
基于Se-ResNet101+KNN的鱼类分类研究
2023-08-04 05:52:04张守棋苏海涛
电脑知识与技术 2023年18期
张守棋,苏海涛
(青岛科技大学信息科学与技术学院,山东青岛 266061)
0 引言
随着现代海洋渔业不断发展,许多识别技术和机制也在不断更新迭代。其中海洋鱼类分类就是一重要领域,传统分类一般以鱼的体态特征为依据,如形状、颜色等,虽然准确率相对较高,但同时缺点也很明显,如耗时长、强度大,得到的结果极易受主观因素影响等。
与此同时,机器学习技术在多个领域逐渐应用,相关研究人员开始将机器学习应用于海洋鱼类的自动识别并分类。如王文成等人[1]通过提取不同种类比目鱼图像的形状和颜色等特征,构建分类器实现比目鱼的自动分类,分类精度达到92.8%。
Hu等人[2]通过人工对鱼体图像进行锚点定位,并利用BP 神经网络进行鱼体形态特征的提取,得到了84%的准确率。但是,它的弊端也是显而易见的。首先,机器学习对数据的依赖性非常强,若训练的数据质量不高,就可能导致学到的模型不全面,从而造成错误的分类或被欺骗现象。其次,机器学习取决于学习模型的类型,而模型的选取直接影响到机器学习系统的性能。最后,机器学习不能执行特定多种任务,其并行度相对较低。
相比之下深度学习在分类问题上也有很好的表现,其能够实现自动抽取图像的特征,并直接提供预测结果,从而简化运算过程,增强了泛化能力,因而逐渐在各个领域得到应用。同时,对鱼类识别的研究也逐渐深入,如:提出了一种基于稀疏低序矩阵分解的方法,并采用深度结构与线性SVN相结合的方法等对鱼类进行分类;利用形态学运算、金字塔平移等[3]方法去除了背景噪声,然后利用卷积神经网络进行分类。
虽然机器学习和深度学习方法在分类中进行了一些进展,但针对海洋鱼类图像信息特征的敏感性和结果的准确率仍然有待进一步提高。鉴于上述问题,本文提出了一种基于KNN 和Se-ResNet101网络组合的自动鱼类识别方法,首先,执行鱼数据集的可视化分析和图像预处理;其次,Se-ResNet101 模型被构造为广义特征提取器,并且迁移到目标数据集;最后,在Fully connected layer 层的特征信息,对特征信息首先通过KNN分类,得到一个由KNN处理后的结果,在对得到的结果进行卷积上实现鱼类鉴定。本文的主要贡献可以概括如下:
1) 所提出的KNN 和Se-ResNet101 相结合,可以提升小规模细粒度图像分类的效果。
2)基于KNN 和Se-ResNet101 网络的自动鱼类分类方法在NOAA Fisheries 公共数据集上进行了提出和测试,其准确率优于常用方法。
1 材料和方法
1.1 数据集
本实验的数据集由美国国家海洋渔业局(NOAA Fisheries)提供,该数据集由三个部分组成:训练、验证和测试图像集,其中训练集和测试集附带的注释数据定义了图像中每个标记的鱼目标对象的位置和范围,并使用.dat文件格式存储数据。
训练和验证图像集:训练集包含929 个图像文件,总共包括4 172张图像。其中包含1 005条带有相关注释的标记鱼(它们的标记位置和边界矩形),这些标记定义了各种种类、大小和范围的鱼,并包括不同背景组成的部分。147 张海底负片图像是从野生训练和测试图像集中的标记鱼类中提取的(提取了不包含鱼类的区域)。其余3 020 张图像可从OpenCV Haar-Training中获得。
测试图像集:包含在近海底鱼类调查期间使用ROV 的高清(HD;1080i)摄像机收集的图像序列。用于检测的测试图像包括来自ROV 调查的视频片段。共标记了2 061个鱼对象,样本如图1所示。

图1 NOAA Fisheries图像示例
1.2 数据分析和预处理
为了增强分类性能并节省训练成本,有必要预处理实验数据。本研究中图像数据的预处理主要包括图像缩放和图像增强。
1.2.1 图像缩放
