
基于注意力机制的SRU模型雷达HRRP目标识别∗
2023-08-04 05:45岳智彬卢建斌
舰船电子工程 2023年4期
岳智彬 卢建斌 万 露
(海军工程大学电子工程学院 武汉 430033)
1 引言
雷达高分辨距离像(HRRP)是目标散射点子回波在雷达视线方向投影的矢量和,它包含了目标尺寸和散射点分布等重要结构信息,并且相比于图像数据,HRRP 易于获取、存储和快速处理[1]。因此,利用舰船HRRP进行目标识别已经成为了雷达自动目标识别的重要研究领域[2~7]。文献[8]将RNN 应用到了HRRP 识别中,取得了较好的效果,文献[9]将RNN 于注意力机制相结合,细化每一段数据识别中所起的作用,提取更为有效的特征,文献[10]采用双向的LSTM 模型,并引入截断的机制选择对于平移敏感性稳健的特征,提高了模型对于平移敏感性的鲁棒性。为了提取对识别更为显著的特征,同时降低运算的复杂度,本文提出了SRU-Atten 舰船目标HRRP 识别方法。该模型将SRU[11]与Transformer[12]中的自注意力模块相结合,通过SRU对HRRP数据进行编码,得到含有局部特征的隐藏状态向量。将得到的隐藏状态向量输入自注意力模块中计算注意力数值,量化HRRP样本中不同距离单元在识别中的作用大小,从而使模型更关注对识别有效的目标区域,提高模型的识别性能。通过堆叠有SRU单元,自注意力机制和前馈神经网络组成的模块构建深层网络,提取深层特征,进一步提高识别效果。
2 模型结构
2.1 HRRP预处理
雷达目标的原始HRRP 数据存在姿态敏感性,幅度敏感性和平移敏感性[13]等问题,这些敏感性对模型的识别性能有很大的影响。所以在使用模型进行识别之前,本文对原始的舰船目标HRRP进行了2 范数归一化来消除幅度敏感性。假设经过幅度归一化之后的HRRP 数据为p=[p1,p2,…,pL]T。其中L为距离单元的个数,pi(i=1,2,…,L)为第i个距离单元的幅度归一化后的数值。在使用对舰船目标HRRP 数据进行目标识别时,要将时域HRRP转化为序列数据之后,输入模型中进行目标的分类识别。
采用文献[9]滑窗方法,将经过幅度归一化之后的HRRP数据转化为序列数据。设定一个滑窗,宽度为d,滑动距离为c:
其中,xl∈ℝd∗1为时刻l的输入,长度为d。矩阵X∈ℝd*T对应的是T 个时间步,每个时间步下的数据维度为d。
2.2 简单循环单元(SRU)模型
