
基于情感特征和谣言种类的谣言检测
2023-07-29 00:30张明书葛晓义
计算机仿真 2023年6期
张明书,葛晓义,魏 彬
(武警工程大学密码工程学院,陕西 西安 710086)
1 引言
随着网络媒体的高速发展,信息的获取和传播更加便利,民众更加倾向于社交媒体中获取信息,根据《微博2020用户发展报告》,9月日活跃用户达2.24亿。但审核机制的不完善等原因也导致了社交媒体中了谣言的滋生和传播,破坏了网络环境的良性发展,给社会、文化、经济等带来严重的影响。在新冠肺炎爆发之初,一系列关于封锁、和感染数量的谣言,使得人们开始囤积口罩等物资[1],在今天关于疫苗的谣言仍影响着疫苗接种效率[2]。
社会网络谣言为一种在社会网络上传播且未经验证,或已被官方证实为假,并在社会网络中流传的信息[3]。目前,社交平台中的谣言检测主要依靠人工检测,对于社交媒体上的信息数据量巨大,内容参差不齐,信息种类繁杂的情况,人工检测显得效率低下,且耗费人力、财力,因此研究谣言自动检测是非常迫切和必要的。
钓鱼谣言[4]本身是指具有明显知识陷阱的戏虐谣言,是一些网络高手为了显摆自己的智力优势而虚构的谣言。在政治和军事类谣言上存在的钓鱼谣言,往往是别有用心者为获取军事情报或其它信息,故意发布具有明显性的错误信息或者误导信息,等待知情者给出正确答案。因此需要谣言产生的评论信息以及转发信息作为特征的谣言检测效果相对滞后。
本文针对利用评论和转发信息作为特征的谣言检测模型的滞后性,提出一种基于情感特征和谣言种类的谣言检测模型。
2 相关工作
谣言检测2011年由Castillo[5]在Yahoo实验室提出后,一直以来作为舆情分析研究的重点,也是自然语言处理领域(Natural Language Processing,NLP)的热点。
基于机器学习的谣言检测主要通过谣言文本、用户信息、传播模式等构造特征,依靠人工设计的特征,Yang[6]等人提出基于地理位置,利用支持向量机(Support Vector Machine,SVM)构建分类器;Kwon[7]等人于提出基于事件、结构等,利用随机森林(Random Forest)构建分类器。虽然基于机器学习的谣言检测具有一定的效果,但该类方法严重依赖于特征工程,耗时耗力且检测准确率低。
随着深度学习技术的不断发展,Ma[8]等利用长短记忆网络[9](Long Short-Term Memory,LSTM)、门控循环神经网络 (Gated Recurrent Unit,GRU)[10]等方法,通过谣言的传播结构获取高级特征对谣言检测进行研究;刘政[11]等提出基于卷积神经网络(Convolutional Neural Networks,CNN)的方法对谣言检测进行研究,通过卷积核提取领域的相关特征,Zhou[12]等在此基础上,结合CNN与GRU二者优点,充分挖掘文本深层特征,检测效果明显提高,李[13]等人改进生成对抗网络,强化谣言特征的学习,进行谣言检测。鉴于用户、帖子和传播模式等可以构成图,采用图神经网络(Graph Neural Network,GNN)进行谣言检测,Bian[14]等人分别通过构造谣言文本与评论之间的关系图和谣言传播树构成的图,采用图卷积神经网络[15](Graph Convolutional Networks,GCN)的方法进行谣言检测,检测结果大幅提升。基于深度学习的谣言检测效果优于基于机器学习的谣言检测。
分析现有模型发现往往需要大量的特征,在谣言发布之初,不具备评论和转发信息,因此现有的谣言早期检测模型不能满足需要。在不具备评论和转发信息的基础上,如何利用谣言文本及谣言种类标识的信息实现谣言高准确率的检测,是谣言检测的一项艰巨任务。Nguyen[16]等人提出一种多头文档注意力机制,根据假新闻中单词对文档语义贡献不同进行谣言检测。Alonso[17]等人综述了当前仅利用文本内容,通过情感分析对假新闻进行检测的方法和技术,主要是讲文本中的情感分析作为文本的基础和补充,以增强谣言检测的性能。在文本分类任务和情感分析任务中,不少学者考虑文本领域不同,对分类任务具有重要的影响,因此提出采用基于Bert和LDA的模型[18,19]。在谣言检测领域,Silva[20]等人考虑不同领域的文本往往具有不同的词汇使用和传播模式,提出一种可以在新闻记录中联合保存特定领域和跨领域的知识,以检测来自不同领域的虚假新闻。
本文提出一种基于情感特征和谣言种类的谣言检测模型,在获取谣言种类标识的基础上,通过Bi-LSTM提取上下文特征,利用Self-Attention根据谣言种类获取特征,与谣言文本提取的情感特征融合,通过(多层感知机)MLP和Softmax进行谣言分类,结果证明能够有效提高谣言检测准确率。
3 检测模型
谣言检测往往需要根据上下文本内容信息来检测,其它特征作为增强向量。Bi-LSTM能够充分学习上下文的特征,获取特征能力更强,并添加谣言文本类别作为文本补充,同时需要知道上下文内容中哪一部分内容重要,就需要自注意力(Self-Attention)分配不同的权重。最后将特征融合通过MLP和Softmax进行谣言分类。因此本文采取基于Bi-LSTM与Self-Attention获取文本和文本种类信息的特征,通过情感词典获取情感特征作为增强特征。具体模型如图1所示。该模型分为输入层、词向量表示层、Bi-LSTM层、Self-Attention层、情感特征层、MLP层、Class层。

