
基于RISC-V 指令集的处理器及其运行环境设计*
2023-07-21 10:36:46李金凤于德明郭瑞华
南方农机 2023年15期
李金凤 ,于德明 ,郭瑞华
(沈阳化工大学信息工程学院,辽宁 沈阳 110027)
RISC-V 指令集架构的出现引起了业内的广泛关注,并产生了许多基于RISC-V 指令集架构的处理器设计成果。比如,UCB 设计研发的标量处理器Rocket 以及超标量处理器BOOM,Vector Blox 公司设计的标量处理器ORCA,由苏黎世联邦理工大学和波罗尼亚大学联合设计的超低功耗处理器RI5CY等等[1]。在国内也同样涌现出了诸多RISC-V 架构相关的研究成果,例如芯来科技公司的蜂鸟E200 系列,平头哥公司的无剑、玄铁等等。然而,国内针对RISC-V 的开源处理器的研究使用5 级流水线且加入64 位扩展集的设计方案较少,大多数的设计方案仅考虑功能方面的实现,对于性能的优化略有不足[2]。基于以上背景,课题组在分析了RISC-V 指令集的基础上,采用五级流水线设计RISC-V 处理器,并在Linux 系统上搭建了相应的运行环境。最终完成的基于RISC-V 指令集的64 位五级流水处理器及其运行环境成功运行了CoreMark 测试程序,CoreMark 测试结果为3.38 CoreMark/MHz。
1 处理器的流水线设计
本处理器采用经典的五级流水线,五级分别称为取指(Instruction Fetch, lF)、译码(Instruction Decode, ID)、执行(Execute, EXE)、访存(memory,MEM)、写回(Write back, WB)。处理器整体框图如图1所示。
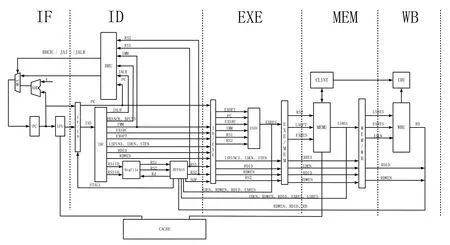
图1 处理器整体框图
取指阶段主要包括指令计数器模块和取指模块,主要作用是在取指后将指令地址与指令传输到译码级。译码阶段主要包括译码模块和通用寄存器模块,主要作用是将指令译码,使处理器明确本条指令的运算类型、源寄存器、源操作数、目标寄存器等信息。执行阶段主要包括算术逻辑运算模块、控制与状态寄存器模块、访存地址生成模块、乘除法器模块。主要功能是根据译码结果执行相应的运算或者操作。访存阶段主要包括存储器访问地址生成模块AGU(Address Generation Unit)、存储器访问控制模块LSU (Load Store Unit),主要作用是对存储器访问指令执行完成后生成的访存地址进行存储器读取操作,并将数据从存储器中读出或者写入存储器[3]。写回阶段主要功能部件就是寄存器写端口,主要作用就是将指令运算的结果写回到存储器或者寄存器。
1.1 分支跳转指令的优化
在RISC-V 指令集中分支跳转指令一般分为无条件分支跳转指令和有条件分支跳转指令。而无条件分支跳转指令又分为无条件直接分支跳转指令和无条件间接分支跳转指令,有条件分支跳转指令只有一种,即有条件直接分支跳转指令[4]。
