
基于主题特征的问答文本摘要自动生成研究
2023-08-14 16:02刘梦豪熊回香王妞妞贺宇航
现代情报 2023年8期
刘梦豪 熊回香 王妞妞 贺宇航











摘 要: [目的/ 意义] 为帮助用户在拥有海量文本信息的问答社区高效率、高质量定位到符合自身需求的信息。[方法/ 过程] 本文提出基于主题特征的问答文本摘要生成模型, 该模型融合Word2Vec 和SLDA 算法多层次表达问答文本语义特征, 而后基于图排序的思想, 结合MRR 冗余控制算法与文本句特征标签, 调整句子权重,高效筛选出贴合问题标签的摘要内容。[结果/ 结论] 本文对知乎问答社区多个问题下的问答文本数据进行验证,结果证明该模型具有较高的可行性和有效性。但本文选取了500 份回答文本数据进行实证, 未来可进一步扩大数据量开展更为充分的验证。
关键词: 摘要自动生成; 知乎; 问答社区; 监督主题模型; 图排序; Word2Vec
DOI:10.3969 / j.issn.1008-0821.2023.08.011
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 08-0114-11
在线问答社区是依托Web2 0 发展起来的知识共享平台, 已经成为越来越多用户交流意见、分享知识的重要载体, 用户在各抒己见的同时, 也创造了海量的问答文本信息, 这些信息因其具备知识导向性和专业性而彰显出极高的价值, 蕴含着较多的问答文本。与此同时, 这些文本还具有数据量大、内容碎片化、结构杂乱化、特征稀疏性强、噪声大、规范性差等特点, 为用户精准高效获取信息带来了巨大的障碍, 自动文摘技术便是能帮助用户从海量的文本信息中找到所需关键信息的重要技术之一, 但自然语言的复杂性、模糊性、歧义性等特征使得计算机难以精准地掌握自然语言的实际语义,加大了自动文摘生成难度。因此, 为了从大量的问答文本中自动抽取出主要的语义信息, 提升长文本摘要的质量, 解决现有自动摘要抽取中信息覆盖率低等问题, 本文尝试从主题特征入手, 结合监督主题模型及Word2Vec 算法从语义角度对问答文本摘要进行抽取, 并利用CoRank 与冗余控制方法调整句子内容及顺序, 进一步提高问答文本摘要水平,以期丰富基于主题模型的自动文摘研究方法, 并拓宽自动文摘应用研究领域, 从而提升信息获取效率, 增强信息服务质量。
1 相关研究
自动文摘需要解决语义分析和句子排序问题,近年来, 主题模型(Topic Model)作为一种含有隐含变量的三层贝叶斯混合概率生成模型, 通常被用于文本语义分析, 该模型以非监督学习的方式自动提取文档集中隐含语义主题, 有助于在文本摘要生成时进行主题语义表示[1] 。国内外学者基于主题模型开展了自动文摘的多项探索研究, 例如, Fang H等[2] 通过引入主题因子, 提出以TAOS 模型来提取各种特征组; Bairi R B 等[3] 为了能更便捷地融合LDA、分类和聚类算法来抽取摘要, 提出了一种依赖于多个子模块函数和层次主题的方法; Yang G[4]基于n-gram 模型, 将语词上下文与LDA 模型相融合, 计算得到不同上下文层次间文本—主题分布以及相同层次间的语词关联性; 汤丹[5] 提出了基于LDA 主题模型的多特征中文自动摘要方法, 从多个角度判断句子的重要性, 并利用冗余控制对句子进行筛选, 从而实现通用的中文自动文摘系统。这类研究多为基于传统无监督主题模型的算法, 难以保证自动文摘的精确度, 随着机器学习算法的不断推广和深化, 有监督的学习方法取得广泛应用。