在实际数据集生产过程中,所获取的图像数据都是用高清相机在水下拍摄而成,由于设备、环境等因素的影响会导致分辨率偏低,直接使用未经处理的图片会增加训练时长、消耗存储等问题。因此,在本研究中,在模型训练之前将数据集中的原始图像进行图像缩放操作,通过双线性插值重新计算缩放的图像数据,并将每个图像的分辨率调整为256×256像素。
1.2.2 图像增强
图像增强是指有限的数据产生相当于更多数据的值,而不会放大数据集大小。考虑到不同网络结构的输入尺寸是不同的,为了适应不同网络结构的输入并提升模型的泛化能力及其鲁棒性,对原始数据执行以下数据增强操作[4]:使用随机图像差异裁剪图像以将其分辨率重置为224,将图像矩阵标准化为[0-1]的范围,并适度改变图像的饱和度、对比度和亮度。
2 技术分析
2.1 KNN原理及概述
KNN 的分类原理是比较不同特征值的间距来实现的。其基本思路是:一个样本在特征空间中的K个最相似(特征空间中最邻近)的样本中的大多数属于某一个类别,则该待测样本也属于这个类别,其中K通常是不大于20 的整数。在KNN 算法中,样本选取的邻域都是正确分类后的对象。这种方法仅根据最接近的一个或多个样品的类型来确定待分类的分类。
在KNN中,各个对象之间的非相似性指标是通过计算待测样本和已分类K 个样本间距离来实现[5],这种方式可以有效避免对象之间匹配不均的问题,其中距离通常使用曼哈顿距离或欧氏距离,如公式(1)、(2)所示:
欧式距离公式:
曼哈顿距离公式:
其中,它们对向量之间差异的计算过程中,各个维度差异的权值不同,如:
向量A(1,2),向量B(5,10),则它们的:
欧氏距离:L_o=8.9;
曼哈顿距离:L_m=12;
由此可见,向量各个属性之间的差距越大,则曼哈顿距离越接近欧氏距离,且曼哈顿距离得到的样本可扩展性更强。本实验中样本数据量相对较大,则数据属性差异较大,所以本实验选择曼哈顿距离。
2.2 Se-ResNet网络结构
2.2.1 Se-ResNet简介
深度残差网络(Deep Residual Networks) 是目前CNN 特征提取网络中广泛使用的特征抽取方法。它主要作用是在保证高精度的同时降低数据的冗余,并使其具有更深的网络模型结构。
相较于其他网络存在随着深度增加可能带来退化问题、梯度弥散或梯度爆炸[6]等问题,残差网络是一种相对易于优化的方法。它可以利用不同深度的网络结构得到不同层次的多样特征,随着层次的增长,它的抽象层次和语义信息会越来越丰富,图像识别的精度也会越来越高。但同时如果网络层太深,则会占用更多内存,需要更多的时间。
在本研究中选择了ResNet-18、ResNet-34、ResNet-50、ResNet-101 等不同深度的ResNet 作为试验对象,其中ResNet 系列网络中“-”后面的数字代表了层数,同时附加AlexNet、GoogleNet、ShuffleNet 模型作为参照。在选择表现最佳的模型时,通常以模型的收敛速度、大小、效率、识别的均衡性作为衡量标准。
实验中使用一个与众不同的网络设计,考虑通道之间的关系,提出新的结构单元Squeeze-and-Extraction(Se)模块,通过显式建模通道之间的关系来提升神经网络表示的质量,Se 模块的示意图如图1所示。
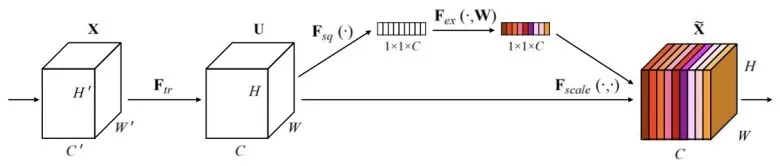
图1 Se模块的示意图
输入一个任意变换的Ftr,如卷积,将输入X 映射到特征图U,U 的大小为H×W×C,然后U 经过一个squeeze 操作,通过聚合特征图的空间维度(H×W),得到通道特征响应的全局分布embedding。之后通过excitation 操作(简单的Self-gating 机制),以上述embedding 作为输入,输出每个通道的modulation 权重,该权重被作用在特征图U 上,得到Se 模块的输出,可以直接送到网络的后续层中。
