
基于子空间投影的舰船图像轮廓特征提取方法
2023-07-22 08:05:34李翠梅
舰船科学技术 2023年11期
周 洋,李翠梅,申 攀
(郑州科技学院,河南 郑州 450064)
0 引 言
人工检测这种耗费劳动成本,且随时间人为错误不断叠加的传统方法,已不适合对目标进行精准检测[1–3],亟需一种更为高效的特征提取方法进行自适应地智能分析与处理。目前学术上较为常见的特征提取方法,多是利用深度卷积神经网络展开,并在实践中取得了较为理想的成效。然而该方法在训练时,需要大量已标注的图像数据。同时,由于特征提取模型过度依赖庞大的数据集,其只能针对检测训练数据中出现的目标类别,对新类别目标的检测能力很低。
因此,为了实现舰船图像轮廓特征提取的高效性及准确性,需要对目标的类别判定与定位回归两方面进行优化改进。在舰船图像特征提取上,寻求一个准确的目标匹配方法与区域定位机制,由此提升舰船小样本特征提取模型的准确率和泛化性能,并在有干扰样本的检测环境中,使其仍能获得较为准确的检测结果。本文基于小样本学习的深度神经网络对舰船样本量较少的数据集进行训练,获得一个自适应、高效的小样本特征提取模型,并针对特征向量在度量过程产生的信息丢失与偏移问题,设计一种舰船图像轮廓特征投影提取的方法,由此实现对特定舰船目标的轮廓特征进行精准检测,满足小样本特征提取的现实需求[4–5]。
1 基于深度学习的特征提取算法
基于深度学习的特征提取算法,如图1 所示。按步骤输出待测图像的目标分类得分(通常为置信度得分和回归得分)与检测框图,一般可完成对待测图像的特征提取任务。双阶段特征提取流程包含特征提取、特征分类和输出等步骤,而单阶段特征提取流程直接进行特征提取与回归,利用NMS 去除冗余框后输出目标的检测得分与位置框图。
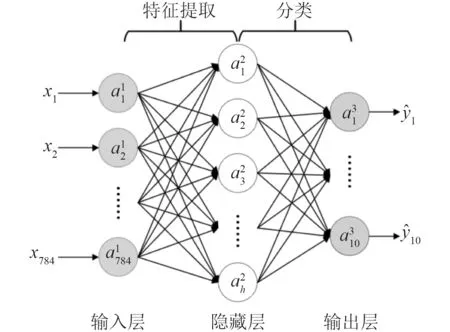
图1 基于深度学习的特征提取算法流程Fig. 1 Target detection algorithm flow based on deep learning
然后,再完成整个模型的训练与优化,使得模型的预测结果更加接近真实结果。
1.1 卷积神经网络的构建
使用卷积神经网络对待测图像进行特征提取与分类回归任务,卷积神经网络主要由卷积(convolution)、激活(activation)和池化(pooling)3 个部分构成,当前较为经典的特征提取算法都是由多个基础的卷积神经网络组合而成。
在计算机视觉中,对特征提取所使用的卷积一般为2D 卷积,在x和y两个方向上进行滑动,且卷积核的深度等于输入特征的通道数。卷积即使用卷积核的权重与目标区域上对应数值进行乘积的和,卷积的数学表达式为:
式中:a 和b分别为卷积核的大小,wi为卷积核对应第i个元素的权重,xi为输入图像对应第i个元素的值,y为卷积的偏置大小。卷积核的数量决定了待测图像进行卷积操作后输出的特征层数。同时,根据任务需求自行设定卷积核的尺寸与滑动步长,调控输出特征图的大小,输出特征图尺寸的数学表达式为:
当卷积核的尺寸大于1 时,输出舰船图像轮廓特征的尺寸保持不变,可以使用尺寸为1×1 的卷积核来改变特征图的通道数,也可使用填充(padding)方法对特征图外围补0 值来扩充。其数学表达式更新为:
式中:padding 为特征图外围补0 的层数。卷积后通常使用非线性激活函数(activation function)激活卷积网络,激活结果为:
式中,h为使用的激活函数。sigmoid 函数输出范围为0~1,函数表达式为:
其输出中心不在0 附近,会出现梯度弥散现象。Tanh 函数输出范围为-1~1,函数表达式为:
其中心值在0 附近仍存在梯度弥散的现象。ReLu函数输出范围为0 到正无穷,函数表达式为:
较少的计算量与较宽的梯度响应区间使得ReLu 函数得到广泛应用。
激活卷积网络后,通常使用池化(pooling)来降低特征图的空间尺寸,进而提取特征图中的主要信息,减小输出特征图的数据量,防止卷积网络出现过拟合现象。常用的池化方法有最大池化与均值池化。最大池化是保留一个空间内所有数值的最大值,均值池化是保留一个空间内所有数值的均值。
1.2 确定网络损失函数
卷积神经网络的训练误差通常需要一个损失函数,衡量经卷积神经网络输出的结果和真实结果之间的差距。一般情况下,损失函数的数值越小表明其网络性能越符合预期。面向不同任务所使用的损失函数类型差异较大,分类任务常用的损失函数为交叉熵损失函数,其表达式如下:
交叉熵损失函数对置信度较高但分类错误的值进行更大的惩罚。回归算法中常用的损失函数为均方误差损失函数,其表达式如下:
1.3 样本量对检测模型的性能影响
如图2 所示,SSD 使用VGG 卷积神经网络提取图像特征,其网络可获取更多细节的语义信息,并提升模型对多尺度目标的检测性能。
为测试样本量对特征提取模型的性能影响,通过实验验证SSD 在不同样本量情况下的检测性能。实验使用控制变量法,只改变每次训练的图像数量,其他变量均保持不变。实验参数设置如下:学习率为0.000 5,batch size 为16,最大迭代轮数为50。实验共进行7 轮,使用VOC2007 数据集,选取不同数量的待测图像,且每幅图像标注的目标个数也不同。训练时,样本图像随机从数据集中选取。测试时,每一轮均选用相同的100 幅图像进行测试,且测试图像均参与训练过程。实验使用的评价指标为mAP,准确地反映模型的检测性能。实验结果如表1 所示。
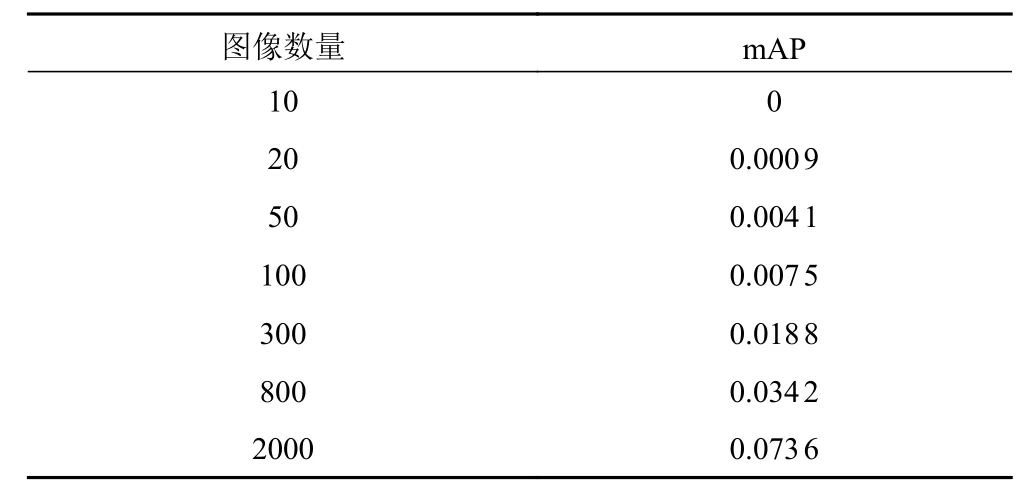
表1 SSD 在不同图像数量训练下的检测性能Tab. 1 Detection performance of SSD in different image number training
观察发现,当图像数量为10 时,其实验结果mAP 为0,说明模型在样本量极少的情况下,无法提取和学习到目标特征,故无法检测到目标。当图像数量从20 逐渐增加时,mAP 随样本量的增加逐渐增大,表明SSD 的检测性能随样本量的增加而逐渐增强。
假设一任务中,最优解为S1,设计模型的理论最优解为S2,设计模型的实验最优解为S3,且在实际生活里的特征提取任务,其S1与S2均无法准确得到,只能通过实验获得最佳的S3。在样本量充足的情况下,训练得到的S3可近似看作S2;当样本量较少时,S3与S2的距离会逐渐拉大,表明较少的样本量会限制模型的检测性能,无法充分表现其检测效果。如何利用少量样本进行特征提取,是本文的研究重点。
2 基于动态子空间的小样本舰船图像轮廓特征提取方法
2.1 检测方法介绍
语义分割任务,是将样本数据集分为支持集和查询集,再与查询样本的特征数据关联匹配,进而获得查询图像的类别信息。该算法通过不断增强分类的细粒度,提升网络的语义分割性能,获得良好的小样本特征提取性能。迁移学习算法利用源数据集充足的样本量,通过深度神经网络多次训练获得较好的特征提取性能,将训练完成的模型或知识迁移至小样本的新类数据集中,通过网络训练获得适应小样本新类的目标分类器。
基于以上检测方式,对舰船图像轮廓特征进行分类。