LiJ 等[6] 在提取特征时引入了查询相关度的概念, 并利用贝叶斯概率模型进行监督训练; Valizadeh M等[7] 融合Word2Vec 等多个机器学习算法模型来改进算法, 避免了抽取特征的单一性, 基于抽取出的多样特征对得到的候选摘要进行语法分析; Blei MD 等[8] 根据有监督的机器学习算法提出了有监督的主题模型SLDA(Supervised Latent Dirichlet Alloca⁃tion), 在指定标签的监督下提升了主题发现的准确性, 一定程度上避免了LDA 为文本强制分配主题的弊端; 唐晓波等[9] 提出了一种混合机器学习模型, 在抽取摘要的过程中同时考虑了句子的形式特征和深层语义, 并在多主题的中文长文本上验证了该模型的有效性; 石磊等[10] 基于序列到序列模型提升了文本摘要的生成效率; 肖元君等[11] 在Gensim 的基础上, 融合Word2Vec 和TextRank 算法生成词向量, 并生成有权无向图, 对句子进行打分排序后生成文本摘要。
为了解决句子排序问题, Erkan G 等[12] 基于LexRank 算法构建出图模型, 在该模型中, 设定句子或语词为图的节点, 以句子或语词间的相似度来表示节点之间的边, 最终得到句子的重要度排序,进而得到文本摘要; 在此基础上, Wei F 等[13] 引入文档间的相关性, 尝试将图分成句子层和文档层, 而不单单利用句子间的相似度来构造图, 取得了较好的效果; Silva S 等[14] 在计算句间相似度的基础上, 利用语词的TF-IDF 值以及查询语词的相关性来进一步计算句子的分数, 然后以分数最高的k 个句子为中心进行聚类, 根据聚类结果构造图模型, 进而生成摘要。赵美玲等[15] 针对多文本, 在对不同主题进行划分的基础上, 融合了改进Kmeans聚类和图模型方法, 实现了多文本自动文摘; 由于普通的图模型只能从相邻节点出发简单描述句子之間的关系, 难以更全面地表示句子间存在的其他复杂关系。学者Wang W 等[16] 基于DB⁃SCAN 方法构造超图, 再计算句子相似度及句子的查询权重, 从而计算句子得分; Zheng H T 等[17] 通过引入文档中的概念, 在TextRank 的基础上增加了概念层, 从而得到了两层超图模型, 在该模型中, 利用句子已有的权重和含有的概念数来改进句子得分的计算方法; 作为一种基于图排序的自动摘要算法, CoRank 算法以TextRank 算法为基础, 融合语词与句子之间的关系, 更适合用于在自动摘要中对句子进行打分排序。此外, 陶兴等[18] 提出,改进的W2V-MMR 自动摘要生成算法, 利用基于深度学习的Word2Vec 词向量生成模型, 优化摘要句信息质量, 引入最大边界相关(MMR) 的思想,对学术问答社区内的用户生成问答文本进行自动摘要; 为有效提高社会化问答社区的问题推荐质量,陈晨等[19] 提出基于多源混合标签的方法。梳理上述研究可知, 学者Fang H 等[2] 、Bairi R B 等[3] 、Yang G[4] 和汤丹[5] 的研究多基于传统的无监督主题模型, 缺点是并不能保证文档的精确度, 甚至可能引起维数灾难。因此, 为了改进算法, Li J 等[6]和Valizadeh M 等[7] 的模型避免了抽取特征的单一性, 提升了主题发现的准确性, 一定程度上避免了LDA 为文本强制分配主题的弊端。此外, Erkan G等[12] 、Wei F 等[13] 、Silva S 等[14] 和陶兴等[18] 提出的模型可以有效地解决句子的重要度排序问题,尤其是CoRank 算法可以有效地提高社会化问答社区的问题推荐质量。