图1 谣言检测模型结构
3.1 Bi-LSTM层
长短记忆网络(Long Short-tern Memory,LSTM)是一种特殊的循环神经网络(RNN),通过增加输入门it,遗忘门ft和输出门ot和记忆单元Ct,使得自循环的节点通过几个“门”来控制,导致不同时刻的训练时更新的权重可以动态改变,避免梯度消失的情况,如图2所示。

图2 LSTM结构
输入门it,遗忘门ft和输出门ot和记忆单元Ct及隐藏状态ht计算过程分别如下所示
ft=σ(Wf·[ht-1,xy]+bf
(1)
it=σ(Wi·[ht-1,xt]+bi
(2)
ot=σ(Wp·[ht-1,xt]+bo
(3)
Ct=fy×Ct-1+it×tanh(Wf·[ht-1,xt]+bc)
(4)
ht=ot·tanh(Ct)
(5)
其中W为权重矩阵,b为偏置矩阵,σ,tanh为激活函数。
在谣言文本中,词汇往往与上下文具有关联性,对于涉军谣言的专有名词,只有某一军种存在,具有较强的双向语义依赖,因此逆序处理十分必要。双向长短记忆网络(Bidirectional Long short-tern memory,Bi-LSTM)将正逆 LSTM 结合起来,用两个相互独立的隐层从两个方向同时处理数据,将输出数据相结合作为输出层的输入。Bi-LSTM 包括前向LSTM 和逆向LSTM,假设一条谣言经过数据预处理后,由n个词组成的谣言数据S=[w1,w2,w3,…,wn],wi是序列中第i个元素的d维嵌入,S是由谣言序列中所有词向量拼接而成的 n×d维矩阵。S输入Bi-LSTM模型后,在t时刻前向 LSTM的隐状态输出为

(6)
逆向LSTM隐状态输出为

(7)

3.2 自注意力层
注意力机制的提出是为了处理图像,用来关注某一小块区域,给予更多的资源。对于自然语言处理而言,同样存在“关键性”的词汇,通过引入自注意力机制区别词语的重要性,如军事、疫情、科技分别对应的重要词汇不同,自动关注更能体现语义的词语。
本文中,自注意力层是作在Bi-LSTM层得到的H上添加注意力,将Bi-LSTM层的隐藏状态集合H=[h1,h2,h3,…,hn]作为输入,则输出注意力向量α为
a=softmax(Ws2tanh(Ws1HT))
(8)
假设LSTM层的前向与逆向LSTM隐藏节点数为u,可得H∈Rn×2u;式中Ws1∈Rda×2u作为权重矩阵,Ws2∈Rda×1为参数向量,其中da为超参数;通过Softmax函数得到每一个向量的概率。按照得到的注意力向量a将H线性加权求和得到状态测量序列的嵌入表示m。那么计算多个特征的m作为序列S的嵌入表示,可得A=[a1,a2,a3,…,an]。那么M矩阵为
M=AH
(9)
3.3 情感特征
谣言文本中几个词就能反应所表达的情感,因此采用基于词典的方法提取情感特征。在情感词典中,假设有d种情感,则情感字典可定义为E={e1,e2,…,ed},对于情感词典中的每一情感e,都有对应的情感词W={w1,w2,…,wL}。在文本中不仅存在代表情感的词语,同时也存在反应情感强度的程度副词以及否定词等。计算某一情感的词汇值
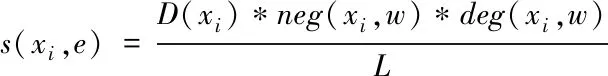
(10)
其中D为情感字典,xi为字典中词汇,w表示上下文的范围,neg(xi,w),deg(xi,w)为对应的否定词和程度副词值

(11)

(12)
根据每一文本中的情感词、程度副词和否定词计算得到文本中某一类的情感值,则该文本的某一情感e为所有存在该情感词汇之和。最后计算得到文本的特征为

(13)
3.4 损失函数
将情感特征与提取文本得到文本和种类特征融合,将得到的特征通过MLP和softmax进行分类,则预测值为

(14)
本文采用交叉熵作为损失函数进行模型训练,计算公式

(15)

