
基于深度强化学习的配件库存决策研究
2023-08-11 07:16:02李雨情潘超凡
现代计算机 2023年11期
李雨情,潘超凡
(1. 西南交通大学制造业产业链协同与信息化支撑技术四川省重点实验室,成都 611756;2. 西南石油大学计算机科学学院,成都 610500)
0 引言
随着中国国民经济的快速发展,我国的汽车工业也得到了迅猛发展。据公安部统计,2022 年全国机动车保有量达4.17 亿辆,其中汽车3.19 亿辆[1]。伴随着汽车保有量的增长,汽车的保养和维修需求也迎来高峰期。众所周知,汽车配件是汽车售后市场获取利润的直接源泉。由于汽车配件种类繁多,需求呈多样性,根据需求发生间断程度的大小,一般将汽车配件分为两类:连续性需求配件和非连续性需求配件[2]。面对这样不确定的配件需求,制定合理的库存决策是企业急需解决的重大问题,也是扩大市场份额的重要支撑。本文根据配件的不同需求特性,通过深度强化学习算法研究汽车配件库存决策问题。在现有研究的基础上,本文的研究更贴合现实,也为企业库存决策提供了一定的依据。
1 相关理论及方法
1.1 强化学习
强化学习(reinforcement learning,RL),是基于智能体与环境进行交互,并从环境中获得信息奖赏并映射到动作的一种学习方式,如图1所示,其主要思想是根据系统当前环境确定下一步决策应采取的行动,行动的结果是系统状态发生转移,而且根据行动的后果产生一定的奖励评价决策的效果并进行反馈,从而逐渐改进决策方法[3]。RL 更接近于自然界生物学习的本质,因而在很多领域取得了成功的应用。
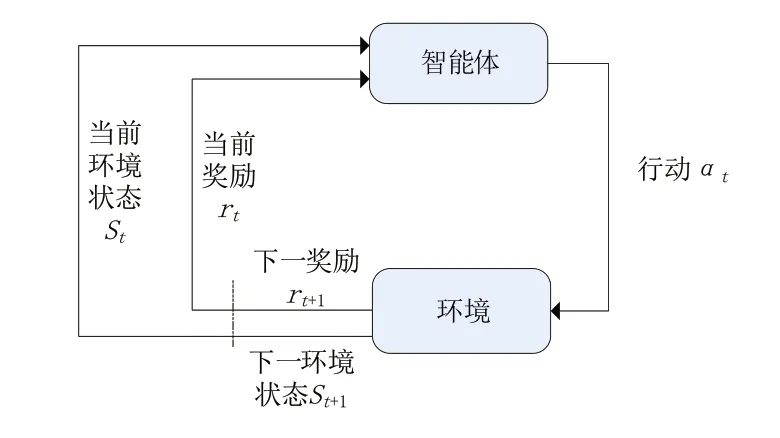
图1 强化学习基本结构
随着深度学习的兴起,它与基于价值函数的RL算法结合产生了DQN[4]等深度强化学习算法[5]。而将深度学习与基于策略函数的RL结合,相继产生了DDPG[6],PPO[7],TD3[8],SAC[9]等算法。
1.2 基于强化学习的库存决策研究
针对需求不确定的情况,目前大部分库存决策研究方法通常分为两步:首先建立需求预测模型得到预测的需求,其次设计算法求解待求问题的数学模型。这样的研究方法需要依赖需求预测模型保证极佳的预测精度,难以考虑动态及随机因素[10]。
而基于强化学习算法的库存决策研究不依赖高精度的需求预测模型,且可充分考虑库存决策过程中的多阶段序贯决策和不确定性。库存决策是一个典型的多阶段序贯决策问题,Stranieri 等[11]将需求表示为余弦函数来模拟季节性行为,通过实验比较VPG[12]、A3C[13]、PPO三种算法在两阶段供应链库存决策问题下的性能,最终得出PPO 更能适应不同环境的结论,且PPO 的平均利润也高于其他算法。毕文杰等[14]针对生鲜产品的易逝性提出了基于深度强化算法的生鲜产品联合库存控制与动态定价方法,通过DQN、DDPG、Q-learning 等算法进行对比实验,结果表明基于DQN 算法的收益表现最佳。
