
基于到时时空分布的微震震源定位算法
2023-08-04 03:38:54李明虎
煤矿安全 2023年7期
李明虎,陈 卫,蔡 珣
(1.山东大学 软件学院,山东 济南 250101;2.北京安科兴业科技股份有限公司,北京 102200)
我国冲击地压煤矿较多,随着煤矿开采强度和深度的增加,冲击地压矿井数量和冲击危险程度显著增加[1]。矿山微震监测预警系统的使用对于保证安全生产、提高生产效率意义重大,是冲击地压灾害精准防控的关键。微震震源定位,即根据检波器阵列采集的微震信号,判断矿山微震发生的时空位置,是监测预警工作中的核心问题之一。矿山微震的震相主要是体波,当前我国矿山大多使用单轴检波器,监测竖直方向的振动,拾取的主要是P 波。
微震震源定位算法起源于天然地震的震源定位算法研究,属于被动地震技术。当前主流的微震定位算法有3 大类:基于到时的定位法,如经典盖革(Geiger)算法[2]、单纯形算法[3]、双差定位法[4]等;基于波形偏移定位法,如逆时成像法[5]、震源扫描算法[6](SSA Source Scanning Algorithm)、联合微震映射法[7](CMM Coalescence Microseismic Mapping)等;基于三分量检波器定位法,如单台站法[8]、P 波偏振法[9]等。基于到时的定位算法提出较早,发展充分,计算简单,定位精度较高,是当前生产中应用的主流算法。
根据发展的驱动力,震源定位算法经历了4 个阶段:①理论分析阶段(1912—1970 年):经典盖革法于1912 年提出,本质上是求解超定方程组的最小二乘解,计算量巨大,到20 世纪70 年代计算机技术普及,求解盖革法的数值分析算法才得以在工程上有效实现,这一阶段的主要工作是初步的理论研究;②算法驱动阶段(1970—2005 年):20 世纪70 年代及随后的30 多年中,一系列的算法进入实际应用并获得反馈和提升,如单纯形算法[3]、联合反演法[10]、主事件定位法[11]等,盖革法的思想得到改进和发展,定位精度大幅提高,震源定位算法的核心概念和基本理念大多产生于这个阶段;③计算驱动阶段(2005—2018 年):进入21 世纪,计算机、物联网、数据分析等技术发展提升,天然地震和矿山微震工作积累了更多的数据数量,数据质量也大幅提升,其间更多数据得到分析处理,更加复杂的算法得到实施应用,与其他学科的交叉研究,如二次优化法[12]、贝叶斯理论差分进化[13]、粒子群差分进化[14]等取得进展,这段时间是震源定位技术深入发展的阶段;④数据驱动阶段(2018 年至今):2018 年以后,人工智能技术逐步应用于地球物理学科的各个领域,基于大量数据的有监督学习和无监督学习已经在自动到时拾取[15],自动高分信号提取[16]等方面进行应用,直接或间接提升地震和微震定位的精度,人工智能的发展与地球物理学的应用交叉融合,提升和突破值得期待。综上,首先简要介绍盖革法,说明传统目标函数的全局最优值无法有效指向实际震源点(或其附近);然后通过到时的分布信息和潜在震源点的区域信息构建合理的目标函数,形成新的D4DA 算法;最后在生产数据中对新算法进行验证。
1 基于到时的震源定位算法
1.1 经典盖革法
基于到时的定位算法的基本思想是利用直达波初至和地层速度模型来反演震源位置和激发时刻[17]。到时类算法大多以盖革法为基础,基本原理如图1。
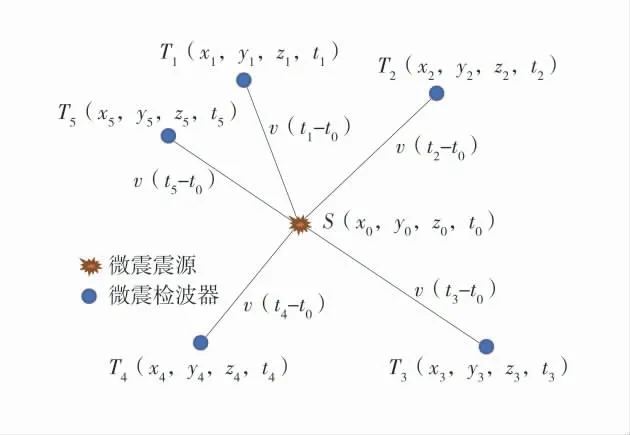