在目前知识获取及知识分享需求日渐扩张的趋势下, 以知乎为代表的问答平台用户量在不断增长, 对问答平台中的长文本进行摘要抽取显得十分必要, 如何有机结合有监督主题模型、句子排序算法及冗余控制方法实现不同的场景的文摘生成, 更好地提取文档主题, 便成为学术界重点关注的问题之一。因此, 为解决自动文摘语义分析问题, 本文在综合学术界现有研究成果的基础上, 充分分析问答文本特征, 通过有监督主题模型SLDA 算法挖掘文本主题, 并结合Word2Vec 对文本进行深层语义表示; 利用图模型CoRank 对摘要进行抽取后, 通过MMR 算法进行摘要句冗余控制, 从而有效解决摘要句的排序问题, 以期提高文摘质量, 丰富自动文摘现有研究成果, 提高信息服务水平。
2 基于主题特征的问答文本摘要自动生成模型构建
本文基于主题模型提出问答文本摘要自动生成体系架构, 主要包括数据收集及预处理、基于主题特征的语义向量表示、基于CoRank 句子排序、基于冗余控制的文本摘要生成4 个部分, 其模型框架如图1 所示。
2 1 基于主题特征的语义向量表示
为了保证得到的摘要句符合用户所需, 本研究首先融合SLDA 和Word2Vec 模型, 从全局角度和局部角度挖掘回答文本中的语义信息, 其基本框架如图2[20] 所示。
在图2 中, D ={x1,x2,…,xm }表示由m 条文本组成的文本集, 其中, xj(1≤j≤m)表示一条完整的文本数据, 对文本集D 分词后, 可获得n 个语词的集合W ={w1,w2,…,wn }, 其中, wi(1≤i≤n)表示单个语词。利用SLDA 主题模型训练得出主题—语词分布矩阵C, 从而得到语词wi (1≤i≤n)的全局语义嵌入词向量wzi(1≤i≤n)。而后根据Word2Vec 模型得到语词wi 的局部语义嵌入词向量wci。最后, 将每个语词wi 的全局语义嵌入词向量wzi与局部语义嵌入词向量wci拼接后, 即可得到语词wi 的综合语义嵌入词向量wsi, 详细阐述如下。
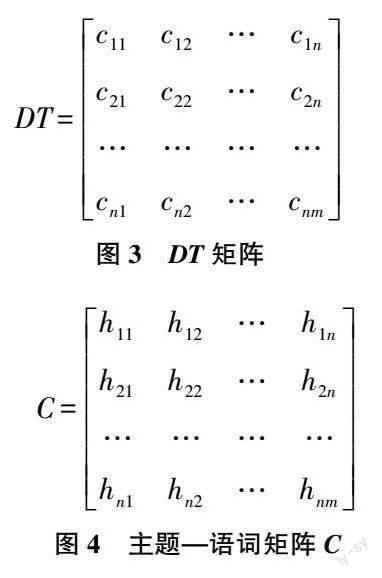
1) 基于SLDA 的语词语义表示。SLDA 模型作为有监督的主题模型, 在训练模型前需要将训练文本集中的所有文本进行初始分类, 本部分通过人工判别的方式获取问题所属领域进行初始分类, 而后获取训练文档集中所有语词集合, 统计得到训练文本集中每条文本的词频矩阵DT, DT 中的每个元素cij(1≤i≤n, 1≤j≤m)表示语词wi 在文本xj 中出现的频次。
将语词集合W、文本集合D 与词频矩阵DT 作为初始数据以训练SLDA 模型。训练可得主题—语词分布矩阵C, 该矩阵中的元素hik表示第i 个单词wi 属于第k 个主题的概率, 而后, 将主题—语词分布矩阵C 转置后得到语词—主题分布矩阵CT ,并用(wi ,hk )(1≤i≤n, 1≤k≤K)表示语词wi 和分配给它的主题向量Zk =(hi1,hi2,…,hiK ), 由于主题是从文本集中挖掘出的全局语义信息, 因此, 可以将语词的主题向量zk 表示为每个语词wi 的全局语义嵌入词向量wzi。
2) 基于Word2Vec 的语词语义表示。Word2Vec是用于训练分布式词嵌入表示的神经网络模型[21] ,包括CBOW 和Skip-Gram 两种模型。在Skip-Gram中, 每个词均受到周围词的影响, 每个词作为中心词时都需要进行多次的预测、调整, 这种多次调整会使得词向量更加准确, 因此, 本文将采用Skip-Gram 模型来构建框架。此外, Word2Vec 模型认为位置相近的语词语义相近, 因此可以通过Word2Vec对语词的上下文语义进行表征, 设定其语义向量维度为H, 得到语词的局部语义嵌入词向量wci(1≤i≤n)。
3) 综合语义表示。本文在1) 中基于监督主题模型SLDA 得到词wi(1≤i≤n)的全局语义嵌入词向量wzi(1≤i≤n), 并于2) 中基于Word2Vec 模型得到局部语义嵌入词向量wci(1≤i≤n), 本节将对向量wzi(1≤i≤n)和wci(1≤i≤n)进行拼接, 生成语词的综合语义词向量wsi= wziwci(1≤i≤n)。
