
一种批量检查中小学Python程序作业文件的算法
2023-08-10 20:49欧建荣
中国信息技术教育 2023年15期
欧建荣


摘要:作者提出了一种批量检查中小学Python程序作业文件的算法并将其编写成应用软件,在实现对Python程序作业文件高效检查的同时,将作业自动评价分类。该方法检查Python程序作业文件准确率高达99%,能够对信息技术教师批量检查Python作业文件起到一定的帮助作用。
关键词:检查作业;Python;mypy;最长公共子序列
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2023)15-0073-04
引言
学习Python程序设计能很好地锻炼学生的逻辑能力和思维能力,但面对大量的Python程序作业文件,教师要花费大量的时间去批改。在批改Python程序作业时,教师要手动打开Python程序并运行,观察是否有语法错误、运行结果是否正确,并与正确的程序对比等。如果教师能利用程序编译Python程序文件以自动检查程序是否有误,并自动检查程序与正确程序的相似度,然后对其进行评价分类,大致得出Python程序作业是属于优秀作业还是乱做作业等,则能高效且及时地掌握学生的学习情况。因此,笔者结合Python程序的特点,提出了一种批量自动检查Python程序文件的方法,旨在提高教师检查作业的效率,并使学生得到及时反馈,提高教学效率。
技术简介
1.mypy
mypy是Python静态类型检查工具,可以检查Python程序文件在编写内容和逻辑上是否有误。mypy工具的安装极为简单,安装命令为:python -m pip install mypy。笔者利用QProcess启动外部程序的方式启动mypy并从其标准输出通道中读取全部的输出信息,通过输出信息去判断Python程序是否有误。
2.最长公共子序列算法
给定一个长度为n的序列A和一个长度为m的序列B,求出一个最长的序列,使得该序列既是A的子序列,也是B的子序列,这就是最长公共子序列问题。最长公共子序列算法是一个非常实用且被广泛应用的算法,适合于求解两个文本之间的相似度。
笔者利用动态规划的方法实现求解最长公共子序列,首先将原问题分割成一些子问题,用L[i][j]表示A的前i个元素、B的前j个元素的最长公共子序列的长度,这时的最长公共子序列的长度就是子问题。L[i][j]就是状态,L[n,m]则是最终要达到的状态,即为所求结果。其中Ai代表序列A的前i个字符组成的序列,Bj代表序列B的前j个字符组成的序列。A[x]代表序列A的第x个字符,i>0;B[y]代表序列B的第y个字符,j>0。L[i][j]代表序列Ai与序列Bj的最长公共子序列的长度,其公式如下页图1所示。
依据最长公共子序列,求序列A和序列B的相似度,其公式如下页图2所示。
实验数据
笔者采用的实验数据为所在学校八年级学生的2565份Python程序作业文件,这些文件均为学生课堂上即时完成的作业。
实验过程
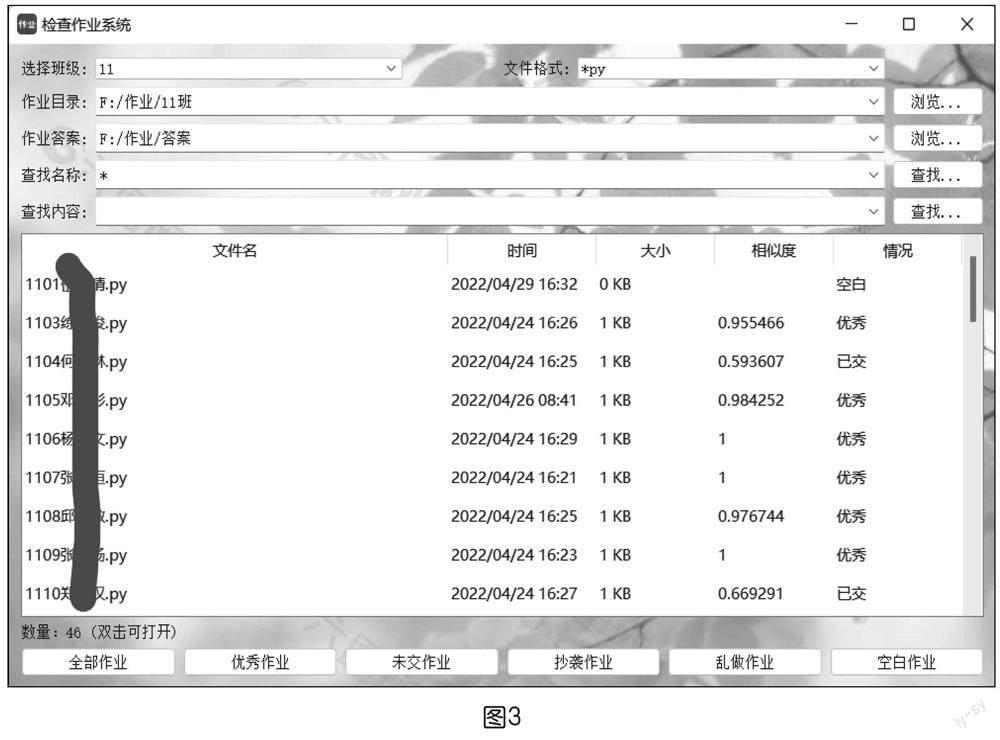
批量检查Python作业系统界面设计如图3所示,首先选择需要检查作业的班级,其次选择该班级所对应的作业目录和作业答案目录,然后点击“全部作业”按钮,即可批量自动检查作业,检查的结果记录显示在中间列表处,其信息包括文件名、时间、大小、相似度,双击列表中的文件可以打开对应的文件。除了对Python作业进行评价分类外,该系统还具备按作业文件名称或按作业文件内容去查找某个作业文件及语音播报等功能,方便教师对作业的查看。