4 实验与分析
4.1 数据获取与处理
本文所使用的数据均已证明为谣言或者确定为准确消息,谣言数据集共分为社会、文化、健康、政治、军事、科技、疫情7种。
分类谣言数据在中国互联网联合辟谣平台的案例分类获取(1)https:∥www.piyao.org.cn/jdal.htm;疫情谣言数据在中国互联网联合辟谣平台的疫情防控辟谣专区(2)https:∥www.piyao.org.cn/2020yqpy/获得。军事类谣言以及其它分类谣言部分数据在微博(3)https:∥weibo.com/通过关键词获取。
本文对获取到的数据进行汇总和去重,谣言与非谣言共计51474条,其中各类数量如图3所示。首先使用正则化过滤无关信息,然后对数据进行去噪,删除长度不足五个字的数据,提高处理效率,并用中文结巴分词进行分词操作。

图3 谣言类别统计图
4.2 评价与标准
本文采取谣言检测常用测评的准确率(Accuracy)、召回率(Recall)与F1 值(F1-Score)作为评价指标,用于反映模型效果。首先引入混淆矩阵,如表1所示,其中TP、TN、FP、FN应的概念为:

表1 混淆矩阵
1) 准确率(Accuracy)
2)召回率(Recall)
3)F1 值(F1-Score)
4.2 评价与标准
1)实验环境。①操作系统::Windows 10 家庭版;②CPU:Intel(R) Core(TM) i7-10750H;③GPU:NVIDIA GeForce RTX 2060。
2)参数设置。采用word2vec对数据进行预训练,词向量长度设为300。LSTM与隐藏层为128,激活函数分别为ReLU与Tanh,其中为避免过拟合,dropout为0.2,采用Adam算法优化结果,模型采用30个epochs,每个batch的大小为64。
3)对比模型。.
本文模型为了评价结果,分别与其它基线方法在同样的数据集上进行实验,选取的模型如下:
LSTM模型[8]:该模型将RNN中的循环机制改为门控机制,不仅可以融入过去的特征,同时还能捕捉到当前时间步长中的特征和选择遗忘不重要的信息,是RNN的一种变体模型。
CNN[11]:该模型通过将谣言事件向量化,直接利用卷积神经网络挖掘表示文本深层的特征,无需人工构建特征,却能发现不易被发现的特征。
RCNN[21]:该模型分别通过RNN学习时间序列表示,CNN学习谣言事件文本表示,解决了传统RNN与CNN在谣言检测上存在的问题。
Transformer[22]:该模型通过Transformer编码器进行特征提取,能更加准确地理解语义,解决长文本存在远距离特性依赖问题。
DPCNN[23]:该模型通过一种低复杂性词级深度卷积神经网络(Deep Pyramid Convolutional Neural Networks,DPCNN)架构,能够有效地代表文本中长级关联,可以有效解决情感分类和文本分类问题。
4.2 结果分析
本文使用keras来实现实验模型,对数据集按照6:2:2的方式进行划分,使用上述指标来评估模型的性能,实验结果如表2所示。

表2 本文模型与基准算法结果
从表2种可以看出,CNN模型的实验结果优于DPCNN模型,说明采用CNN模型进行谣言分类时,不能仅依靠增加卷积深度来提高准去率。而RCNN模型效果优于CNN与RNN模型,是因为通过两个模型的融合能够更好的提取特征。单独使用Transformer模型并没有取得较好的结果,虽然,Attention机制可以调整权重,但是不能较好的提取上下文特征。
通过提取上下文特征与谣言种类特征,并调整权重,取得最优结果,与次优模型相比在准确率上提高了0.09,在F1上与次优结果相比提高了0.08。
在上述实验的基础上,将不谣言种类标识特征加入谣言文本内,放在每一个文本前,并进行各模型训练,实验结果如表3所示。

表3 加入种类标识后的结果
通过对比表3与表2,可以发现各模型在加入种类后的效果都相对有所提升,RCNN在准确率上提上了0.12,F1上提升了0.07,Bi-LSTM和Self-Attention模型在准确率上提升了0.11,F1上提升了0.13,证实了谣言种类类别作为特征对于谣言检测的有效性。
将文本中在情感字典获取的单个情感特征连接得到文本情感特征,将情感特征与文本与种类组成的特征融合,通过训练得到结果如图4所示。

图4 综合特征的准确率
通过图4可以看出,模型在运行至第14个epoch时就停止,此时val_acc已经为0.900,采用保存的最好的模型对测试机进行测试,准确率也达到0.898,进一步说明仅从谣言文本中提取丰富的特征进行谣言检测也可以取得较好的效果。
5 结语
本文提出一种基于情感特征和谣言种类的谣言检测模型,通过Bi-LSTM充分学习上下文和谣言种类的特征,通过Self-Attention对特征重要程度动态调整,以及提取情感特征作为增强特征,实验证明谣言文本在加入谣言种类类别和情感特征提取后能够提升模型性能,能够有效进行谣言检测,从而避免了钓鱼谣言的危害。下一步将考虑谣言文本与谣言评论的语义差异进行谣言检测。
猜你喜欢
环球时报(2022-04-13)2022-04-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国盐业(2018年17期)2018-12-23
收藏界(2018年1期)2018-10-10
中国交通信息化(2018年5期)2018-08-21
创新作文(小学版)(2018年31期)2018-05-16
摄影之友(影像视觉)(2017年1期)2017-07-18
民间文化论坛(2016年2期)2016-12-01