如图5 所示, 为保证语词的全局语义嵌入词向量和局部语义嵌入词向量在融合后不会因综合语义融合过程产生影响, 本文采用向量拼接的方式将两者进行融合, 以保留最原始的向量数据, 由于wzi(1≤i≤n)是K 维向量, wci(1≤i≤n)是H 维向量, 最后可以得到K+H 维的综合嵌入词向量。
2 2 基于CoRank 的句子排序
2 2 1 特征词分析
以知乎为代表的问答社区文本由两部分构成,其一为提问者提出的问题文本, 另一部分则是回答者的回答文本。通常, 提问者提出的问题需要遵循社区的规范, 如必须是问句等, 同时提问者也可以针对问题做细节描述。问答文本的问题内容往往因提问者的表达能力及表达方式而表现出极大的主观性, 因此知乎会自动给提问者推荐相关的问题标签, 用户也可以自定义问题标签, 这些标签往往可以作为问题的特征詞, 可用于研究者对回答者的文本进行特征分析。
回答者的文本往往具有长短不一、涉及领域较多、掺杂回答者的主观因素等特点。统计发现, 有些较长的回答者文本属于自媒体文本。基于此, 将问答平台回答文本分为两大类: 一类是对客观性事实的解读, 其客观性较强; 另一类是回答者自我感情的表达, 其主观性较强, 表达的信息和意义往往比较模糊。但无论回答文本属于哪一类, 其宗旨都会与问题的标签相关联, 因此问题标签也可以作为回答者文本的特征词, 从而可以根据特征词对回答者文本进行语义特征表示。
2 2 2 CoRank 句子排序
在自动摘要研究中, 越来越多的研究者开始应用计算简单、性能稳定的图排序算法, CoRank 算法就是其中的一种[22] 。CoRank 算法使用杰卡德相似系数(Jaccard Similarity Coefficient)来计算顶点间的关系, 通过统计文本层的共同词语数量来计算杰卡德相似系数, 这种方法能正确识别具有相同词语的句间关系, 但是并未考虑到句间语义层面的关系, 会降低某些句子之间的权值, 本文利用上文得到的句子语义向量来确定不同顶点间是否存在关系。在2 1 节中, 本文利用SLDA 主题模型和Word2Vec 模型得到语词的综合语义词向量wsi(1≤i≤n), 将每个句子中语词的综合语义词向量取均值, 即可得到问答文本的句子语义向量。假设文本中句子α 的语义向量为sα , 句子β 的向量语义为sβ , 则可以根据杰卡德相似系数计算方法得到句子α 和句子β 之间边的关系即权重qαβ , 其计算公式如式(1):
在迭代计算过程中, 较小的权值往往不会增大到影响节点间的关系, 但是会增加计算量, 实验中常采用为θ 设置阈值的方法来消除这种缺陷, 一般可以取经验值θ =0 1, qαβ≥θ。对于包含M 个句子的文本, 可按照句间相似度qαβ构造出M×M 的对称邻接矩阵以表示句间关系, 这种邻接矩阵反映出句子的空间结构关系, 可用于摘要句排序。
2 2 3 句子特征表示
为了分析问答文本的句子特征, 本文选取回答文本的问题标签作为特征词。由于特征词本身存在于句子中时也会对句子产生一定的影响, 且不同词汇在句中发挥的作用不尽相同, 因此, 本文根据特征词权重来表征句子特征。此外, 若表示問题的标签出现在回答文本的句子中, 则代表该条句子具有更高的重要性, 句子间的相互联系、相互作用, 使得不同句子的整体权重也有所不同。
前文基于CoRank 计算得到了句子间边的权重,并构建了句子的对称邻接矩阵, 随后, 可以根据式(2) 计算得到文本中第e 个句子的初始权重Ee(1≤e≤M)。其中, qαβ由句子α 和句子β 间的相似度决定, 表示两个句子间的关系强度, d(0≤d≤1)用来解决关系强度均为0 的孤立句, r 通过困惑度函数收敛得出, 对于句子e 而言, 假设该句包含m个语词, 式(2) 用Us(1≤s≤m)表示该句第s 个单词的重要度。在实际训练句子权重Ee 过程中,可先将其初始化为任意值, 然后不断迭代得到最终句子权重。
