
融合ALBERT 与多通道特征网络的档案数据分类模型
2023-07-25 09:55刘景霞
电子设计工程 2023年15期
刘景霞
(河南省驻马店市上蔡县卫生计生监督所,河南驻马店 463800)
传统电子档案依靠人工分类,存在效率较低、易出错等缺点[1-2],如何快速且准确地区分档案类型,是档案管理急需解决的重要难题。
机器学习方法[3]无法确保提取特征的准确性。文献[4]采用FastText 模型对档案进行分类,文献[5]提出了BERT-BiLSTM 模型,BiLSTM 缺乏对局部语义的学习。文献[6]提出了BERT-CNN 模型,CNN 提取文本局部特征。文献[7]提出了ERNIE2.0-BiLSTMAtt 模型,注意力[8]能有效提升分类性能。以上模型无法完整地捕捉档案语义特征。
该文采用ALBERT 提取档案文本动态词向量、多通道特征网络捕捉局部语义和序列特征,软注意力负责识别关键特征。
1 档案数据分类模型
1.1 整体模型架构
融合ALBERT 与多通道特征网络的档案数据分类模型主要由ALBERT 预训练语言模型、多通道特征网络二次语义提取、软注意力机制和线性分类层构成。模型整体结构如图1 所示。

图1 模型整体结构
对档案数据文本进行字符级别的分词操作,由大规模语言模型ALBERT 提取档案文本的动态词向量表示,多通道特征网络捕捉不同尺度下字、词和短语级别的全局上下文特征,软注意力计算每个特征对档案分类结果的贡献程度,识别出关键特征,线性分类层调整特征维度,由分类概率分布得出当前批档案样本的标签。
1.2 ALBERT模型
预训练模型ALBERT[9]提出了多种降低参数量的策略和增强模型语义理解能力的预训练任务。采用段落连续性预训练任务替代下一句预测任务,显著提升下游多句子编码任务的性能,提升模型对语料的建模能力。ALBERT 模型结构如图2 所示。
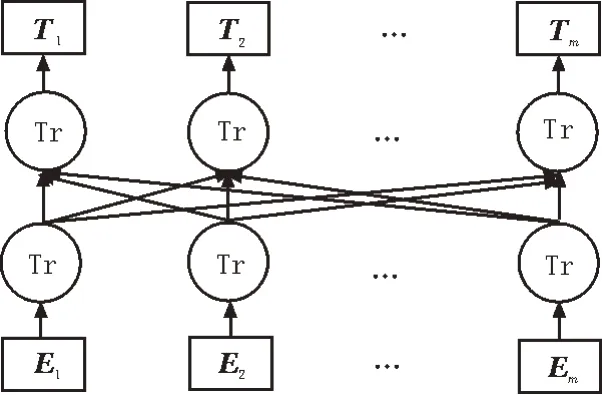
图2 ALBERT模型结构
E1,E2,…,Em为输入向量,由字向量、位置向量和分割向量相加而成,相关计算过程如图3 所示。