图1 到时不同定位法原理示意图[18]Fig.1 Locating hypocenter by arrival time
S(x0,y0,z0,t0)和Ti(xi,yi,zi,ti)分别为实际震源和第i 个检波器的时空位置,v 为地震波的波速。盖革法的介绍文献较多,如[2,8],简要描述如下:
1)进行到时提取。分析检波器记录信号,确定P波初至时刻。当前,到时拾取工作仍然需要一定程度的人工参与。
2)确定目标函数。计算潜在震源到各检波器的距离di,结合波速v 计算地震波走时tgi,tgi与起震时间ts的和记为计算到时tci,即tci=ts+tgi,理想情况下,计算到时tci应当与观测到时toi相等。设所有检波器计算到时向量tc与观测到时向量to的差向量为a(记为到时偏差),即a=tc-to,使用a 的函数,如1-范数和2-范数。
3)优化目标函数。选择合适的反演策略找到最优的起震时间和震源位置。一般采用数值分析的方法,针对所使用的观测数据类型、物理方程及约束条件等因素,选择最优反演策略以避免收敛到局部极值,并且快速、准确地找到最优解。
实际微震波传播过程中,会受自然地质、工程采动等因素的影响,传播介质并非均匀,更非各向同性,因此,实际微震波的速度场是非均匀且各向异性的,为了聚焦在问题的主要方面,这里采用均匀且各向同性的速度场。当前,完全依赖算法的定位结果精度一般不会很高,误差多在20 m 量级或以上,会出现明显违背常理的结果。生产中进行震源定位时大多需要人工干预,如选择合适的监测信号、进行适合的滤波、选择合理的通道数或去除不合理结果等。提高定位工作的精度和智能化程度一直是震源定位工作的目标。
1.2 L1 和L2 目标函数
设起震时刻为ts,第i 个检波器的观测到时、走时、计算到时为toi、tgi、tci,有tci=ts+tgi。
定义L1目标函数(1-范数)为:
L2目标函数(2-范数)为:
式中:L1、L2为目标函数,ms;n 为检波器个数;abs(·)为取绝对值;tci为计算到时,ms;toi为观测到时,ms。
2 个目标函数性能优良,在人工智能、模式识别等学科中应用广泛,基于到时的定位算法大多使用2 种目标函数或其变体。由二者的定义可知,L1对每个检波器的偏重是一样的,而L2更加偏重于误差较大的检波器。L2在定义域上连续可导,L1连续,但存在不可导的点。L2在优化方法适应性上优于L1。
2 D4DA 算法的思路与实现
2.1 传统震源定位算法中的偏离问题
盖革法的基本假设是目标函数最优值在实际震源点附近。然而,目标函数全局最优值可能离实际震源点很远,即使只是在理想情况下加上非常小的扰动,全局最优值也可能以较高的概率对实际震源点有非常大的偏离;实验表明偏离是普遍的,在实际生产量级的扰动下,伪震源点占比可能达到10%甚至40%以上。
在目标函数普遍偏离的情况下,优化算法失去真正的目标,难以取得好的定位结果。需要技术人员结合现场情况进行经验判断才能进行较好的震源定位。
2.2 目标函数Ls 的构建
新目标函数构建的思路:使用到时偏差的分布信息确定单个潜在震源点的基础目标函数;使用潜在震源点邻近的时空区域信息构建最终目标函数。
具体构建包含3 个步骤,①确定到时偏差的尺度;②计算到时偏差的似然函数作为单点目标函数;③使用区域信息计算目标函数。
2.2.1 确定到时偏差的尺度。
由ai=tci-toi=ts+tgi-toi可知,到时偏差ai的方差可由式(3)进行计算。