可以直接堆叠一系列Se 模块得到SeNet,或者替换原有网络结构的模块。同时,尽管构建Se模块的方法是通用的,但是在不同深度使用Se模块的结果是不同的,如在底层使用,更多地融入与类别无关的lowlevel表示,而在高层使用,更多信息与类别高度相关。
目前,新的CNN 系统的设计是一个复杂的工程问题,其中包括了超参量的选取以及网络的组态。可以通过替代已存在的SOTA网络架构,Se模块可直接使用,同时其计算轻量,轻微增加模型复杂度和计算负担。
2.2.2 Se实现方式
一般卷积运算对所有信道进行累加运算,并将信道相关隐含地编码在卷积核内,但与卷积核捕获的空间关联紧密相关。本文旨在明确地建立信道间的相互关系,加强卷积特性的学习,从而使网络能够更好地识别信息的特性,并被后续转换所利用。
squeeze:
全局信息embedding该步骤由全局平均池化实现(这里可以使用更复杂的策略),如公式(3)所示:
全局平均池化公式:
Excitation:Adaptive Recalibration
该操作用于捕捉通道之间的相关性,需要具有灵活性(希望学习通道之间的非线性关系),需要学习anon-mutually-exclusive relationship(希望强调多个通道,而不是得到one-hot activation),如公式(4)所示:
多通道相关性公式:
其中,δ指的是ReLU,W1和W2是两个全连接层,最终以如下形式获得输出(s为excitation 得到scale 因子,u为H×W的特征图):
Se模块输出:
2.2.3 Se模块实例化
Se 模块能够融入像VGG 的标准结构,在每个卷积的非线性后使用。Se 模块能够在各种结构中灵活使用,比如Inception和ResNet。
在Inception中,研究人员试图暴力地提高网络的层次,以提高识别精度,但在复杂问题面前,过于浅显的网络难以取得预期的结果。因此,加深网络依然是目前解决图像分类问题最好方案[7]。但是增加网络很容易造成overfiting,甚至是在训练集上其结果也不如浅层网络,因此,如何有效提高网络层数成为当前深度学习领域的一个重要课题,Se-Inception结构如图2所示。

图2 Se-Inception示意图
为了解决这个问题,研究者提出了一种新型的网络结构Se-Net,这个网络结构可以对所有网络进行改进,做到真正有效地增加层数,无论原网络层数有多深,通过加入Se-Net,都能增加相当数量的深度,有效提高实验效果,Se-ResNet结构如图3所示。

图3 Se-ResNet示意图
2.3 KNN和Se-ResNet组合
图4 为Se-ResNet 整个网络结构模型,首先是一个包含输入、卷积、池化的多层结构模型,每一层都会产生一个特征响应,以及相应的功能转移到下一层结构。完全连接利用多层卷积的方法,对所获得的图像进行卷积处理图像特征。该层结构的特征信息是提取图像的特征向量全连接层作为支持向量的参数输入机器,整体结构如图4所示。

图4 SeResNet-101+KNN组合图
鱼类深层特征的处理是一个非线性分类因此。KNN通过引入核函数对空间进行变换,得到最优分类曲面,将非线性分类问题转化为线性分类问题高维空间中的分类问题。其中在Fully connected layer层的特征信息,首先通过KNN分类,得到一个由KNN处理后的结果,再对得到的结果进行卷积。
3 Se-ResNet系列网络设计与实现
3.1 ResNet系列网络
3.1.1 ResNet基本网络结构
传统的卷积神经网络由于其精度会随着网络深度的增加,准确率逐渐趋于饱和且快速递减,导致其在一些复杂的任务中出现性能上的瓶颈,所以仅靠增加网络层数来实现准确率上升是不可行的。文献[8]证实了这类问题并非过拟合导致的。He 等人[9]针对这一问题,提出一种基于残差结构的深度神经网络。传统的卷积神经网络是用堆栈直接匹配所需要的底层映射,残差网络则利用“快速连接”的模块来实现,如图5所示。