通常在流水线中,取指阶段以及译码阶段无法对有条件跳转指令做出判断,决定是否跳转,只能等待指令执行结束,才能判断出指令是否满足跳转的条件。在这个过程中处理器将出现较长时间的延迟,严重影响处理器的性能[5]。所以为了解决这一问题,将分支指令的处理提前到译码阶段,这样做可以极大地降低处理分支指令时产生的延迟对后续流水线的影响。分支跳转指令处理模块如图2所示。
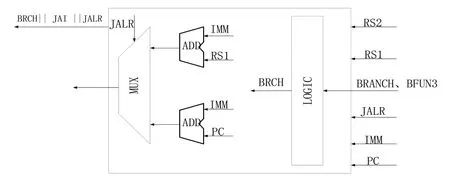
图2 分支跳转指令处理模块
该模块首先使用LOGIC 模块根据BFUN3 信号判断跳转指令的类别,然后计算出跳转指令的地址,最后将生成的这两个信号通过一个多路选择器传输给PC,最终实现分支跳转指令。
1.2 流水线冒险的处理
流水线的冒险主要包括三个方面:结构冒险、数据冒险、控制冒险。
结构冒险是指流水线中硬件资源的冲突,解决资源冲突可以通过复制硬件资源或者流水线停顿等待硬件资源的方法解决[6]。
数据冒险是指流水线在传播过程中,不同指令可能在同一时刻对同一寄存器产生读写信号,指令先后顺序的不同可能造成读写数据发生错误,即产生数据冒险[7]。在本处理器中主要会引起数据相关冲突的是先写后读(Read After Write, RAW),也称为真相关[8]。RAW 必须等到先序指令执行完成,再进行后续操作,这将造成流水线停顿。本文采用数据旁路传播技术来处理该问题。具体实现思路如图3 所示。通过数据旁路,将先序指令的数据通路生成的中间数据直接转发到ALU 的输出端。图中,指令4 中ALU 的输入端与前三条指令的中间数据使用数据旁路连接,具体实现如图4所示。
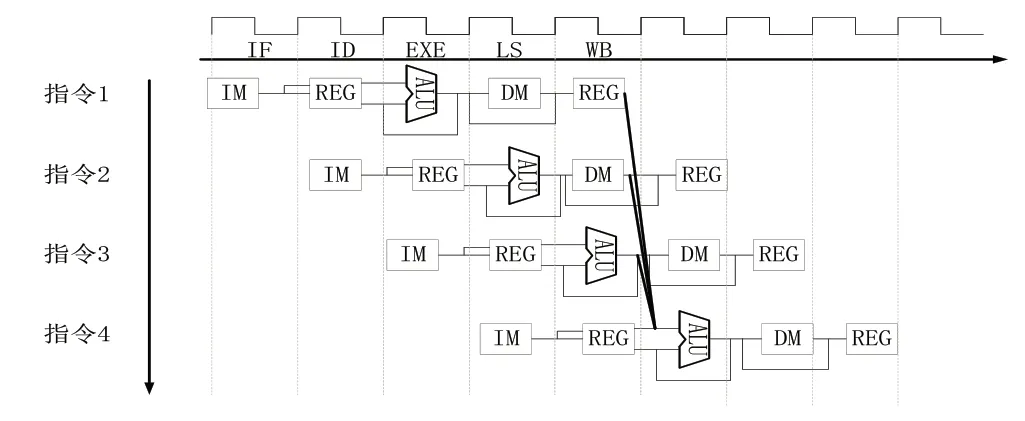
图3 使用数据旁路解决数据冒险

图4 数据旁路模块
使用数据旁路可以解决大部分RAW 数据冒险,但是对于LW 指令后紧跟R 型指令或者I 型运算指令(即Load-use 数据冒险)的情况只能使用前插入空操作的方式来解决。具体的实现需要在load 指令前插入空操作指令NOP,同时还需要让PC 以及IF/ID 的寄存器状态保持在一个周期。
控制冒险也称为分支冒险。因为取到的指令或者指令地址的变化与流水线的预期不符,从而导致指令不能在预定的时钟周期内完成[9]。本文采用流水线阻塞的方式来处理控制冒险。在IF/ID 的寄存器中插入一个气泡(NOP)强制改写寄存器中的内容。当分支未被选中时(在ID 期间确定),提取未选中指令,继续进行。当在ID 期间确定选中该分支时,则在分支目标处重新开始提取,该分支后面的所有指令停顿1个时钟周期。
1.3 乘法计算与除法计算的优化
乘法器使用了2 位Booth 算法来实现,2 位Booth算法见公式(1):
由于在硬件中所有的操作数都是以补码的形式存在,如果单纯使用补码乘法算法,则需要特地挑出第N个部分积,并使用补码减法操作,这就需要实现一个额外的状态机来控制,从而增加了硬件设计复杂度。但是,使用2 位Booth 算法可以显著减少加法计算的次数[10]。