综上所述,考虑到产品需求复杂性的研究较少,而这是当前企业面临的现实问题。本文针对这些问题,基于深度强化学习来建模求解库存决策问题,以最大化期望总收益,并探讨了不同需求下各前沿强化学习算法的表现优劣。
2 模型构建
2.1 问题定义
汽车制造厂内的配件中心库是整个配件产业链的统筹计划中心,其存储了上万种可能用于自身品牌汽车售后维修保养的配件,企业投入了大量人力和财力用于其日常运营。本文对由制造厂的配件中心库和供应商组成的两阶段供应链库存决策问题进行建模,从供应商订购两种不同需求特性的配件,满足下级代理商的需求,如图2所示。

图2 供应链结构
假设供应商可以提供无限数量的配件,从供应商到仓库的交货时间为零。假定制造厂有法律义务履行所有订单,供应过程中允许缺货,但是一旦缺货,所欠的货必须补上。其中各数学符号含义如表1所示。
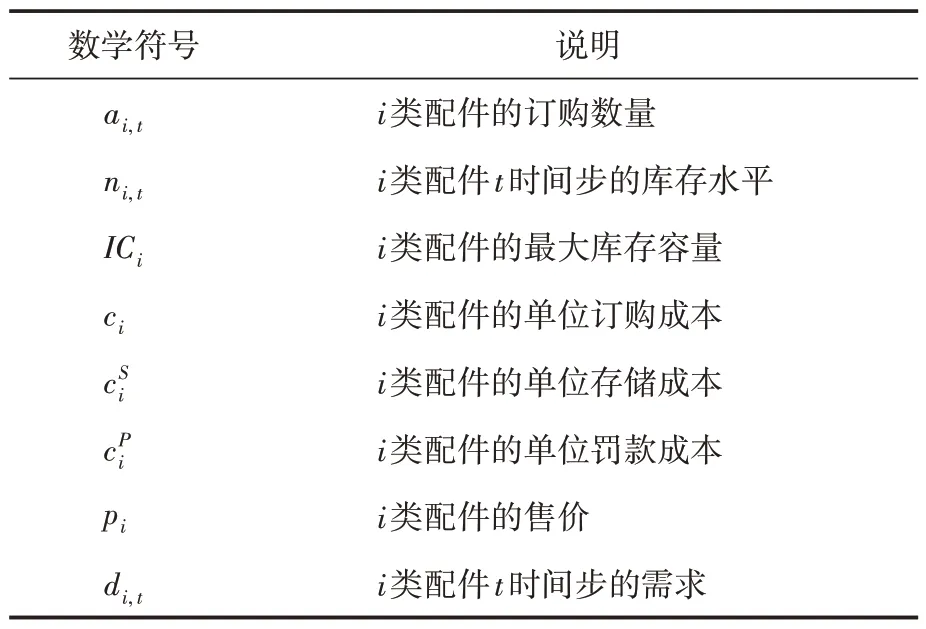
表1 数学符号含义说明
为了更贴合现实坏境,需求采用每个时间段的均值(λ)的泊松分布进行建模。连续性需求和非连续性需求的详细设置将在第4节介绍。实验中考虑1080 天的需求值,每15 天为一个时间步,故有72 个时间步。连续性需求和非连续性需求配件的需求值的某个实例如图3所示。
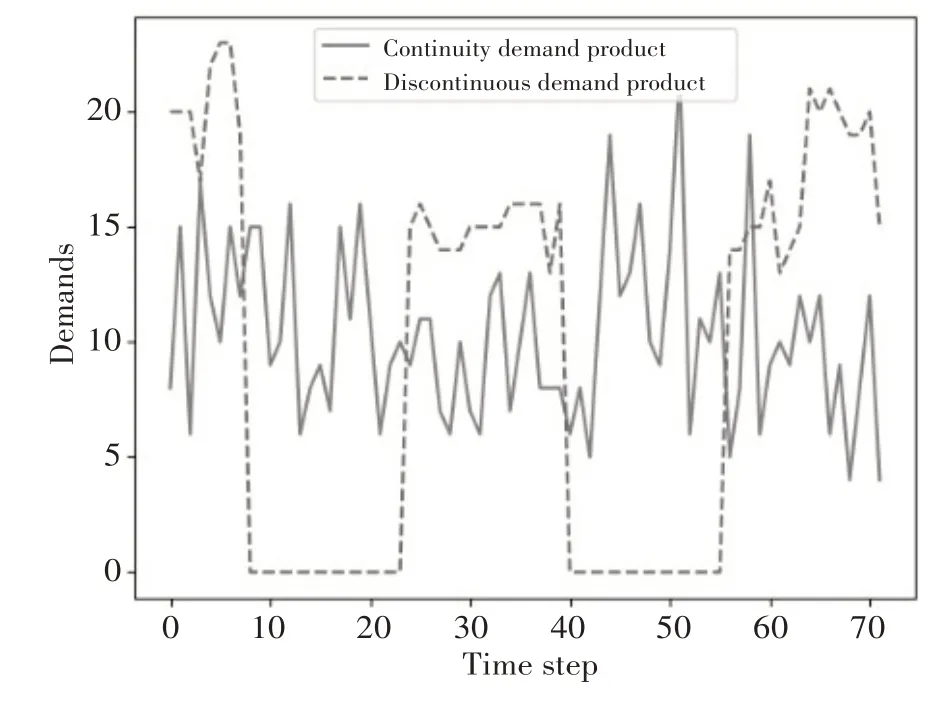
图3 不同需求特性配件需求值的某实例
2.2 马尔可夫决策过程
强化学习将库存控制这类序贯决策问题建模为马尔可夫决策过程并进行求解。本文通过马尔可夫决策过程将待求解问题定义为一个四元组M=(S,A,P,R),本文定义马尔可夫决策过程的各要素如下:
状态空间:状态向量包括仓库的每种配件类型的当前库存水平,加上历史x个时间步的需求值,并定义如下:
其中dt-1=(d0,t-1,d1,t-1,…,di,t-1)。当前t时间步的实际需求dt要到下一个t+1 时间步才能知道。类似于由Kemmer等[15]所做的工作,在后面加上需求值是为了使智能体可以从需求历史中学习,从而将一种需求预测直接集成到策略中。
动作空间:通过神经网络直接生成动作值实现了一个连续的动作空间,包括在供应商采购每种配件类型i的数量:
其中每个值的下界都是零,上限是仓库对每种配件类型的最大容量,也即(0 ≤ai,t≤ICi)。
状态转移:下一状态的更新规则定义为
在下一个时间步开始时,制造厂的库存等于初始库存加上订购的数量,减去当前的需求。最后,更新包含在状态向量中的需求值。
