
土壤肥力与农作物科学施肥管理融合知识图谱构建与可视化
2023-08-02 12:18:30张彩丽吴赛赛
农学学报 2023年7期
张彩丽,吴赛赛,李 玮,王 慧,陈 磊
(1安徽省农业科学院农业经济与信息研究所,合肥 230031;2中国农业科学院农业信息研究所,北京 100081;3安徽省农业科学院作物研究所,合肥 230031;4安徽省农业科学院土壤肥料研究所,合肥 230031)
0 引言
随着计算机技术和生物学研究的快速发展与相互间的融合,由两者引领的农业科学技术变革引发世界范围的响应,而由此产生的生物信息及数据已至“海量”并仍指数式突破[1-2]。在以往科学研究过程中,一方面科学数据位置分散,其保存和展示方式不太一致,这种数据组织方式与科研工作者的需要不能成功对接;其二,小型科研项目产生的数据在数据格式、存储方式、数据类型、产生方式等方面有较大差异,数据之间无法达到某种程度上的统一,产生了一个个信息上的盲区[3-4]。而在图书情报学与计算机科学研究人员的共同努力下,藉由关联数据与知识库建设的发展,这些问题逐步化解[5-7]。
与此同时,知识图谱(knowledge graph)因具有动态性、直观性、有效性,可以展示知识及其内外部联系,而逐步来到大众视野[8-9]。近年来随着自然语言处理等技术的成熟,知识图谱慢慢在互联网上得到深度发展与应用,从提取文本中特定类型实体、关系、事件向深度发掘大数据中实体信息方向不断进化[10-11]。然而数据的中心化和冗余问题,一定程度上影响了知识图谱的快速发展。近年来,万维网之父Tim Berners-Lee提出了去中心化技术规范Solid,致力于推动互联网的去中心化,这对于知识图谱的融合发展具有重要意义[12]。
目前国内的知识图谱研究按照应用领域主要分为企业界和学术界。当前国内企业界对于知识图谱的研究非常活跃,特别是一些大型的互联网企业,由于知识图谱能描述实体间交错互联的关系对企业产生的应用价值,对于知识图谱的需求非常强烈。而国内学术界对于知识图谱的研究则更倾向于技术性,即知识图谱中的关键技术及其实现等方面的研究。所以目前国内真正实现落地的知识图谱研究,更多的是集中在可以迅速产生经济效益的领域,比如生物医药、电商、金融、创投、旅游等领域[13-17]。这一方面说明知识图谱的确可以创造经济效益,也获得了市场的认可,这对于知识图谱的研究发展是非常有利的。另一方面,知识图谱人才和研究热点的不均衡会加剧。对于一些基础性的、非盈利性的知识图谱研究,可能会陷入无人问津的境地,这对于行业的均衡发展是不利的。因此为了知识图谱的长足发展,一方面需要学术界承担起拓展知识图谱研究领域的责任,另一方面也需要国家相关政策的倾斜和支持[18]。
