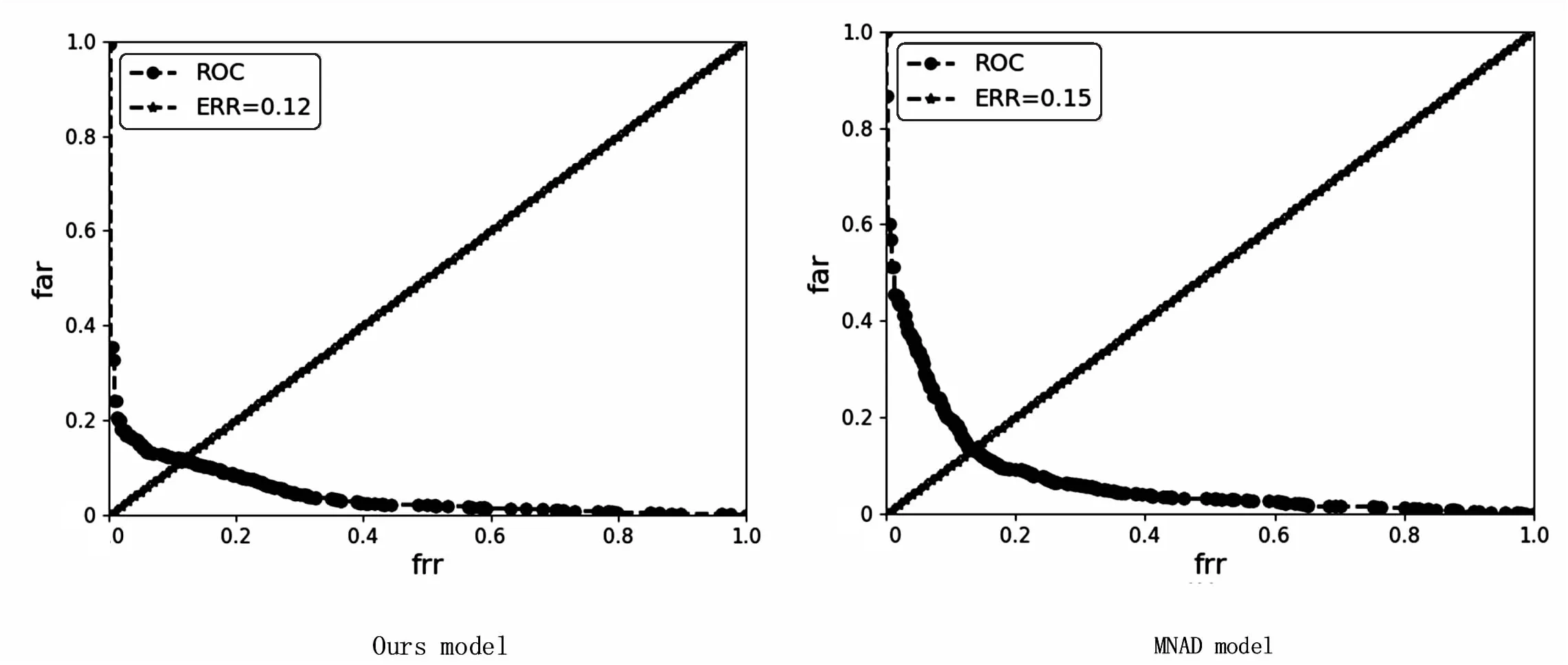
图4 绘制等错误率的曲线
如图3所示,关于曲线下面积的对比,左图为文中方法,右图为文献[5]的方法,横坐标代表FPR,纵坐标代表TPR。经过实验对比,文中方法的检测效果会更好。如图4所示,关于等错误率的对比,左图为文中方法,右图为文献[5]的方法,纵轴代表误识率,横轴代表拒识率。EER是ROC曲线与ROC空间中对角线的交点。由实验对比可知,文中方法的错误率值更小,表示方法的性能好,检测效果更好。
(2)可视化展示。
针对文献[5]中记忆模块容量受限,相关特征信息丢失,造成误判,在检测中发现很多异常数据样本的异常得分很低等现象,提出带有时间和空间注意力机制的异常行为识别模型。检测结果可视化如图5所示。