式中:σi为到时偏差ai的标准差,ms;σs为起震时刻标准差,ms;σgi为走时标准差,ms;σoi为观测到时标准差,ms。
检波器的空间位置固定且到时拾取算法确定时,通过随机变量S(x0,y0,z0,t0)计算σs、σgi、σoi,进而计算σi,需知道S 在4 维时空的分布,这需要精准的地质、采动的模型进行演绎或大量的S 和观测到时向量to的对应数据进行归纳,二者都是无法做到的。
分析σi的使用需求和σs、σgi、σoi的特点来寻求σi的合理近似。各个检波器到时偏差的标准差σi是为了让不同检波器通道上的到时偏差可以相互比较,σi的相对大小更有意义,各σi同步的缩放不会对后续目标函数的相对大小产生影响,也就不会改变目标函数最优值点的坐标即震源;起震时刻对各检波器是独立的,从而各个检波器的σs是相同的,这即是σs没有脚标i 的原因;观测到时的偏差来源于到时拾取的方法和检波器的位置,到时拾取的方法与检波器独立可忽略,检波器的位置对观测到时标准差σoi和走时标准差σgi的影响是一样的。综合上述,在式(3)中忽略σs,把σoi替换为σgi,得σi≈2 σgi,进一步忽略系数2,得式(4)。
式中:σi为到时偏差的标准差,ms;i 为检波器编号;σgi为走时的标准差,ms;std(·)为取标准差;tgi为走时,ms。
式(4)表明,如果求得随机变量tgi,则到时偏差的尺度问题即告解决。理想情况下求tgi需要震源在三维空间的分布,实际计算时也是需要合理的简化。检波器台网布设主要关注微震易发区域,危险区域周边应尽量在空间上被候选点均匀包围[18],这就提示,可以构建以各检波器的形心为中心的适当间距扩展的栅格,通过栅格点来构建随机变量tgi。这种方法另外的2 个优点:①潜在震源位置受各检波器的影响相似;②相对于边缘点,形心附近的潜在震源位置变化时tgi会有合理的波动。
实际计算σi所使用的形心法如图2。
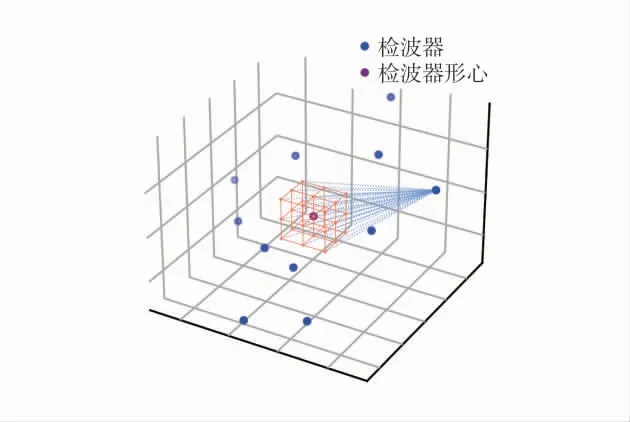
图2 形心法计算到时偏差的标准差Fig.2 Calculating standard deviation of arrival time deviations by the centroid-method
如图2,以所有检波器的形心为中心,以Δd=Δt×v(Δt,v 分别是采样时间间隔和波速)为间隔,沿着3 轴6 方向分别对外扩展n 个步长,形成(2n+1)3的网格,计算每个节点到各个检波器的走时tgi,计算tgi的标准差σgi,依据式(4)将σgi当作σi来使用。可适当调整n 的值,使得各通道tgi的标准差的平均值与Δt×v 相当,实际应用时,n 的值一般取5~25,对应的空间立方区域的边长大约是40~200 m,范围过小则σi之间的比例波动剧烈,范围过大则各σi趋于相等。
2.2.2 计算到时偏差的似然函数
对传统定位算法分析发现,L2的表现好于L1,说明到时偏差大的分量应当赋予更大的权重。对a=tc-to,假设a 各分量间相互独立,且到时偏差的每个分量ai=tci-toi符合正态分布,则可用式(5)的似然函数描述到时偏差的不确定性,并记为Lp目标函数。
式中:Lp为似然函数即单点目标函数;p(·)为取概率密度;a 为到时偏差,ms;n 为检波器个数;tci为计算到时,ms;toi为观测到时,ms;K 为归一化因子;ai为到时偏差a 的第i 个分量,ms;σi为到时偏差的标准差,ms。