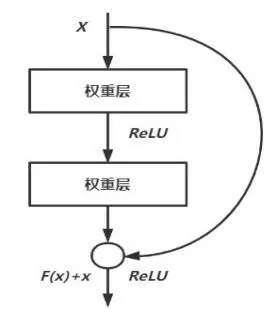
图5 残差模块示意图
假设非线性的叠加层为F(x),拟合目标函数为H(x),传统做法是使F(x) 无限逼近H(x),然而残差结构中采用F(x) 逼近H(x) -x的方式,此结构的好处是深层网络能够等价接收到浅层特征,使浅层和深层得到有效交流。由于网络的正向传输特性,使其在深层不易被忽视,而在逆向传输过程中,则可以将其传递到浅层,有效地克服了网络的退化问题[10]。这样就可以根据实际情况,设计出更大深度的网络结构,以提高网络的性能。对于图5中的残差模块,其拥有两层卷积层和一个快捷连接,如公式(6)。
式中:x、y为模块的输入与输出,Wi为各层的权重,F(x,{Wi}) 是模块需要拟合的映射。层与层之间的激活函数(activation function) 使用线性整流函数(ReLU),如公式(7)所示:
3.1.2 ResNet系列网络
图6描述了ResNet 多个版本的具体结构,所有的ResNet 都分为5 个stage。如ResNet101 所示,Stage 0的结构比较简单,可以视其为对INPUT的预处理,后4个Stage 都由BN 组成,结构较为相似。Stage 1 包含3个BN,剩下的3个stage分别包括4、23、3个BN。

图6 ResNet结构示意图
Stage:
在Stage 0中,形状为(3,224,224)的输入先后经过卷积层、BN 层、ReLU 激活函数、MaxPooling 层得到了形状为(64,56,56)的输出,其他stage同理。
BN(Bottleneck):
在本图最右侧,介绍了2 种BN 的结构。2 种BN分别对应了2种情况:输入与输出通道数相同(BN2)、输入与输出通道数不同(BN1),这一点可以结合改进ResNet图像分类模型[11]。
BN1(Bottleneck1):
BN1 有4 个可变的参数C、W、C1 和S。与BN2 相比,BN1多了1个右侧的卷积层,
令其为函数。BN1 对应了输入与输出通道数不同的情况,也正是这个添加的卷积层将起到匹配输入与输出维度差异的作用(和通道数相同),进而可以进行求和。
BN2(Bottleneck2):
BN2 有2 个可变的参数C和W,即输入的形状(C,W,W)中的c和W。
令输入的形状为(C,W,W),令BN2 左侧的3 个卷积块(以及相关BN和RELU)为函数,两者相加后再经过1个ReLU激活函数,就得到了BN2的输出,该输出的形状仍为(C,W,W),即上文所说的BN2 对应输入与输出通道数相同的情况。
3.2 实验设计与实现
3.2.1 模型设计
本文所提的基于Se-ResNet101 模型和KNN 组合的模式实现海洋鱼类的分类,其中主要的模型设计步骤如下:
Step 1:导入模块:将Se-ResNet101 基础网络和KNN模块导入,并实例化对象。
Step 2:数据预处理:将图像进行缩放和增强,将每个图像的分辨率调整为255×255 像素。使用随机图像差异裁剪图像以将其分辨率重置为224,将图像矩阵标准化为[0-1]的范围,并随机改变图像的亮度,对比度和饱和度。
Step 3:KNN预分类:将full connect layer层数据通过KNN进行预处理进行分类。
Step 4:模型训练:将Step3 处理后的数据进行激活、卷积、池化操作并将结果保存在Res数组变量中
Step 5:取最优K值:将设置K值设置在1~10,并且重复Step3~Step4 步骤。对比数组Res 结果,取最大值作为最优解。
3.2.2 K值选择