采用2 位Booth 算法,使用移位加策略实现64 位的乘法操作需要32 个时钟周期,并且不支持流水操作,即第一条乘法全部完成之后才能开始计算下一条。为了实现全流水、4 个时钟周期延迟的定点乘法指令,就需要使用将各个部分积并行地加在一起的方式进行计算,而不是串行迭代累加。因此,在使用Booth 算法的基础上,使用不需要等待进位信号的保留进位加法器,并且使用华莱士树结构。最终完成的乘法器结构如图5所示。
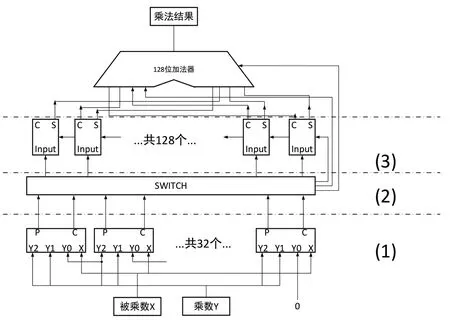
图5 乘法器结构
图5 中的第(1)部分采用2 位Booth 算法得到16个部分积,其中P 为128 位,是部分积的主体,C 为1位,表示对被乘数取反。第(2)部分采用类似矩阵转置连线方式,将16 个128 位部分积转置为128 个16位等宽的数,用作华莱士树每处的输入。第(3)部分为保留进位加法器搭建的华莱士树结构,是64 个1 位的华莱士树的集合。由于两个64 位的由符号数相乘得到的最大数值不超过126 位,所以最高位处的华莱士树向高位的进位直接忽略。
除法器不能像前面乘法器一样使用多个加法器加速乘法的运算,因为除法的每次迭代都需要知道前面减法结果的符号,而乘法却可以直接生成64 个部分积。所以除法器采用循环移位的方式进行设计。除法计算流程如图6 所示。
(3)加强对农业循环经济的相关延伸,促进多种模式的循环发展。目前很多地区发展循环经济的模式比较单一,仅仅停留在单项或者双向流通的过程之中,应该加大宣传力度,推广新的发展模式,让更多的农民了解并使用,从而实现农业循环经济的更加充分发展。
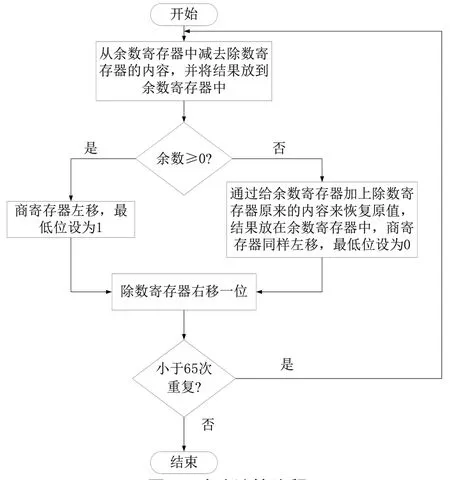
图6 除法计算流程
根据上述流程,最终实现的除法器结构如图7所示。
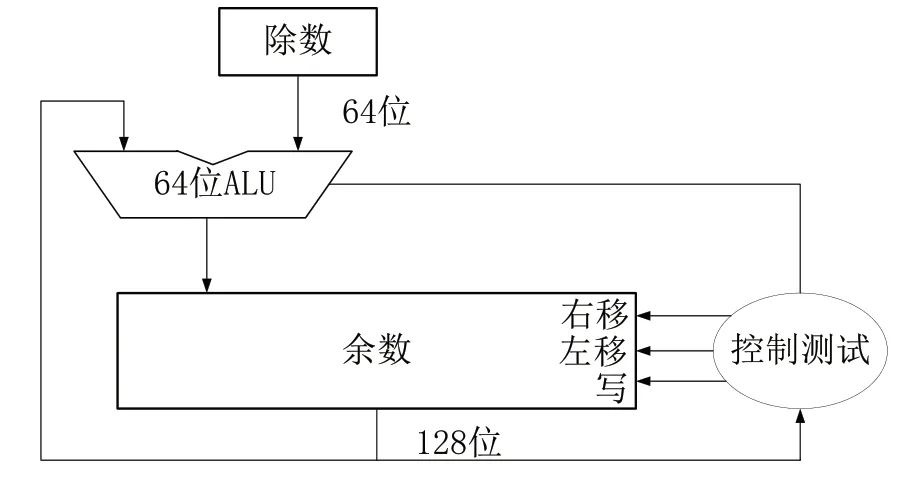
图7 除法器结构
1.4 高速缓存设计
由于在物理实现上存在差异,处理器与内存的运行速度一直存在着较大的差距。如果程序有较多地依赖访存结果的数据,那么这个差距会极大地影响处理器的性能。为了减小这一差距对处理器性能的影响,通常将存储结构划分为四个不同的层次:高速缓存(Cache)、寄存器、IO、内存[11]。在与处理器距离越近的位置采用存储密度较小的电路,通过牺牲内存容量来提升访问速度。高速缓存就是距离处理器最近的存储结构,通常容量设计得较小以获得更快的访问速度。设计的Cache模块结构如图8所示。
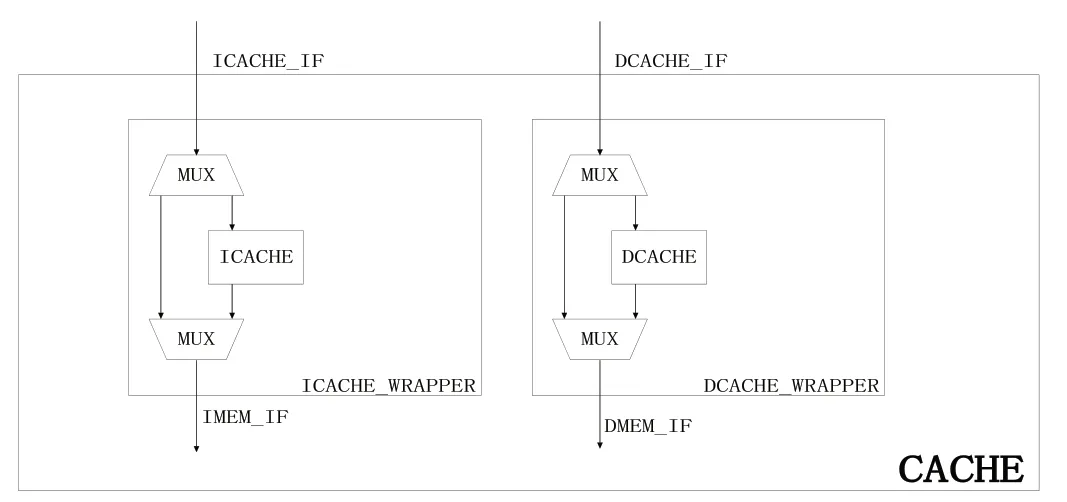
图8 Cache模块结构
为了避免共享Cache 产生的结构冲突,设计了独立的指令Cache(I-cache)和数据Cache(D-cache),I-cache 只用来取指,D-cache只用来访存。
I-cache 的行内偏移(Offset)大小为4 bit,索引(Index)大小为7 bit,标签(Tag)大小为21 bit。更新方式使用写直通。采用Tag 和数据(Data)同步访问的形式来降低Cache 命中情况下的执行周期数,其中Data Array 采用同步SRAM 实现,容量大小为4 KB,Cache Line 的大小为16 byte,路数为两路,组索引(Set Index)大小为128 bit。Tag Array 采用寄存器实现,路数为两路,Set Index 大小为128 bit,内容为大小为1 bit的有效位(Valid)以及大小为21 bit的Tag。
