
远程实验设备终端的硬件加速方案研究
2023-07-25 09:55蒋诚恒唐立军
电子设计工程 2023年15期
蒋诚恒,唐立军
(1.长沙理工大学物理与电子科学学院,湖南长沙 410114;2.近地空间电磁环境监测与建模湖南省普通高校重点实验室,湖南长沙 410114)
远程实验设备终端视频图像处理主要有小型ARM 系统[1-3]、大型计算机[4]和FPGA+ARM[5-7]三种实现方案。小型ARM 系统大多调用封装好的图像处理库进行处理,但其本身算力和资源限制,导致在对实验数据的处理提取有很大延迟;使用大型计算机可以对图像数据高速处理,但占地空间大、成本高;FPGA+ARM 具有体积小、成本低、速度快的优势。目前ARM+FPGA 的视频图像处理方案利用FPGA 硬件运算优势进行预处理,把实验图像识别放到搭载linux 系统的ARM 上。FPGA 通过相应的图像处理IP核来实现图像的模块化处理,使用的图像处理IP 核是封装好的现成IP 核,处理过程数据存在重复处理、运算周期长的问题,处理好的实验图像被移植到Linux 系统上的OPENCV 库进行识别,最终实验图像结果并不能保证系统整体的实时性[8]。因此,文中以减少远程实验平台延迟为目标,探索ARM+FPGA 的远程实验设备终端视频图像处理方法,为提高远程实验操作平台的性能提供一定的支撑条件。
1 远程实验设备终端架构设计
实验设备终端负责整个系统对实验现象的采集、处理传输等任务。该实验采用ARM+FPGA 架构,该架构包含PS 端和PL 两部分,PS 端集成双核ARM 处理器芯片,PL 端由FPGA 芯片组成,架构设计如图1 所示,包括图像数据采集、缓存、图像处理、网络传输四个部分。

图1 远程实验平台设备终端架构设计
实验终端视频图像通过视频接口传输进入PL端。图像数据流经过滤波、边缘检测、帧间差分IP 核进行视频图像处理以及实验现象信息提取,得到的图像数据通过AXI-stream IP 核进行格式转换,并送入VDMA IP 核,VDMA 利用其特有的帧缓存和缓冲机制,实现高效视频数据存取。PL 和PS 通过AXI 片内协议进行通信,PS 端控制PL 端寄存器的配置以及DDR3、以太网模块等外设的控制,处理好的图像数据存入DDR3 进行存储,待准备好送入PS 端进行进一步的处理,最终将处理所得的实验现象信息通过以太网口进行发送,并与远程实验平台进行通信。
2 远程实验设备终端视频图像加速方案
2.1 滤噪加速方案
考虑到远程实验平台实际使用场景,选取在实验室场景下滤噪效果好的中值滤波。文中选择3×3的滤波窗,通过三个步骤来求得最终的中值[9]。
中值滤波算法划分为两级流水线任务,其实现步骤如图2 所示,第一级流水线的行列计数模块对滤波窗滑过的图像行列进行计数,此步的目的是判断滤波窗滑动是否到达图像边界,到达边界像素值因为没有邻域像素则需要独立进行处理[10-11]。

图2 中值滤波两级流水线设计
第一级流水线的滤波窗口生成模块将图像数据分成三通道并行阵列方便后续进行并行处理,中值滤波算法将输入的三通道图形数据分别进行运算,文中采用的3×3 滤波窗口模块结构如图3 所示。可以采用同步FIFO 或者shift_ram 来完成对图像的遍历,在图中为硬件实现滤波窗口框图,该滤波窗口由两个FIFO(或是带抽头的shift_ram)和六个寄存器构成,图像数据在同步时钟驱动下,从FIFO 输入端口串行输入,图像数据通过FIFO 一次向下和向右通过,将图像数据分割成九个独立像素,从而转变为并行数据,以便通过中值滤波进行处理。