相比于L1、L2目标函数,因为σi的引入,Lp目标函数考虑了偏差的尺度信息,不同检波器之间的差异有了可比性,使得到时偏差的意义更加明确。
2.2.3 使用时空区域信息计算目标函数
对于实际震源点,如果时空坐标发生较小的扰动,目标函数会以相对和缓的方式进行减少。对于伪震源点,其时空坐标的目标函数只是“恰好”在某一个位置较小,如果时空坐标发生较小的扰动,那么目标函数将会发生比较大的变动。表明将某个时空坐标附近多个点的目标函数进行聚合,以聚合值作为总体目标函数将会使算法有更好的鲁棒性。
具体地,Ls目标函数采用如下的方式进行构建,设检波器采样间隔为Δt,以潜在震源点S(xq,yq,zq,tq)为中心,空间上以Δd=Δt×v 为间隔沿3 轴6 向各外扩展n 个步长,时间上以Δt 为间隔向前后各扩展n 个步长,形成(2n+1)4的4 维时空网格,对每个网格节点,计算其Lp目标函数。聚合权重可为等权相加,如式(6),也可取4 维高斯卷积核。
式中:Ls为4 维区域目标函数;q 为4 维区域内网格节个数;Lpi为单点目标函数。
需要说明的是:①形心法确定偏离方差时使用3 维空间区域,且只需要计算1 次,Ls使用4 维时空区域,且需要对每个潜在震源点进行计算;②Lp目标函数比L2目标函数略复杂,但都是O(n)级别,Ls目标函数的复杂度为O(n×m4),其中m 为时空区域核的宽度,由于幂次较高,m 取值不可太大,当n 取2 时m 为5,Ls的计算量是Lp的625 倍;③在形心法和Ls计算时,都使用了Δd=Δt×v 计算空间栅格的间距,空间间距本质上是由微震信号的采样时间间隔Δt 确定的,微震波在此期间行进了Δt×v 的距离,即速度是时间与空间的纽带。
2.3 D4DA 算法
D4DA 算法流程图如图3。
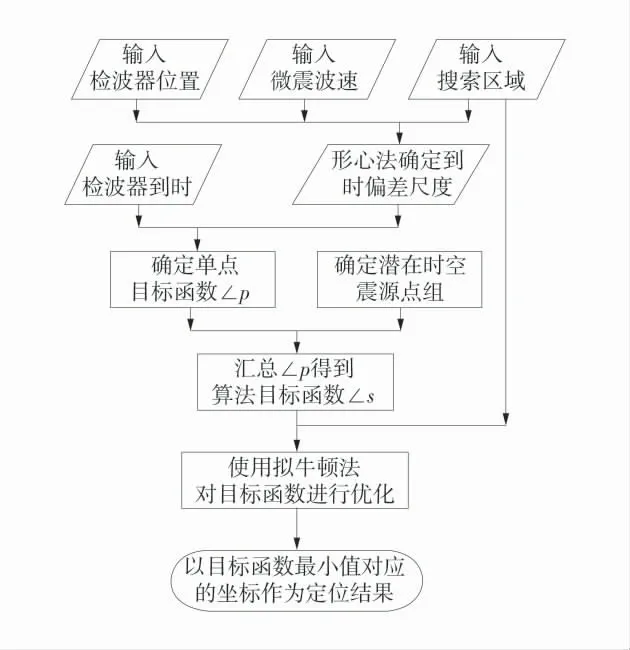
图3 D4DA 算法流程图Fig.3 Flowchart of D4DA algorithm
算法输入包括各检波器位置Ti及其观测到时toi、波速v、搜索区域R。首先,用形心法计算到时偏差标准差σi作为各检波器到时偏差的尺度;然后,按2.2 节“使用时空区域信息计算目标函数”方法确定潜在时空震源点组,按式(5)确定单点目标函数Lp并按式(6)汇总得到算法的目标函数Ls最后,使用拟牛顿法在潜在搜索区域R 中得到使得目标函数最优值的时空坐标Sc,输出Sc作为定位结果。
3 数值实验与结果分析
3.1 数据设定
使用文献[19]中第五章的空间数据,包括16 个检波器和12 个炮点的位置坐标,划定搜索空间为可以包含所有检波器和炮点的、最小的长方体向3 轴6 向外侧各扩展200 m 的长方体的范围。选取这里的数据是因为其搜索空间较大,有较好的深度跨度;有12 组标定炮数据,16 个检波器,数据充分,容易体现出统计特征,便于发现规律。检波器和标定炮坐标可见原文献。潜在震源点的搜索范围见表1。

表1 仿真数据的搜索区域Table 1 Search area in simulation data
对于遍历搜索,各坐标间隔取7 m,立方对角间隔为12.12 m 可以满足绝大多数生产环境中的定位粒度要求。此时每次需要计算30 945 110 个候选震源点。使用Numpy 包进行计算,如果有16 个通道拾取了到时,一次定位需要约20 GB 内存,在i7-8700K 处理器上运行约60 s。