批量检查Python作业系统是在Qt Creator集成开发环境下开发实现,实验中利用到Qt Creator的内部库texttospeech,以实现语音播报功能。另外,实验中需要借助非Qt Creator内部库,因此需要编译并加载第三方库QXlsx,以实现将Excel表中的学生信息批量写入数据库中以及将系统检查作业的结果自动记录到Excel表中。批量检查Python作业系统主要过程如下:
①将学生信息通过编程批量录入SQLite数据库;
②利用红蜘蛛多媒体教学软件收集学生的作业文件;
③使用迭代的方式获取学生的作业文件;
④利用mypy对文件进行编译,并结合最长公共子序列算法将作业文件与正确的答案文件进行相似度计算,从而将作业文件进行评价分类并通过语音播报出来;
⑤自动生成评价分类结果并保存到Excel表格。
具体流程如下页图4所示。
1.录入学生信息
将全年级学生的信息汇总到Excel表格中,学生的信息包括学号和姓名,其中学号由两位数的班级和两位数的座位号组成,如11班1号,则学号为1101。编写程序将Excel表格中全部的学生信息导入并保存到SQLite数据库。
2.收集学生作业
首先,对计算机室的计算机按顺序进行名称修改,如第一台计算机名称为“xs01”,第二台计算机名称为“xs02”,依此类推。学生根据自己的座位号就座相应的位置。课堂上学生通过红蜘蛛多媒体教学软件提交作业后,红蜘蛛多媒体教学软件会为每位学生在教师机端自动生成一个文件夹以存放学生的作业,文件夹命名为对应的学生机的名称。学生所提交的作业文件统一以“班级+学号+姓名”的形式命名,如11班1号张三,则命名为“1101张三”。
3.獲取学生作业
通过编写程序以迭代的方式获取每位学生所提交的作业所对应的文件夹的路径。
4.检查学生作业
(1)算法设计
①统计每个学生文件夹里提交的Python程序作业文件的数量。
②正常情况下,每个学生的文件夹里只有一个Python程序作业文件,如果多于一个则认为该生为他人提交作业。从数据库中查找是否有这些人,如有则将文件夹里的所有作业对应的学生均记录为“抄袭作业”,同时标记为“已交作业”。
③在文件夹里只有一个Python程序作业文件的情况下,先从数据库中查找是否有此人,如有则获取该文件的路径、名称、时间、大小、学生学号和姓名等信息,同时标记为“已交作业”。然后检查文件的大小:文件大小为0KB,则记录该生所提交作业为“空白作业”。文件大小大于0KB,则对文件进行编译处理以及将作业文件与答案文件进行相似度计算。编译通过且相似度大于0.8,则记录为“优秀作业”;编译不通过且相似度小于0.15,则记录为“乱做作业”。
④以班级为单位从数据库中查找出该班所有的学生,“减去”标记为“已交作业”的学生,从而得到“未交作业”的学生。
(2)具体实现
①统计每个学生所提交作业对应的文件夹里后缀名为“.py”的文件的数量。如果数量大于1,为防止学生在文件命名时,将学号和姓名颠倒或在命名中误加入空格或其他特殊符号,本文采用正则表达的方法而非字符串分割截取的方法去提取文件名称中的学号和姓名,其中利用正则表达式“[^0-9]+”提取文件名称中的学号以及利用正则表达式“[^\u4e00-\u9fa5]”提取文件名称中的姓名。由于学号是唯一的,因此利用学号与数据库中该班级的所有学生学号进行对比,如数据库中存在这些学生,则将这些学生均记录为“抄袭作业”,并标记为“已交作业”。