2 3 基于冗余控制的文本摘要生成
在2 2 节中, 本文得到了文本中所有句子的权重得分, 在通常情况下, 将句子权重得分进行排序后即可选取其中的前几名作为摘要句, 但这种情况仅是基于句子间的关系及特征词的权重来选取摘要句子, 其冗余度未得到有效控制, 为了使摘要句在重要性较高的同时简明扼要、包含更全面的信息,本文将基于MMR 冗余控制模型[23] 对候选摘要句进行冗余控制。对于包含T 个句子的候选摘要句集合, 候选摘要句st(1≤t≤T)冗余控制分数计算方法如式(6) 所示。
score(st )= λ∗Xt -(1-λ)∗Sim2(st ,S) (6)
其中, λ 是调节参数, score(st )(1≤t≤T)是第t 个句子的得分, Sim2 表示句子st (1≤t≤T)与当前摘要S 的余弦相似度, 该值越大表明当前句子与已更新得到的摘要越相似, 加入摘要中可能会引起信息冗余, 此处用减法控制句子冗余得分。此外, 得到的score(st )(1≤t≤T)越高表明该句子与已有摘要相似度越低, 因此每次迭代会将得分最高的句子加入摘要中。图6[24] 是进行候选摘要句冗余控制的流程图, 在进行冗余控制前, 需要初始化摘要结果S, 可将Xt(1≤t≤T)值最高的候选摘要句加入其中进行初始化。
3 实证研究
过去几年, 国内问答社区逐渐从小众平台转型为大众平台, 迎来了用户和内容数量的井喷。如今, 知乎用户已突破2 2 亿, 全站问题总数超过4 400万, 回答总数超过2 4 亿, 拥有海量的问答文本数据, 其良好的答题氛围和高水平、多样化的问答文本是优质的数据来源。本文将从知乎的问答文本内容入手, 利用构建的摘要提取模型提取问答文本摘要。
3 1 数据获取及预处理
3 1 1 知乎平台数据获取
本次实验的数据来自知乎问答社区, 选取了互联网分类下的“中文互联网的产出在渐渐枯萎吗?”、心理学分类下的“为什么现在的年轻人内心都越来越悲观?” 等5 个领域的问题, 如表1 所示。
每个问题中获取110 条文本在200 字以上的回答, 经过人工审查发现, 部分回答文本中包含了较多的无意义符号, 将此类无意义文本及重复文本剔除后, 每个问题下保留100 条数据进行后续实证分析。表2 为部分回答文本数据。
3 1 2 数据预处理
获取到文本数据后, 对文本进行分词处理。鉴于Pkuseg 包可以进行多领域分词, 并且支持用户自定义自训练模型, 具有更高的分词准确率, 本文采用Pkuseg 分词包进行文本分词, 同时利用百度停用词表、哈工大停用词表、中文停用词表、四川大学机器智能实验室停用词库得到内容较全的停用词库, 分词结果如表3 所示。
3 1 3 问题标签属性抽取
知乎的问题中都会带有用户定义的标签, 问题本身以及问答文本往往也都与这些标签相关, 后续实证将基于已有标签对摘要进行监督处理, 由于标签属性往往为用户自定义或者知乎推荐的标签, 规范程度较低, 所以此处对标签进行拆分处理, 得到如表4 所示的结果。
3 2 语义向量表示
3 2 1 基于SLDA 模型和Word2Vec 的语词语义表示
首先, 利用文本语词集合以及如表5 所示的文本所属类别及文本的词频矩阵DT, 训练SLDA 模型。