在农业知识图谱方面,目前相关研究较少,而在土壤肥力这个具体方向上,仅见少量与土壤相关的知识图谱研究[19],而土壤肥力的研究几乎没有。与此同时,构建知识图谱中的本体知识库基本框架的辅助资料——土壤肥力叙词表或主题词表也非常稀少[20]。但欣慰的是,1980—1996 年完成了全国第二次土壤普查,在土壤肥力指标方面有可观的数据资源;在科学施肥方面,测土施肥专家决策系统的开发研究已取得一定成果[21-24]。然而,近几年测土配方专家决策系统的建立和推广并不十分顺利,一方面与地块小且零散、增加了农民种地成本、配方肥生产销售不到位等有关,另一方面与专家决策系统的功能和查询效率及智能水平有关。因此,建立智能化、可视化水平更高、更“聪明”的土壤肥力知识图谱势在必行。建立土壤肥力与农作物施肥管理领域知识图谱,一方面可提供土壤肥力与科学施肥知识图谱的智能知识服务方案,将信息资源转化成知识[25];另一方面可有效地将土壤肥力与科学施肥知识连接并形成推理,可以促进挖掘土壤肥力与科学施肥之间的内在联系,从而支持基础研究的跨越式前进。
由此,笔者以安徽省为例,结合对土壤肥力与科学施肥管理领域知识服务需求的调研,利用大量文献资料[26-27],以及土壤肥力与科学施肥专家验证等方式设计领域知识服务驱动的土壤肥力与科学施肥本体模型;在本体的基础上,利用命名实体识别、关系抽取等技术构建土壤肥力与科学施肥管理知识图谱,以期实现对土壤肥力与科学施肥领域海量数据的语义化处理和存储,搭建面向领域知识服务、融合测土配方施肥决策系统的土壤肥力与科学施肥管理智能服务平台,以期实现土壤肥力与科学施肥管理的知识探索、推理、查询等智能化功能[28],促进大数据与人工智能现状下土壤肥力与科学施肥管理知识组织及使用方式的革新,加快传统农业研究范式的升级。
1 土壤肥力知识图谱构建