②如果文件夹里后缀名为“.py”的文件的数量为1,则获取该文件的路径、名称、时间、大小等信息以及利用正则表达式“[^0-9]+”和“[^\u4e00-\u9fa5]”分别提取名称中的学号和姓名,接着查找学生信息数据库中是否有此人,如有则标记为“已交作业”。
如果该文件的大小为0KB,则将该生记录为“空白作业”,如果大于0KB,那么:
a.编程调用mypy工具对文件进行静态编译,如果编译通过则其标准输出通道中会含有“Success”关键字,否则含有“error”关键字,从而根据关键字去判断Python程序作业文件是否编译通过,也就是是否有误;
b.打开Python作业文件及其对应的答案文件并分别读取里面的全部内容。为使算法更合理准确,对所读取到的内容进行预处理,Python程序中英文双引号里面的内容以及程序注释内容均为主观定义的内容,内容可能相差较大,而且这些内容并不需要作为求最长公共子序列的内容,因此先用正则表达式“\”[^\”]*\”|#.*”去掉文件内容中的双引号里面的内容和#号后面的内容。另外,去掉文件内容中的回车换行符和空格等。
③求出预处理好后的Python作业文件和其对应的答案文件的最长公共子序列,并求出它们的相似度。结合a和b,如果Python程序作业文件编译通过且相似度大于0.8,则记录为“优秀作业”;如果编译不通过且相似度小于0.15,则记录为“乱做作业”。
④以所选择的班级为单位从数据库中查找出该班所有的学生,“减去”标记为“已交作业”的学生而得到“未交作业”的学生。
实验结果
批量检查Python作业系统能在短时间内高效完成对全班作业的检查,检查结果将作业评价分类为“优秀作业”“未交作业”“抄袭作业”“乱做作业”和“空白作业”。在对2565份Python程序作业文件进行检查后,得到的准确率较高。
讨论
作为初学者,在极短时间的课堂里,学生基本都是按照课本上的程序代码和教师的教学指导去编写,加上初学的程序較为简单且基本没有第二种写法,因此学生课堂上完成的Python程序基本与课本里的程序或教师要求完成的程序完全相同或者类似,从而非常适用于批量检查Python作业系统。但该系统也存在一些不足之处:
①有些学生可能会按自己的想法去写出正确的程序,造成所编写的Python程序与答案程序较为不同,导致系统所检测出的相似度偏低,从而可能不被系统判断为“优秀作业”,但至少会被判断为“已交作业”。根据实验结果统计,在2565份作业中,只有2份作业出现这种情况,因此这种情况属于极少数,对批量检查Python作业系统的准确率的影响微乎其微。
②不适合较为复杂的或具有多种写法的程序,因为这样会造成与答案程序较为不同,导致系统所检测出的相似度偏低。
总的来说,中小学信息技术课程中的编程内容对中小学的学习要求较低,基本是处于基础的层面,程序较为简单,且学生为初学者,因此批量检查Python作业系统非常适合对中小学课堂Python程序作业的检查。
参考文献:
郑翠玲.最长公共子序列算法的分析与实现[J].武夷学院学报,2010,29(02):44-48.