本实验集共有25 430个语词, 将文本集拆分为训练集和测试集, 其中训练集取文本集中每类文本的前90 条, 共450 条文档数据, 测试集取文本集中每类文本的后10 条数据, 共50 条数据。将以上训练集作为输入数据, 根据处理后标签属性的个数, 将K 值归纳为20, 设置迭代次数为1 000次,经过前期试验得到, 在先验分布参数α 取值为1 0时, 整体的训练效果较好, 因此本次实证采用α =1 0 训练得到的SLDA 模型来对测试集数据进行分组, 根据以上SLDA 模型可以得到测试集中每个单词在不同主题下的概率分布, 该语词—主题分布矩阵即是所有语词的全局语义向量wzi。
而后利用维基百科语料对文本集进行Word2Vec处理, 以Skip-Gram 模型作为训练模型, 设置窗口大小为5, 词向量维数设置为100, 得到文本的局部语义嵌入词向量wci。
3 2 2 综合语义表示
将根据训练的SLDA 模型得到的测试集单词的全局语义嵌入词向量wzi和根据Word2Vec 模型得到的单词局部语义嵌入词向量wci, 做向量拼接, 得到每个测试集中每个单词的综合语义嵌入词向量,如表6 所示。
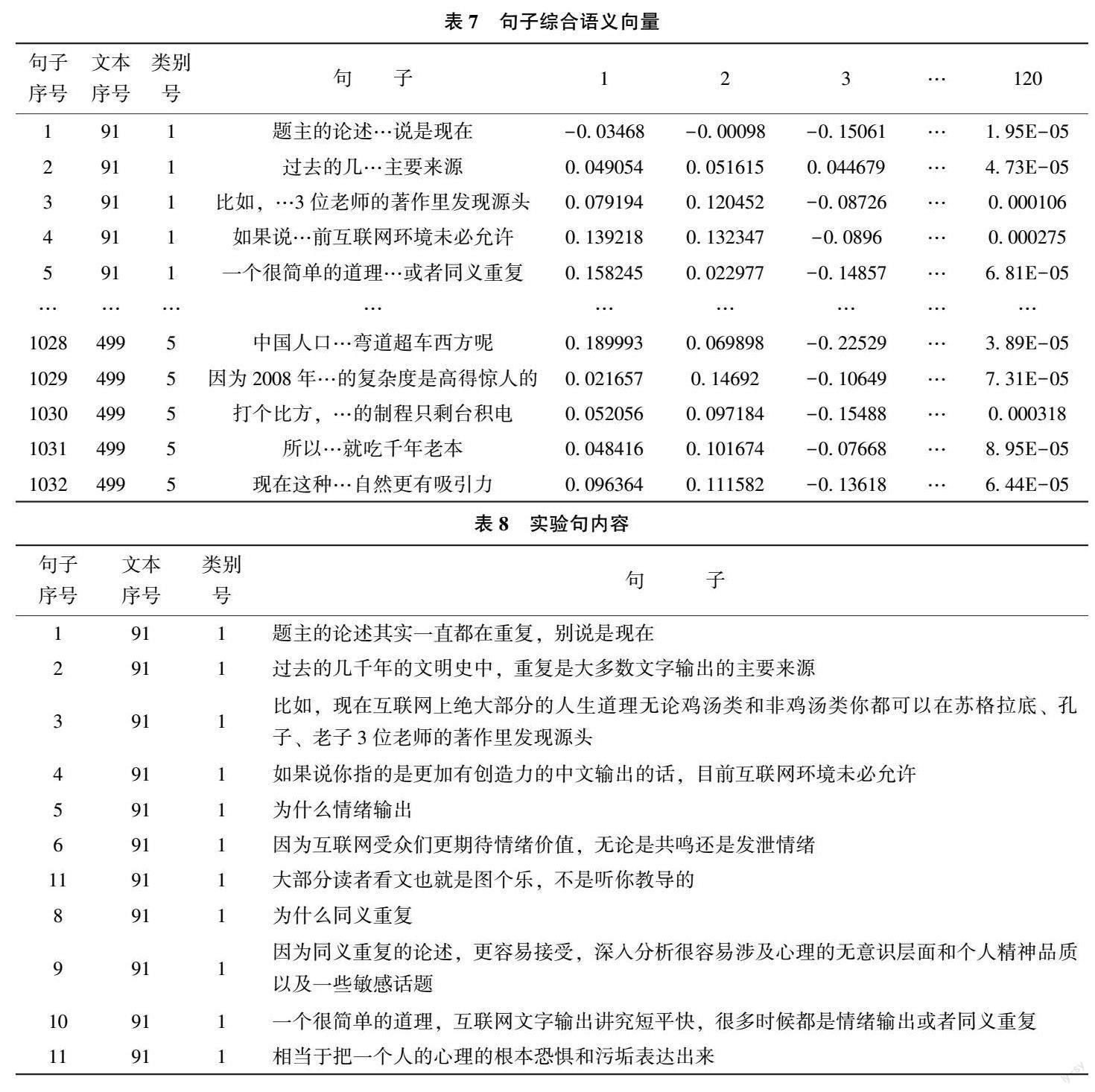
得到单词的综合语义嵌入词向量后, 将其代入测试集的文本中, 将每个句子中所有语词的综合语义嵌入词向量取均值, 便可以得到每个句子的综合语义向量, 本文对句子的分割以“。” “?” “.” “?”为基准, 从而尽量保证句子的完整性。由于每个句子所包含的词语数量不同, 为统一句子的向量维度, 取句子中所有词向量的均值来对句子进行向量表示, 可以得到测试集中部分句子的综合語义向量如表7 所示。
3 3 摘要生成
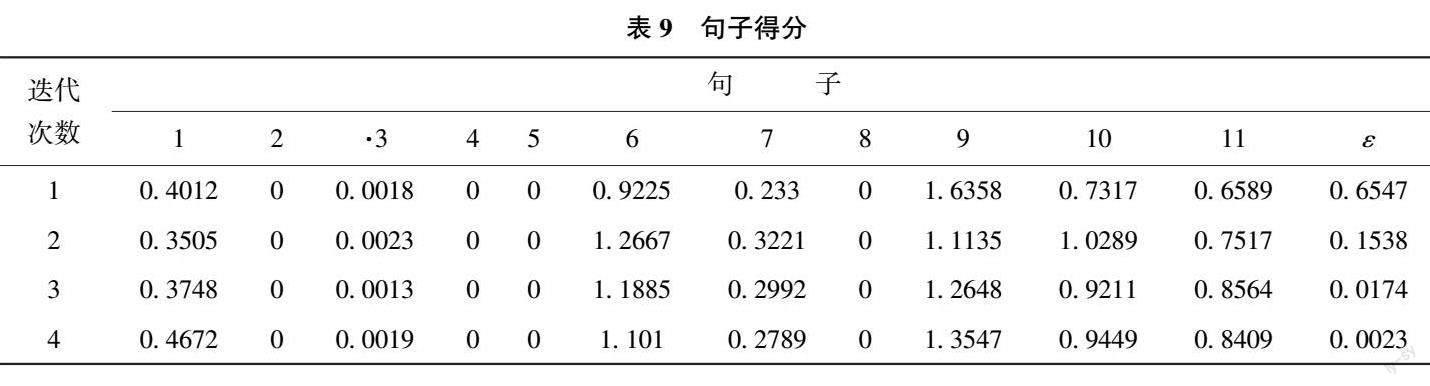
上文通过获取全局语义嵌入词向量及局部语义嵌入词向量的方式对句子进行了语义表征, 此处利用CoRank 图排序算法获取句子的对称邻接矩阵,从语义层面获取句间关系。为便于更直观地查看模型效果, 本文选择测试文本集中的第1 条数据, 即类别号为1, 文本序号为91 的回答文本进行后续实证, 表8 为该文本根据“。” “?” “.” “?” 进行句子分割后得到的11 个句子。
抽取表8 中句子的语义向量, 根据CoRank 算法, 可以计算出句子之间的杰卡德相似系数, 从而得到句子的对称邻接矩阵。
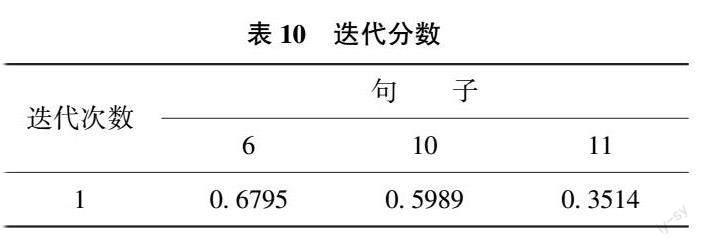
随后, 将问题标签作为特征词引入到文本表里以计算句子之间的关系强度, 根据特征词词频矩阵以及基于邻接矩阵, 可以根据式(6) 迭代计算句子权重得分, 设置阈值为经验值0 01, 结果稳定后, 其11 个句子的得分如表9 所示。
其中, 句子9、6 和句子11、10 具有较高的分值。如果仅仅通过句子关系来抽取摘要句子, 则句子9 和句子6 可以被看作是包含信息量最大的候选摘要句, 为了保证信息的多样性, 本文将91 号文本中1/3 的句子加入候选摘要集, 因此对该回答文本, 可以选取得分在前4 名(即句编号为: 9、6、10、11)的句子加入候选摘要集, 取句子最后迭代得到的得分作为句子得分。
根据以上得到的候选摘要集以及其中的句子得分, 结合MMR 冗余控制流程(中间过程), 将得分最高的句子9 作为最终摘要的初始句, 为保证用户能在最短的时间内获取更多的信息且符合快速阅读习惯, 本研究设置最终摘要长度为80 个字(包含文字和标点符号, 中文单字及英文单词均为1 个字),迭代过程中得到每个候选摘要句的分数如表10 所示。
在第一次迭代中, 句子6 就被加入最终摘要中, 导致最终摘要的字数超过了80, 因此迭代结束。将最终得到的摘要句9 和6 进行组合, 可以得到最终摘要结果为: “因为同义重复的论述, 更容易接受, 深入分析很容易涉及心理的无意识层面和个人精神品质以及一些敏感话题, 互联网受众们更期待情绪价值, 无论是共鸣还是发泄情绪”, 即为本文实验结果。