图3 滤波窗口生成模块
第二级流水线是中值滤波部分,如图4 所示。根据中值滤波原理,可以将处理过程分成三级子流水线。

图4 中值滤波模块结构
第一级子流水线将滤波窗对应的3×3 图像9 个数据按行进行分组(L1,L2,L3),对它们进行大小排序。
第二级子流水线进行重新分组,将每组中最大值、中值、最小值分别筛选出来。
第三级子流水线在三组数据中挑选最大值组中的最小值、中值组的中值、最小值组的最大值,将三个数据再做比较,最终将这三个值的中值作为9 个数据的中值。
将快速中值滤波算法进行原理分析,将算法计算任务划分为两级流水线,其中滤波窗体生成模块和中值滤波模块又细分为多级子流水线,同时有多个图像数据在重叠执行,子流水线将三通道数据进行并行处理,从而大大提高了图像数据处理速度。
2.2 边缘检测加速方案
文中采用Sobel 边缘检测算法进行边缘检测,为避免像素点其他方向幅值较高,但水平和垂直方向梯度幅值较低的情况出现,采用x、y、45°、135°方向算子进行梯度计算,如式(1)所示:
梯度幅值采用向量[Gx,Gy,G45°,G135°]T的一范数进行表示。
根据Sobel 边缘检测算法的原理[12],其硬件实现包括三个部分,如图5 所示。

图5 边缘检测流水线设计
根据边缘检测原理将处理任务分成三级流水线,将梯度计算的四个方向梯度分成四路并行阵列。图像输入与前文一样不做赘述。第一级流水线卷积运算通常使用触发器、加法器和乘法器方式或可编程乘法器的altmult_add 模块方式进行实现,但这些方法基于乘法器的结构,存在图像处理过程复杂速度较慢和缺乏输入的连续性的问题。针对这些不足,该模板设计采用移位加法运算,第二级流水线将四个方向的梯度值进行合成,第三级流水线与阈值T进行比较筛选出边缘。
图6 所示为垂直方向的梯度计算子电路,该子电路将三行数据分成并行阵列垂直方向Sobel 算子模板和对应的像素灰度值做移位乘法,算子模板储存在寄存器中,与相对应的图像模板数据进行移位乘法运算,将每一行结果送入并行相加模块进行相加。

图6 卷积计算流水线设计
第二级流水线将第一级流水线四路有符号梯度结果求一范数并进行相加,得出该像素点的梯度值。
第三级流水线采用自适应的阈值方法[13],以像素窗口中的中值作为该局部图像的阈值,实现阈值的自适应。将每个像素梯度值与其自适应阈值进行比较来判断是否为边缘。这种方式调用模块较少,可以简化设计,因为没有乘法器的使用,增加了运算效率和减少资源使用率,流水线设计和并行处理三通道可以让任务重叠执行,提高了边缘检测效率。
2.3 实验特征信息提取加速方案
该设计以迈克尔逊干涉仪为场景,根据实验步骤,实验现象信息为干涉条纹“冒出”和“湮灭”数量和微动鼓轮读数。
文中使用逻辑复杂度低、易于实现的帧间差分法对条纹状态信息进行提取[14-15]。
当条纹发生位移时,每帧图像运动区域的像素点与上一帧相比,灰度值会发生变化,此时对两帧做差分,可以将运动部分像素分割出来,根据两帧图像差分的正负值便可以得出条纹位移方向。两帧图像差分得到的像素由摄像头与观察屏进行标定可得出每一帧相比上一帧的微位移dx1,将每帧的dx进行累加,那么一段时间内的条纹运动距离为当变化的像素对应的位移距离大于阈值T时,则判定“冒出”或“湮灭”条纹,记作一次标志位,如图7所示。
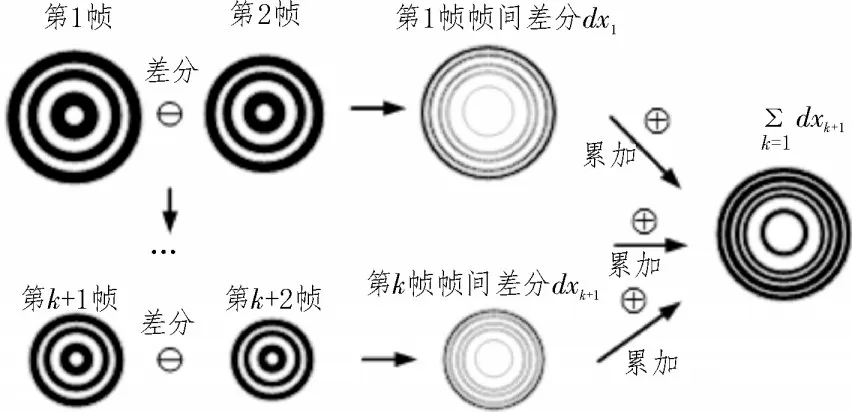
图7 条纹边缘帧间差分过程
实现过程如图8 所示,将图像数据分为两路,前一帧做一次缓存处理,在当前帧到来时,将两帧图像进行差分,将所得的差分结果放入累加器,累加器累加得位移结果,将位移结果通过AXI 总线与PS端进行通信,存入DDR 中,PS 端访问DDR 对结果进行最终的阈值判断,最终发送到以太网模块与服务器通信。