图5 关于UCSD Ped2数据集和The CUHK Avenue数据集视频序列的下一帧预测的实验结果(左面为输入帧,右面标记出了不正常的区域,其余的为正常区域)
图5清晰展示了UCSD Ped2数据集中04和06视频序列,The CUHK Avenue数据集中03和11视频序列关于模型预测任务的实验结果,结果展示了视频序列里面的一些异常现象,例如人行道中的汽车、自行车等异常情况。在MNAD检测方法会出现连续帧中的异常检出率低,并且有的视频帧异常分数得分很低的情况,而文中方法能够很好地将连续帧中的异常区域突显出来,在The CUHK Avenue数据集03视频序列中的间隔帧中的异常区域也预测的很好,说明了文中方法的有效性,有效缓解因容量受限,信息丢失造成的误判、漏检等问题。
为了进行可视化,利用文献[16]的像素异常得分,当异常得分较大的区域大于帧内平均值时就将其标记。
(3)消融实验。
图6给出了所提模型在训练时不同的注意力关注特征信息的不同模式。在表2中,展示了所提模型在UCSD Ped2数据库上重构和预测任务模型的消融实验AUC性能变化。

表2 实验结果AUC %

图6 不同方式计算每个块注意力值的效果
图6展示了基于空间的注意力以及基于时间和空间注意力的模式。空间注意力:只取视频里同一帧内的图像块进行注意力机制。分散时空注意力:先对不同帧中相同位置的块进行注意力机制,再对同一帧中所有图像块进行注意力机制。说明前者只能关注一帧图片上的局部信息,忽视了连续视频帧的相关性。后者加入时间相关性,能够更好的关注视频帧的时间上下文信息。
如表2所示,在记忆模块的基础上加入了时间和空间的注意力机制,结果使用PSNR计算异常分数94.8%,而所提模型的效果在这个基础上提高0.6%。这是由于Transformer更多的是关注视频帧图像中局部的特征信息,而记忆模块更多是关注视频里面的全局信息,导致两者共同作用时发生冲突。(1)如果只有空间上下文提取信息,在表2中第一行可以看到异常检测效果降低了很多,说明了时间注意力的重要性。(2)第二行则是没有记忆模块部分,加入时间和空间的注意力机制,结果显示,该文提出的方案会比上面的方案更有效。在使用时,会有时间和空间注意力顺序问题,实验发现,只有时间先的方式,效果要略好一些。
基于文中模型框架,将只加入空间注意力机制和加入基于时间和空间的注意力机制相比,基于时间和空间的注意力机制效果更好,它提供了0.6%的AUC增益。从以上实验得出,基于时间和空间注意力机制相辅相成,其中异常评分St,使用PSNR量化异常的程度发挥到更好。
4 结束语
考虑到基于记忆的异常检测模型中的记忆模块容量有限,在加入Transformer时会产生冲突的实际情况,提出基于时间和空间的自注意力机制来替换记忆模块。在公共数据集上展示了该方法的有效性,实验表明,该模型优于最新技术。该模型具有以下优点:(1)基于Transformer的理念,相对简单且容易理解;(2)通过提取空间上下文信息来建立视频帧中的目标之间的联系实现;(3)可以应用于长期视频建模。但是模型的重构任务在适用环境上受到限制。因此,该模型并不能同时满足所有的场景,有待进一步完善。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
摄影世界(2022年1期)2022-01-21
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
知识经济·中国直销(2018年12期)2018-12-29
数学小灵通·3-4年级(2017年9期)2017-10-13
商周刊(2017年6期)2017-08-22
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
山东大学法律评论(2016年0期)2016-08-16