3 4 实验结果分析
从定性角度来看, 本实验最终摘要句总体可以概况回答文本内容, 其包含内容较多, 信息较为丰富。同时, 得到的两个句子在内容上重复度较低,更全面地概括了文本内容, 即该摘要结果在信息性、多样上均有较好的结果。此外, 摘要句中均包含“因为”, 这与问题中的疑问遥相呼应, 摘要句中的“互联网” 也属于特征词, 并且该摘要句能回答该问答文本对应的问题“中文互联网的产出在渐渐枯萎吗”, 阐述了作者对于问题的看法, 说明了问题标签的引入对句子的权重有一定影响, 从全局角度来看, 该句子与该问题下的内容紧密相连,从局部角度来看, 在该回答文本的11 个句子中,该摘要具有最丰富的语义信息, 能更好地表达文本主旨内容。此外, 学术界也常用ROUGE(Recall-OrientedUnderstudy for Gisting Evaluation)指标来评价实验结果, 该指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE 通过将模型生成的摘要或者回答与人工得到的摘要或者回答按ngram拆分后, 计算召回率, 从而得到对应的得分。
为了验证本文摘要提取方法的有效性, 在同一数据集的基础上, 本文设置了两个对照实验, 将基于LDA 的冗余控制方法[5] 作为实验一用于验证有监督的主题表示模型对问答文本主题特征的表征情况, 以及将基于TextRank 的方法[25] 作为实验二用于验证CoRank 算法对于句子顺序的排列效果, 横向对比得到的评测结果, 按照1-gram 和2-gram 进行拆分, 得到ROUGE-1 和ROUGE-2 值的对比结果, 如图7 所示。
实验结果显示, 本文方法的评测结果总体上优于其他对比方法。实验一基于LDA 及冗余控制的摘要提取方法充分利用了LDA 主题模型的特征,从多个角度判断了句子的重要性, 取得了一定的成果, 但未能进行深层次的语义、语法分析, 忽略了问答文本的标签属性等, 导致其评分较低。实验二基于句子权重优化了TextRank 算法, 但对于问答文本特征的忽略导致其在评测时得分不高。以上结果说明, 本文基于主题特征的主题模型能更全面地挖掘问答文本的语义信息, 所提取的摘要有效性更高, 具有更优的摘要提取效果。
4 结 语
本文结合SLDA 及Word2Vec 语义向量模型, 从全局角度及局部角度挖掘文本语义信息, 利用词向量更全面地对文本语义进行表征, 基于CoRank 算法实现句子排序, 选取出重要度较高的句子, 初步保证了摘要句在整个回答文本中的重要性; 同时,为保证得到的摘要句与问答文本的问题紧密相关,本文引入问答文本标签, 结合特征词, 计算句子得分以保证摘要句信息性; 并采用MMR 冗余控制算法, 控制最终摘要长度, 以候选摘要集中的句子冗余得分为基础, 迭代更新候选摘要集和最终摘要,最终得到具有信息性和多样性的摘要句。而后, 利用爬虫技术获取5 个问答文本下的500 份回答文本数据验证本文模型, 结果显示, 本模型所抽取的摘要句在总体上概括了文本内容, 使用户在短时间内可快速获取到该回答文本的主旨内容, 但本文仍存在一定不足, 例如: 在引入特征词时, 仅基于词频来结合计算句子权重, 容易忽略语义层面上的信息,未来也将在此基础上做进一步改进, 探索更科学的评价机制来评价结果和模型, 从而继续提升在线问答社区的服务水平, 促进信息服务的高质量发展。
参考文献
[1] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation [ J].Journal of Machine Learning Research, 2003, 3 ( 4/5): 993 -1022.