图8 实验数据提取
3 测试与分析
文中对加速方案的测试分为两种,一种是实验结果准确性测试,将线下实验数据与远程实验操作实验数据进行对比;另一种是对加速环节延迟性进行测试,将原有远程终端视频处理方案和传统方案的延迟进行对比。原有平台为树莓派3b+,拥有1.4 GHz 处理器,双频2.4 GHz;传统FPGA 硬件实现采用zynq-7000,100 MHz 工作频率;实验均使用迈克尔逊干涉仪实验进行测试。
该实验为测量He-Ne 激光的波长,需要转动微调鼓轮并记录刻度读数,在观察屏上观察干涉条纹的“冒出”和“湮灭”,记录干涉条纹“冒出”和“湮灭”的次数,最终使用逐差法计算波长的平均值[16]。每当“冒出”或“湮灭”条纹时,新条纹会取代旧条纹的位置,因此“冒出“或“湮灭”条纹的标志是位移距离等于条纹间距。迈克尔逊干涉条纹半径可表示为:
根据条纹半径公式可以求出指定条纹的间距,经过标定,可以根据条纹间距设定阈值T,当位移距离大于阈值T时,可以判断条纹状态变化,进行一次标记。根据收到的条纹“冒出”和“湮灭”信息Δk和M1 镜移动Δd,可以求出He-Ne 激光波长为:
准确率结果通过对比线下实验操作和远程实验操作得到,远程实验平台实验可得条纹数Δk(X1-X10 表示每变化50 个条纹进行一次计数)与对应的M1 镜位置Δd如表1 所示。

表1 实验数据表
经过逐差法得出M1 镜平均位置变化:
延迟性测试针对硬件加速模块进行测试,结果如图9 所示。

图9 测试结果
加速后的延迟与原平台、传统硬件实现方案延迟如表2 所示。

表2 三种实现方案对比
根据三种方案对比中值滤波和边缘检测两项延迟表现,可以发现,原有平台和传统硬件实现方案在中值滤波环节延迟分别是文中方案的180 倍和2.4倍;原有平台和传统方案在边缘检测环节延迟分别是文中方案的114 倍和3 倍;最终远程视频图像处理总延迟相较于原有平台方案缩短了97.17%。
4 结论
采用ARM+FPGA 作为远程实验设备终端视频图像处理架构,设计流水线、并行阵列以及帧间差分的方法实现了图像处理以及实验特征信息提取的加速,有效解决了远程实验过程中图像处理效率低、实验特征信息提取速度慢的问题,有效缩短了远程实验平台的延迟。在该实验室的远程实验操作平台应用结果表明,应用文中方法使原有平台的总延迟缩短了97.17%,提升了远程实验平台的性能。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22
小学科学(学生版)(2020年2期)2020-03-03
小福尔摩斯(2019年2期)2019-09-10
小学生必读(低年级版)(2019年9期)2019-04-13
小学生必读(低年级版)(2019年10期)2019-04-13
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
电气化铁道(2016年4期)2016-04-16
中国资源综合利用(2016年9期)2016-01-22
娃娃画报(2014年9期)2014-10-15