D-cache 的结构与I-cache 大致相同,但是由于访存的需要,D-cache 采用了写回的更新方式,所以在Tag Array中还含有1 bit大小的脏块(Dirty)用来标识Cache Line 是否被修改。
2 运行环境设计
完成处理器的硬件部分设计后,要想让处理器运行程序还需要完成相应的运行环境设计。程序的运行都需要运行环境的支持,包括加载、销毁程序以及提供程序运行时的各种动态链接库等。本设计中运行环境主要包括基础环境以及输入输出两部分。其中,基础环境主要负责程序的运行,输入输出主要负责处理器与外围设备的连接。
2.1 基础环境
在处理器运行客户程序之前,将需要执行的程序代码编译成可执行文件。但是不能使用GCC 的默认选项直接编译,因为默认选项会根据Linux 的运行环境将代码编译成运行在Linux 下的可执行文件。但此时的处理器并不能为客户程序提供GNU/Linux的运行环境,在处理器中无法正确运行上述可执行文件。所以,需要采用交叉编译的方式来生成处理器可运行的文件。
1)计算:作为程序最基本的需求,所有计算相关的代码(顺序语句、分支、循环、函数调用等)都会被编译器编译成功能等价的指令序列,最终在CPU 上执行。
2)内存申请:某些程序需要在运行时动态地申请内存来使用,通过实现内存的动态管理相应的库函数来实现。
3)结束运行:一般程序都会有结束运行的时候,通过RISC-V 指令集的Ebreak 指令实现程序结束的库函数。
4)打印信息:输出是程序的另一个基本需求,通过实现输出字符的库函数putch()来实现。
2.2 输入输出
对于RISC-V 架构,输入输出是通过内存映射(Memory Mapping I/O, MMIO)实现的。此外,使用DPI(Direct Programming Interface)-C 机制将硬件电路中寄存器的值传输给仿真环境,使用DPI-C 机制额外的好处就是不用修改硬件电路。
使用通用异步收发传输器(Universal Asynchronous Receiver/Transmitter, UART)来实现处理器与外围设备的通信。实时时钟(Real Time Clock, RTC)用来产生时钟信号。
3 处理器及运行环境测试
3.1 功能测试
采用C语言编写测试集对RV64I的所有指令进行测试。测试在Linux 环境下进行,使用虚拟板卡以及开源编译器Verilator 进行编译仿真[12]。大致流程为:1)通过运行环境将测试集内的程序加载到虚拟内存中,CPU 读取并运行程序至结束语句,仿真结果显示“pass!”表明测试程序运行成功;2)最后遍历测试集内的所有程序,完成对处理器以及运行环境的功能测试。图9 给出了乘法指令的仿真波形图,此时运行的指令为MUL 乘数X 与乘数Y 为0x11f42438,最终计算结果res 为0x14255a47fdfcc40,可以看出,在加入了Booth 算法以后,乘法指令的运行过程得到简化,并且运行结果正确。图10 给出了除法指令的仿真波形图,运行的指令为DIV,除数divisor 为2,被除数dividend 为0x375F00,最终结果为0x1baf80。图11给出了测试集内包括上述指令的所有程序的仿真测试结果。这些仿真结果表明,CPU 通过了测试集内的所有测试程序的测试。