土壤肥力知识图谱的构建选择自顶向下的方式,构建过程中包括概念层与数据层2 个部分,其中概念层是数据的模板范式,数据层则是具体数据填充。首先结合专家定义和数据内容,构建土壤肥力领域本体(概念层),然后在本体的基础上,根据领域数据特征,通过IDW(反距离加权)插值—数据清洗—数据标注—命名实体识别—属性关系抽取等操作,得到相关三元组数据,存储到Neo4j 图数据库中形成安徽省土壤肥力知识图谱,同时可以进行可视化操作以及特定的知识推理过程,具体流程见图1。

图1 土壤肥力知识图谱构建流程
1.1 土壤肥力领域本体构建
构建领域本体的方法学问题在领域内目前是热点方向之一,但研究至今仍无系统的、工程化的、可以覆盖全部领域的构建方法。该研究根据构建安徽省土壤肥力知识图谱的目的和使用范围,以及领域专家建议,采用人工构建的方法,使用Protégé本体库构建工具构建安徽省土壤肥力领域本体,其本体层次如图2所示。

图2 土壤肥力领域本体类层次
土壤肥力领域本体的层级包括:(1)土壤肥力知识图谱;(2)行政区域、土壤肥力、施肥管理及常见农作物;(3)行政区域包括省、市、县/区、乡镇/街道等,土壤肥力包括pH、有机质、全氮、全磷、全钾、有效氮、有效磷、粘粒、粉粒、砂粒等,施肥管理包括氮、磷、钾肥,常见农作物类为小麦、水稻、玉米、油菜、马铃薯、棉花、花生、大豆等。
构建本体时,针对某个概念的建模允许有一些不同选择。而概念描述由于本体存在自高层到低层、自低层到高层2 个方向,因此存在描述的不匹配问题[27]。本研究采用领域专家协作人工构建的方式构建本体,其概念层(图3)的匹配问题在构建时已经统一,但以后在与其他应用系统之间进行信息交互时需要考虑本体概念层的异构问题。
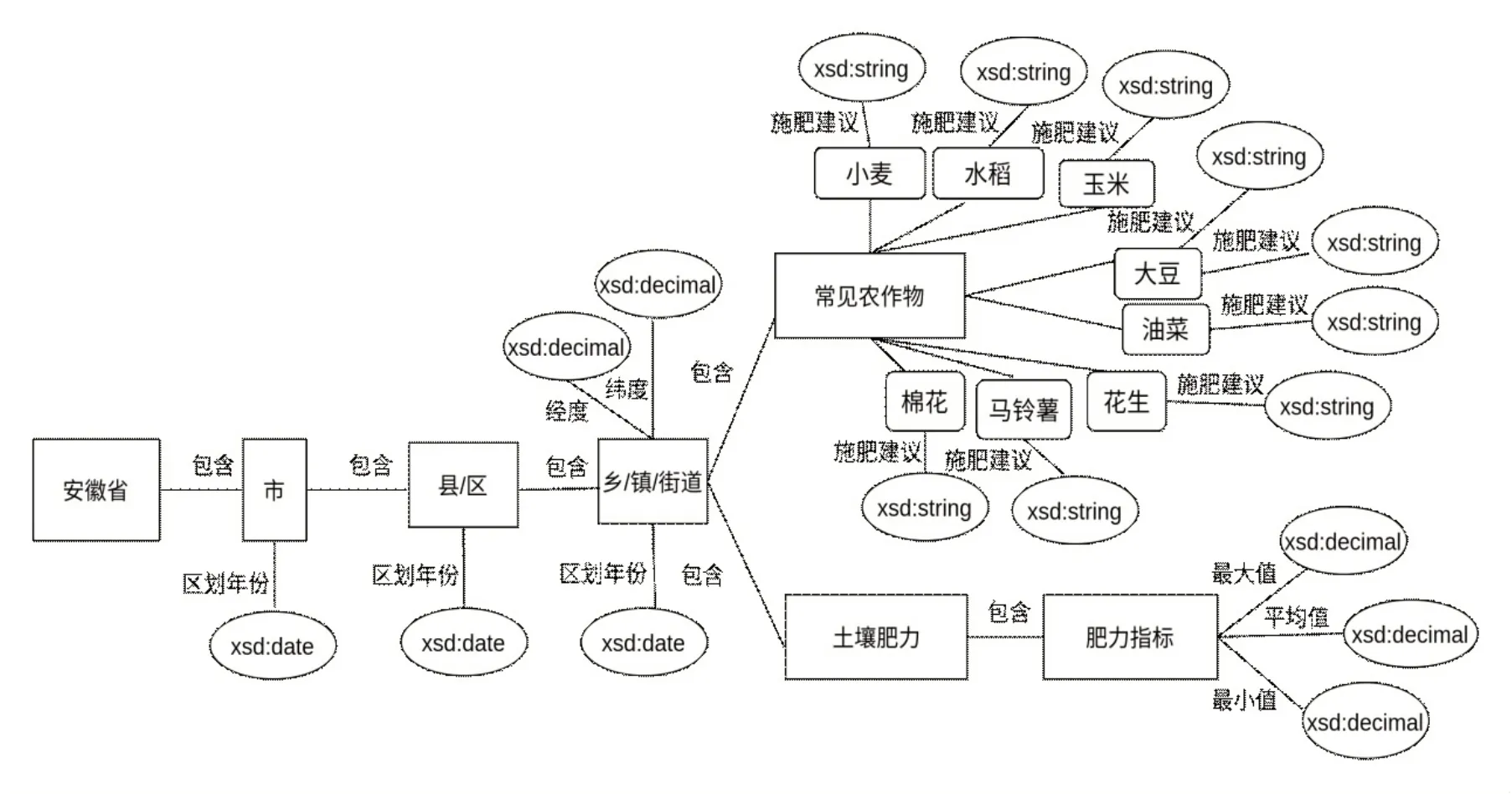
图3 土壤肥力领域本体概念层
1.2 数据处理方法
研究的数据来源有3类。(1)全国第二次土壤普查安徽省1:400 万土壤全氮、全磷、全钾、pH、有效磷、有效氮、有机质、粘粒、砂粒、粉粒分布图(1980—1996)的相关信息与数据,这些数据从国家科技基础条件平台——国家地球系统科学数据中心平台申请得到(http://www.geodata.cn)。(2)安徽省土壤肥力相关主题与常见农作物施肥管理政策相关主题期刊文献。(3)包含安徽省特定区域土壤肥力数据的测土配方查询系统的网络数据。平台申请得到的数据基本结构比较固定,属结构化数据;而其他类型属于半结构与非结构化数据。利用反距离加权插值法对结构化数据进行信息提取,其他2种类型数据通过深度学习模型提取命名实体与实体间关系。
