
改进YOLOv3算法在矸石充填的应用
2023-08-02 02:43蔡晓敏秦绪彬
自动化仪表 2023年7期
蔡晓敏,成 超,秦绪彬
(1.南京邮电大学通达学院,江苏 扬州 225000;2.扬州环锐科技有限公司,江苏 扬州 225000)
0 引言
由于煤炭开采会导致土地塌陷,开采出的矸石堆渗浸对土地会造成污染,所以越来越多的煤矿将矸石回填采矿区。矸石充填时,判断捣实机构和后部输送刮板机的相对位置至关重要。这对于控制捣实机构上下和伸缩的动作,使捣实结构把矸石捣实压密具有重要作用。捣实机构太高会和后部输送刮板机发生机械干涉;太低会把矸石带回,从而造成捣实机构撞断传送带的事故[1-2]。传统的矸石充填捣实系统靠操作人员用眼睛判断位置。这一方面会造成人力资源的耗费,另一方面由于煤矿工作环境复杂、人眼观察不清晰,在操作过程中不可避免地会产生失误和疏漏。因此,业内迫切需要用计算机和传感器替代人眼对充填位置进行检测,从而判断安全距离、防止碰撞。
近年来,深度学习在计算机视觉、图像处理方面取得了巨大的成功。其中,你只看一遍(you only look once,YOLO)算法是目前比较流行的一种目标检测算法。YOLO算法指只需要看一遍图片就能预测出物体的类别和位置。YOLOv3是继YOLO和YOLOv2之后,YOLO系列的又一目标检测算法。YOLOv3具有速度更快、精度更高的特点。
深度学习的性能在很大程度上取决于其结构和超参数设置。因此,本文提出1种基于实数和整数混合编码的粒子群优化(particle swarm optimization,PSO)算法来优化YOLOv3超参数获取过程,并把该算法应用于矸石充填捣实视觉系统中,以获得对应的充填溜子和横截面的对应位置,从而保证捣实机构不会和后部输送刮板机发生干涉并避免碰撞。同时,捣实机构能将矸石压实、没有回矸,从而达到保护安全、最大程度处理矸石固废且实现最大程度回填充实率的目的。根据调研,本文提出的智能方法在国内外矸石充填领域鲜有研究。
1 YOLOv3算法概述
近年来,深度学习领域获得了长足的发展,特别是卷积神经网络(convolutional neural network,CNN)的方法取得了广泛的应用。和传统模式识别最大的不同是,深度学习可以从大量带有标签的数据中准确、自动地学习到特征,提升了算法应用速度和自动化程度[3-4]。深度学习中的YOLO算法先将目标边界位置的问题直接转换为回归问题,然后通过CNN对其进行处理,在具有高精度的同时保证了实时性。因此,YOLO算法近年来得到了广泛的重视。