[2] Fang H, Lu W, Wu F, et al. Topic Aspect-oriented Summariza⁃tion Via Group Selection [J]. Neurocomputing, 2015, 149: 1613-1619.
[3] Bairi R B, Iyer R, Ramakrishnan G, et al. Summarization of MultidocumentTopic Hierarchies Using Submodular Mixtures [ C] / /Proceedings of the 53rd Annual Meeting of the Association for Com⁃putational Linguistics and the 7th International Joint Conference onNatural Language Processing (Volume 1: Long Papers), 2015, 1:553-563.
[4] Yang G. A Novel Contextual Topic Model for Query-focused MultidocumentSummarization [C] / /2014 IEEE 26th International Con⁃ference on Tools with Artificial Intelligence. IEEE, 2014: 576 -583.
[5] 汤丹. 基于LDA 和冗余控制的多特征中文自动文摘的研究和实现[D]. 昆明: 云南师范大学, 2021.
[6] Li J, Li S. A Novel Feature-based Bayesian Model for Query Fo⁃cused Multi-document Summarization [J]. Transactions of the As⁃sociation for Computational Linguistics, 2013, 1: 89-98.
[7] Valizadeh M, Brazdil P. Exploring Actor-object Relationships forQuery-focused Multi-document Summarization [ J]. Soft Compu⁃ting, 2015, 19 (11): 3109-3121.
[8] Blei M D, McAuliffe J D. Supervised Topic Models [ J]. NIPS,2007: 121-128.
[9] 唐晓波, 顾娜, 谭明亮. 基于句子主题发现的中文多文档自动摘要研究[J]. 情报科学, 2020, 38 (3): 11-16, 28.
[10] 石磊, 阮选敏, 魏瑞斌, 等. 基于序列到序列模型的生成式文本摘要研究综述[J]. 情报学报, 2019, 38 (10): 1102-1116.
[11] 肖元君, 吴国文. 基于Gensim 的摘要自动生成算法研究与实现[J]. 计算机应用与软件, 2019, 36 (12): 131-136.
[12] Erkan G, Radev D R. Lexrank: Graph-based Lexical Centralityas Salience in Text Summarization [ J]. Journal of Artificial Intelli?gence Research, 2004, 22 (1): 457-479.
[13] Wei F, Li W, He Y. Document-aware Graph Models for QueryorientedMulti -document Summarization [ M]. Multimedia Analysis,Processing and Communications. Springer, Berlin, Heidelberg, 2011:655-678.
[14] Silva S, Joshi N, Rao S, et al. Improved Algorithms for Docu⁃ment Classification & Query-based Multi-Document Summarization[J]. International Journal of Engineering and Technology, 2011, 3(4): 404.
[15] 赵美玲, 刘胜全, 刘艳, 等. 基于改进K-means 聚类与图模型相结合的多文本自动文摘研究[J]. 现代计算机(专业版),2017, (17): 26-30.
[16] Wang W, Wei F, Li W, et al. Hypersum: Hypergraph BasedSemi-supervised Sentence Ranking for Query-oriented Summarization[C] / / Proceedings of the 18th ACM Conference on Information andKnowledge Management. ACM, 2009: 1855-1858.
[17] Zheng H T, Guo J M, Jiang Y, et al. Query-Focused MultidocumentSummarization Based on Concept Importance [ C] / / Pa⁃cific- Asia Conference on Knowledge Discovery and Data Mining.Springer, Cham, 2016: 443-453.
[18] 陶兴, 张向先, 郭顺利, 等. 学术问答社区用户生成内容的W2V-MMR 自动摘要方法研究[ J]. 数据分析与知识发现,2020, 4 (4): 109-118.
[19] 陈晨, 侯景瑞, 吴任力, 等. 基于多源混合标签的社会化问答社区问题推荐方法研究[J]. 情报科学, 2019, 37 (7): 139-145.
[20] 朱辉. 融合主题模型的文本语义表示方法研究[ D]. 烟台:山东工商学院, 2021.
[21] 谷莹, 李贺, 李叶叶, 等. 基于在线评论的企业竞争情报需求挖掘研究[J]. 现代情报, 2021, 41 (1): 24-31.
[22] 刘凯鹏, 方滨兴. 一种基于社会性标注的网页排序算法[ J].计算机学报, 2010, 33 (6): 1014-1023.
[23] 朱玉佳, 祝永志, 董兆安. 基于TextRank 算法的联合打分文本摘要生成[J]. 通信技术, 2021, 54 (2): 323-326.
[24] 程琨, 李传艺, 贾欣欣, 等. 基于改进的MMR 算法的新闻文本抽取式摘要方法[J]. 应用科学学报, 2021, 39 (3): 443-455.
[25] 曹洋. 基于TextRank 算法的单文档自动文摘研究[D]. 南京:南京大学, 2016.
(责任编辑: 郭沫含)