奖励函数:每个时间步t的奖励函数定义如下:
等式右边的第一项是收入,第二项是订购成本,第三项是存储成本,实现max 函数是为了避免负库存(积压订单)被计算在内。最后一项表示惩罚成本,它是用加号引入的,因为在不满足订单的情况下,库存水平已经为负。因此,智能体的目标是利润最大化。
3 算法设计
3.1 状态抽象
强化学习中的状态抽象是指将环境状态映射到一个更低维的表示形式的过程。具体来说,在库存决策环境中进行状态抽象指的是对库存状态中与订单决策不相关的状态值进行映射,以达到状态空间压缩的效果。
本文针对库存决策的环境提出一种基于状态抽象的状态归一化模块,该模块设计了一个针对库存决策的状态抽象函数,使智能体能以更快的速度做出决策。基于订单数量仅与一定范围内的库存水平相关的思想,本文设计了如下的状态抽象函数:
其中s表示环境的状态向量,状态向量分为库存水平和历史需求两部分,因此状态向量的下限也分为两部分,其中,需求下限为0,当积压的订单数大于制造厂每个t时间步订购的数量at时,智能体都需要最大化订单数量,因此状态向量的下限需求的上限dh取决于需求的具体分布,当库存水平高于两倍需求的上限时,决策系统都需要将订单数量设为0,以减小库存成本,因此状态向量的上限sh=(2dh,dh)。通过该状态抽象函数可以将原始状态空间S映射到新的状态空间S′=[-1,1]中。
3.2 算法选取及设计
强化学习方法应用于库存管理领域已经有一定研究,Q-learning 算法与DQN 算法应用较为广泛。DQN 算法适用于离散动作空间,为了适用于连续动作空间,产生了DDPG 算法。和DDPG 相比,SAC 算法使用的是随机策略,目标是最大化带熵的累积奖励,使其具有更强的探索能力,且更具有鲁棒性,面对干扰的时候能更容易做出调整。
结合第2 节所设的库存决策环境的SAC 算法流程如下:
输入:环境
使用参数θ1、θ2、φ初始化策略网络πφ、第一个评价网络Qθ1和第二个评价网络Qθ2。初始化经验池B,设置其大小为N。
对于每一幕执行:
(1)初始化环境和状态抽象后的状态S0;
(2)从t= 1到t=T,执行以下操作:
①观察状态S从策略网络中选择动作A。
②执行所选动作A,观察下一个状态S′和奖励r。
③在经验池中存储四元组(S,A,R,S′)。
④如果经验池中存储经验的数量大于批次大小,执行以下操作:
(a)从经验池中随机采样经验批次(Si,Ai,Ri,S′i),∀i= 1,…,N。
(b)使用两个评价网络中最小的Q值来计算目标值,利用梯度下降算法最小化评估值和目标值之间的误差,从而更新两个评价网络Qθi。
(c)通过梯度上升算法更新策略网络πφ。自动调整熵的系数α,让策略的熵保持一种适合训练的动态平衡。