YOLOv3模型可分为特征提取层和处理输出层。特征提取层是Darknet-53和ResNet-like网络的组合。处理输出层类似于特征金字塔网络。YOLOv3模型还可以具体划分为106层全卷积体系结构,包括卷积层、批标准化(batch normalization,BN)层、shortcut层、路由层、上采样层和YOLO层。其中:shortcut层借鉴了深度残差网络;路由层索引到前面的特征映射;上采样层是双线性上采样层;YOLO层是特征映射解析层[5]。在卷积层中主要使用1×1和3×3滤波器。3×3卷积层用于减小宽度和高度以及增加通道数。1×1卷积层用于表示压缩特征。网络体系结构的复杂性往往伴随着模型训练难度和收敛速度的双重挑战。因此,基于复杂的底层结构,YOLOv3采用了快捷层,大大降低了训练难度、提高了训练精度。跨层连接是通过路由层实现的,有助于多个不同特征的融合,以实现多层联动学习。上采样层采用2次上采样,将大分辨率特征图和小分辨率特征图有机地联系起来,以增强对小目标的识别能力。YOLO层用于输出预测对象的坐标和类别。YOLOv3结构如图1所示。
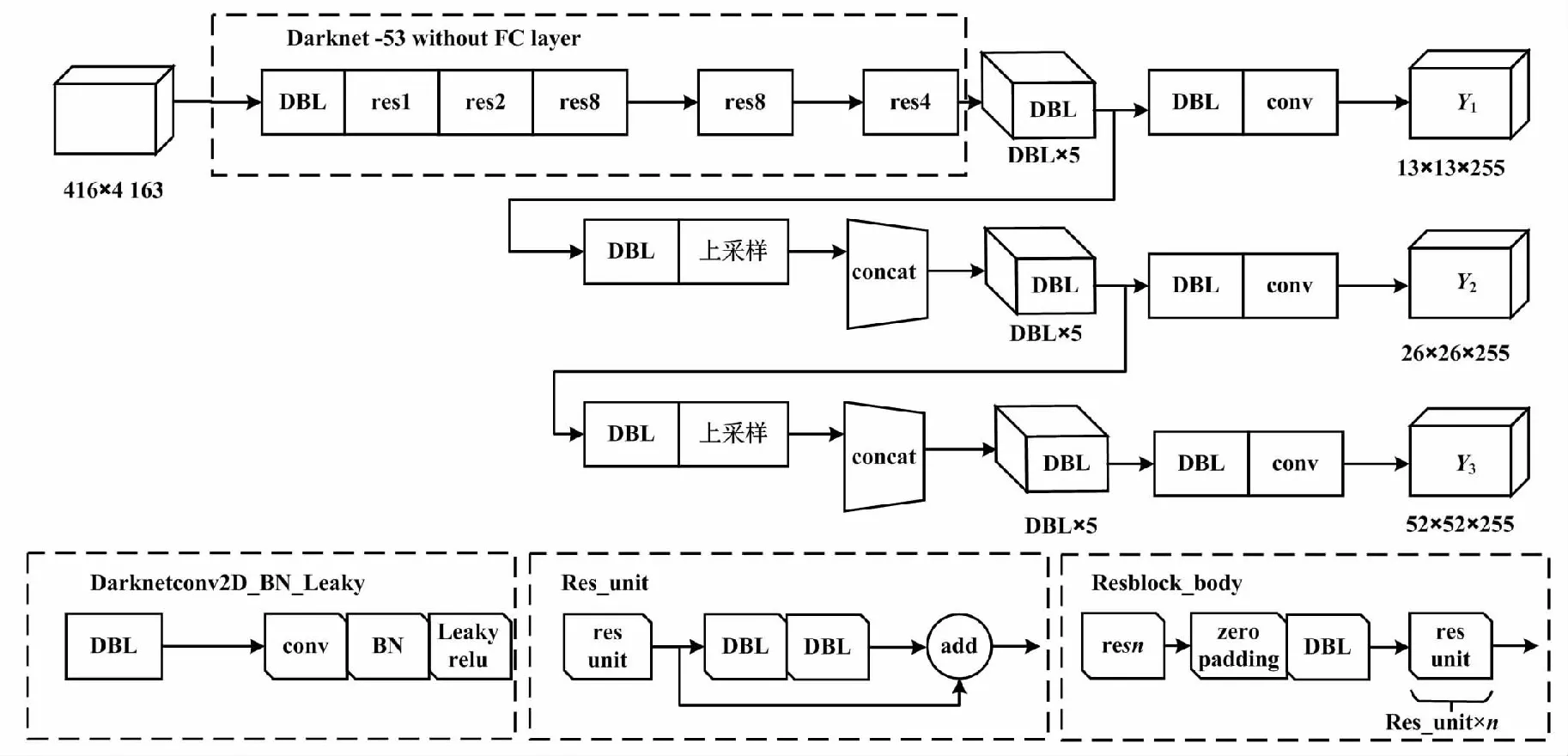
图1 YOLOv3结构示意图
图1中:DBL表示Darknetconv2d_BN_Leaky是YOLOv3的基本组件;resn中的n代表数字,包括res1,res2,… ,res8等,表示这个res_block里含有多少个res_unit;concat表示张量拼接;add表示张量相加;conv表示卷积。
2 改进PSO方法
合理的神经网络结构和超参数设置能够极大地提高YOLOv3的性能。通常,这些超参数的设置由在这方面有丰富经验的研究人员手动调制。1个性能良好的神经网络结构会依赖于问题的特征,因此在过去的几十年里,许多研究者都在研究如何自动识别合适的网络结构。进化算法是1类基于群体的元启发式优化算法,已被证明在识别合适的网络模型方面是有效的,因而被广泛应用到各种工业生产和实际生活领域,并有望解决深度学习领域超参数调试难的问题。大卫等[6]介绍了1种在修改的美国国家标准与技术研究院(Modified National Institute of Standards and Technology,MNIST)数据集上基于遗传算法改进深度自动编码器性能的深度学习算法。Suganuma等[7]提出利用笛卡尔遗传规划(Cartesian genetic programming, CGP)算法建立CNN结构及其连通性。为了减少搜索空间,该算法以卷积块、张量级联等高级功能模块作为CGP的节点函数。为此,本文利用改进PSO获得YOLOv3的超参数,使得优化后的算法更利于矸石充填捣实系统中的防碰撞检测。基于改进PSO的YOLOv3超参优化算法流程如图2所示。
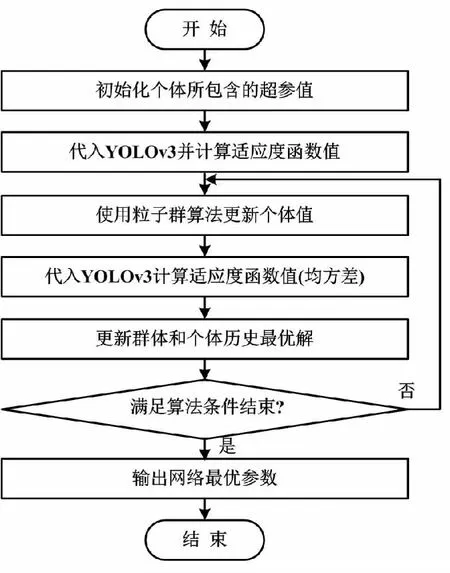