到时数据的生成:取起震时刻ts为1 000 ms,取各向同性的均匀波速场且波速vp为3.75 m/ms,根据炮点和各检波器的坐标计算距离di,得走时tgi=di/vp,由式(7)生成观测到时。
式中:toi为观测到时,ms;i 为检波器编号;ts为起 震 时 刻,ms;tgi为 走 时,ms;r 为 信 号 干 扰 强 度;norm(0,1)为标准正态分布发生器。
理论观测到时为起震时刻加走时,实际观测到时为理论观测到时加入强度为r 的标准正态分布随机扰动。偏离存在性验证时r 取1‰,偏离普遍性验证时r 分别取1‰、1%、10%及50%。一般认为,生产环境中,干扰强度至少在10%以上,1‰和1%的干扰属于理想情况,生产中不可能做到。
3.2 定位算法的求解
拟牛顿法是高效的代数类优化算法,适应性强且收敛速度快,其基本原理可参考数值分析的书籍,主流的数值分析工具如Matlab、Scipy 中都有拟牛顿法的实现。实际生产中,典型的经典盖革法,使用拟牛顿法对L2目标函数进行优化。
遍历搜索法以一定的粒度在搜索区域内遍历离散网格,对每个网格点的目标函数进行计算,搜索最优值。遍历搜索法存在着粒度与计算能力的矛盾,粒度过粗无法满足生产要求,粒度过细则过于消耗算力,无法在合理的时间给出计算结果。对于长宽深各3 000 m 的空间,如果做到直线10 m 的精度,在实验室环境的主流服务器上运行1 次L2目标函数的遍历搜索是百秒量级,生产环境下遍历搜索法显然不能使用。遍历搜索法可以提供空间的整体信息,生成用于对比和验证的基线,防止算法收敛于局部最优。相比于其它优化算法,遍历搜索法更多用于研究探索,不太适合于生产实践。
3.3 偏离存在性的验证
对第1 次标定炮,干扰强度r 取1‰,以不同的随机种子按式(7)生成3 组到时数据,分别取L1、L2和Ls目标函数,拟牛顿法定位情况见表2,遍历搜索法定位情况见表3。

表2 拟牛顿法定位情况(1‰正态扰动)Table 2 Locating results of quasi-Newton method(1‰ normal disturbance)
表2、表3 的数据很好地支持了全局最优值可能会离实际震源点非常的远的结论。对第2~第12次标定炮,进行了同样的实验,可以发现:
1)L1、L2和Ls目标函数的伪震源点是存在的。
2)遍历搜索可以发挥基线的作用。遍历搜索法不存在陷入局部最优的问题,可以保证给出“不会太差”的优化结果,遍历搜索法在各种情况下都给出了伪震源点。
3)L1目标函数不适合拟牛顿法,多收敛到局部最优。L2和Ls目标函数有更好的一致性和稳定性,L2和Ls目标函数在两个优化算法中都找到了伪震源点。
4)表2 中的L2目标函数被拟牛顿法优化即是典型盖革法,Ls对应的即是D4DA 算法,在仿真数据上D4DA 算法的表现略好。
3.4 偏离普遍性的验证
使用上节的3 组数据相同的随机种子,干扰信号强度r 分别取1‰、1%、10%及50%时进行遍历搜索。不同等级扰动下的伪震源点占比(搜索点数:30 945 110 个)见表4。

表4 不同等级扰动下的伪震源点占比(搜索点数:30 945 110 个)Table 4 Proportion of pseudo hypocenters under different disturbances(searched in 30 945 110 points)