1)围绕30 张舰船图像小样本进行轮廓特征的向量分析。在此过程中,为了规避出现诸如各舰船图像轮廓特征的相互干扰,特对搜集的样本量进行特征拆解,并基于相似性度量检测方法对其各投影子空间进行正交化处理。
2)通过对舰船图像轮廓特征的小样本模型进行反复训练,不断优化损失函数,在实际操作中可以迭代出舰船图像轮廓的特征相似性,并基于损失函数提升子空间的类间差异性,从而增强其检测类别概率,提升检测方法的抗干扰能力。
2.2 图像分类模型
分类模型实现的具体步骤如下:
首先,将本次搜集的舰船图像轮廓特征导入到训练好的网络ResNet-18 中,得到相对应的轮廓特征向量f(xi),并计算第m类舰船图像对应的轮廓特征均值:
基于上式,获得第m类图像的去均值集合:
采用主成分分析法对全舰船图像轮廓特征样本进行分解,得到对应的映射矩阵与投影子空间的转换公式:
对舰船图像轮廓特征样本类别的投影子空间进行正交化处理,计算得出投影子空间的平方欧式距离:
式中,f(q)为查询图像的特征向量。在对图像的类别进行分析时,计算查询图像q与每个投影子空间的距离,并借助softmax 函数计算出了舰船图像轮廓特征属于第m类图像的概率:
最终,基于ResNet-18 网络,实现对舰船的图像轮廓特征的动态子空间分类。
2.3 特征提取网络
采用ResNet 对搜集到的相关图像进行特征轮廓提取,经整理后,其网络结果如表2 所示。
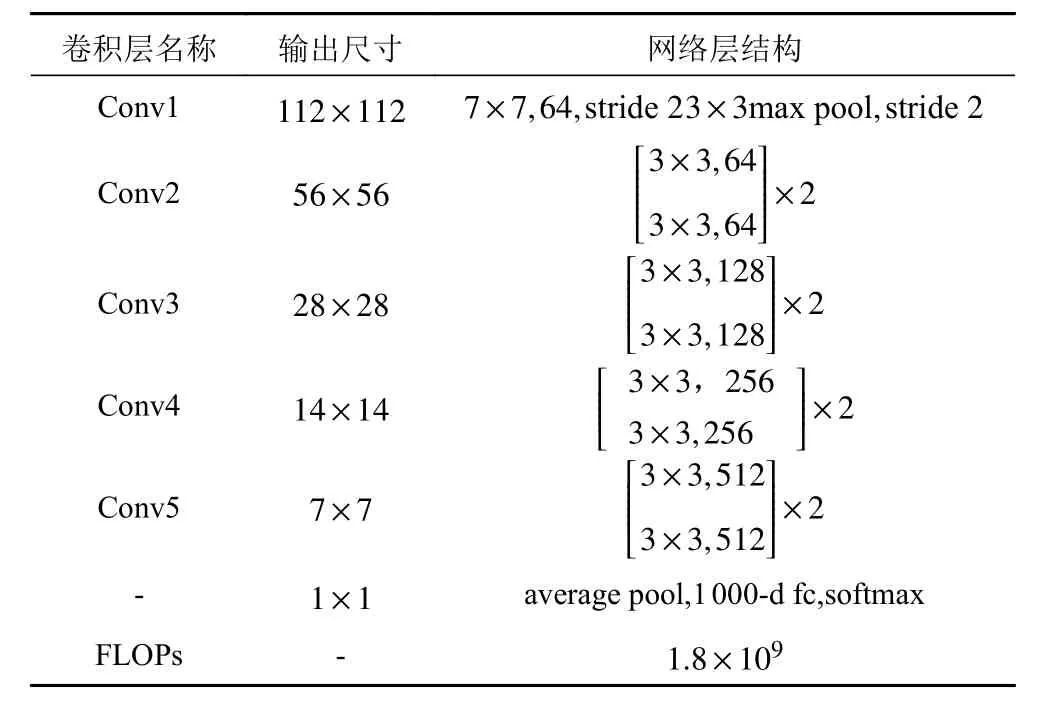
表2 ResNet-18 网络结构Tab. 2 ResNet-18 Network architecture
2.4 动态子空间
按照图3 所示的正交化处理方式,基于前文相关数据对舰船图像轮廓特征样本构建动态子空间,得出协方差矩阵公式。

图3 动态子空间正交化示意图Fig. 3 Diagram of orthogonalization of dynamic subspaces
通过损失函数的参数回传与优化,借助格拉斯曼数对舰船图像轮廓特征各类子空间的差异性进行计算,得出距离度量公式:
通过损失函数的迭代最大化,对舰船图像轮廓的各子空间差异化特性进行提取,由此提升特征提取方法的泛化能力。
2.5 损失函数
关于交叉熵分类的损失函数为:
关于子空间的损失函数为:
将二元损失函数视为总损失函数,通过平衡损失函数前后项的量级与收敛速度,得出最终的二元损失函数为:
基于以上函数结果,将舰船图像的样本数据集进行训练与优化,得出其轮廓特征的高效分类模型。
3 结 语
本文基于子空间投影对舰船图像轮廓特征进行提取,通过动态正交化处理,经验证可以提升子空间的特征差异性,完成对舰船图像的轮廓特征的提取。
猜你喜欢
课堂内外·小学版(低年级)(2023年6期)2023-04-29 00:44:03
舰船科学技术(2022年21期)2022-12-12 08:07:10
内蒙古统计(2021年4期)2021-12-06 02:49:20
舰船科学技术(2021年12期)2021-03-29 01:28:44
制造技术与机床(2019年11期)2019-12-04 05:50:54
测控技术(2018年4期)2018-11-25 09:46:52
上海精神医学(2017年5期)2017-11-29 06:03:10
舰船科学技术(2016年1期)2016-02-27 15:39:26
计算机工程(2015年4期)2015-07-05 08:27:39
统计与决策(2012年14期)2012-07-25 08:15:34