图2 基于改进PSO的YOLOv3超参优化算法流程图
2.1 PSO算法
PSO算法是1995年由Kenndy等依据鸟群和鱼群的觅食合作行为而提出的[8]。在PSO算法中,每个在定义域内的可行解被看作1个粒子,而被求解的优化问题被看作适应度函数,通过迭代运行把每个粒子代入适应度函数计算,从而求得最终的近似解。相对于其他群体优化算法而言,PSO算法提出了群体和个体历史经验解的概念,分别代表全体和个体在搜索历史中获得的最优位置。群体在迭代过程中向这2个历史最优解的不间断学习加速了寻优过程,从而获得相对于其他群体算法更快的收敛速度。PSO算法的迭代如式(1)、式(2)所示。
vid(t+1)=wvid(t)+c1r1×[pid-xid(t)]+c2r2×[pgd-xid(t)]
(1)
式中:i为粒子序号,i=1,2,...,N,N为粒子个数;d为粒子维度序号,d=1,2,...,D,D为粒子维度;t为迭代次数;w为惯性权重;c1为个体学习因子;c2为所有粒子的学习因子;r1和r2为两个服从分布U(0,1)的随机数,可增加搜索的随机性;vid为第i个粒子第d维的速度;xid为第i个粒子第d维的位置;pid为第i个粒子第d维的最优解;pgd为到第d次迭代为止,所有粒子第d维的最优解。
xid(t+1)=xid(t)+vid(t+1)
(2)
2.2 PSO算法个体初始化和编码
PSO算法在搜索空间中随机选择对应的超参数组合初始化群体。学习率(learning_rate,LR)、LR从 0 上升到LR的样本数burn_in(简称“BI”)、动量(momentum,MO)、学习率更新迭代步数1(step1,ST1)和LR更新迭代步数2(step2,ST2)这些超参数分别以实数和整数的形式进行编码。优化的超参数及其变化范围如表1所示。

表1 优化的超参数及其变化范围
由表1可知,待优化的超参数分别为离散值和整数值。因此,本文针对这2种数值分别采用不同的初始化和更新方法。针对离散值,本文定义离散值的初始范围为[1,n]。其中,n为离散值的数目。在使用PSO迭代式进行计算的过程中,本文通过向下取整获得个体更新以后的位置。例如:针对超参数LR,本文定义的范围为[1,4]。在迭代计算过程中,假如x取值为3.4,则向下取整为3,代入网络对应的LR为0.001。针对整数值,则只使用向下取整概念更新个体。
表1所示的这些超参数在本文定义的取值范围内(该取值范围是经验值)可以取不同的数值。随机选择这些超参数后,本文基于层数和特征图的数目,根据以下所述的规则创建网络。
①当YOLOv3模型首次训练时,LR的初始值为0.001。一般而言,LR的范围在0.001~0.1之间,在对数范围均匀分布。随着迭代次数的增加,学习速度降低,损失函数的收敛加速。在整个培训期间,从训练开始到结束,LR应降低至原来的1%。