(d)引入动量τ,用软更新稳定训练,更新目标网络θ′i←τθi+(1 -τθ′i)。
SAC 算法是异策略的随机策略梯度算法,在异策略的确定性策略梯度算法中,本文采用了相对于DDPG 算法优化的TD3 算法进行对比实验。此外,同策略算法中也采用了较先进的PPO算法进行对比实验。
4 仿真实验
引入了深度神经网络的算法模型的超参数一般需要手动设置,其中,学习率和gamma 值是深度强化学习模型训练中非常重要的参数,影响到智能体训练的稳定性和收敛性。因此,本文通过控制变量法,分别测试了学习率α=0.005、α= 0.001、α= 0.0005 的情况,最终选定α= 0.0005。固定其他参数,分别测试了gamma 值γ= 0.9、γ= 0.95、γ= 0.99 的 情 况,最终选定γ= 0.95。由于篇幅有限,具体效果图不做展示。
本文设计并进行了一组丰富的实验,分不同需求特性设定了三个场景,比较PPO、TD3、SAC 三种深度强化学习算法在不同场景下的性能,以此分析算法在仿真库存决策环境中的表现,并判断算法能否应用于现实环境。实验中对i类配件的通用参数常量设置如表2所示。

表2 实验环境常量
4.1 连续性需求场景
本场景下的连续性需求配件的需求服从于均值为10 的泊松分布,结合上述参数设置进行实验,对比分析TD3、SAC、PPO 三种深度强化学习算法在连续性需求下的性能。实验结果如图4所示,在连续性需求场景下,SAC和TD3算法的最终奖励都比PPO 算法高,且SAC 算法和TD3 算法都比PPO 算法收敛稳定。SAC 算法比TD3 算法先收敛。尽管TD3 算法比SAC 算法先达到较高的奖励,但TD3算法前期比较震荡。
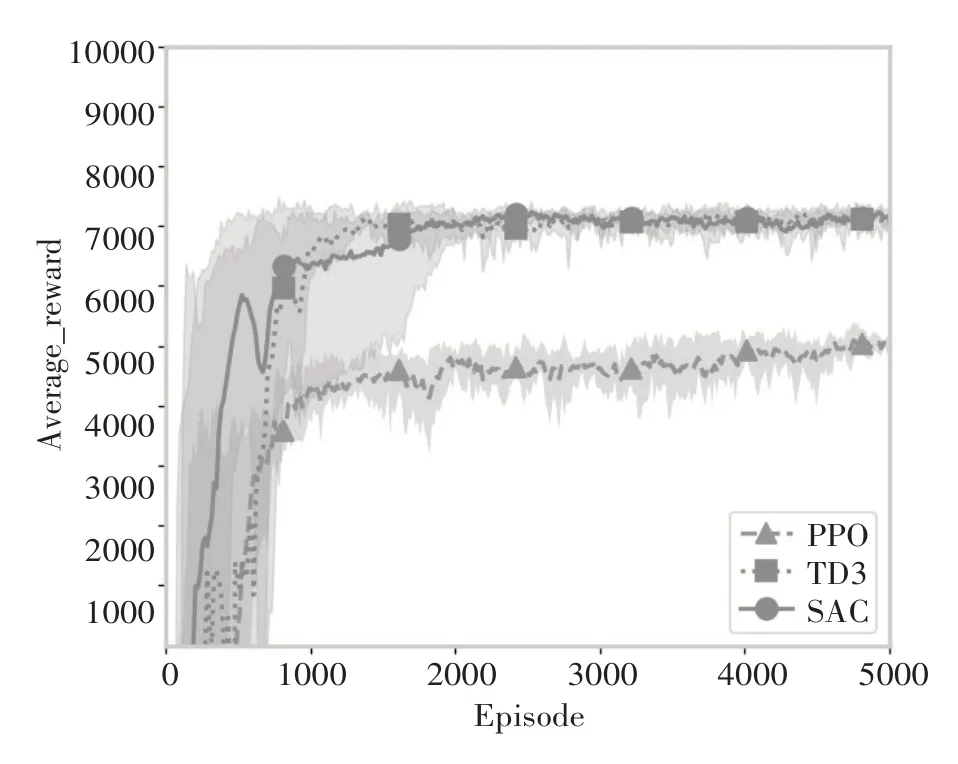
图4 TD3、SAC、PPO在连续性需求下的实验对比结果
4.2 非连续性需求场景
本场景下的非连续性需求配件的需求依然服从于泊松分布,均值每120天从[10,15,20,0]中等概率随机选取。本研究结合上述参数设置进行实验,对比分析了TD3、SAC、PPO 三种深度强化学习算法在非连续性需求下的性能。实验结果如图5 所示,在非连续性需求场景下,SAC 和TD3 算法都比PPO 算法奖励高,且SAC算法和TD3 算法都比PPO 算法收敛稳定。SAC算法比TD3算法先收敛也先达到较高的奖励。
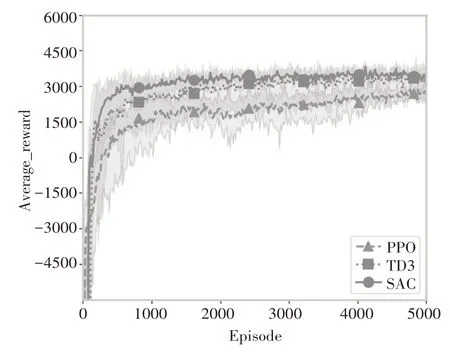
图5 TD3、SAC、PPO在非连续性需求下的实验对比结果
4.3 混合连续性及非连续性需求场景