1.2.1 反距离加权插值法 全国第二次土壤普查中,安徽省的土壤普查数据侧重不同土种的理化性质(土壤肥力指标),数据多是不同地区多个样点的平均值,无法与镇/乡级的地址对应。另外,安徽省行政区划多年来变化也很大。因此,根据安徽省1:400万土壤全氮、全磷、全钾、pH、有效磷、有效氮、有机质、粘粒、砂粒、粉粒分布图(1980—1996)的数据特征,选择反距离加权插值法插值出安徽省各市县土壤全氮、全磷、全钾、pH、有效磷、有效氮、有机质、粘粒、砂粒、粉粒的点数据。反距离加权(Inverse distance weighted,IDW)插值法由美国国家气象局于1972年第一次提出,其逻辑支撑是地理学第一定律——相近相似原理[29-32]。IDW插值法计算如式(1)。
式中,Z(X0)为估测点X0属性值,Z(Xi)为估测点X0周边区域内第i点Xi的属性值,n为局部邻域内点的个数,Wi为Xi点对于X0点的权值。
1.2.2 基于深度学习的有监督实体关系抽取方法 命名实体识别及关系抽取是信息抽取、自然语言理解、信息检索等领域的核心任务与重要环节。实体自自然语言文本里被抽取后,其间的关系也依次被抽取出来。实体对之间的内在联系一般被组织化为关系三元组(e1,r,e2),e1、e2为实体,r为目标关系集R{r1,r2,r3,...,ri}[33]。
分别采用ERNIE-BiLSTM-CRF 模型与PCNNAttention模型来实现土壤肥力命名实体识别与土壤肥力关系抽取任务。2个模型的训练数据采用的是国内土壤肥力期刊文献的txt文本进行实体和关系标注,标注后的文本共计为1036 篇。土壤肥力期刊文献的获取过程为:采用检索式“SU=(土壤)*(土壤肥力+测土配方+养分+全氮+全磷+全钾+pH+有效磷+有效氮+有机质+粘粒+砂粒+粉粒)NOT TI=(订阅+订购+征文+征稿+稿约+声明+启事+通知+须知+通讯+论文索引)”在中国知网上进行专业检索,期刊出版时间始于1980年1月1日,终于2021年5月31日。
深度学习模型ERNIE-BiLSTM-CRF 的实体识别过程主要为:(1)使用ERNIE 模型获得目标文本的字向量;(2)输入字向量至双向LSTM模型中捕获上下文特征,获取更长距离的语义信息;(3)通过CRF解码得到数据,训练、学习取得标签转移概率与约束条件,得到各标签的类别信息。取得的准确率为95.44%,召回率为97.10%,F1值为96.26%。