图1 为一个时间步下的SRU 单元的运算过程。xt代表t 时刻的输入,xt∈ℝd*1,d 为输入数据的维度。ht和ct分别代表SRU 单元t 时刻的输出和单元状态,ht∈ℝm*1,ct∈ℝn*1,n 是隐藏层单元的维度,m 是舰船目标的类别个数。ft和rt代表t时刻的遗忘门和重置门,其中的σ和g分别代表着sigmoid 激活函数和tanh 激活函数,函数表达式分别为σ(x)=1/(1+exp(-x)),g(x)=(exp(x)-exp(-x))/(exp(x)+exp(−x)),W*表示线性变换。图中的乘法和加法运算都代表着矩阵对应元素之间的相乘。
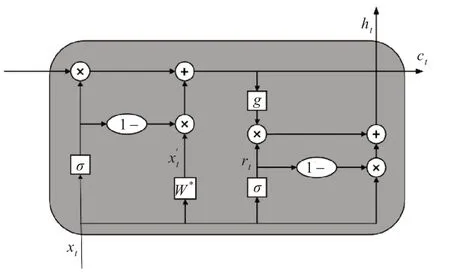
图1 SRU结构单元图
t时刻的输入xt经过一个线性变换得到,同时xt经过遗忘门得到遗忘门的输出ft:
其中Wf是遗忘门的权值矩阵,W为线性层的权值矩阵。遗忘门决定保留数据中对舰船目标识别的重要信息,“忘记”数据中不重要的信息。
遗忘门的输出ft用来调制单元的内部状态ct,结合前一时刻的单元内部状态ct−1和线性层的输出,将保留的重要信息传入ct中,根据ct求出当前的输出结果:
2.3 SRU-Atten模型
本文提出了一种适用于舰船目标HRRP 识别的注意力模型,3 层的模型结构如图2 所示。模型在SRU 网络的基础上,增加了Transformer 中的自注意力模块来衡量每一个时间步的数据在目标识别中重要性,从而使得网络可以自适应对重要的数据部分施加更大的权重。模型的关键部分是由SRU 单元,自注意力单元和前馈神经单元组成SRU-Atten 模块。通过堆叠SRU-Atten 模块,提取易于识别的深层特征。输入序列由N 层SRU-At⁃ten模块编码,得到最终的特征向量,输入到识别网络进行目标分类识别。

图2 SRU-Atten模型
假设将SRU模块运算过程简化为
将得到的h1,h2,…,ht作为自注意力模块的输入,进行注意力的运算。自注意力模块如图3 所示。
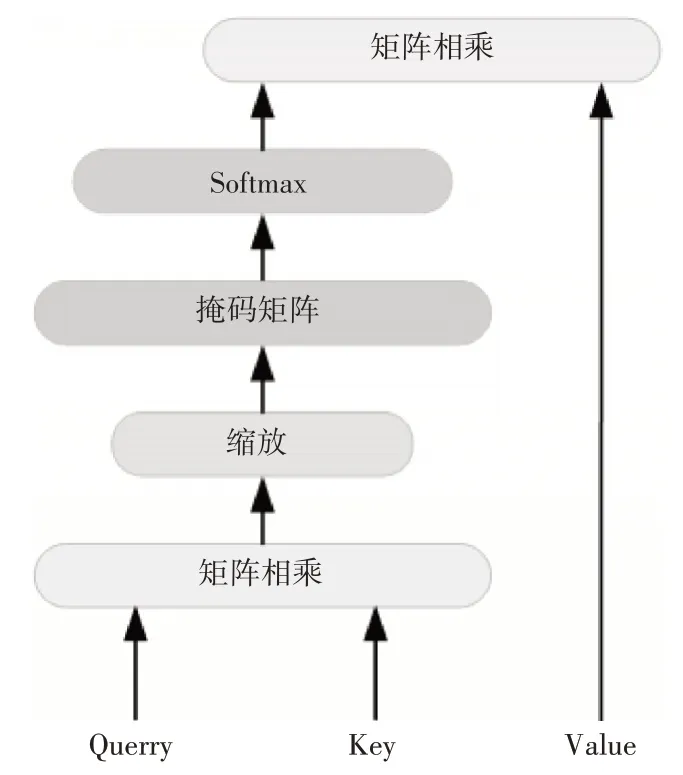
图3 自注意力模块
自注意力模块的表达式如下:
其中Q,K,V 是三个键值向量。dk是K 向量的维数,Q,K,V 是对前一层的输出进行线性变换而得到。通过计算Q 与K 之间的注意力分布,并附加在V 上得到最终注意力值。为了梯度在反向传播过程中的稳定,式(8)中对运算结果先进行了缩放归一化,即除以了
前馈神经网络层主要是利用非线性的激活函数对输出的结果进行特征转化,增强网络的拟合效果,包括两个线性层和一个ReLU 激活函数的非线性层:
所有的单元之间使用了层归一化和残差连接。通过归一化和残差连接处理后,可以有效的缓解训练过程中出现的梯度消失,使网络以更快的速度收敛。以SRU 单元为例,假设输入序列为X,则表达式如(10)所示:
假设SRU-Atten 模块有M 层,将经过最后一层得到的输出结果x1M+1,x2M+1,…,xTM+1经过一个包含单个线性层的网络,最后通过Softmax 函数得到样本属于每一类的概率矩阵:
其中y'表示样本属于每一类舰船目标的概率向量。
识别网络使用交叉熵损失函数,其公式为
其中M 是类别数,是符号函数,如果样本i 的真是类别等于c 是取1,否则取0.pic是样本i 属于类别c的概率。
3 实验结果与分析
3.1 实验数据集介绍
舰船目标多为非合作目标,很难通过实测数据建立目标的HRRP 数据库。本文利用CAD3D 软件建立10种1:1的舰船目标模型,导入CST电磁仿真软件,10 种舰船目标的结构参数如表1 所示。CST仿真参数设置如下:方位角为0°~360°,俯仰角为90°,角度步长为1°;雷达的中心频率为3GHz,带宽为150MHz,极化方式包括垂直极化和水平极化,频率采样点数为360,采用软件默认的最优网格剖析尺寸,选择射线追踪算法进行求解。最终,仿真10种舰船目标的360个方位角的HRRP数据。
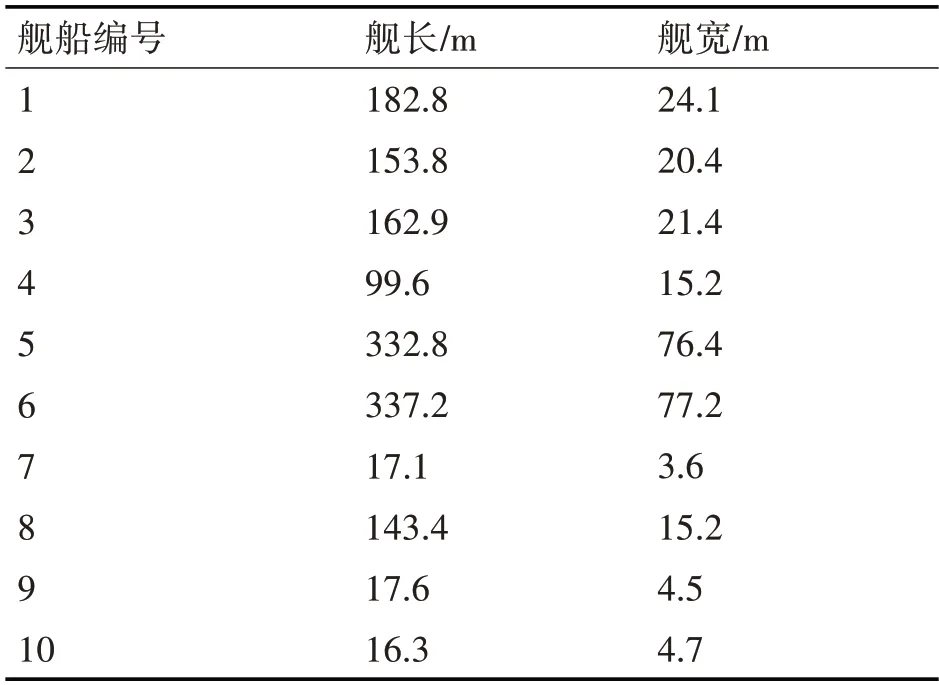
表1 10种舰船目标的结构参数
训练样本匮乏会导致模型的过拟合,用CST仿真的HRRP数量对所提模型来说远远不够,需要对其进行扩充。本文按信杂比大小为10dB,对原始数据分3 次加入符合K 分布的杂波对数据进行扩充,在每个信杂比下将数据扩充3倍。
模型参数设置:训练的总轮数为300,初始学习率为0.03,在训练的过程中每80 轮学习率变为原来的四分之一,隐藏层的维度均设置为128。Transformer 中的多头注意力中自注意力模块的个数为4,优化器选择的是随机梯度下降法(SGD),批大小为32。预处理的滑窗长度d=48,平移距离l=24。
3.2 识别性能
为了探求堆叠层数对识别性能的影响,取层数1~8,识别准确率与层数之间的关系如图4 所示。除了LSTM 模型外,其余模型随着模型深度的增加,模型能够学习到更深层的特征,模型的识别性能也得到了提升。相比于其他模型,本文所提的SRU-Atten 模型,能够在不同深度下都保持较好的识别性能。为了检验模型的最佳性能,本文所使用的模型均是8层。
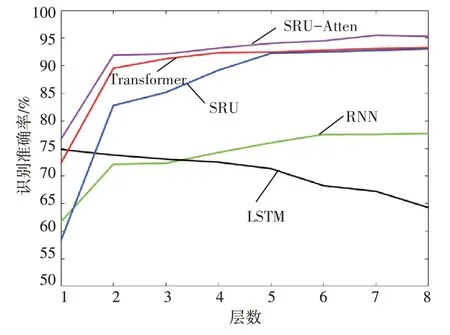
图4 5种模型层数与识别准确率的关系
为了验证SRU-Atten 模型对舰船目标HRRP识别的有效性,将SRU-Atten 模型同RNN,LSTM,SRU和Transformer模型进行了比较,识别结果如表2 所示。从表2 中可以看出,相对于经典的循环神经网络RNN 与LSTM 来说,SRU,Transformer 和SRU-Atten 模型可以更有效地识别目标。SRU 模型改变输入数据流的处理方式,通过构建深层网络提取HRRP 的深层特征。