本场景下配件的需求结合前两节的需求设置,奖励为这两类配件的利润之和。本研究结合上述参数设置进行实验,对比分析TD3、SAC、PPO 三种深度强化学习算法在混合连续性需求和非连续性需求下的性能。实验结果如图6所示,在混合连续性需求和非连续性需求场景下,SAC 算法达到的奖励最高,最先收敛,稳定性也最强;TD3算法其次,PPO算法最后。

图6 TD3、SAC、PPO在混合连续性及非连续性需求下的实验对比结果
综合上述三幅图可得,SAC 算法的收益表现和稳定性无论在连续性需求、非连续性需求,还是混合连续性及非连续性需求上表现都最佳,其次是TD3算法,PPO算法的收益最低。
现实中的需求变化极其复杂,各种因素导致需求呈现随机性强、非稳态的波动变化。SAC 算法能够解决动态需求问题,也能为企业提供近似最优的订货策略。由此可见,基于SAC 算法的库存决策模型具有非常广泛的应用价值。
5 结语
目前汽车后市场规模相应扩大,配件需求也逐年递增,对于制造厂而言如何合理控制库存是非常重要的决策问题。本文研究了汽车配件的库存决策问题,根据配件的需求特性,分为连续性需求配件和非连续性需求配件并制定了三个场景。通过将库存决策问题建模为马尔科夫决策过程,本文在更现实的实验下评估了多个深度强化学习算法的有效性和稳健性。本文还设计了一个针对库存决策的状态抽象函数,从而有效减少无用状态信息,简化库存决策环境,提高决策效率。
本文改进的深度强化学习算法,可以根据当前可用库存来动态调整订货量,使预期利润最大化。然而,由于条件限制,本研究只关注了两阶段供应链的库存决策问题,未考虑运输及订购提前期等因素。未来可以在考虑运输和订购提前期等情况下的库存决策方面进行深入的研究。
猜你喜欢
中外玩具制造(2022年8期)2022-08-08 11:59:00
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26 14:04:14
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26 14:04:06
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:34
新世纪智能(语文备考)(2019年12期)2020-01-13 06:04:26
军事运筹与系统工程(2017年3期)2018-01-23 02:48:40
厦门理工学院学报(2016年1期)2016-12-01 04:50:51
中学生数理化·七年级数学人教版(2016年4期)2016-11-19 08:41:24
工程建设与设计(2016年4期)2016-02-27 10:51:14
Coco薇(2015年11期)2015-11-09 00:52:20