图3 输入向量构成
经多层Transform 编码器动态语义学习后,得到文本特征矩阵T1,T2,…,Tm,Ti表示文档案文本中第i个词的向量表示。
1.3 多通道特征网络
多通道特征网络由时间卷积网络[10]模块和多尺度卷积网络构成。多尺度卷积网络通过设置不同尺寸的卷积核,捕获字、词和短语级别的局部语义特征。对ALBERT 模型输出的动态特征表示T进行卷积操作,为降低语义损失,不加入池化操作,得到新的特征表示ci。计算过程如式(1)-(2)所示。
其中,w为卷积核;b为偏置值;m为滑动窗口大小;*为卷积操作;f为非线性激活函数Relu();Ti:i+m-1表示T中第i到i+m-1 行词向量。设置卷积核心为(2,3,4),卷积得到特征c2、c3和c4。
时间卷积网络(TCN)相较于传统循环网络BiGRU[11]和BiLSTM[12],能避免循环依赖机制导致训练速度慢的问题,计算效率更高。TCN 由多个残差块连接而成,单个残差块则由膨胀因果卷积层、归一化权重、激活函数ReLU 和Dropout 层构成。膨胀因果卷积层确保从未来到过去没有出现信息泄漏并构建非常长的有效历史大小。残差连接是搭建TCN 深度网络的关键前提,避免网络随深度增加产生退化现象。归一化权重能够加快收敛速度,降低模型训练成本。TCN 模型结构如图4 所示。
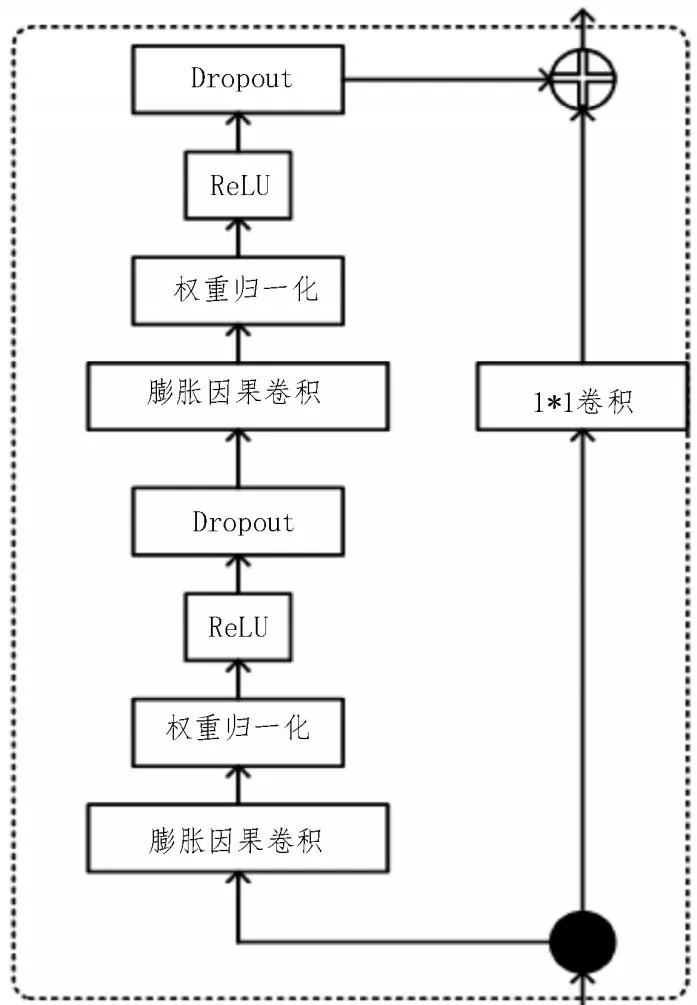
图4 时间卷积模块结构
将卷积网络得到的局部特征c2、c3、c4和原始文本语义向量T分别输入到TCN 网络,经上下文序列特征提取后得到多通道特征H,如式(3)所示。
1.4 软注意力机制
将多通道时间卷积网络TCN 输出H送入软注意力层计算每个特征注意力得分ai,加权求和后得到注意力特征A。相关计算过程如式(4)-(6)所示。
1.5 线性分类层
将注意力特征A通过线性层转换到具体分类空间,Softmax 函数计算得到档案类别概率分布Ps,取行最大值对应的档案类别标签作为分类结果。其过程如式(7)-(8)所示。
2 结果分析
2.1 数据集和性能指标
为验证该文模型在档案数据文本自动分类任务上的有效性,采用复旦大学档案文档数据集作为实验数据。由于数据存在类别不平衡现象,选取其中数量较多的五个类别档案文本进行实验。其中,档案文本内容作为训练内容,分类标签用分隔符 进行区分。采用五折交叉验证方法划分训练集和测试集,将平均值作为最终实验结果,降低随机误差对结果造成影响。具体档案各类别数量如表1 所示。

表1 档案样本数量
为客观评价模型性能表现,实验采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1 值作为评价指标,相关计算过程如式(9)-(12)所示。
其中,TP 代表样本为正例且预测为正例,TN 代表样本为负例且预测为负例,FN 代表样本为正例但预测为负例,FP 代表样本为负例但预测为正例。
2.2 实验环境与参数设定
深度学习模型训练需要耗费大量的计算资源,因此需要配置高性能计算服务器。该文实验采用的软硬件环境设置如表2 所示。

表2 软硬件配置
模型综合训练参数如表3 所示。Ranger 优化器通过结合优化策略RAdam[13]和LookAhead[14]两者的优势,自适应调整学习率的大小,并加快模型收敛速度,提升训练效果。

表3 综合训练参数
模型训练参数设定的好坏影响着分类性能表现,通过多次实验调整参数后得到最优参数设定如下:ALBERT 预训练模型采用中文基础版本,参数量大小为4 MByte,词向量维度为768;TCN 膨胀系数为1,层数为2;注意力机制维度为256,全连接层神经元数量为128个;多尺度卷积网络卷积核数量为3个,特征图数量为128 幅。
2.3 实验结果分析
各模型实验结果如表4 所示。由表4 结果可知,该文模型ALBERT-MCFN-Att 档案文本分类准确率达到了97.51%,优于实验对比的优秀模型BERTBiLSTM、BERT-TextCNN 和ERNIE2.0-BiLSTM-Att,准确率分别提高了2.98%、2.84%和1.41%,证明了结合ALBERT 与-MCFN-Att 模块能准确地识别出档案文本类别,实现快速分类。