基于PCNN-Attention 模型的关系抽取任务:PCNN即是在CNN(卷积神经网络)模型上的改进,抽取关系时,因CNN 中的max-pooling 层需要对全部卷积层数据处理,导致对关系与实体的结构提取效果不高;而PCNN 把每个卷积核输出的结果分成3 段分别进行max-pooling操作,对于关系抽取的效果有了很大提升。同时引入Attention机制为每个示例赋予权重,很大程度上遏制噪声数据对模型的影响。结果的准确率为85%,召回率为78%,F1值为80%。
1.2.3 基于规则模板的信息抽取 测土配方查询系统的常见数据格式见表1[21](目标产量为6750 kg/hm2的中等肥力水平的水稻土壤肥力指标情况)、表2[21](推荐施肥量)与表3[22],数据格式基本属于半结构化数据。通过实践发现,可以利用这些半结构化特征构造相应规则进行信息抽取。因此采用基于规则模板的正则表达式来抽取测土配方查询系统中相关数据,如提取三元组(均溪镇红星村,有机质,20.8 g/kg)、(均溪镇红星村,有效磷,69.3 mg/kg)、(均溪镇红星村,速效钾,39 mg/kg)等。

表1 测土配方查询系统数据格式1

表2 测土配方查询系统数据格式2
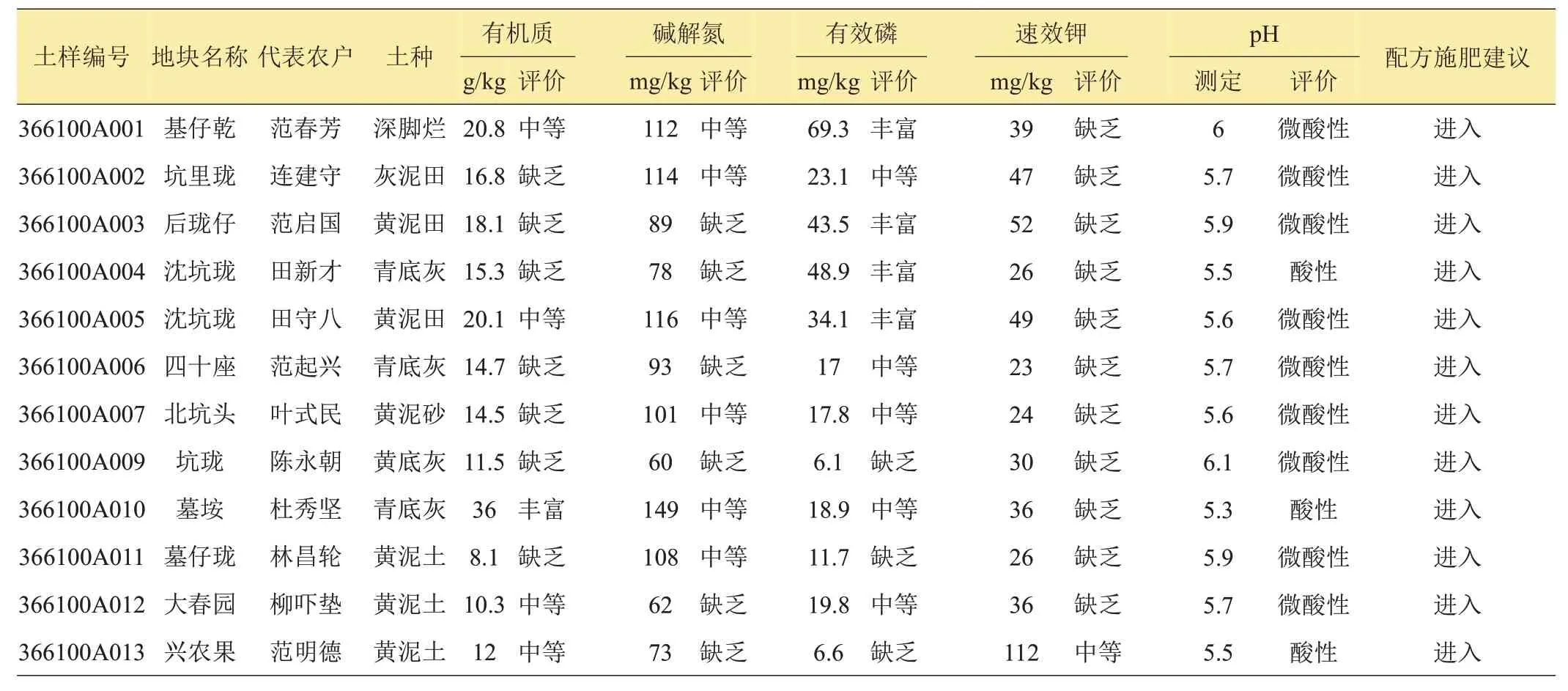
表3 测土配方查询系统数据格式3
2 土壤肥力知识图谱的可视化
目前,采用关系数据库存储RDF三元组容易保存很多重复无用数据,因此需要花费额外的人力资源成本定期维护。而Neo4j 是高性能开源图数据库,也是目前知识图谱存储领域最常用的存储选择之一。在Neo4j 中,实体作为节点,关系及属性作为边,能够较为直观地反映实体之间的交互关系以及知识图谱的内部结构,大幅度提升知识检索性能,也有利于知识推理,且具有更强的扩展性。与此同时,Neo4j 采用的Cypher语言,对于数据的保存与检索非常有效率。土壤肥力知识图谱中土壤肥力与科学施肥管理建议的检索基于Cypher语言,在检索语言模板中输入需要检索的实体或者属性,即可检索到节点的相关信息,随后数据封装通过D3.js实现数据的可视化,实现知识图谱中节点以及边的可视化展示[34]。安徽省土壤肥力知识图谱的可视化展示见图4。以安徽省行政区划为主线连接的节点,在镇/乡/街道级别,即查询到常见农作物种类与10项土壤肥力指标的不同取值。