②批次表示一批训练样本的样本数。每批样本更新1次参数,以保证训练速度和计算能力。通常选择样本数为8或64。
③随着训练迭代的进行,损失函数将在训练后期的迭代过程中缓慢收敛。BI可以更好地解决这个问题[9]。BI的范围一般在0.85~0.95之间,不能大于1。
④当迭代次数达到BI时,LR的更新方法将改变。初始网络值为500,范围限制在400~700之间。
⑤当迭代到ST1和ST2时,LR将变为原来的10%。初始网络值分别设置为400和700,并且范围有限。
2.3 适应度函数
YOLOv3的平均分类精度被用作个体的适应度得分,即从每个粒子上构建YOLOv3模型并将其存储在个体中。训练数据集的90%用于训练网络、10%用于验证。本文采用随机梯度下降(stochastic gradient descent, SGD)算法对所构造的网络进行训练。训练时间为固定的迭代数e(e=50)。本文将验证阶段的平均分类精度作为适应度得分。对于每个网络的训练,本文将交叉熵损失作为损失函数。每20个e的LR降低至10%。损失函数Loss如式(3)所示。
Loss=-yi×log(pi)-(1-yi)×log(1-pi)
(3)
式中:yi为样本i的标签,正类为1、负类为0;pi为样本i预测为正类的概率。
3 试验结果及分析
本试验使用视觉目标分类(visual object class,VOC)2007的官方数据集来预训练网络,使用矸石真实数据来训练和测试网络。VOC包含2种类型的标签数据,分别为检测和语义。所有的数据均有检测标签,有些还包括语义标签。VOC数据集目前被广泛应用于网络算法性能的判断。许多研究人员报告了他们的训练和测试在这些数据集上的表现。数据集对象包括20个类别,共9 963幅图像,分为训练、验证、测试这3个部分,共有24 640个对象被标记[10]。本文涉及的YOLOv3网络的代码和架构都从YOLO官网中获得。调试代码使用的显卡为英伟达2080TI 图形处理器。
本文主要介绍了1种利用PSO迭代求解YOLOv3网络结构最优超参数组合的方法,以获得较低的损失函数值和精度[11-12]。
PSO的初始化参数设置如下:最大迭代次数为10次;初始粒子数为10个;搜索维数d=5;初始惯性权重w=0.8、c1=2、c2=2。
试验采用PSO对YOLOv3的一些超参数进行优化,而其他超参数(如归一化等)则保持不变。实际上,为了保证在训练中损失函数不会产生梯度爆炸,这些需要优化的超参数应在有限的范围内迭代。
