
一种基于累积分布函数的需求开发平台满意度模型的系统实现
2023-07-26 09:13黄晶晶陈霞王娟刘晓富
电脑知识与技术 2023年16期
黄晶晶,陈霞,王娟,刘晓富
(1.中国移动通信集团信息技术有限公司,北京 100044;2.中国移动通信集团江苏有限公司,江苏 南京 210029)
0 引言
对软件平台的满意度[1]评估是软件改进的重要手段,传统的问卷调查式满意度评估方法对于大型软件的复杂流程环节适用度不高。为了有效评估软件平台各个环节的满意度,提升用户使用体验,提出了一种基于累积分布函数[2-3]的满意度模型对客户满意度进行评估,帮助软件开发组织,提高开发与管理工作的效率与能力。本文以需求开发平台[4]为例,需求开发平台功能随着组织流程不断增加变得更加复杂,其满意度也更难评估。本文基于累积分布函数构建满意度评价模型,通过需求开发平台各环节采集的基础数据,分析挖掘评价满意度所需各项指标及其中的关键指标,对数据分析清洗,最终成功分析内部客户在需求开发处理中的不满意环节及原因。同时采用回归[5]、异常点检测[6-7]等多种算法,与本文模型所得结果进行对比。
1 总体方案
传统满意度调查还是主要通过问卷调查方式开展,通过被测评对象对需求管理平台进行打分,但随着系统日益复杂,笼统的打分无法获知影响客户满意度的主要环节从而进行系统改进。
为了更好地量化满意度指标,并准确找到不满意的环节,于是构建满意度评估模型,并设计出情绪感知值,将业务流转的环节与整个系统的满意度进行关联,从而达到准确定位影响感知的环节。
1.1 模型提出和设计
首先根据平台业务特性进行环节划分,针对本项目涉及的需求开发可划分为需求提出、需求评审、工作量评估、业务部门工作量复核、开发时长和验收6个环节,每个环节都有若干指标项。根据每个指标的分布函数,计算各指标下不同值所对应的情绪感知得分。且基于业务理解,可以给不同指标设定不同的权重,不同的环节也可以设置不同的权重,权重之和为1。因此最终每个用户的总情绪感知值EPS(Emotional Perception Score) 则为:
由于需求开发平台涉及6个环节,因此当前userA的总情绪感知值EPSuserA为6 个环节情绪感知值的加权总和。其中Wlinki为环节i的权重,EPSlinkiuserA为环节i中userA的情绪感知值,具体计算如下:
其中,feajlinki表示环节i下面所对应的第j个指标,Wfeajlinki为该指标的权重,EPSfeajlinkiuserA为userA 在该指标下的情绪感知值。具体地,EPSfeajlinkiuserA基于分布函数计算得到,公式如下:

图1 feaj的CDF示意图
特别的,对于某些指标其类别较为离散(类别数≤3) ,这类指标不建议使用上述方法进行情绪感知值计算,而是基于业务逻辑进行情绪感知值转换。目前针对这类指标,都采用以下方式进行情绪感知值评估:
其中,α为调节系数(0<α<1) ,α越大,不同指标值之间的情绪感知值差距越小,目前可设置为1/2。
为了使最终EPS值的分布更符合实际,需对每个指标的基础EPS值进行转换映射,使最终的EPS均值得到提升。具体的,对每个指标的基础EPS值进行线性+非线性的组合映射,若基础EPS值在(0,1) 之间的,则按以下方式映射,否则,值不变。映射公式如下:
在满意度评价模型中,会存在某个重点指标对评价结果有较大影响,例如在需求开发平台中需求是否为重点需求则对用户有较大影响,因此对最终的总情绪感知值EPS进行如下调整:
2 算法验证和模型解释
为了验证满意度评价模型的准确性,采用对需求管理平台的按照需求提出、需求评审、工作量评估、业务部门工作量复核、开发时长和验收这6个环节进行划分,并分析了各环节下的指标项,各环节对应的指标见表1。