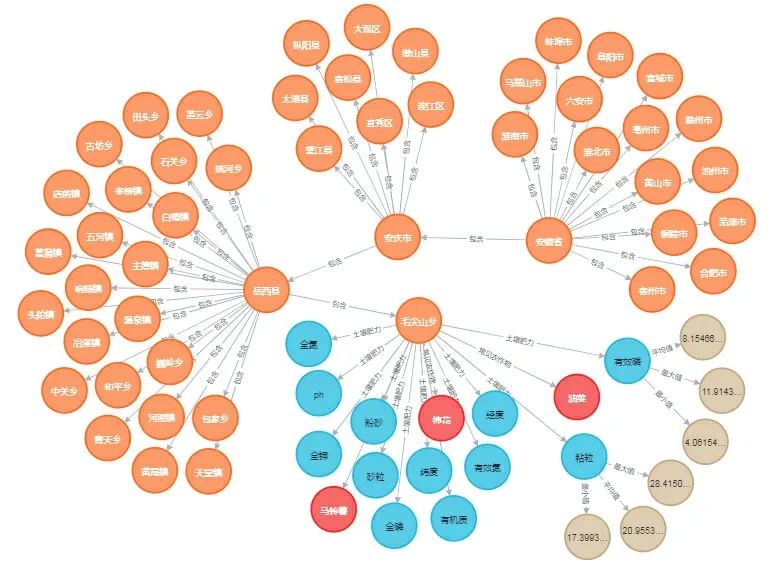
图4 土壤肥力知识图谱的可视化
3 结论与讨论
基于土壤肥力指标数据、期刊文献数据的结构与特点,笔者提出了构建土壤肥力知识图谱的方法。首先根据构建土壤肥力知识图谱的目的和使用范围,结合领域专家建议,采用人工构建的方法,通过Protégé建立土壤肥力相关的领域本体。其次,根据安徽省1:400万土壤全氮、全磷、全钾、pH、有效磷、有效氮、有机质、粘粒、砂粒、粉粒分布图(1980—1996)的数据特征,选择反距离加权插值法插值出安徽省各市县土壤的全氮、全磷、全钾、pH、有效磷、有效氮、有机质、粘粒、砂粒、粉粒的点数据;采用基于深度学习的有监督实体和关系抽取方法(ERNIE-BiLSTM-CRF 模型与PCNNAttention模型)来进行命名实体识别与关系抽取任务,得到土壤肥力三元组数据;采用基于规则模板的正则表达式抽取测土配方查询系统中相关数据。最后,将RDF 三元组保存至Neo4j 中,并基于可定制化Cypher查询语言,查询检索需要的节点信息,其后封装数据采用D3.js可视化知识图谱的节点与周边的联系。
虽然土壤肥力知识图谱已成功构建并实现了可视化查询,但有些问题需要进一步深入探索。就目前来看,土壤肥力知识图谱理论上具有很强的可扩展性,但能否将地域范围扩大至全国,需要实践不同的深度模型对更多来源标注语料的适应能力;其次,该知识图谱中常见农作物施肥管理政策存在长文本抽取困难,及同一文献里面的实体融合问题,需要进一步研究。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
少儿画王(3-6岁)(2022年6期)2022-07-19 09:40:33
家教世界(2021年7期)2021-03-23 08:49:18
家教世界(2021年5期)2021-03-11 12:08:54
家教世界(2021年2期)2021-03-03 09:27:00
中国音乐学(2020年4期)2020-12-25 02:58:06
西藏农业科技(2018年4期)2018-04-25 06:39:34
文学教育(2016年27期)2016-02-28 02:35:15
茶叶(2014年4期)2014-02-27 07:05:15
卷宗(2013年6期)2013-10-21 21:07:52