本试验选择YOLOv3的损失函数作为适应度函数。每次调整超参数后,试验将超参数输入YOLOv3网络进行完整的训练。YOLOv3的初始迭代次数是520 000次。由于在实际矸石数据训练中发现模型经过1 000次迭代后基本收敛,过大的训练迭代只会消耗计算资源,因此试验的训练周期设定为1 000次迭代。1次试验获得的粒子群10个个体超参值如表2所示。

表2 1次试验获得的粒子群10个个体超参值
在表2的试验中,粒子数是10。首先,在表1的范围内随机生成10个粒子的位置,并将这10个粒子的初始超参数进行YOLOv3训练,得到1组初始局部最优值。然后在第一次迭代后,根据式(1)、式(2)得到了10个粒子的1组新的超参数,并将它们重新输入YOLOv3进行训练。如果有更好的适应值,则更换相应位置的参数。通过这种往复运动,经过10次迭代,得到1组新的局部最优值。随着粒子的迭代,具有最佳适应度函数值的粒子被称为全局最佳粒子,即试验结束时的最佳超参数粒子。
为了展示PSO与YOLOv3网络集成后的优点、防止误差导致的数据失真,在相同的试验环境下,本文将标准超参数和算法改进优化后获得的全局最优超参数分别输入YOLOv3 5次。本文将5次运行改进后的PSO算法优化后获得的网络损失函数与网络预测值进行比较。标准YOLOv3和改进YOLOv3的5次损失函数值如图3所示。
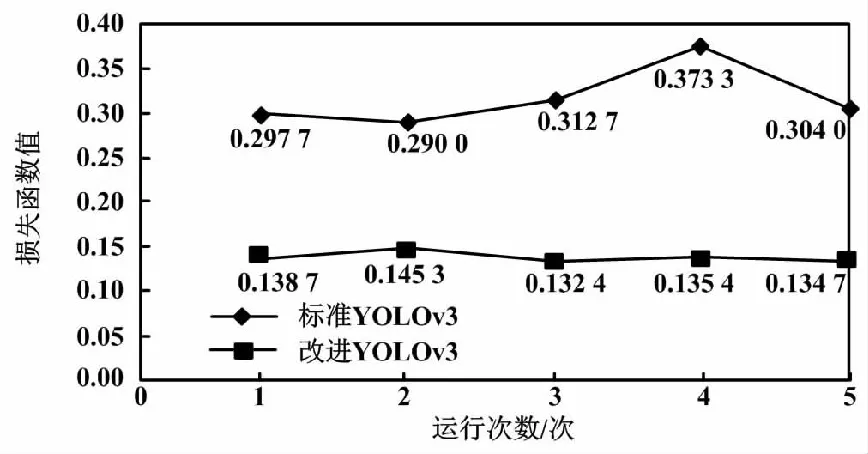
图3 标准YOLOv3和改进YOLOv3的5次损失函数值
标准YOLOv3算法运行后获得的平均损失函数为0.315 54。改进后YOLOv3的平均损失函数为0.137 3。由此可知,改进YOLOv3的预测精度大大提高。
4 结论
针对煤矿系统中的矸石回填机构防碰撞问题,本文提出了1种基于整数和实数混合编码的PSO算法的YOLOv3解决方案。本文提出的PSO算法用于解决网络超参数选择问题,进而使得优化后的网络具有更优的性能,从而有效地优化选择网络的超参数、精确地检测出捣实机构在图片中的精确位置。该方案应用于矸石充填捣实系统中,以获得对应的充填溜子和横截面的对应位置。控制器通过反馈,驱动电液控阀组执行捣实机构的上下和伸缩动作,保证捣实机构不会和后部输送刮板机发生干涉,以保障安全,提高防碰撞效率。同时,捣实机构能将矸石压实,没有回矸,以达到最大化处理矸石固废且最大化回填充实率的目的。平均损失函数对比结果表明,改进后YOLOv3的预测精度大大提高。本文所提算法具有更加良好的性能,可以进一步优化和推广。
猜你喜欢
山西冶金(2022年3期)2022-08-03
陕西煤炭(2021年6期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
煤炭与化工(2021年5期)2021-07-04
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