表1 需求环节及各环节对应的指标
分析每个环节分别有不同的指标数据,表1 中业务部门指需求提出部门,IT指信息技术部门及需求开发部门。经分析是否紧急需求、IT 需求响应时长、是否延期、是否提前、是否延迟、需求bug数、需求负责人需求验收时长这7个指标数据无法直接获取,实际获取指标数据时应剔除。
2.1 特征衍生
根据日常业务判断,工作量、需求开发时长、需求完成周期这三个指标耦合性强,而其单个指标的值不足以直接影响满意度,因此对其进行特征衍生,生成与满意度强相关的指标,分别衍生出需求完成饱和度和需求开发饱和度,其中需求完成饱和度对应在验收环节,需求开发饱和度对应在流转开发工单环节。
需求完成饱和度 = 需求完成周期/工作量
需求开发饱和度 = 需求开发时长/工作量
2.2 特征筛选
将工作量、需求开发时长、需求完成周期这三个指标绝对值对满意度无影响的特征删除。且是否重点需求单指标评估满意度意义不大,因此仅将其作为权重指标调节最终的情绪感知值,而不单独计算该指标的情绪感知值。
2.3 指标采集
针对以上指标,共采集2021 年10 月—2022 年4月共3 440条评估数据,排除掉无法获取数据的7个指标,包括需求编号、需求名称以及满意度打分等共包含字段27 个。针对以上数据进行预处理,采取措施如下:
1) “是否重点需求”字段重编码,1 代表是重点需求,0代表不是。
2) 将字段中小于0的值作为异常值,并用缺失值替换,各字段最终缺失情况如表2所示。

表2 获取字段及缺失情况
3) 删除有缺失值的行,剩余数据2 910条。
4) 删除工作量为0 的异常数据,最终剩余数据2 908条。
2.4 模型实施
基于业务层面的分析,目前各环节权重设置如表3所示,各指标权重不做调整、均相同。

表3 各环节权重设置
计算得到各指标CDF图如图2。

图2 各指标的CDF图

图 3 各指标情绪感知值分布图

图4 各环节情绪感知值分布图
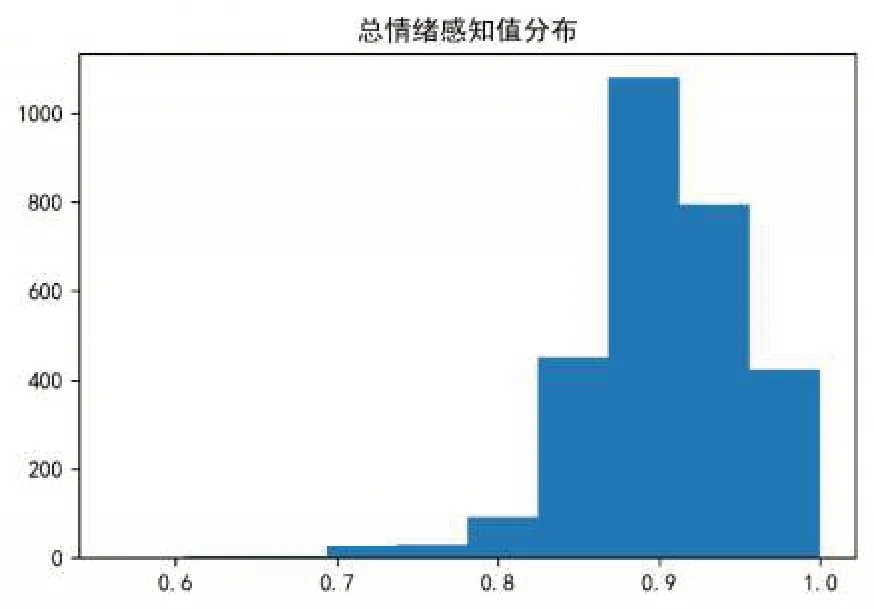
图5 总情绪感知值分布
最终每个指标、每个环节以及总情绪感知值分布如图3所示。
为了进一步增加模型可解释性,对总EPS值较低的用户,需对其不满意原因进行溯源分析。首先找到用户最不满意的环节,其次在该环节中找到用户最不满意的指标。由于各环节的权重不同,因此不能根据各环节绝对EPS 值最低的环节作为用户最不满意的环节。而是根据用户在各环节上的EPS值得分,用各环节满分-各环节实际得分,得到用户各环节满意度扣分值。其中,扣分值最高的环节则为用户最不满意的环节。进一步地,通过比对该环节中用户的各指标EPS 值,其中值最低的则为影响用户满意度的关键因子。
根据以上2 908 个数据,发现情绪感知值几乎均大于0.7,最终EPS值小于0.7的数据有12条。因此可以认为小于0.7 为感知不满意,分析其中的不满意环节如表4所示。