可以看出:仅1‰的正态扰动下,L1、L2和Ls目标函数的伪震源点数量即非常可观,随着干扰的增大,伪震源点占比急剧上升,伪震源点是普遍现象。Ls的伪震源占比明显小于L1和L2,与Ls目标函数构建时对时空区域信息的使用的预期相符。另外,由表2、表3 可知:Ls6 次实验都收敛到伪震源,且定位误差波动较小,说明Ls目标函数鲁棒性较好。
4 现场应用
某矿采用北京安科兴业技术有限公司的微震监控系统,系统正常运行后,选择在1604 工作面两巷道的生产帮煤体中打孔,2 次炮孔位置分别选在回风巷和运输巷,炮点及检波器位置见表5。

表5 某矿1604 工作面炮点及检波器位置Table 5 Blast positions and detector positions of the 1604 working face in a certain mine
运输巷标定炮的微震信号被1#~6#和8#检波器有效拾取,回风巷标定炮的微震信号被1#~6#和8#~9#检波器有效拾取。
分别采用典型盖革法和D4DA 算法对2 次标定炮进行定位,2 种算法分别使用L2目标函数和Ls目标函数,都使用拟牛顿法进行优化。定位结果如下:
1)回风巷。①典型盖革法:定位震源点坐标(38 448 402.45,3 911 206.75,-438.36),发震时刻580.43 ms,偏离18.13 m;②D4DA 法:定位震源点坐标(38 448 402.38,3 911 207.05,-438.64),发震时刻580.41 ms,偏离15.61 m。
2)运输巷。①典型盖革法:定位震源点坐标(38 448 388.53,3 911 035.21,-436.97),发震时刻556.62 ms,偏离11.38 m;②D4DA 法:定位震源点坐标(38 448 388.33,3 911 036.00,-437.62),发震时刻556.76 ms,偏离8.41 m。
可以看出:Ls目标函数较普通的L2目标函数有更好的定位结果。
5 结 语
1)基于到时的震源定位算法理论成熟、定位精度高,是业内使用的主流算法。基于到时的震源定位算法中伪震源现象是存在的,而且是普遍的。提出了伪震源点占比的计算方法,并以此对定位算法中的目标函数进行定量评估。构建了基于分布信息和区域信息的Ls目标函数,进一步形成D4DA 算法,并在生产数据中对D4DA 算法进行了验证。
2)分布信息和区域信息的使用是D4DA 算法的核心,在这2 种信息的使用上进行了初步的尝试,相信更深入的研究会给震源定位工作带来新的思路。到时类定位算法研究充分,有许多目标函数的构建思路和优化算法,如双差法、单纯形法等,这些方法与分布信息和区域信息相结合,有望提升震源定位精度,更好地保障煤矿生产安全。
猜你喜欢
新疆钢铁(2021年1期)2021-10-14 08:45:48
魅力中国(2020年46期)2020-02-02 11:50:08
信息技术时代·中旬刊(2019年1期)2019-10-21 21:18:52
电子测试(2018年6期)2018-05-09 07:31:34
石油地球物理勘探(2017年4期)2017-12-18 07:14:33
知识经济·中国直销(2017年11期)2017-11-28 05:34:18
中国煤炭(2016年1期)2016-05-17 06:11:34
华北地质(2015年3期)2015-12-04 06:13:25
物探化探计算技术(2015年2期)2015-02-28 17:42:56
四川建筑(2013年6期)2013-08-15 00:50:43