而Transformer 中则是通过多头注意力机制,通过位置匹配,寻找对于检测重要的特征区域。SRU-Atten 模型兼顾了SRU 和Transformer的优点,采用SRU 模型提取HRRP 数据的时序特性,放大每个时间步中易于识别的特征,同时使用自注意力模块来寻找对于识别重要的时间步,得到一组注意力分布函数,对重要特征进行加权放大,更好地识别目标。实验结果证明,SRU-Atten 模型取得了最好的识别效果,相比SRU和Transformer模型,准确率提高了2%~2.5%。

表2 各模型对10类舰船目标的识别结果(%)
3.3 可视化分析
为了直观体现模型提取特征能力,本节将经5类模型提取到的顶层特征和原始HRRP 降维可视化,其二维ISOMAP 可视化投影如图5 所示。十种颜色的散点代表十类舰船目标通过对比,原始舰船目标的HRRP数据不同类别样本重叠在一起,而经过模型提取特征后,相同类别的样本聚集在一起,不同类别样本间的距离在增大,重叠区域在减小,可分性更好。经过RNN 和LSTM 模型提取的特征,相同类别样本聚集不明显,不同类别样本边界重叠,而经过SRU 模型提取的特征,相同类别的样本聚集效果有了极大的提升,更有利于区分目标,但不同类别样本仍有较大的重叠部分,随着模型的改进,Transformer 和SRU-Atten 模型提取特征后,相同类别样本聚集效果越来越好,不同类别样本间的重叠区域越来越小,具有更好的可分性,其中SRU-Atten 模型,通过结合SRU 和Transformer 自注意力模块后提取的目标特征具有最好的可视化效果。
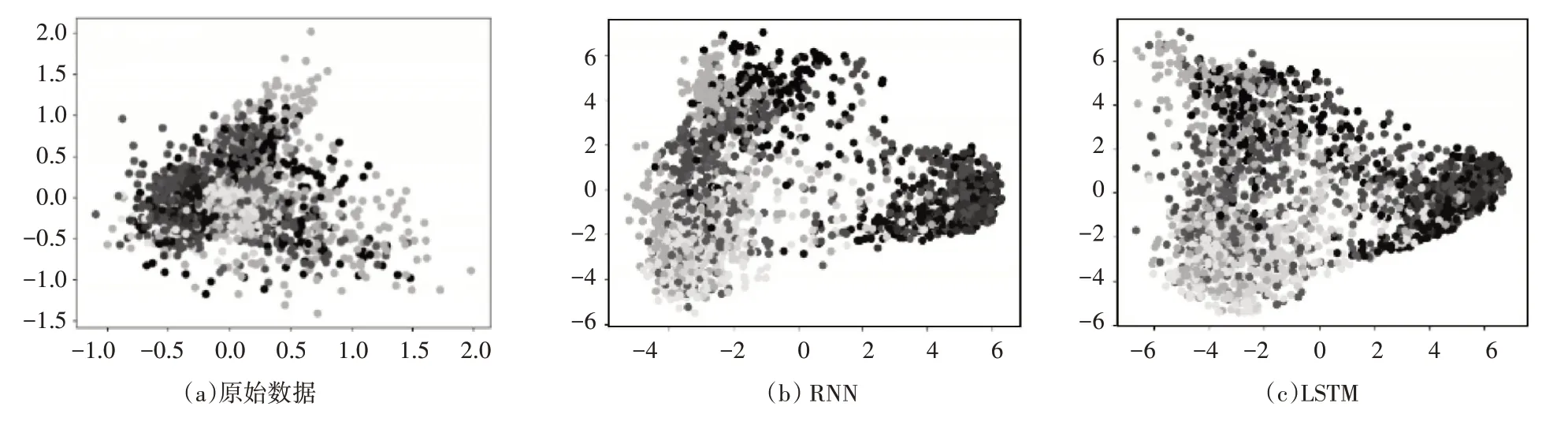
图5 2维ISOMAP投影
4 结语
本文提出的SRU-Atten 模型将SRU 和自注意力机制相结合,利用SRU提取HRRP内部的时序特性,通过自注意力机制提取对HRRP识别有明显作用的重要特征,同时堆叠有SRU,自注意力和前馈神经网络组成的模块提取HRRP是深层抽象特征,并将其运用于目标的识别过程中。实验表明该模型能够提取易于区分的深层特征,有效识别舰船目标。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
小雪花·成长指南(2022年1期)2022-04-09
舰船科学技术(2021年12期)2021-03-29
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
舰船科学技术(2016年1期)2016-02-27
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