表4 不满意环节分布
2.5 算法对比
为验证上文所列算法的有效性,分别采用回归模型和异常点检测模型进行效果对比。
在回归模型中,基于各用户最终满意度打分,构建回归模型,来获知各指标对用户满意度的重要性权重。运算结果见图6,分析发现,各指标与最终满意度打分之间相关性较弱,无论是构建回归模型或是分类模型效果均很差,因此说明用户的最终满意度较为主观,目前所罗列的指标对其影响较小,不能通过此种方式来确定各指标的重要性权重。

图6 回归模型各指标与满意度的相关性图
对于异常点检测模型,理论认为异常点为偏离于绝大多数数据的点,因此可将其认为是情绪较差的点,正常点认为是情绪较好的点。分别采用孤立森林和LOF算法进行分析,如图7所示,分析中发现,模型识别出的部分异常点和业务角度认为的异常点相悖。下图为需求提出环节和市场部增评环节基于孤立森林算法识别出的异常点,但结果中部分点与实际业务理解的异常点不太一致,且此种方式只能将情绪划分为满意和不满意两类,无法进行更细粒度的划分。LOF效果与孤立森林方法类似,如图8 所示。
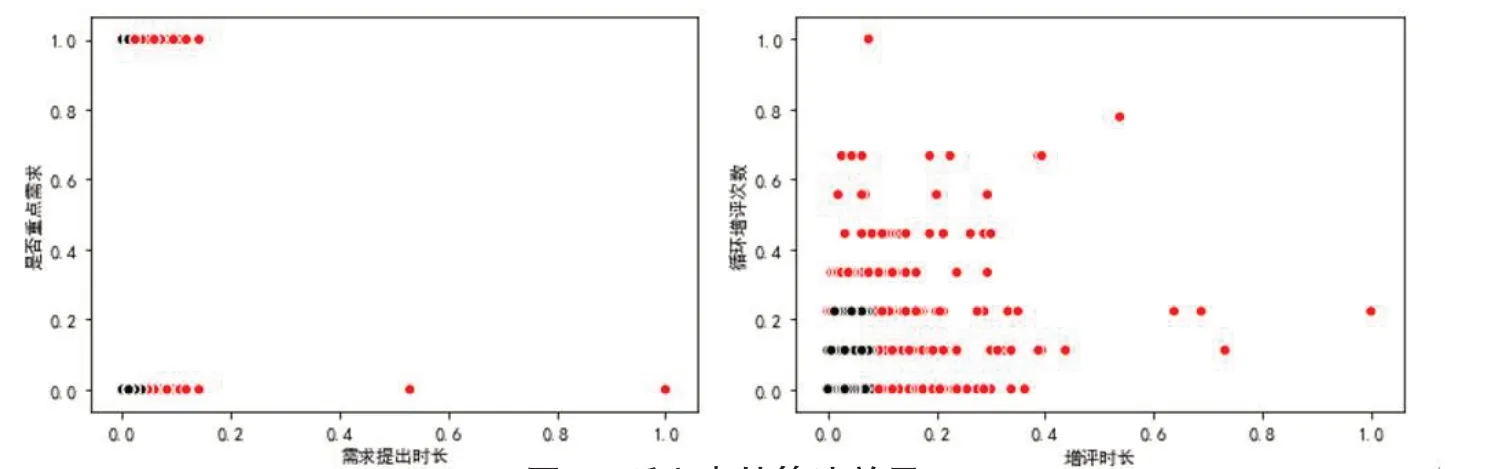
图7 孤立森林算法效果

图8 LOF算法效果
3 总结
本文提出了一种基于累积分布函数的满意度测算模型,针对需求开发平台的流程特性,将全流程进行环节划分,在每个环节下获取若干指标项,根据每个指标的分布函数,计算各指标下不同值所对应的情绪感知得分。对其中一些类别较为离散的指标,基于业务逻辑通过设置调节系数进行情绪感知值转换。最后通过实验证明了算法的有效性,成功地找到了系统中的不满意环节,并与其他模型进行了对比,成功验证了本文所提出模型的合理性和有效性。由此可推广至其他系统,通过结合业务的环节划分和相应的指标采集以及特征处理,可以用于寻找其系统和流程上不满意的环节,并为系统改进找到方向。
猜你喜欢
地理信息世界(2021年2期)2021-08-14
小学生学习指导(高年级)(2021年3期)2021-04-06
当代陕西(2020年17期)2020-10-28
今日农业(2019年16期)2019-09-10
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
河南工程学院学报(社会科学版)(2017年1期)2017-03-27
中国信息化周报(2016年45期)2016-12-27
学习月刊(2015年10期)2015-07-09
终身教育研究(2015年1期)2015-02-28