图9 乘法指令仿真波形图

图10 除法指令仿真波形图
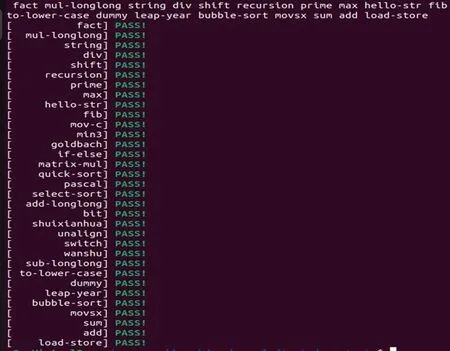
图11 仿真测试结果
3.2 性能测试
这里用CoreMark 测试程序来进行性能测试。CoreMark 测试程序包含了大部分处理器工作时的常用算法,所以其测试结果在处理器领域中是处理器性能评价的重要参考指标[13]。其跑分的计算方法为:首先,使用宏定义ITERATIONS 参数确定程序循环执行的次数,然后除以程序运行的总时长Total time,计算出来的每秒执行CoreMark 程序的循环次数,再除以处理器的主频,就得出CoreMark 程序的跑分,单位是CoreMark/MHz。CoreMark 测试程序的测试结果如图12 所示。可以计算出最终得分为:
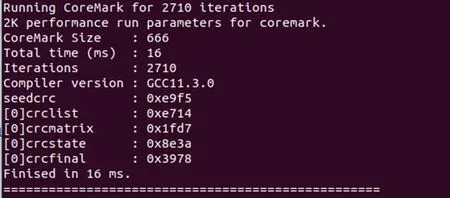
图12 CoreMark测试程序的运行结果
(Iteration/Total time)/50M=3.38 CoreMark/MHz。
表1 给出了处理器关键技术对照情况。相比较而言,本处理器性能优于大多数5 级开源流水线处理器。

表1 处理器关键技术对照表
4 结语
课题组基于RISC-V 指令集搭建了5 级流水线处理器,从分支跳转指令的处理、乘除法运算处理、冒险问题的处理、存储结构等方面优化处理器性能,并搭建了针对RISC-V 指令集的运行环境。最终完成的处理器及其运行环境在虚拟环境下通过了功能验证并完成了CoreMark 性能测试。结果表明,该处理器在性能方面优于大部分同流水线深度的开源项目。该处理器还可以从超标量、多发射、动态指令预测、非对齐指令等方面继续优化,从而进一步提升性能。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
计算机应用(2020年5期)2020-06-07 07:06:44
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
小学生优秀作文(低年级)(2017年9期)2017-08-07 02:14:09
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
小学教学研究(2016年36期)2016-05-17 05:51:56
中国资源综合利用(2016年9期)2016-01-22 08:35:22
儿童故事画报·智力大王(2015年2期)2015-05-20 14:39:08
自动化博览(2014年6期)2014-02-28 22:32:05
兴趣英语(2013年12期)2014-02-11 03:21:38