在实验过程中KNN 本质上起到了将特征信息预分类的作用,结果如图8所示。从图中可看出,K值在1~11之间不断变化,当K值在1~7时,准确率随着K值的不断增大而增大。当K 在7~11 时,整体的收敛速度明显下降,是1~7 区间的2 倍。当K=7 时,各个网络得到的准确率最高,其中Se-ResNet101准确率达到最高的98.83%,如图7所示。

图7 K-Rate折线图
4 实验结果分析
4.1 模型训练
模型训练环境为centos7,CPU R5 3600X,GPU NVIDIA GTX2060s,32G RAM,2T SSD ROM。按照8:2的比例划分为训练集和验证集,训练模型输入600×600像素的图片6 233张,迭代次数为101次。
4.2 结果分析
4.2.1 实验结果评判指标
在实验中,通过Accuracy、Sensitivity、Specificity、FPR和F1Score评估每个分类器性能。这些指标在评估实验结果方面发挥了关键作用,如公式(8)所示:
(1)Accuracy是一种不计正例或负例的抽样,即正确预测的样本数占总预测样本数的比值,如公式(9)所示。
(2)Sensitivity又叫真正例率,或者真阳性率,它的意义是阳性的那部分数据被预测为阳性。敏感性越高,结果的正确率越高。实际上就是预测正确的结果占真正的正确结果的百分比,如公式(10)所示:
(3)Specificity又叫真反例率,或者真阴性率,它的意义是阴性的那部分数据被预测为阴性。特异性越高,确诊概率越高。实际上就是预测不正确的结果占真正的不正确结果的百分比,如公式(11)所示:
(4) FPR(false Positive Rate) 预测错误的正类占实际负类的比例,即给定数据集标签后,统计出负样本个数即可作为分母,如公式(12)所示。
(5)F1 Score是Precision和Recall的调和平均,Recall 和Precision 任何一个数值减小,F-score 都会减小,反之,亦然。
其中,TP(True Positive)、TN(True Negative)、FP(False Positive)、FN(False Negative),positive和negative表示预测得到的结果,预测为正类则为positive,预测为负类则为negative;true表示预测的结果和真实结果相同,false则表示不同。
4.2.2 实验结果分析
在该实验中,使用卷积神经网络作为提取模块来选择图像特征信息。然后将每个神经网络的特征信息导入KNN 进行分类。特征信息从模型中的第1 层完全连接的图层获取。训练迭代在12次迭代后,大多数模型的收敛趋势放缓。ResNet101+KNN 的收敛在迭代过程中最明显,达到30次迭代后的最小观察值。12型号的平均准确性为97.76%。
如表1所示,Resnet101+SVM实现了最佳识别结果,识别精度为98.83%,F1core 为96.41%,灵敏度为96.38%,特异性为98.77%,FPR 为0.012 4。因为模块在此模型中引入了残差学习。Resnet 允许网络模型层的数量深入而不会进行性能下降。此外,当提取鱼类的特征信息时,网络层的增加导致增强提取图像特征的能力。实验结果表明,Se-ResNet101+KNN模型在该实验中具有最好的识别效果。

表1 Models+KNN结果分析
5 总结
本文提出了一种基于ResNet 系列网络与KNN 结合的海洋鱼类分类方法,该网络结构在分类效果中整体表现良好。单独使用Se-ResNet101 网络识别精度为93.03%,当Se-ResNet101 和KNN 组合时的识别精度可以达到98.83%。因此,该方法提供了一种高精度的模型分类策略,该方法将促进高效分类设备的开发,并为将来提供可行的智能分类方法的策略,具有相当的实际实用价值。此外,该方法对其他海洋生物的分类具有一定的参考意义。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