表4 模型实验结果
为验证语言模型ALBERT 提取档案文本特征向量的有效性,采用Word2vec[15]和BERT[16]作为词嵌入实验对比。由结果可知,ALBERT准确率较Word2vec和BERT分别提升了4.61%和2.23%,说明了ALBERT能够通过结合词的上下文动态学习向量表征,得到更为准确的语义表示。
为验证模型各个模块对整体性能的贡献程度,设置消融实验。与ALBERT-TCN 和ALBERT-MCNN模型相比较,ALBERT-MCFN 模型准确率分别提升了1.17%和1.31%,说明了单一特征提取模块性能较差,将两者整合为多通道特征网络后能有效提升分类性能。ALBERT-MCFN 模型在加入注意力模块后准确率提高了1.07%,注意力能够为整体模型提供聚焦于关键特征的能力,降低噪声词对结果的影响。
各模型在每个类别上的F1值如图5所示。由图5可得,该文模型在各类别上的F1 值均高于实验对比模型,平均值达到了97.59%。
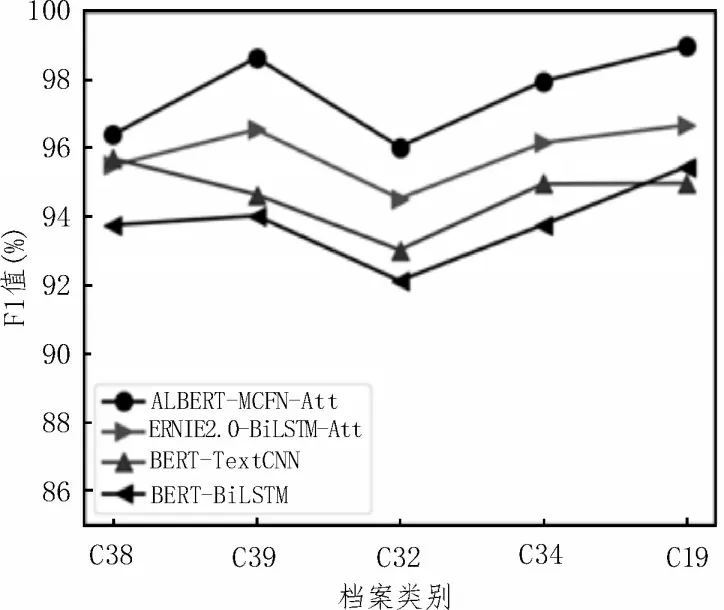
图5 在各个类别上的F1值
各个模型准确率和损失值随训练轮次的变化趋势如图6、7 所示。
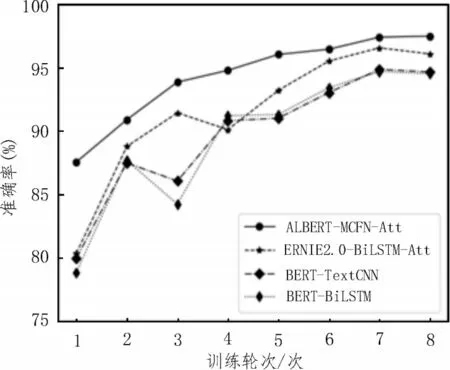
图6 准确率变化趋势图
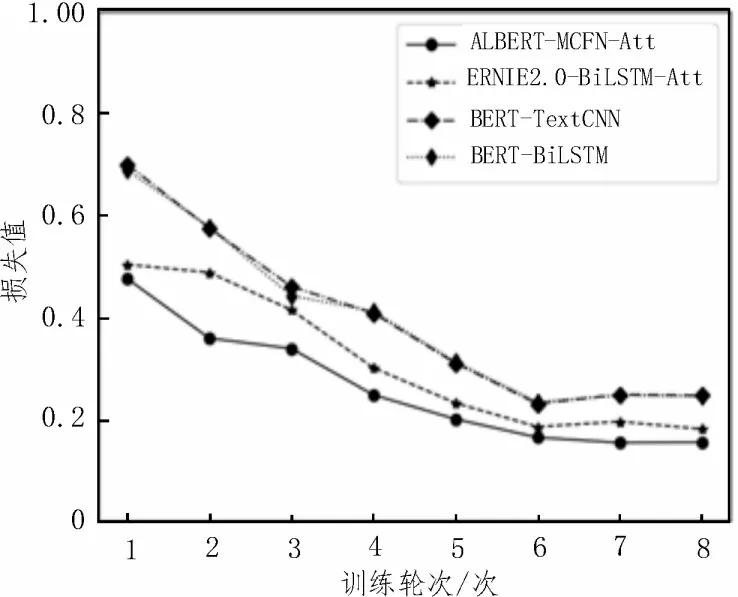
图7 损失值变化趋势图
由图6、7 可知,该文模型ALBERT-MCFN-Att 训练过程稳定性更好,在较少轮次便达到较高的准确率和较低的损失值,随后趋于稳定,而其他模型则存在一定幅度的波动[17-18]。
3 结论
针对档案数据文本自动分类任务,提出了结合ALBERT 与多通道特征网络的档案数据分类模型。采用ALBERT 双向动态语言模型提取档案文本特征向量表示,解决传统词向量无法结合上下文学习当前词语义的问题,在档案数据文本分类任务上的应用性能更好;多通道特征网络全面地捕捉档案文本多尺度局部语义和上下文序列特征,增强了模型整体的特征学习能力;软注意力机制赋予模型关注重点特征的能力,有效提升模型性能,在公开数据上的实验验证了该文模型的有效性。接下来的研究将进一步增强模型特征捕捉的全面性以及降低模型参数量。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
电视技术(2014年19期)2014-03-11
